 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling and Estimation of Human Walking Gait for Physical Human-Robot Interaction
Aug 27, 2021
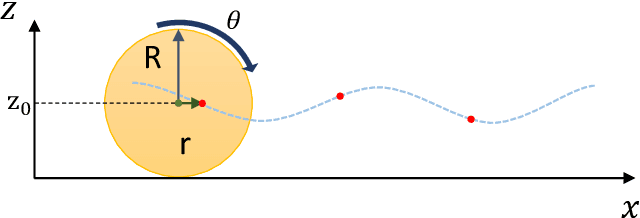
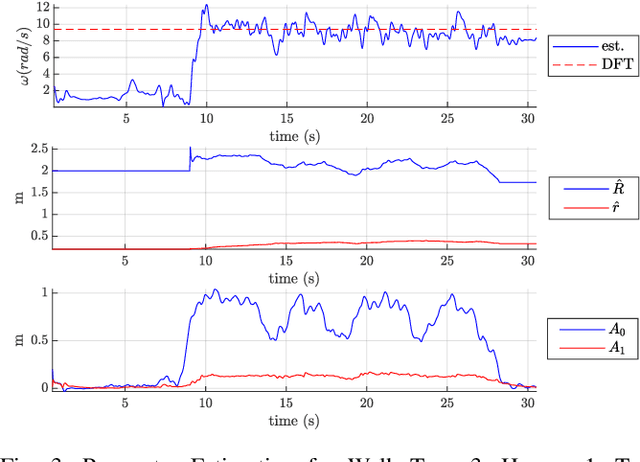
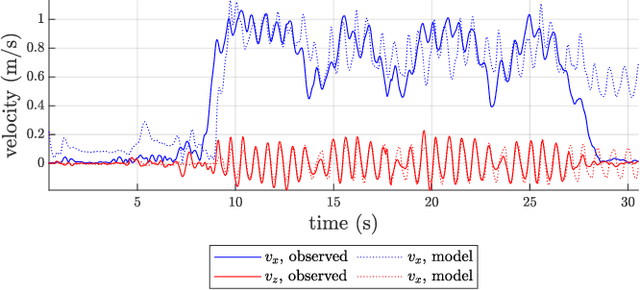
An approach to model and estimate human walking kinematics in real-time for Physical Human-Robot Interaction is presented. The human gait velocity along the forward and vertical direction of motion is modelled according to the Yoyo-model. We designed an Extended Kalman Filter (EKF) algorithm to estimate the frequency, bias and trigonometric state of a biased sinusoidal signal, from which the kinematic parameters of the Yoyo-model can be extracted. Quality and robustness of the estimation are improved by opportune filtering based on heuristics. The approach is successfully evaluated on a real dataset of walking humans, including complex trajectories and changing step frequency over time.
