 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto4D: Learning to Label 4D Objects from Sequential Point Clouds
Jan 17, 2021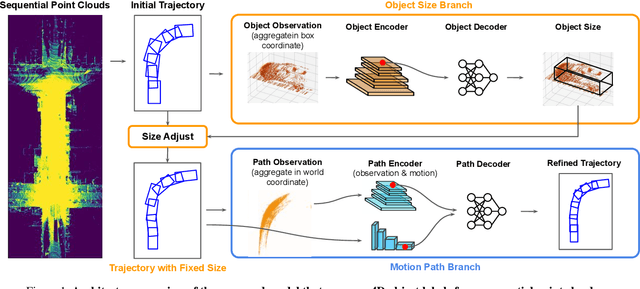
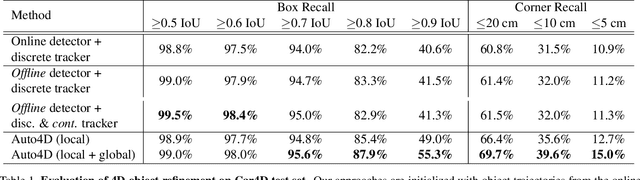
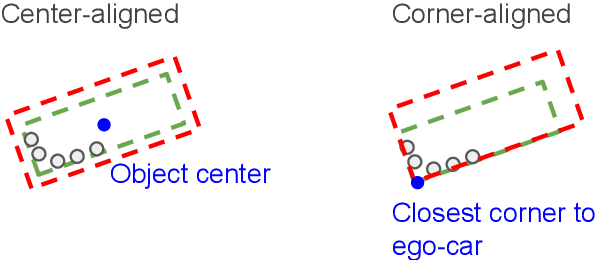
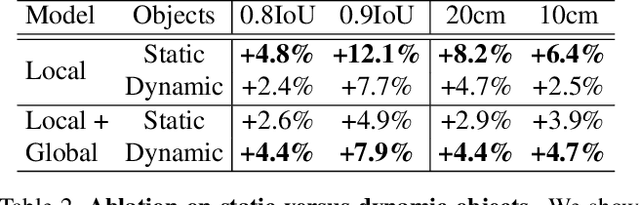
In the past few years we have seen great advances in 3D object detection thanks to deep learning methods. However, they typically rely on large amounts of high-quality labels to achieve good performance, which often require time-consuming and expensive work by human annotators. To address this we propose an automatic annotation pipeline that generates accurate object trajectories in 3D (ie, 4D labels) from LiDAR point clouds. Different from previous works that consider single frames at a time, our approach directly operates on sequential point clouds to combine richer object observations. The key idea is to decompose the 4D label into two parts: the 3D size of the object, and its motion path describing the evolution of the object's pose through time. More specifically, given a noisy but easy-to-get object track as initialization, our model first estimates the object size from temporally aggregated observations, and then refines its motion path by considering both frame-wise observations as well as temporal motion cues. We validate the proposed method on a large-scale driving dataset and show that our approach achieves significant improvements over the baselines. We also showcase the benefits of our approach under the annotator-in-the-loop setting.
