 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Remember from a Multi-Task Teacher
Oct 10, 2019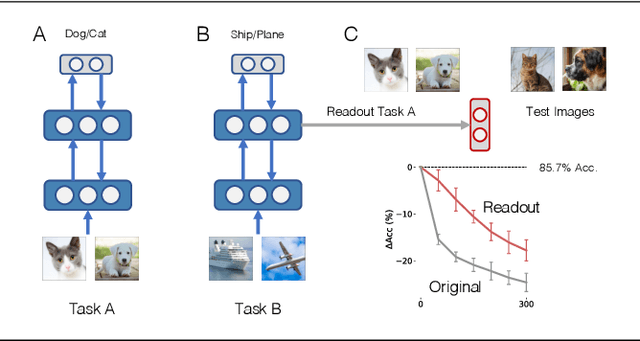
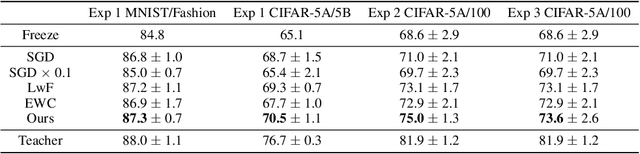
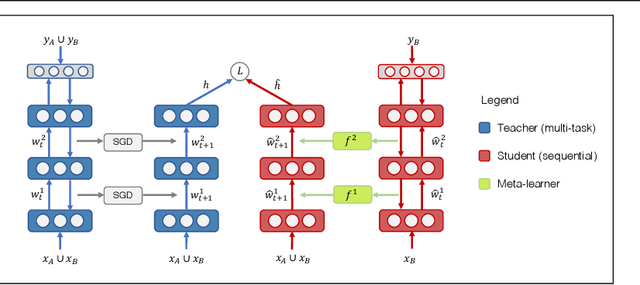
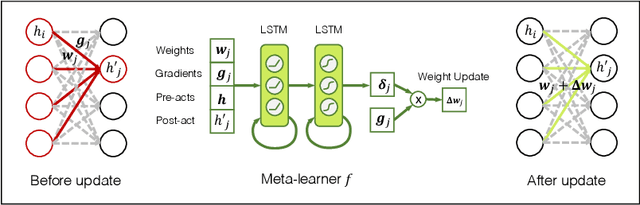
Recent studies on catastrophic forgetting during sequential learning typically focus on fixing the accuracy of the predictions for a previously learned task. In this paper we argue that the outputs of neural networks are subject to rapid changes when learning a new data distribution, and networks that appear to "forget" everything still contain useful representation towards previous tasks. Instead of enforcing the output accuracy to stay the same, we propose to reduce the effect of catastrophic forgetting on the representation level, as the output layer can be quickly recovered later with a small number of examples. Towards this goal, we propose an experimental setup that measures the amount of representational forgetting, and develop a novel meta-learning algorithm to overcome this issue. The proposed meta-learner produces weight updates of a sequential learning network, mimicking a multi-task teacher network's representation. We show that our meta-learner can improve its learned representations on new tasks, while maintaining a good representation for old tasks.
