 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Predicates and Actions Enables Zero-Shot Skill Composition
May 20, 2026Learning from Demonstration (LfD) enables robots to learn complex behaviors from expert examples, yet existing approaches often fail to generalize to new compositions of known skills without retraining. Modern generative policies model distributions over action trajectories alone, thus are unable to reason about the symbolic outcomes required for robust composition. We propose that skills should jointly model action trajectories and the symbolic outcomes they induce. To address this gap, we introduce Predicate Action Skills (PACTS), a class of closed-loop visuomotor policies that model skills as a joint generative process over action and predicate belief trajectories, producing coherent action-outcome rollouts within a single model. Jointly generating actions and predicates enables PACTS to learn internal representations that improve both action generation and predicate classification. Furthermore, we demonstrate zero-shot composition of learned skills via planning by leveraging online predicate predictions from PACTS as a symbolic interface for sequencing and monitoring execution. Project website: https://planpacts.github.io/
JAXenstein: Accelerated Benchmarking for First-Person Environments
May 19, 2026The progression of reinforcement learning algorithms have been driven by challenging benchmarks. The rate in which a researcher can iterate on a problem setting directly impacts the speed of algorithm development. Modern machine learning has produced tools that allow for fast and scalable algorithm development like the JAX library. With the availability of these tools, a serious bottleneck in algorithm development is the availability of large and complex domains for experimentation. Most notably, the JAX reinforcement learning ecosystem does not have any benchmarks that test visual first-person tasks; these domains are crucial for testing both exploration and an agent's ability to overcome partial observability. We introduce JAXenstein: an open-source JAX-based benchmark that implements the Wolfenstein 3D rendering engine for fast and scalable experimentation in visual first-person tasks. JAXenstein is several times faster than comparable vision-based benchmarks, and is easily extensible to more complex first-person domains.
Learning Equivariant Neural-Augmented Object Dynamics From Few Interactions
May 04, 2026Learning data-efficient object dynamics models for robotic manipulation remains challenging, especially for deformable objects. A popular approach is to model objects as sets of 3D particles and learn their motion using graph neural networks. In practice, this is not enough to maintain physical feasibility over long horizons and may require large amounts of interaction data to learn. We introduce PIEGraph, a novel approach to combining analytical physics and data-driven models to capture object dynamics for both rigid and deformable bodies using limited real-world interaction data. PIEGraph consists of two components: (1) a \textbf{P}hysically \textbf{I}nformed particle-based analytical model (implemented as a spring--mass system) to enforce physically feasible motion, and (2) an \textbf{E}quivariant \textbf{Graph} Neural Network with a novel action representation that exploits symmetries in particle interactions to guide the analytical model. We evaluate PIEGraph in simulation and on robot hardware for reorientation and repositioning tasks with ropes, cloth, stuffed animals and rigid objects. We show that our method enables accurate dynamics prediction and reliable downstream robotic manipulation planning, which outperforms state of the art baselines.
NovaPlan: Zero-Shot Long-Horizon Manipulation via Closed-Loop Video Language Planning
Feb 23, 2026Solving long-horizon tasks requires robots to integrate high-level semantic reasoning with low-level physical interaction. While vision-language models (VLMs) and video generation models can decompose tasks and imagine outcomes, they often lack the physical grounding necessary for real-world execution. We introduce NovaPlan, a hierarchical framework that unifies closed-loop VLM and video planning with geometrically grounded robot execution for zero-shot long-horizon manipulation. At the high level, a VLM planner decomposes tasks into sub-goals and monitors robot execution in a closed loop, enabling the system to recover from single-step failures through autonomous re-planning. To compute low-level robot actions, we extract and utilize both task-relevant object keypoints and human hand poses as kinematic priors from the generated videos, and employ a switching mechanism to choose the better one as a reference for robot actions, maintaining stable execution even under heavy occlusion or depth inaccuracy. We demonstrate the effectiveness of NovaPlan on three long-horizon tasks and the Functional Manipulation Benchmark (FMB). Our results show that NovaPlan can perform complex assembly tasks and exhibit dexterous error recovery behaviors without any prior demonstrations or training. Project page: https://nova-plan.github.io/
Effective Task Planning with Missing Objects using Learning-Informed Object Search
Feb 13, 2026Task planning for mobile robots often assumes full environment knowledge and so popular approaches, like planning via the PDDL, cannot plan when the locations of task-critical objects are unknown. Recent learning-driven object search approaches are effective, but operate as standalone tools and so are not straightforwardly incorporated into full task planners, which must additionally determine both what objects are necessary and when in the plan they should be sought out. To address this limitation, we develop a planning framework centered around novel model-based LIOS actions: each a policy that aims to find and retrieve a single object. High-level planning treats LIOS actions as deterministic and so -- informed by model-based calculations of the expected cost of each -- generates plans that interleave search and execution for effective, sound, and complete learning-informed task planning despite uncertainty. Our work effectively reasons about uncertainty while maintaining compatibility with existing full-knowledge solvers. In simulated ProcTHOR homes and in the real world, our approach outperforms non-learned and learned baselines on tasks including retrieval and meal prep.
Hierarchical Entity-centric Reinforcement Learning with Factored Subgoal Diffusion
Feb 02, 2026We propose a hierarchical entity-centric framework for offline Goal-Conditioned Reinforcement Learning (GCRL) that combines subgoal decomposition with factored structure to solve long-horizon tasks in domains with multiple entities. Achieving long-horizon goals in complex environments remains a core challenge in Reinforcement Learning (RL). Domains with multiple entities are particularly difficult due to their combinatorial complexity. GCRL facilitates generalization across goals and the use of subgoal structure, but struggles with high-dimensional observations and combinatorial state-spaces, especially under sparse reward. We employ a two-level hierarchy composed of a value-based GCRL agent and a factored subgoal-generating conditional diffusion model. The RL agent and subgoal generator are trained independently and composed post hoc through selective subgoal generation based on the value function, making the approach modular and compatible with existing GCRL algorithms. We introduce new variations to benchmark tasks that highlight the challenges of multi-entity domains, and show that our method consistently boosts performance of the underlying RL agent on image-based long-horizon tasks with sparse rewards, achieving over 150% higher success rates on the hardest task in our suite and generalizing to increasing horizons and numbers of entities. Rollout videos are provided at: https://sites.google.com/view/hecrl
NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
Oct 09, 2025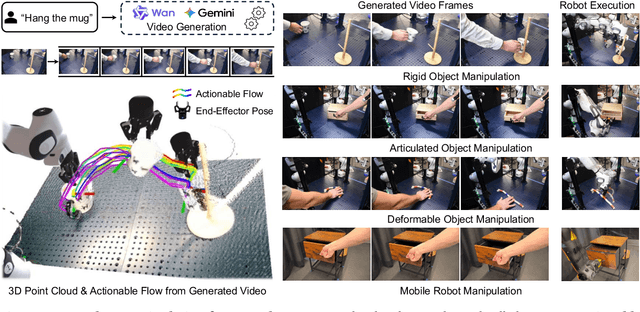
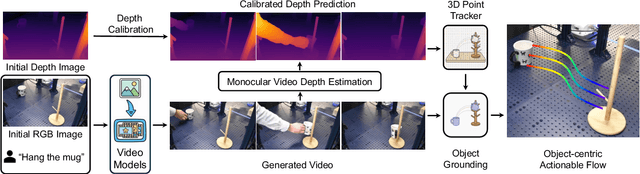