S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
Jan 17, 2021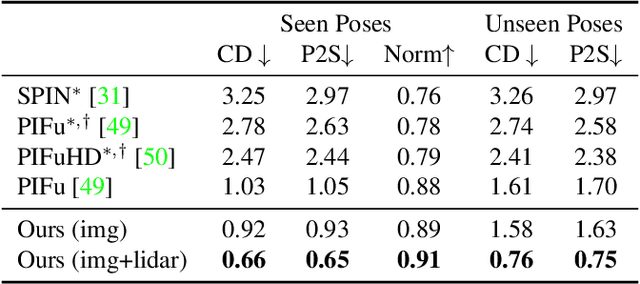
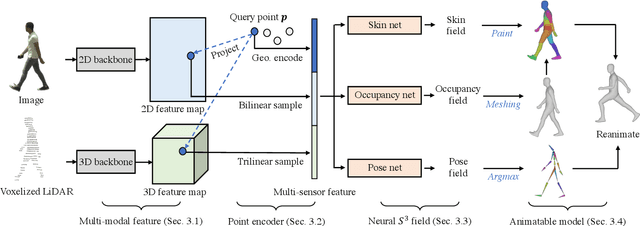
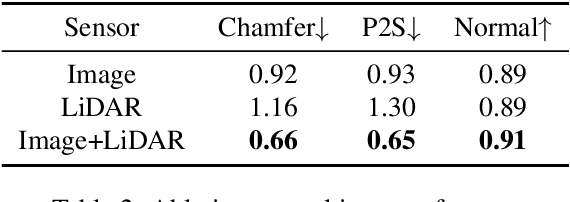
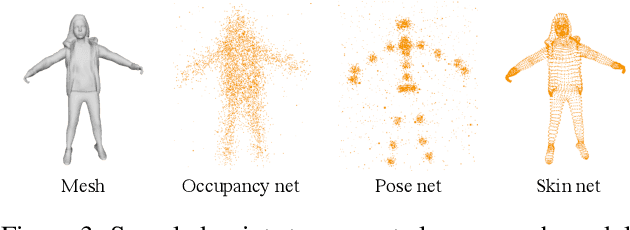
Constructing and animating humans is an important component for building virtual worlds in a wide variety of applications such as virtual reality or robotics testing in simulation. As there are exponentially many variations of humans with different shape, pose and clothing, it is critical to develop methods that can automatically reconstruct and animate humans at scale from real world data. Towards this goal, we represent the pedestrian's shape, pose and skinning weights as neural implicit functions that are directly learned from data. This representation enables us to handle a wide variety of different pedestrian shapes and poses without explicitly fitting a human parametric body model, allowing us to handle a wider range of human geometries and topologies. We demonstrate the effectiveness of our approach on various datasets and show that our reconstructions outperform existing state-of-the-art methods. Furthermore, our re-animation experiments show that we can generate 3D human animations at scale from a single RGB image (and/or an optional LiDAR sweep) as input.
Asynchronous Multi-View SLAM
Jan 17, 2021



Existing multi-camera SLAM systems assume synchronized shutters for all cameras, which is often not the case in practice. In this work, we propose a generalized multi-camera SLAM formulation which accounts for asynchronous sensor observations. Our framework integrates a continuous-time motion model to relate information across asynchronous multi-frames during tracking, local mapping, and loop closing. For evaluation, we collected AMV-Bench, a challenging new SLAM dataset covering 482 km of driving recorded using our asynchronous multi-camera robotic platform. AMV-Bench is over an order of magnitude larger than previous multi-view HD outdoor SLAM datasets, and covers diverse and challenging motions and environments. Our experiments emphasize the necessity of asynchronous sensor modeling, and show that the use of multiple cameras is critical towards robust and accurate SLAM in challenging outdoor scenes.
Adversarial Attacks On Multi-Agent Communication