Jointly Learnable Behavior and Trajectory Planning for Self-Driving Vehicles
Oct 10, 2019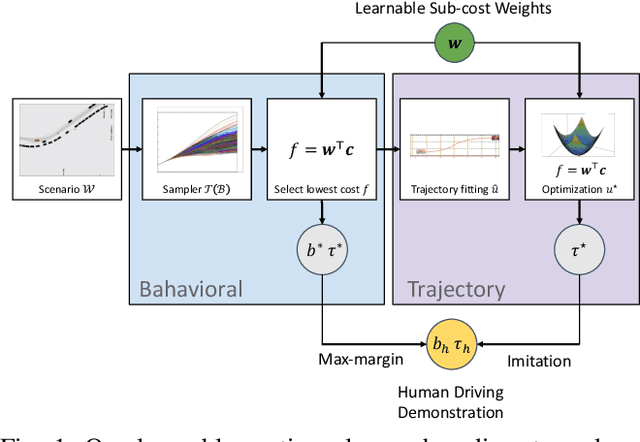
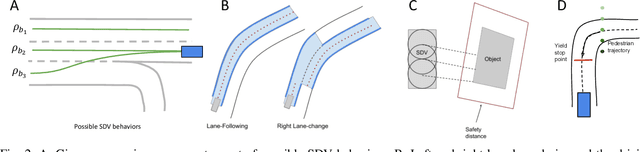
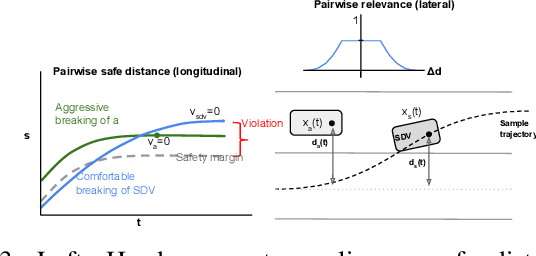

The motion planners used in self-driving vehicles need to generate trajectories that are safe, comfortable, and obey the traffic rules. This is usually achieved by two modules: behavior planner, which handles high-level decisions and produces a coarse trajectory, and trajectory planner that generates a smooth, feasible trajectory for the duration of the planning horizon. These planners, however, are typically developed separately, and changes in the behavior planner might affect the trajectory planner in unexpected ways. Furthermore, the final trajectory outputted by the trajectory planner might differ significantly from the one generated by the behavior planner, as they do not share the same objective. In this paper, we propose a jointly learnable behavior and trajectory planner. Unlike most existing learnable motion planners that address either only behavior planning, or use an uninterpretable neural network to represent the entire logic from sensors to driving commands, our approach features an interpretable cost function on top of perception, prediction and vehicle dynamics, and a joint learning algorithm that learns a shared cost function employed by our behavior and trajectory components. Experiments on real-world self-driving data demonstrate that jointly learned planner performs significantly better in terms of both similarity to human driving and other safety metrics, compared to baselines that do not adopt joint behavior and trajectory learning.
Efficient Graph Generation with Graph Recurrent Attention Networks
Oct 02, 2019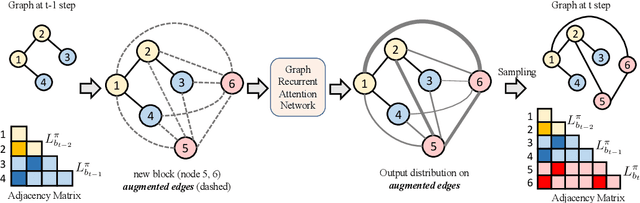
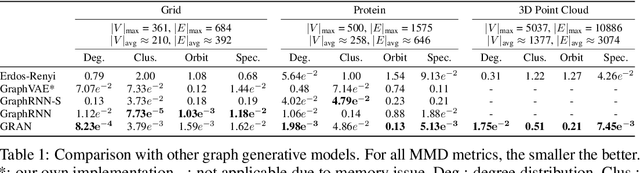