SemSegMap- 3D Segment-Based Semantic Localization
Jul 30, 2021
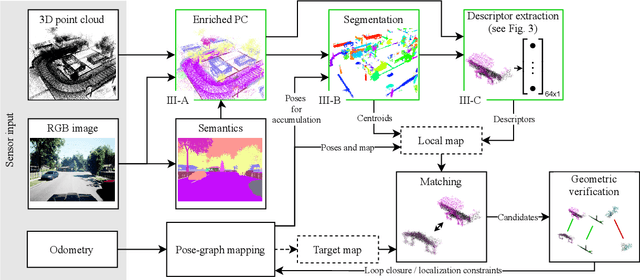
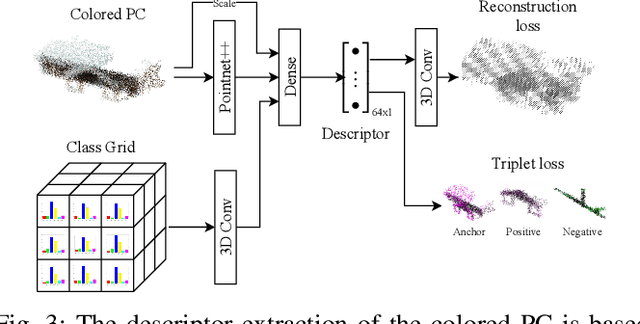
Localization is an essential task for mobile autonomous robotic systems that want to use pre-existing maps or create new ones in the context of SLAM. Today, many robotic platforms are equipped with high-accuracy 3D LiDAR sensors, which allow a geometric mapping, and cameras able to provide semantic cues of the environment. Segment-based mapping and localization have been applied with great success to 3D point-cloud data, while semantic understanding has been shown to improve localization performance in vision based systems. In this paper we combine both modalities in SemSegMap, extending SegMap into a segment based mapping framework able to also leverage color and semantic data from the environment to improve localization accuracy and robustness. In particular, we present new segmentation and descriptor extraction processes. The segmentation process benefits from additional distance information from color and semantic class consistency resulting in more repeatable segments and more overlap after re-visiting a place. For the descriptor, a tight fusion approach in a deep-learned descriptor extraction network is performed leading to a higher descriptiveness for landmark matching. We demonstrate the advantages of this fusion on multiple simulated and real-world datasets and compare its performance to various baselines. We show that we are able to find 50.9% more high-accuracy prior-less global localizations compared to SegMap on challenging datasets using very compact maps while also providing accurate full 6 DoF pose estimates in real-time.
Under the Sand: Navigation and Localization of a Small Unmanned Aerial Vehicle for Landmine Detection with Ground Penetrating Synthetic Aperture Radar
Jun 18, 2021
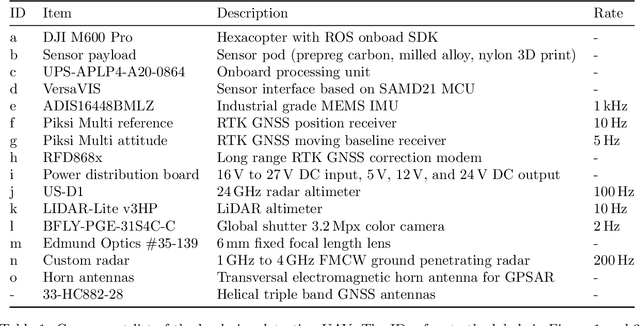
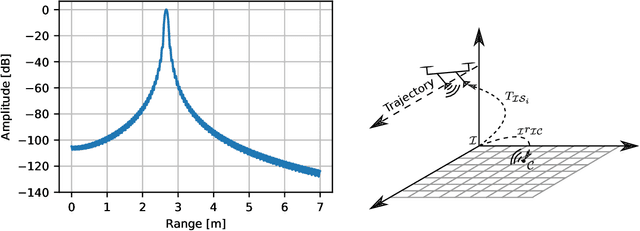
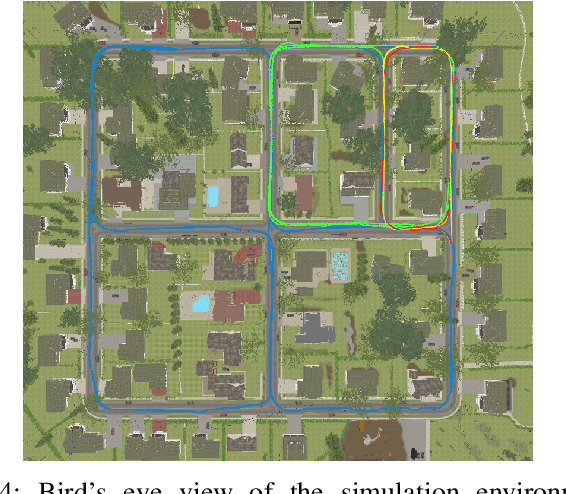
Ground penetrating radar mounted on a small unmanned aerial vehicle (UAV) is a promising tool to assist humanitarian landmine clearance. However, the quality of synthetic aperture radar images depends on accurate and precise motion estimation of the radar antennas as well as generating informative viewpoints with the UAV. This paper presents a complete and automatic airborne ground-penetrating synthetic aperture radar (GPSAR) system. The system consists of a spatially calibrated and temporally synchronized industrial grade sensor suite that enables navigation above ground level, radar imaging, and optical imaging. A custom mission planning framework allows generation and automatic execution of stripmap and circular GPSAR trajectories controlled above ground level as well as aerial imaging survey flights. A factor graph based state estimator fuses measurements from dual receiver real-time kinematic (RTK) global navigation satellite system (GNSS) and an inertial measurement unit (IMU) to obtain precise, high rate platform positions and orientations. Ground truth experiments showed sensor timing as accurate as 0.8 {\mu}s and as precise as 0.1 {\mu}s with localization rates of 1 kHz. The dual position factor formulation improves online localization accuracy up to 40 % and batch localization accuracy up to 59 % compared to a single position factor with uncertain heading initialization. Our field trials validated a localization accuracy and precision that enables coherent radar measurement addition and detection of radar targets buried in sand. This validates the potential as an aerial landmine detection system.