Jan 17, 2021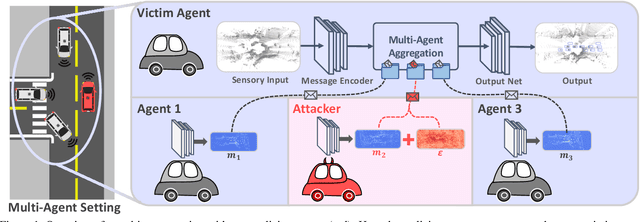
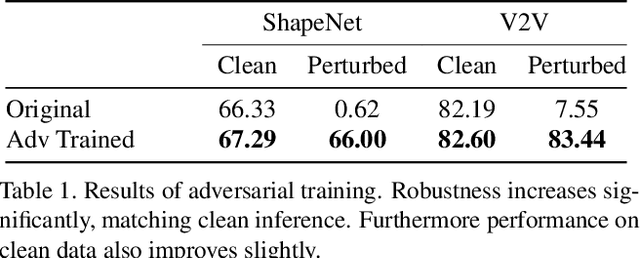
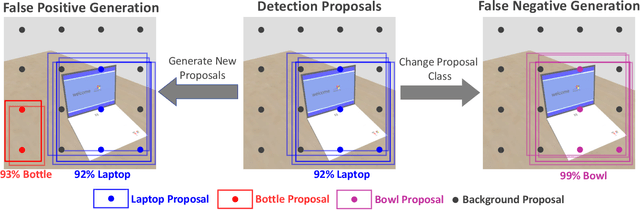
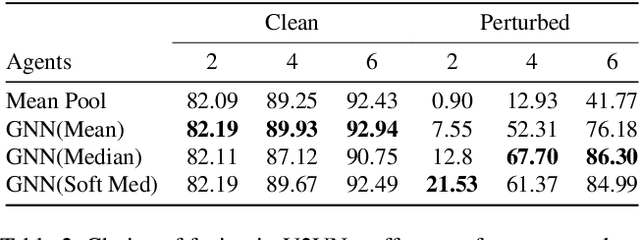
Growing at a very fast pace, modern autonomous systems will soon be deployed at scale, opening up the possibility for cooperative multi-agent systems. By sharing information and distributing workloads, autonomous agents can better perform their tasks and enjoy improved computation efficiency. However, such advantages rely heavily on communication channels which have been shown to be vulnerable to security breaches. Thus, communication can be compromised to execute adversarial attacks on deep learning models which are widely employed in modern systems. In this paper, we explore such adversarial attacks in a novel multi-agent setting where agents communicate by sharing learned intermediate representations. We observe that an indistinguishable adversarial message can severely degrade performance, but becomes weaker as the number of benign agents increase. Furthermore, we show that transfer attacks are more difficult in this setting when compared to directly perturbing the inputs, as it is necessary to align the distribution of communication messages with domain adaptation. Finally, we show that low-budget online attacks can be achieved by exploiting the temporal consistency of streaming sensory inputs.
TrafficSim: Learning to Simulate Realistic Multi-Agent Behaviors
Jan 17, 2021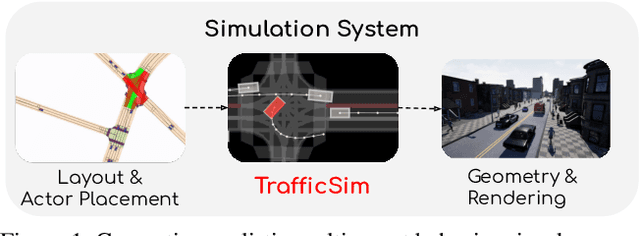
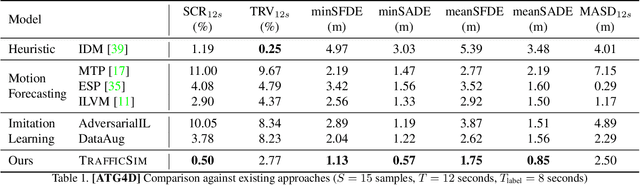

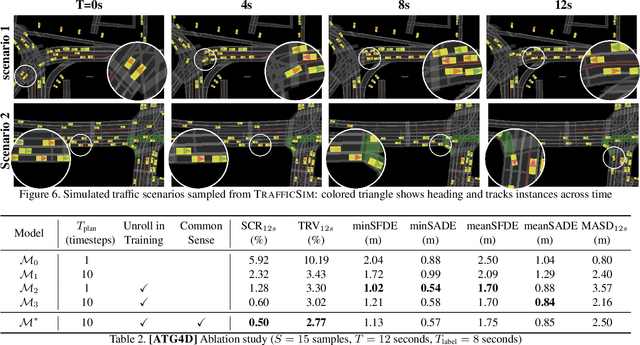
Simulation has the potential to massively scale evaluation of self-driving systems enabling rapid development as well as safe deployment. To close the gap between simulation and the real world, we need to simulate realistic multi-agent behaviors. Existing simulation environments rely on heuristic-based models that directly encode traffic rules, which cannot capture irregular maneuvers (e.g., nudging, U-turns) and complex interactions (e.g., yielding, merging). In contrast, we leverage real-world data to learn directly from human demonstration and thus capture a more diverse set of actor behaviors. To this end, we propose TrafficSim, a multi-agent behavior model for realistic traffic simulation. In