 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBipedalism for Quadrupedal Robots: Versatile Loco-Manipulation through Risk-Adaptive Reinforcement Learning
Jul 27, 2025Loco-manipulation of quadrupedal robots has broadened robotic applications, but using legs as manipulators often compromises locomotion, while mounting arms complicates the system. To mitigate this issue, we introduce bipedalism for quadrupedal robots, thus freeing the front legs for versatile interactions with the environment. We propose a risk-adaptive distributional Reinforcement Learning (RL) framework designed for quadrupedal robots walking on their hind legs, balancing worst-case conservativeness with optimal performance in this inherently unstable task. During training, the adaptive risk preference is dynamically adjusted based on the uncertainty of the return, measured by the coefficient of variation of the estimated return distribution. Extensive experiments in simulation show our method's superior performance over baselines. Real-world deployment on a Unitree Go2 robot further demonstrates the versatility of our policy, enabling tasks like cart pushing, obstacle probing, and payload transport, while showcasing robustness against challenging dynamics and external disturbances.
LLMPhy: Complex Physical Reasoning Using Large Language Models and World Models
Nov 12, 2024Physical reasoning is an important skill needed for robotic agents when operating in the real world. However, solving such reasoning problems often involves hypothesizing and reflecting over complex multi-body interactions under the effect of a multitude of physical forces and thus learning all such interactions poses a significant hurdle for state-of-the-art machine learning frameworks, including large language models (LLMs). To study this problem, we propose a new physical reasoning task and a dataset, dubbed TraySim. Our task involves predicting the dynamics of several objects on a tray that is given an external impact -- the domino effect of the ensued object interactions and their dynamics thus offering a challenging yet controlled setup, with the goal of reasoning being to infer the stability of the objects after the impact. To solve this complex physical reasoning task, we present LLMPhy, a zero-shot black-box optimization framework that leverages the physics knowledge and program synthesis abilities of LLMs, and synergizes these abilities with the world models built into modern physics engines. Specifically, LLMPhy uses an LLM to generate code to iteratively estimate the physical hyperparameters of the system (friction, damping, layout, etc.) via an implicit analysis-by-synthesis approach using a (non-differentiable) simulator in the loop and uses the inferred parameters to imagine the dynamics of the scene towards solving the reasoning task. To show the effectiveness of LLMPhy, we present experiments on our TraySim dataset to predict the steady-state poses of the objects. Our results show that the combination of the LLM and the physics engine leads to state-of-the-art zero-shot physical reasoning performance, while demonstrating superior convergence against standard black-box optimization methods and better estimation of the physical parameters.
Autonomous Robotic Assembly: From Part Singulation to Precise Assembly
Jun 11, 2024



Imagine a robot that can assemble a functional product from the individual parts presented in any configuration to the robot. Designing such a robotic system is a complex problem which presents several open challenges. To bypass these challenges, the current generation of assembly systems is built with a lot of system integration effort to provide the structure and precision necessary for assembly. These systems are mostly responsible for part singulation, part kitting, and part detection, which is accomplished by intelligent system design. In this paper, we present autonomous assembly of a gear box with minimum requirements on structure. The assembly parts are randomly placed in a two-dimensional work environment for the robot. The proposed system makes use of several different manipulation skills such as sliding for grasping, in-hand manipulation, and insertion to assemble the gear box. All these tasks are run in a closed-loop fashion using vision, tactile, and Force-Torque (F/T) sensors. We perform extensive hardware experiments to show the robustness of the proposed methods as well as the overall system. See supplementary video at https://www.youtube.com/watch?v=cZ9M1DQ23OI.
Generalize by Touching: Tactile Ensemble Skill Transfer for Robotic Furniture Assembly
Apr 26, 2024Furniture assembly remains an unsolved problem in robotic manipulation due to its long task horizon and nongeneralizable operations plan. This paper presents the Tactile Ensemble Skill Transfer (TEST) framework, a pioneering offline reinforcement learning (RL) approach that incorporates tactile feedback in the control loop. TEST's core design is to learn a skill transition model for high-level planning, along with a set of adaptive intra-skill goal-reaching policies. Such design aims to solve the robotic furniture assembly problem in a more generalizable way, facilitating seamless chaining of skills for this long-horizon task. We first sample demonstration from a set of heuristic policies and trajectories consisting of a set of randomized sub-skill segments, enabling the acquisition of rich robot trajectories that capture skill stages, robot states, visual indicators, and crucially, tactile signals. Leveraging these trajectories, our offline RL method discerns skill termination conditions and coordinates skill transitions. Our evaluations highlight the proficiency of TEST on the in-distribution furniture assemblies, its adaptability to unseen furniture configurations, and its robustness against visual disturbances. Ablation studies further accentuate the pivotal role of two algorithmic components: the skill transition model and tactile ensemble policies. Results indicate that TEST can achieve a success rate of 90\% and is over 4 times more efficient than the heuristic policy in both in-distribution and generalization settings, suggesting a scalable skill transfer approach for contact-rich manipulation.