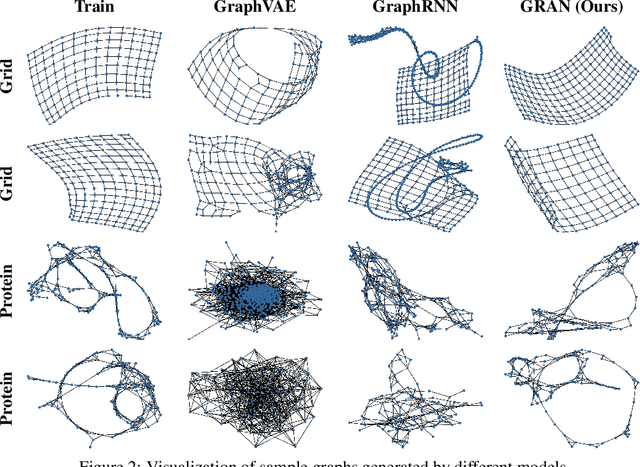
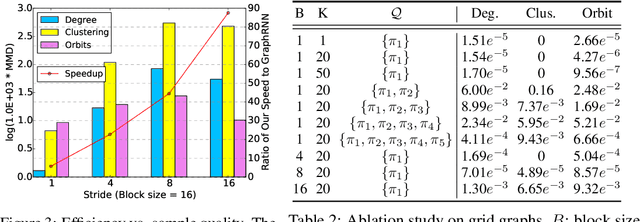
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time. The block size and sampling stride allow us to trade off sample quality for efficiency. Compared to previous RNN-based graph generative models, our framework better captures the auto-regressive conditioning between the already-generated and to-be-generated parts of the graph using Graph Neural Networks (GNNs) with attention. This not only reduces the dependency on node ordering but also bypasses the long-term bottleneck caused by the sequential nature of RNNs. Moreover, we parameterize the output distribution per block using a mixture of Bernoulli, which captures the correlations among generated edges within the block. Finally, we propose to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large graphs of up to 5K nodes with good quality. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size. Our code is released at: https://github.com/lrjconan/GRAN.
DMM-Net: Differentiable Mask-Matching Network for Video Object Segmentation
Sep 27, 2019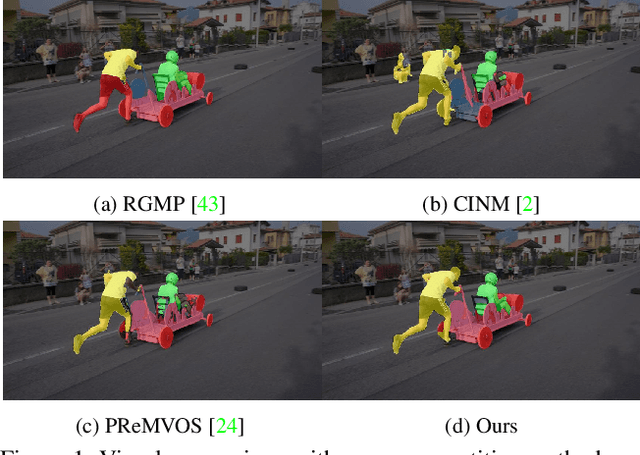
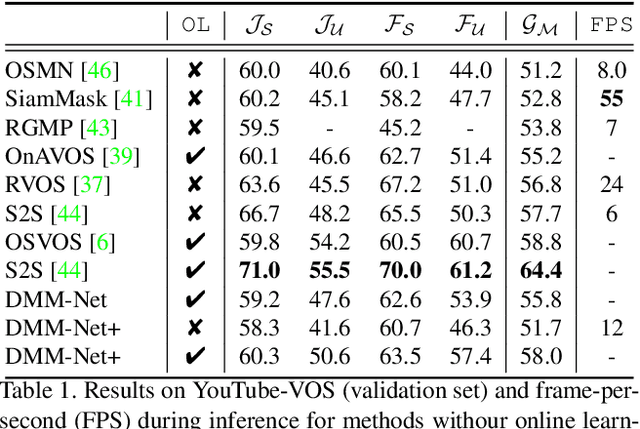
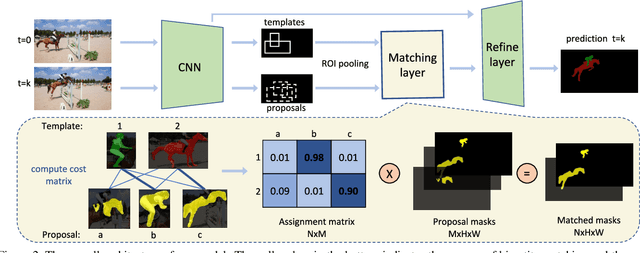
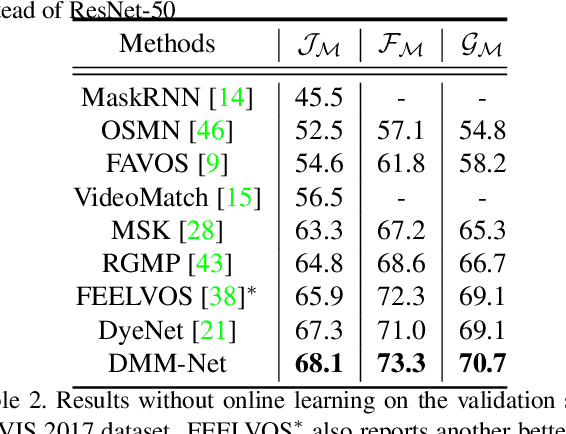
In this paper, we propose the differentiable mask-matching network (DMM-Net) for solving the video object segmentation problem where the initial object masks are provided. Relying on the Mask R-CNN backbone, we extract mask proposals per frame and formulate the matching between object templates and proposals at one time step as a linear assignment problem where the cost matrix is predicted by a CNN. We propose a differentiable matching layer by unrolling a projected gradient descent algorithm in which the projection exploits the Dykstra's algorithm. We prove that under mild conditions, the matching is guaranteed