TSDF++: A Multi-Object Formulation for Dynamic Object Tracking and Reconstruction
May 16, 2021
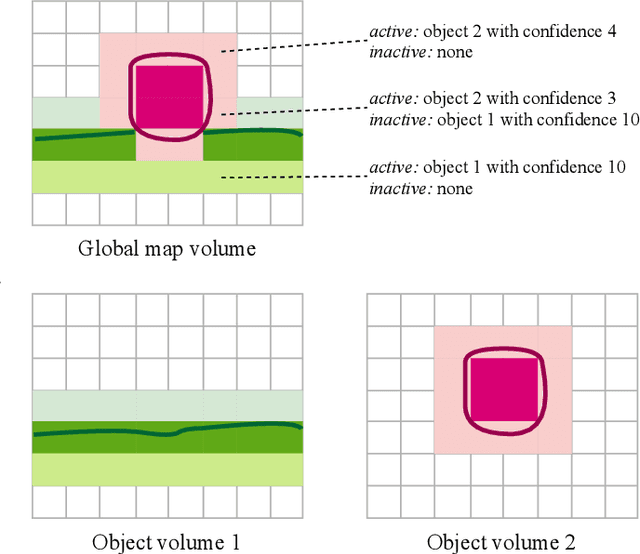

The ability to simultaneously track and reconstruct multiple objects moving in the scene is of the utmost importance for robotic tasks such as autonomous navigation and interaction. Virtually all of the previous attempts to map multiple dynamic objects have evolved to store individual objects in separate reconstruction volumes and track the relative pose between them. While simple and intuitive, such formulation does not scale well with respect to the number of objects in the scene and introduces the need for an explicit occlusion handling strategy. In contrast, we propose a map representation that allows maintaining a single volume for the entire scene and all the objects therein. To this end, we introduce a novel multi-object TSDF formulation that can encode multiple object surfaces at any given location in the map. In a multiple dynamic object tracking and reconstruction scenario, our representation allows maintaining accurate reconstruction of surfaces even while they become temporarily occluded by other objects moving in their proximity. We evaluate the proposed TSDF++ formulation on a public synthetic dataset and demonstrate its ability to preserve reconstructions of occluded surfaces when compared to the standard TSDF map representation.