Interactive Planning Using Large Language Models for Partially Observable Robotics Tasks
Dec 11, 2023



Designing robotic agents to perform open vocabulary tasks has been the long-standing goal in robotics and AI. Recently, Large Language Models (LLMs) have achieved impressive results in creating robotic agents for performing open vocabulary tasks. However, planning for these tasks in the presence of uncertainties is challenging as it requires \enquote{chain-of-thought} reasoning, aggregating information from the environment, updating state estimates, and generating actions based on the updated state estimates. In this paper, we present an interactive planning technique for partially observable tasks using LLMs. In the proposed method, an LLM is used to collect missing information from the environment using a robot and infer the state of the underlying problem from collected observations while guiding the robot to perform the required actions. We also use a fine-tuned Llama 2 model via self-instruct and compare its performance against a pre-trained LLM like GPT-4. Results are demonstrated on several tasks in simulation as well as real-world environments. A video describing our work along with some results could be found here.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023



To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
Constrained Dynamic Movement Primitives for Safe Learning of Motor Skills
Sep 28, 2022
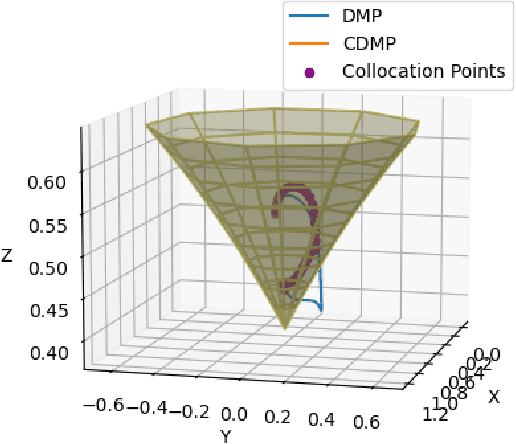
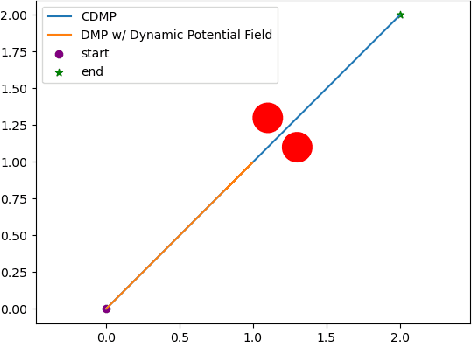
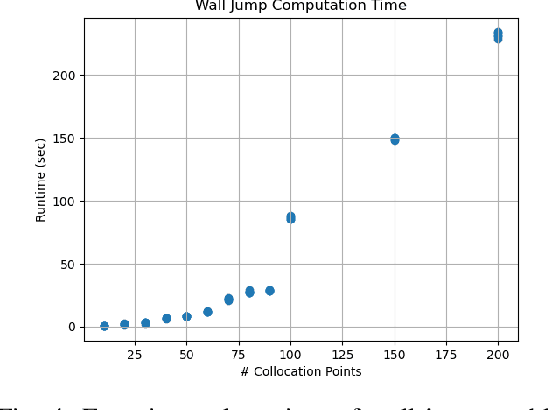
Dynamic movement primitives are widely used for learning skills which can be demonstrated to a robot by a skilled human or controller. While their generalization capabilities and simple formulation make them very appealing to use, they possess no strong guarantees to satisfy operational safety constraints for a task. In this paper, we present constrained dynamic movement primitives (CDMP) which can allow for constraint satisfaction in the robot workspace. We present a formulation of a non-linear optimization to perturb the DMP forcing weights regressed by locally-weighted regression to admit a Zeroing Barrier Function (ZBF), which certifies workspace constraint satisfaction. We demonstrate the proposed CDMP under different constraints on the end-effector movement such as obstacle avoidance and workspace constraints on a physical robot. A video showing the implementation of the proposed algorithm using different manipulators in different environments could be found here https://youtu.be/hJegJJkJfys.