to converge to the optimum. In practice, it performs similarly to the Hungarian algorithm during inference. Meanwhile, we can back-propagate through it to learn the cost matrix. After matching, a refinement head is leveraged to improve the quality of the matched mask. Our DMM-Net achieves competitive results on the largest video object segmentation dataset YouTube-VOS. On DAVIS 2017, DMM-Net achieves the best performance without online learning on the first frames. Without any fine-tuning, DMM-Net performs comparably to state-of-the-art methods on SegTrack v2 dataset. At last, our matching layer is very simple to implement; we attach the PyTorch code ($<50$ lines) in the supplementary material. Our code is released at https://github.com/ZENGXH/DMM_Net.
DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch
Sep 12, 2019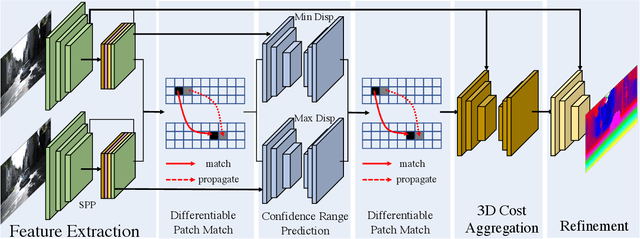

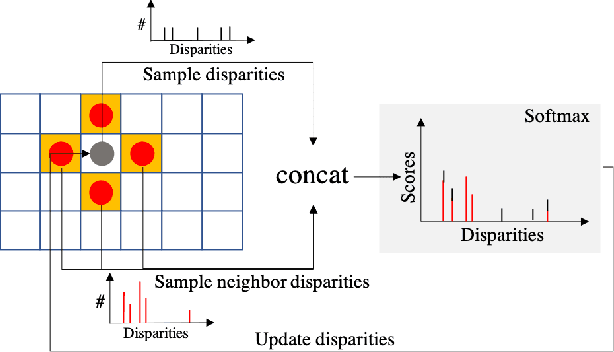
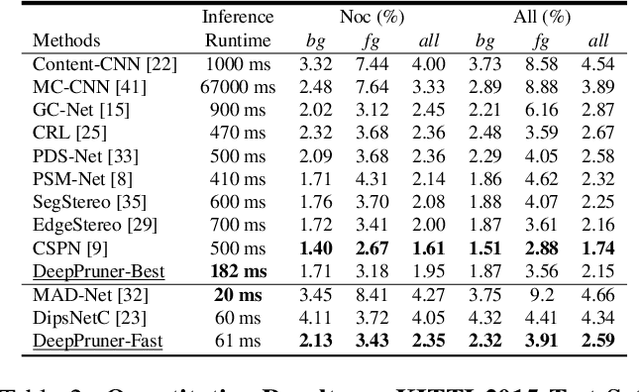
Our goal is to significantly speed up the runtime of current state-of-the-art stereo algorithms to enable real-time inference. Towards this goal, we developed a differentiable PatchMatch module that allows us to discard most disparities without requiring full cost volume evaluation. We then exploit this representation to learn which range to prune for each pixel. By progressively reducing the search space and effectively propagating such information, we are able to efficiently compute the cost volume for high likelihood hypotheses and achieve savings in both memory and computation. Finally, an image guided refinement module is exploited to further improve the performance. Since all our components are differentiable, the full network can be trained end-to-end. Our experiments show that our method achieves competitive results on KITTI and SceneFlow datasets while running in real-time at 62ms.
