 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need Curated Malicious Data for Safety Alignment in Multi-modal Large Language Models?
Apr 14, 2025Multi-modal large language models (MLLMs) have made significant progress, yet their safety alignment remains limited. Typically, current open-source MLLMs rely on the alignment inherited from their language module to avoid harmful generations. However, the lack of safety measures specifically designed for multi-modal inputs creates an alignment gap, leaving MLLMs vulnerable to vision-domain attacks such as typographic manipulation. Current methods utilize a carefully designed safety dataset to enhance model defense capability, while the specific knowledge or patterns acquired from the high-quality dataset remain unclear. Through comparison experiments, we find that the alignment gap primarily arises from data distribution biases, while image content, response quality, or the contrastive behavior of the dataset makes little contribution to boosting multi-modal safety. To further investigate this and identify the key factors in improving MLLM safety, we propose finetuning MLLMs on a small set of benign instruct-following data with responses replaced by simple, clear rejection sentences. Experiments show that, without the need for labor-intensive collection of high-quality malicious data, model safety can still be significantly improved, as long as a specific fraction of rejection data exists in the finetuning set, indicating the security alignment is not lost but rather obscured during multi-modal pretraining or instruction finetuning. Simply correcting the underlying data bias could narrow the safety gap in the vision domain.
ID-Cloak: Crafting Identity-Specific Cloaks Against Personalized Text-to-Image Generation
Feb 12, 2025Personalized text-to-image models allow users to generate images of new concepts from several reference photos, thereby leading to critical concerns regarding civil privacy. Although several anti-personalization techniques have been developed, these methods typically assume that defenders can afford to design a privacy cloak corresponding to each specific image. However, due to extensive personal images shared online, image-specific methods are limited by real-world practical applications. To address this issue, we are the first to investigate the creation of identity-specific cloaks (ID-Cloak) that safeguard all images belong to a specific identity. Specifically, we first model an identity subspace that preserves personal commonalities and learns diverse contexts to capture the image distribution to be protected. Then, we craft identity-specific cloaks with the proposed novel objective that encourages the cloak to guide the model away from its normal output within the subspace. Extensive experiments show that the generated universal cloak can effectively protect the images. We believe our method, along with the proposed identity-specific cloak setting, marks a notable advance in realistic privacy protection.
Survey on AI-Generated Media Detection: From Non-MLLM to MLLM
Feb 07, 2025The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.
InfoBFR: Real-World Blind Face Restoration via Information Bottleneck
Jan 26, 2025