Lyapunov Robust Constrained-MDPs: Soft-Constrained Robustly Stable Policy Optimization under Model Uncertainty
Aug 05, 2021Safety and robustness are two desired properties for any reinforcement learning algorithm. CMDPs can handle additional safety constraints and RMDPs can perform well under model uncertainties. In this paper, we propose to unite these two frameworks resulting in robust constrained MDPs (RCMDPs). The motivation is to develop a framework that can satisfy safety constraints while also simultaneously offer robustness to model uncertainties. We develop the RCMDP objective, derive gradient update formula to optimize this objective and then propose policy gradient based algorithms. We also independently propose Lyapunov based reward shaping for RCMDPs, yielding better stability and convergence properties.
Tuning-Free Contact-Implicit Trajectory Optimization
Jun 11, 2020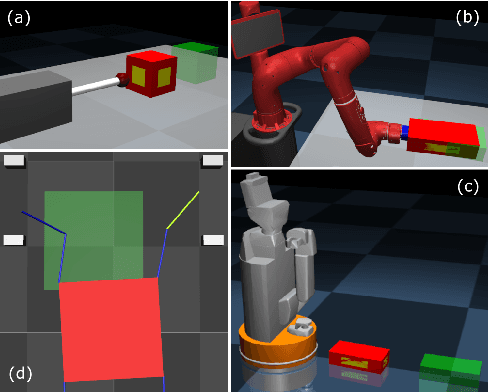
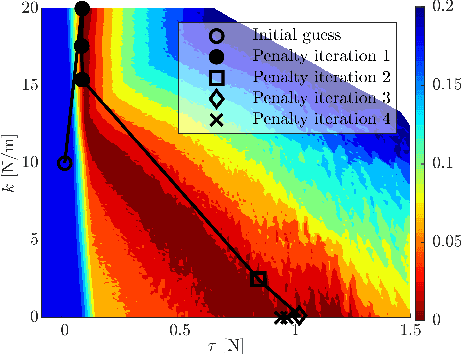
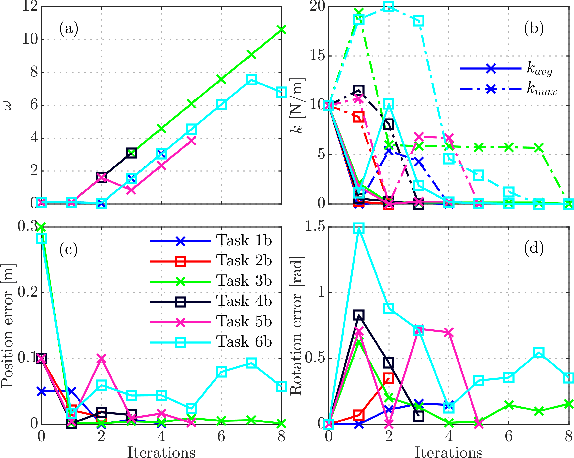
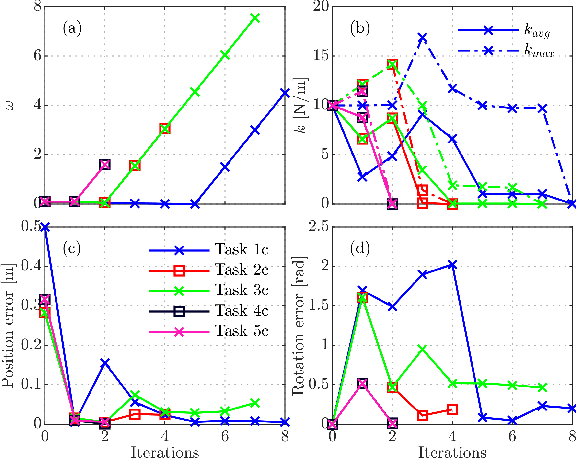
We present a contact-implicit trajectory optimization framework that can plan contact-interaction trajectories for different robot architectures and tasks using a trivial initial guess and without requiring any parameter tuning. This is achieved by using a relaxed contact model along with an automatic penalty adjustment loop for suppressing the relaxation. Moreover, the structure of the problem enables us to exploit the contact information implied by the use of relaxation in the previous iteration, such that the solution is explicitly improved with little computational overhead. We test the proposed approach in simulation experiments for non-prehensile manipulation using a 7-DOF arm and a mobile robot and for planar locomotion using a humanoid-like robot in zero gravity. The results demonstrate that our method provides an out-of-the-box solution with good performance for a wide range of applications.