DSIC: Deep Stereo Image Compression
Aug 09, 2019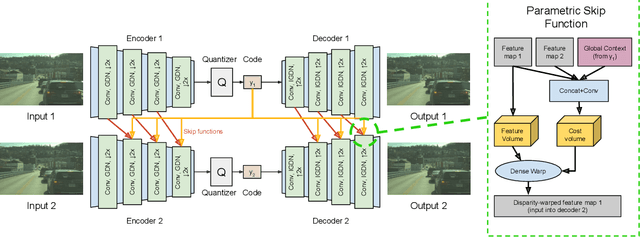
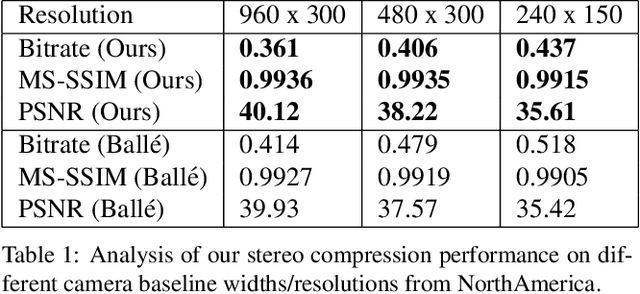
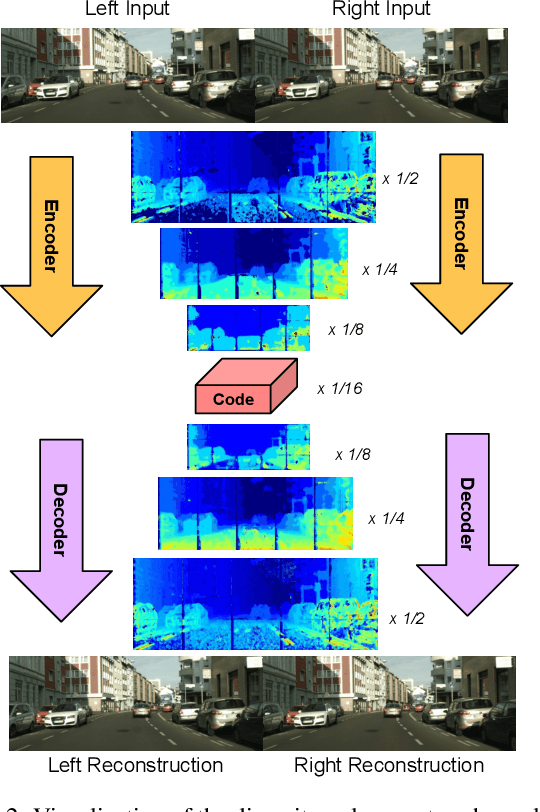
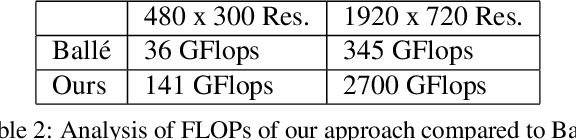
In this paper we tackle the problem of stereo image compression, and leverage the fact that the two images have overlapping fields of view to further compress the representations. Our approach leverages state-of-the-art single-image compression autoencoders and enhances the compression with novel parametric skip functions to feed fully differentiable, disparity-warped features at all levels to the encoder/decoder of the second image. Moreover, we model the probabilistic dependence between the image codes using a conditional entropy model. Our experiments show an impressive 30 - 50% reduction in the second image bitrate at low bitrates compared to deep single-image compression, and a 10 - 20% reduction at higher bitrates.
Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization
Aug 08, 2019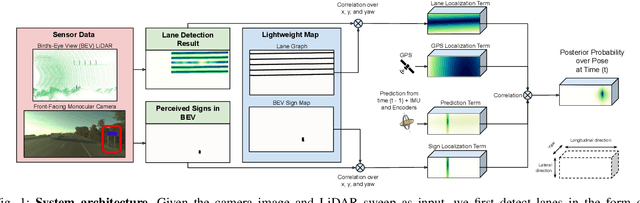
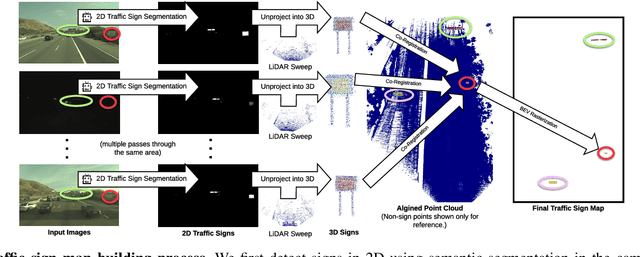

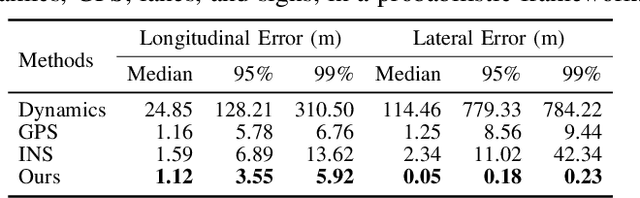
In this paper we propose a novel semantic localization algorithm that exploits multiple sensors and has precision on the order of a few centimeters. Our approach does not require detailed knowledge about the appearance of the world, and our maps require orders of magnitude less storage than maps utilized by traditional geometry- and LiDAR intensity-based localizers. This is important as self-driving cars need to operate in large environments. Towards this goal, we formulate the problem in a Bayesian filtering framework, and exploit lanes, traffic signs, as well as vehicle dynamics to localize robustly with respect to a sparse semantic map. We validate the effectiveness of our method on a new highway dataset consisting of 312km of roads. Our experiments show that the proposed approach is able to achieve 0.05m lateral accuracy and 1.12m longitudinal accuracy on average while taking up only 0.3% of the storage required by previous LiDAR intensity-based approaches.