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021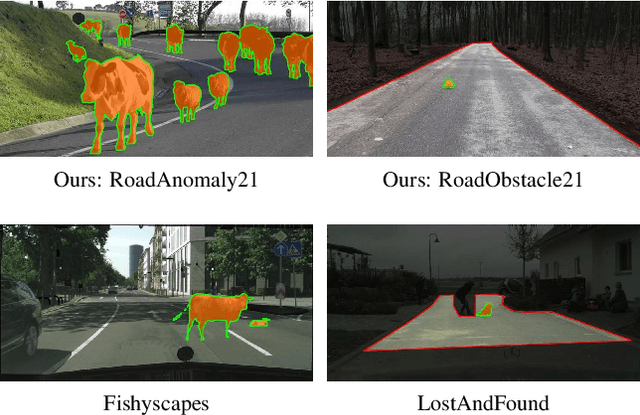
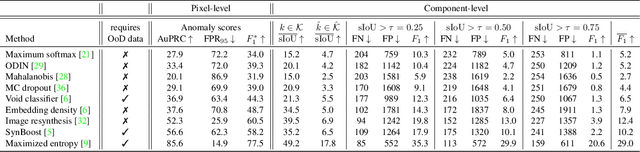

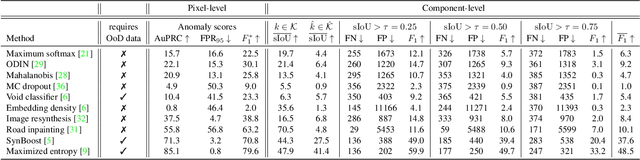
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.
Crowd against the machine: A simulation-based benchmark tool to evaluate and compare robot capabilities to navigate a human crowd
Apr 29, 2021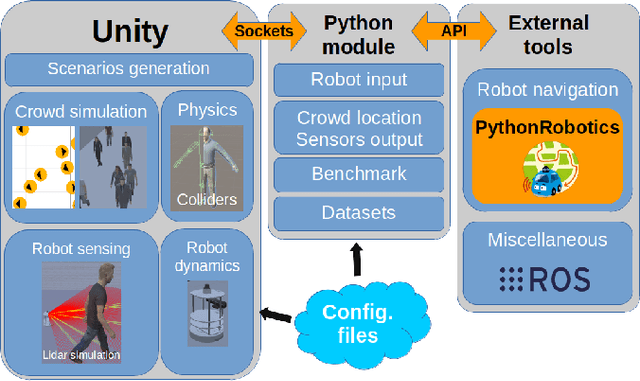
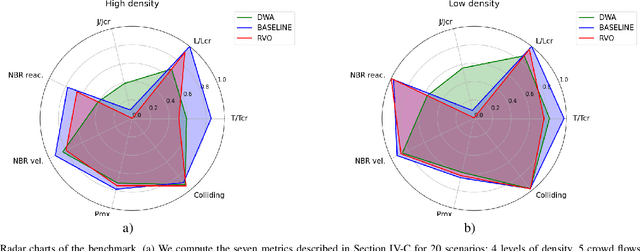
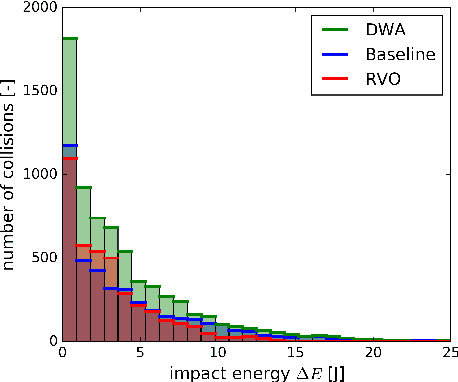
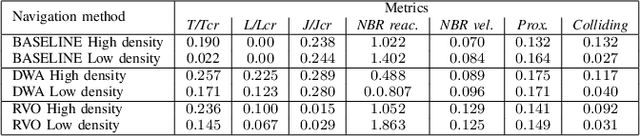
The evaluation of robot capabilities to navigate human crowds is essential to conceive new robots intended to operate in public spaces. This paper initiates the development of a benchmark tool to evaluate such capabilities; our long term vision is to provide the community with a simulation tool that generates virtual crowded environment to test robots, to establish standard scenarios and metrics to evaluate navigation techniques in terms of safety and efficiency, and thus, to install new methods to benchmarking robots' crowd navigation capabilities. This paper presents the architecture of the simulation tools, introduces first scenarios and evaluation metrics, as well as early results to demonstrate that our solution is relevant to be used as a benchmark tool.