particular, we leverage an implicit latent variable model to parameterize a joint actor policy that generates socially-consistent plans for all actors in the scene jointly. To learn a robust policy amenable for long horizon simulation, we unroll the policy in training and optimize through the fully differentiable simulation across time. Our learning objective incorporates both human demonstrations as well as common sense. We show TrafficSim generates significantly more realistic and diverse traffic scenarios as compared to a diverse set of baselines. Notably, we can exploit trajectories generated by TrafficSim as effective data augmentation for training better motion planner.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021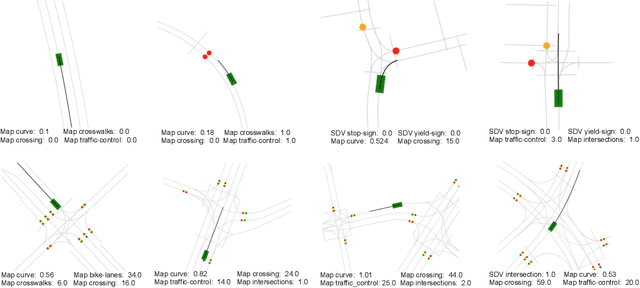
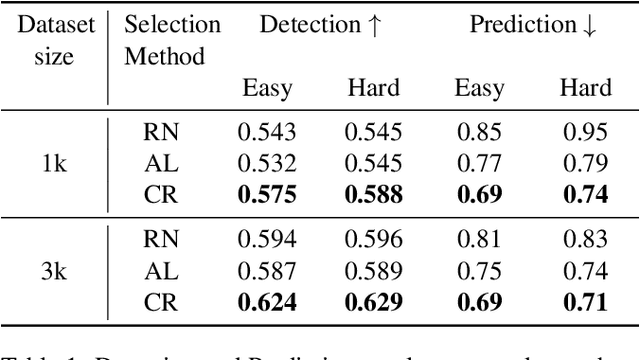

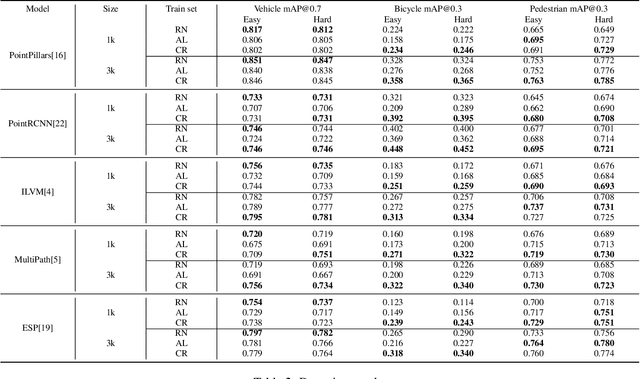
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
Self-Supervised Representation Learning from Flow Equivariance
Jan 16, 2021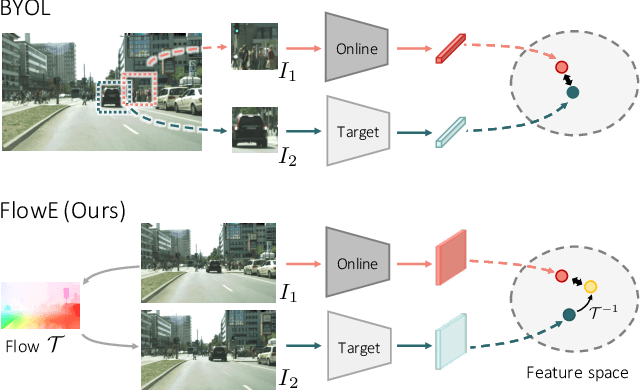
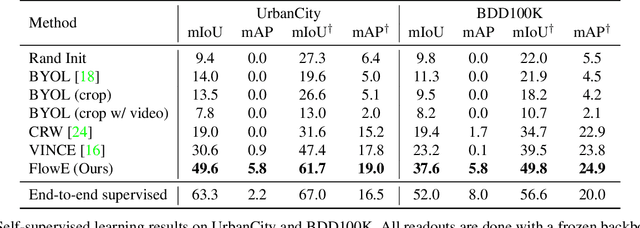
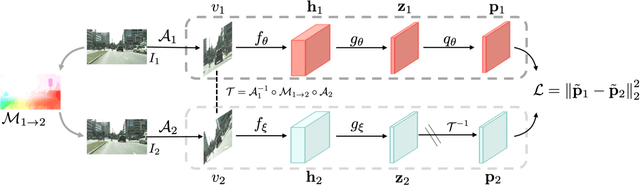
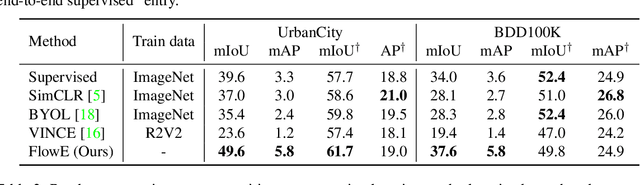
Self-supervised representation learning is able to learn semantically meaningful features; however, much of its recent success relies on multiple crops of an image with very few objects. Instead of learning view-invariant representation from simple images, humans learn representations in a complex world with changing scenes by observing object movement, deformation, pose variation, and ego motion. Motivated by this ability, we present a new self-supervised learning representation framework that can be directly deployed on a video stream of complex scenes with many moving objects. Our framework features a simple flow equivariance objective that encourages the network to predict the features of another frame by applying a flow transformation to the features of the current frame. Our representations, learned from high-resolution raw video, can be readily used for downstream tasks on static images. Readout experiments on challenging semantic segmentation, instance segmentation, and object detection benchmarks show that we are able to outperform representations obtained from previous state-of-the-art methods including SimCLR and BYOL.