Deformable Filter Convolution for Point Cloud Reasoning
Jul 30, 2019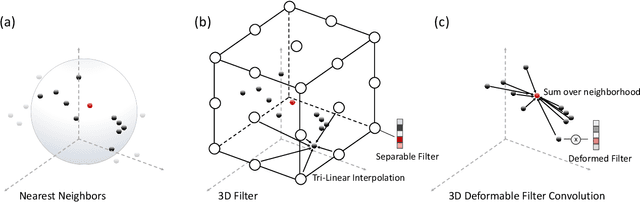
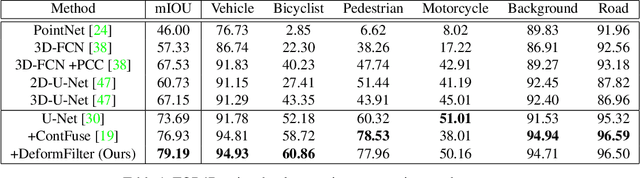
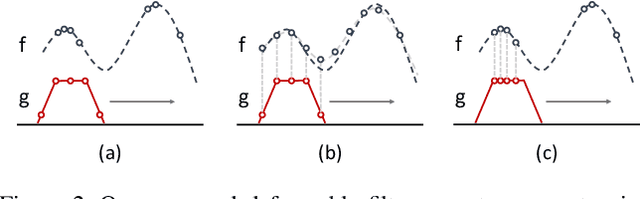
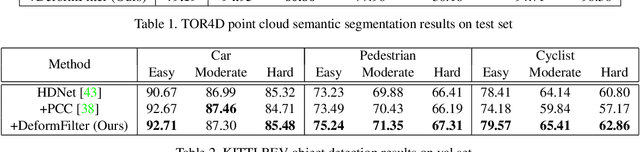
Point clouds are the native output of many real-world 3D sensors. To borrow the success of 2D convolutional network architectures, a majority of popular 3D perception models voxelize the points, which can result in a loss of local geometric details that cannot be recovered. In this paper, we propose a novel learnable convolution layer for processing 3D point cloud data directly. Instead of discretizing points into fixed voxels, we deform our learnable 3D filters to match with the point cloud shape. We propose to combine voxelized backbone networks with our deformable filter layer at 1) the network input stream and 2) the output prediction layers to enhance point level reasoning. We obtain state-of-the-art results on LiDAR semantic segmentation and producing a significant gain in performance on LiDAR object detection.
DARNet: Deep Active Ray Network for Building Segmentation
May 15, 2019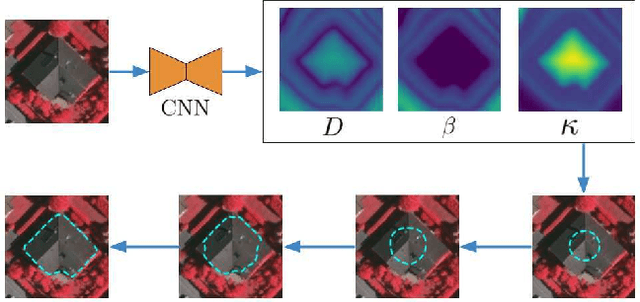

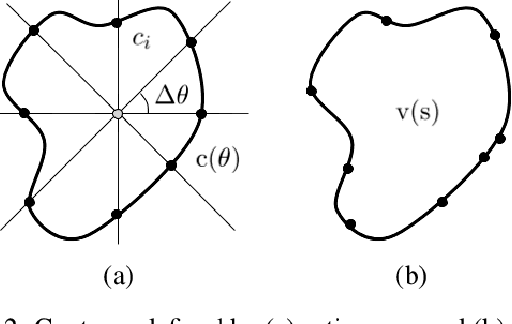
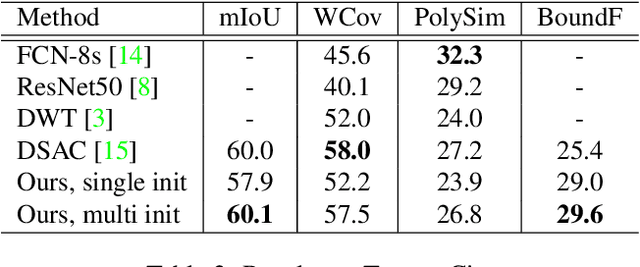
In this paper, we propose a Deep Active Ray Network (DARNet) for automatic building segmentation. Taking an image as input, it first exploits a deep convolutional neural network (CNN) as the backbone to predict energy maps, which are further utilized to construct an energy function. A polygon-based contour is then evolved via minimizing the energy function, of which the minimum defines the final segmentation. Instead of parameterizing the contour using Euclidean coordinates, we adopt polar coordinates, i.e., rays, which not only prevents self-intersection but also simplifies the design of the energy function. Moreover, we propose a loss function that directly encourages the contours to match building boundaries. Our DARNet is trained end-to-end by back-propagating through the energy minimization and the backbone CNN, which makes the CNN adapt to the dynamics of the contour evolution. Experiments on three building instance segmentation datasets demonstrate our DARNet achieves either state-of-the-art or comparable performances to other competitors.