Spherical Multi-Modal Place Recognition for Heterogeneous Sensor Systems
Apr 17, 2021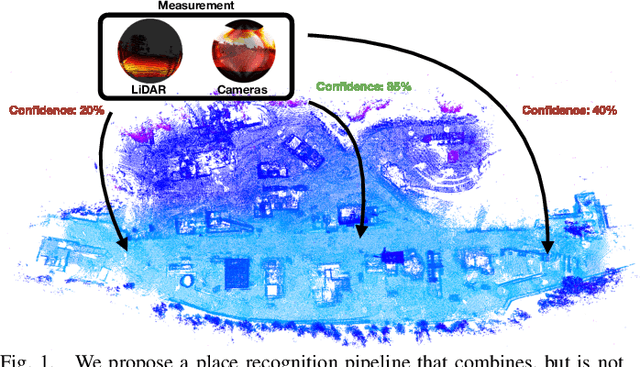
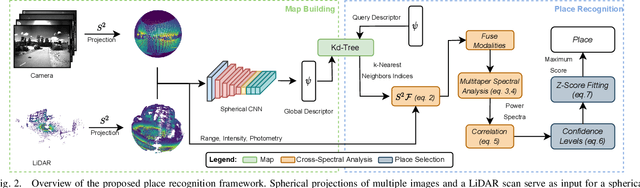
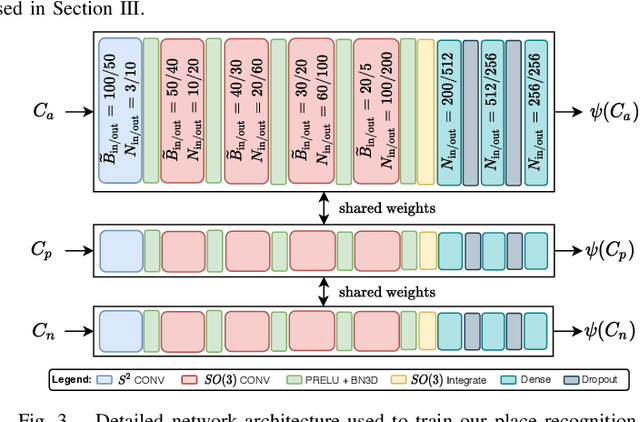
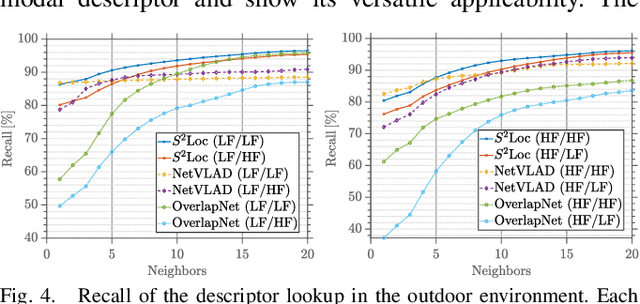
In this paper, we propose a robust end-to-end multi-modal pipeline for place recognition where the sensor systems can differ from the map building to the query. Our approach operates directly on images and LiDAR scans without requiring any local feature extraction modules. By projecting the sensor data onto the unit sphere, we learn a multi-modal descriptor of partially overlapping scenes using a spherical convolutional neural network. The employed spherical projection model enables the support of arbitrary LiDAR and camera systems readily without losing information. Loop closure candidates are found using a nearest-neighbor lookup in the embedding space. We tackle the problem of correctly identifying the closest place by correlating the candidates' power spectra, obtaining a confidence value per prospect. Our estimate for the correct place corresponds then to the candidate with the highest confidence. We evaluate our proposal w.r.t. state-of-the-art approaches in place recognition using real-world data acquired using different sensors. Our approach can achieve a recall that is up to 10% and 5% higher than for a LiDAR- and vision-based system, respectively, when the sensor setup differs between model training and deployment. Additionally, our place selection can correctly identify up to 95% matches from the candidate set.