Blind face restoration (BFR) is a highly challenging problem due to the uncertainty of data degradation patterns. Current BFR methods have realized certain restored productions but with inherent neural degradations that limit real-world generalization in complicated scenarios. In this paper, we propose a plug-and-play framework InfoBFR to tackle neural degradations, e.g., prior bias, topological distortion, textural distortion, and artifact residues, which achieves high-generalization face restoration in diverse wild and heterogeneous scenes. Specifically, based on the results from pre-trained BFR models, InfoBFR considers information compression using manifold information bottleneck (MIB) and information compensation with efficient diffusion LoRA to conduct information optimization. InfoBFR effectively synthesizes high-fidelity faces without attribute and identity distortions. Comprehensive experimental results demonstrate the superiority of InfoBFR over state-of-the-art GAN-based and diffusion-based BFR methods, with around 70ms consumption, 16M trainable parameters, and nearly 85% BFR-boosting. It is promising that InfoBFR will be the first plug-and-play restorer universally employed by diverse BFR models to conquer neural degradations.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024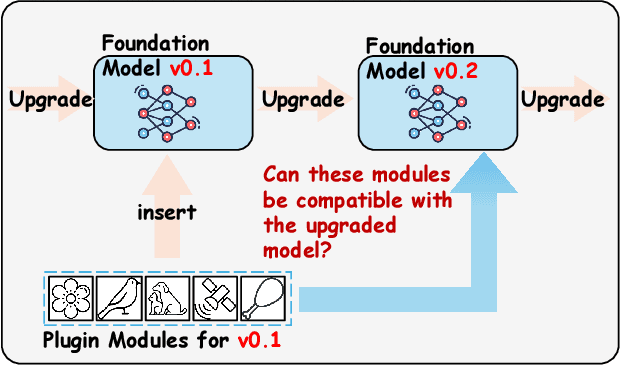
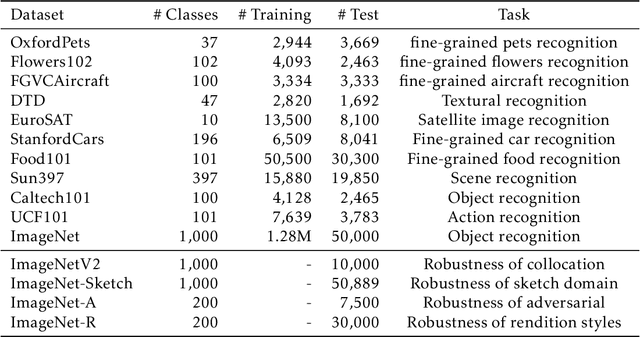
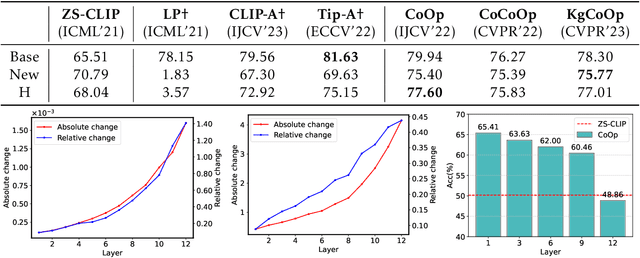
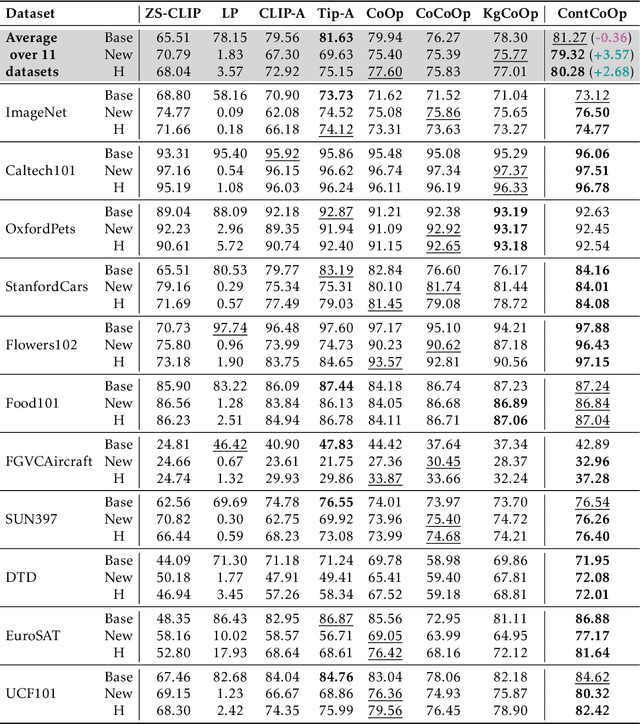
So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
Sample Correlation for Fingerprinting Deep Face Recognition
Dec 30, 2024Face recognition has witnessed remarkable advancements in recent years, thanks to the development of deep learning techniques.However, an off-the-shelf face recognition model as a commercial service could be stolen by model stealing attacks, posing great threats to the rights of the model owner.Model fingerprinting, as a model stealing detection method, aims to verify whether a suspect model is stolen from the victim model, gaining more and more attention nowadays.Previous methods always utilize transferable adversarial examples as the model fingerprint, but this method is known to be sensitive to adversarial defense and transfer learning techniques.To address this issue, we consider the pairwise relationship between samples instead and propose a novel yet simple model stealing detection method based on SAmple Correlation (SAC).Specifically, we present SAC-JC that selects JPEG compressed samples as model inputs and calculates the correlation matrix among their model outputs.Extensive results validate that SAC successfully defends against various model stealing attacks in deep face recognition, encompassing face verification and face emotion recognition, exhibiting the highest performance in terms of AUC, p-value and F1 score.Furthermore, we extend our evaluation of SAC-JC to object recognition datasets including Tiny-ImageNet and CIFAR10, which also demonstrates the superior performance of SAC-JC to previous methods.The code will be available at \url{https://github.com/guanjiyang/SAC_JC}.
Prototypical Distillation and Debiased Tuning for Black-box Unsupervised Domain Adaptation
Dec 30, 2024



Unsupervised domain adaptation aims to transfer knowledge from a related, label-rich source domain to an unlabeled target domain, thereby circumventing the high costs associated with manual annotation. Recently, there has been growing interest in source-free domain adaptation, a paradigm in which only a pre-trained model, rather than the labeled source data, is provided to the target domain. Given the potential risk of source data leakage via model inversion attacks, this paper introduces a novel setting called black-box domain adaptation, where the source model is accessible only through an API that provides the predicted label along with the corresponding confidence value for each query. We develop a two-step framework named $\textbf{Pro}$totypical $\textbf{D}$istillation and $\textbf{D}$ebiased tun$\textbf{ing}$ ($\textbf{ProDDing}$). In the first step, ProDDing leverages both the raw predictions from the source model and prototypes derived from the target domain as teachers to distill a customized target model. In the second step, ProDDing keeps fine-tuning the distilled model by penalizing logits that are biased toward certain classes. Empirical results across multiple benchmarks demonstrate that ProDDing outperforms existing black-box domain adaptation methods. Moreover, in the case of hard-label black-box domain adaptation, where only predicted labels are available, ProDDing achieves significant improvements over these methods. Code will be available at \url{https://github.com/tim-learn/ProDDing/}.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
MME-Survey: A Comprehensive Survey on Evaluation of Multimodal LLMs
Nov 22, 2024



As a prominent direction of Artificial General Intelligence (AGI), Multimodal Large Language Models (MLLMs) have garnered increased attention from both industry and academia. Building upon pre-trained LLMs, this family of models further develops multimodal perception and reasoning capabilities that are impressive, such as writing code given a flow chart or creating stories based on an image. In the development process, evaluation is critical since it provides intuitive feedback and guidance on improving models. Distinct from the traditional train-eval-test paradigm that only favors a single task like image classification, the versatility of MLLMs has spurred the rise of various new benchmarks and evaluation methods. In this paper, we aim to present a comprehensive survey of MLLM evaluation, discussing four key aspects: 1) the summarised benchmarks types divided by the evaluation capabilities, including foundation capabilities, model self-analysis, and extented applications; 2) the typical process of benchmark counstruction, consisting of data collection, annotation, and precautions; 3) the systematic evaluation manner composed of judge, metric, and toolkit; 4) the outlook for the next benchmark. This work aims to offer researchers an easy grasp of how to effectively evaluate MLLMs according to different needs and to inspire better evaluation methods, thereby driving the progress of MLLM research.