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles
Jan 16, 2021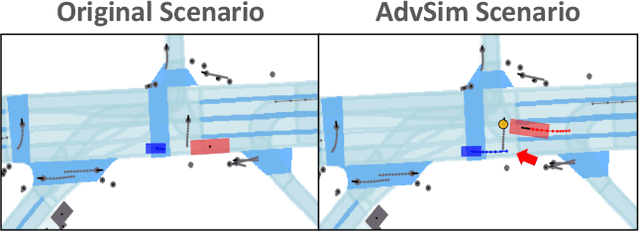
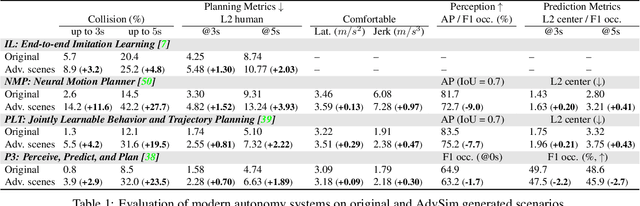

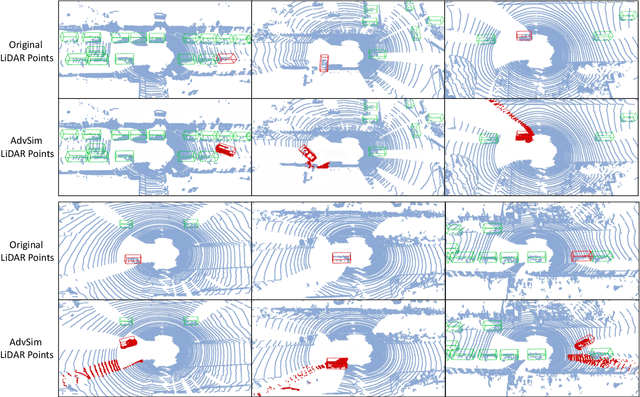
As self-driving systems become better, simulating scenarios where the autonomy stack is likely to fail becomes of key importance. Traditionally, those scenarios are generated for a few scenes with respect to the planning module that takes ground-truth actor states as input. This does not scale and cannot identify all possible autonomy failures, such as perception failures due to occlusion. In this paper, we propose AdvSim, an adversarial framework to generate safety-critical scenarios for any LiDAR-based autonomy system. Given an initial traffic scenario, AdvSim modifies the actors' trajectories in a physically plausible manner and updates the LiDAR sensor data to create realistic observations of the perturbed world. Importantly, by simulating directly from sensor data, we obtain adversarial scenarios that are safety-critical for the full autonomy stack. Our experiments show that our approach is general and can identify thousands of semantically meaningful safety-critical scenarios for a wide range of modern self-driving systems. Furthermore, we show that the robustness and safety of these autonomy systems can be further improved by training them with scenarios generated by AdvSim.