3D3L: Deep Learned 3D Keypoint Detection and Description for LiDARs
Apr 12, 2021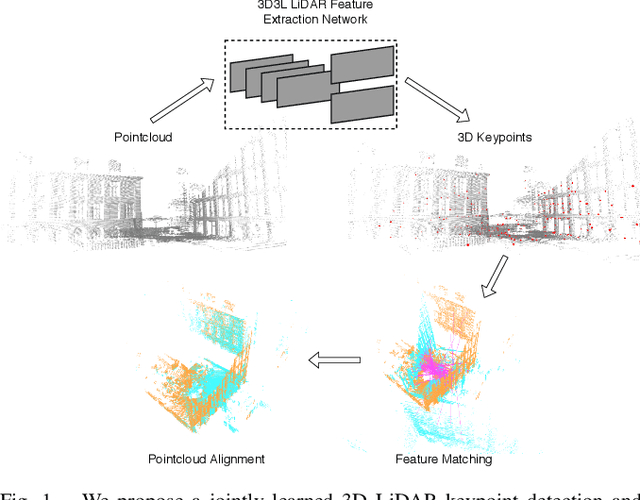
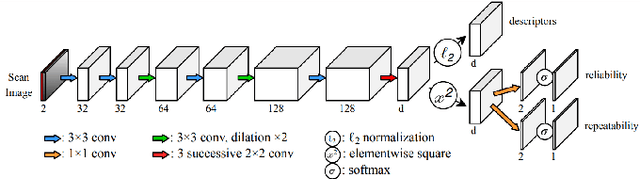
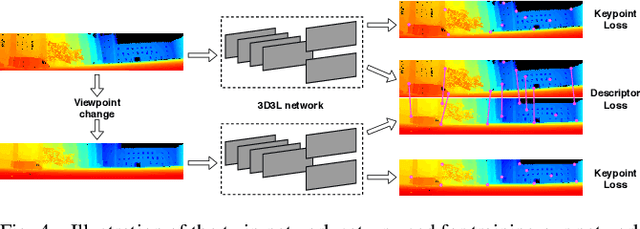
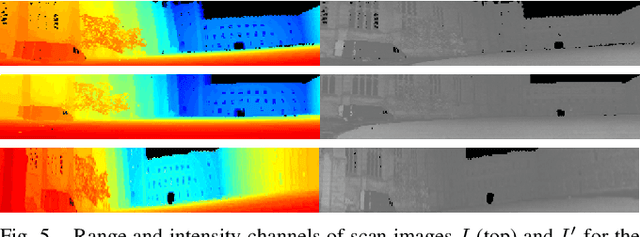
With the advent of powerful, light-weight 3D LiDARs, they have become the hearth of many navigation and SLAM algorithms on various autonomous systems. Pointcloud registration methods working with unstructured pointclouds such as ICP are often computationally expensive or require a good initial guess. Furthermore, 3D feature-based registration methods have never quite reached the robustness of 2D methods in visual SLAM. With the continuously increasing resolution of LiDAR range images, these 2D methods not only become applicable but should exploit the illumination-independent modalities that come with it, such as depth and intensity. In visual SLAM, deep learned 2D features and descriptors perform exceptionally well compared to traditional methods. In this publication, we use a state-of-the-art 2D feature network as a basis for 3D3L, exploiting both intensity and depth of LiDAR range images to extract powerful 3D features. Our results show that these keypoints and descriptors extracted from LiDAR scan images outperform state-of-the-art on different benchmark metrics and allow for robust scan-to-scan alignment as well as global localization.