Deep Multi-Sensor Lane Detection
May 04, 2019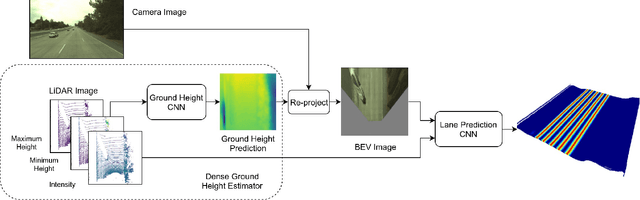

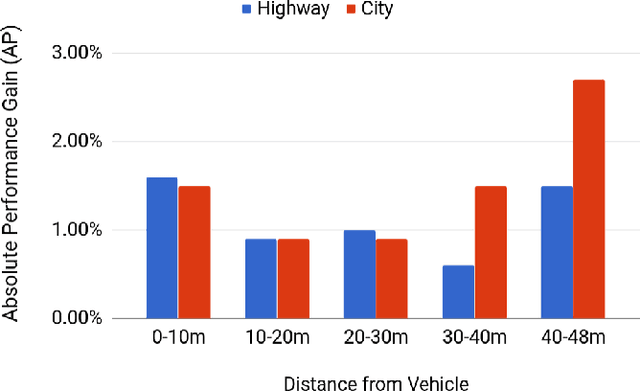
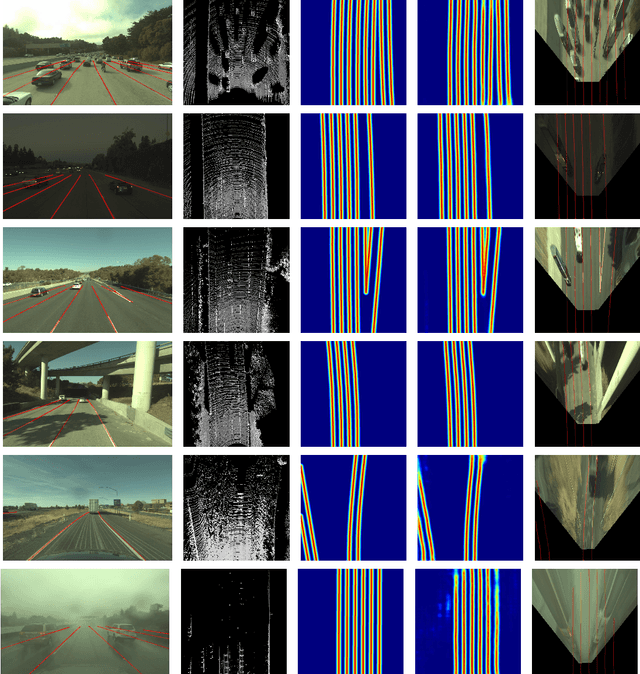
Reliable and accurate lane detection has been a long-standing problem in the field of autonomous driving. In recent years, many approaches have been developed that use images (or videos) as input and reason in image space. In this paper we argue that accurate image estimates do not translate to precise 3D lane boundaries, which are the input required by modern motion planning algorithms. To address this issue, we propose a novel deep neural network that takes advantage of both LiDAR and camera sensors and produces very accurate estimates directly in 3D space. We demonstrate the performance of our approach on both highways and in cities, and show very accurate estimates in complex scenarios such as heavy traffic (which produces occlusion), fork, merges and intersections.