LookOut: Diverse Multi-Future Prediction and Planning for Self-Driving
Jan 16, 2021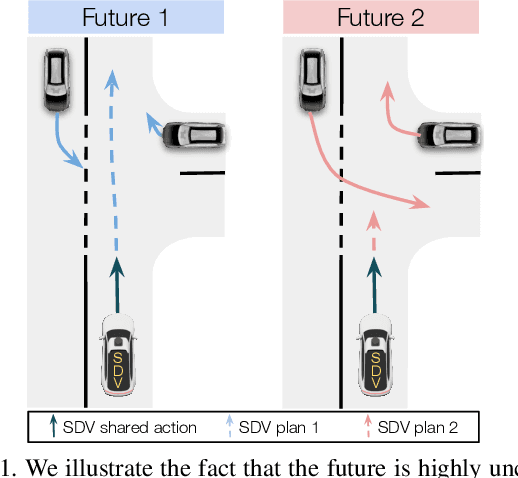
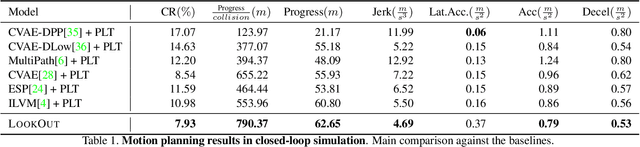

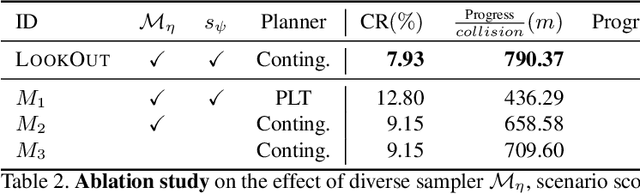
Self-driving vehicles need to anticipate a diverse set of future traffic scenarios in order to safely share the road with other traffic participants that may exhibit rare but dangerous driving. In this paper, we present LookOut, an approach to jointly perceive the environment and predict a diverse set of futures from sensor data, estimate their probability, and optimize a contingency plan over these diverse future realizations. In particular, we learn a diverse joint distribution over multi-agent future trajectories in a traffic scene that allows us to cover a wide range of future modes with high sample efficiency while leveraging the expressive power of generative models. Unlike previous work in diverse motion forecasting, our diversity objective explicitly rewards sampling future scenarios that require distinct reactions from the self-driving vehicle for improved safety. Our contingency planner then finds comfortable trajectories that ensure safe reactions to a wide range of future scenarios. Through extensive evaluations, we show that our model demonstrates significantly more diverse and sample-efficient motion forecasting in a large-scale self-driving dataset as well as safer and more comfortable motion plans in long-term closed-loop simulations than current state-of-the-art models.
VideoClick: Video Object Segmentation with a Single Click
Jan 16, 2021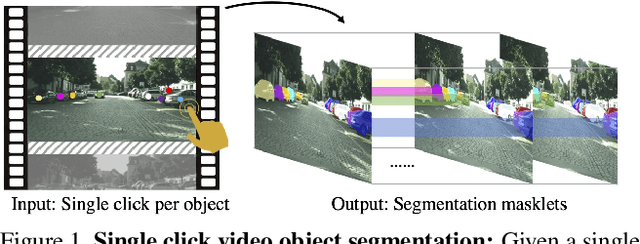


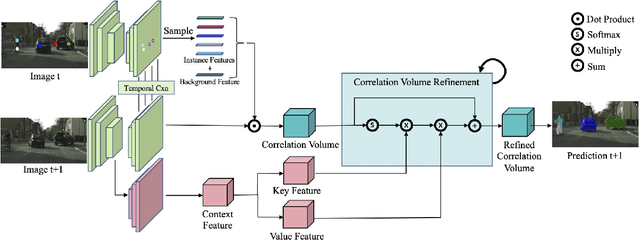
Annotating videos with object segmentation masks typically involves a two stage procedure of drawing polygons per object instance for all the frames and then linking them through time. While simple, this is a very tedious, time consuming and expensive process, making the creation of accurate annotations at scale only possible for well-funded labs. What if we were able to segment an object in the full video with only a single click? This will enable video segmentation at scale with a very low budget opening the door to many applications. Towards this goal, in this paper we propose a bottom up approach where given a single click for each object in a video, we obtain the segmentation masks of these objects in the full video. In particular, we construct a correlation volume that assigns each pixel in a target frame to either one of the objects in the reference frame or the background. We then refine this correlation volume via a recurrent attention module and decode the final segmentation. To evaluate the performance, we label the popular and challenging Cityscapes dataset with video object segmentations. Results on this new CityscapesVideo dataset show that our approach outperforms all the baselines in this challenging setting.