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021
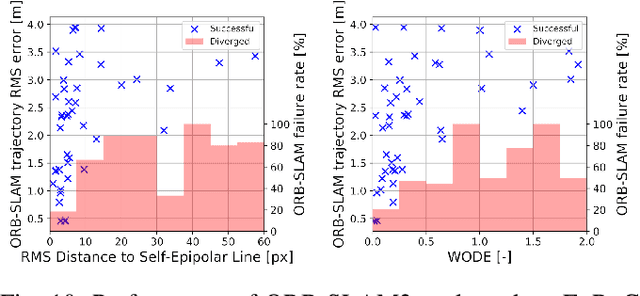

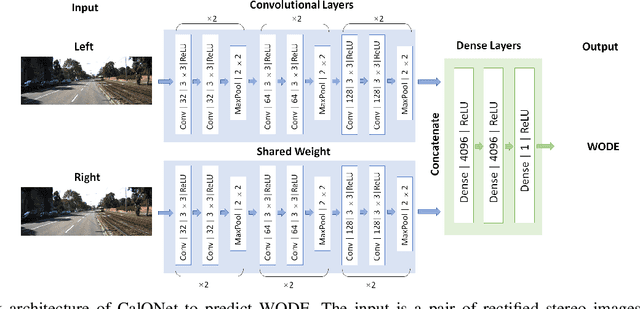
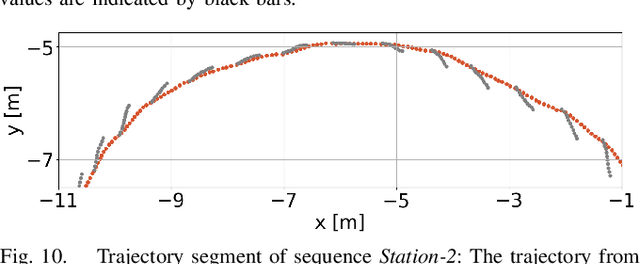
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.
Dynamic Object Aware LiDAR SLAM based on Automatic Generation of Training Data
Apr 08, 2021
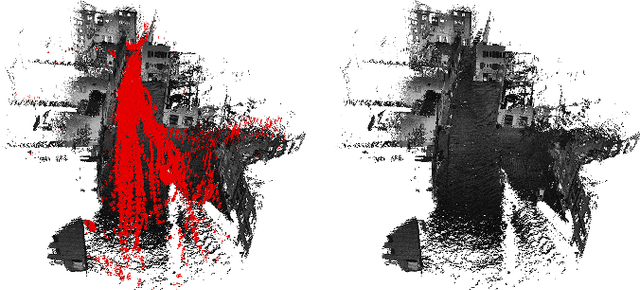
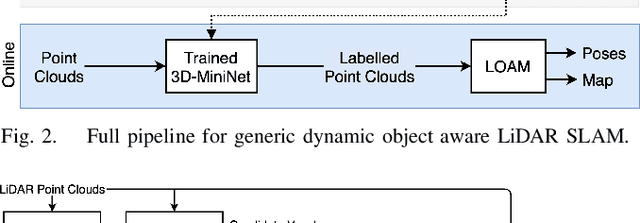
Highly dynamic environments, with moving objects such as cars or humans, can pose a performance challenge for LiDAR SLAM systems that assume largely static scenes. To overcome this challenge and support the deployment of robots in real world scenarios, we propose a complete solution for a dynamic object aware LiDAR SLAM algorithm. This is achieved by leveraging a real-time capable neural network that can detect dynamic objects, thus allowing our system to deal with them explicitly. To efficiently generate the necessary training data which is key to our approach, we present a novel end-to-end occupancy grid based pipeline that can automatically label a wide variety of arbitrary dynamic objects. Our solution can thus generalize to different environments without the need for expensive manual labeling and at the same time avoids assumptions about the presence of a predefined set of known objects in the scene. Using this technique, we automatically label over 12000 LiDAR scans collected in an urban environment with a large amount of pedestrians and use this data to train a neural network, achieving an average segmentation IoU of 0.82. We show that explicitly dealing with dynamic objects can improve the LiDAR SLAM odometry performance by 39.6% while yielding maps which better represent the environments. A supplementary video as well as our test data are available online.