Enabling robots to execute novel manipulation tasks zero-shot is a central goal in robotics. Most existing methods assume in-distribution tasks or rely on fine-tuning with embodiment-matched data, limiting transfer across platforms. We present NovaFlow, an autonomous manipulation framework that converts a task description into an actionable plan for a target robot without any demonstrations. Given a task description, NovaFlow synthesizes a video using a video generation model and distills it into 3D actionable object flow using off-the-shelf perception modules. From the object flow, it computes relative poses for rigid objects and realizes them as robot actions via grasp proposals and trajectory optimization. For deformable objects, this flow serves as a tracking objective for model-based planning with a particle-based dynamics model. By decoupling task understanding from low-level control, NovaFlow naturally transfers across embodiments. We validate on rigid, articulated, and deformable object manipulation tasks using a table-top Franka arm and a Spot quadrupedal mobile robot, and achieve effective zero-shot execution without demonstrations or embodiment-specific training. Project website: https://novaflow.lhy.xyz/.
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
Sep 26, 2025

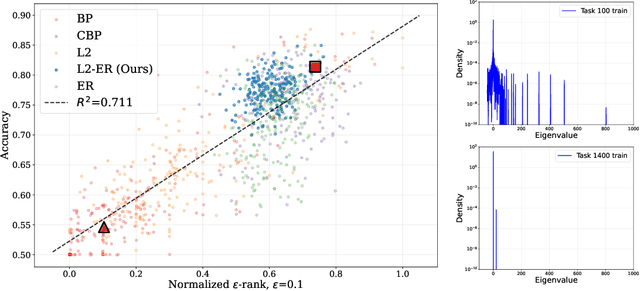

We investigate why deep neural networks suffer from \emph{loss of plasticity} in deep continual learning, failing to learn new tasks without reinitializing parameters. We show that this failure is preceded by Hessian spectral collapse at new-task initialization, where meaningful curvature directions vanish and gradient descent becomes ineffective. To characterize the necessary condition for successful training, we introduce the notion of $\tau$-trainability and show that current plasticity preserving algorithms can be unified under this framework. Targeting spectral collapse directly, we then discuss the Kronecker factored approximation of the Hessian, which motivates two regularization enhancements: maintaining high effective feature rank and applying $L2$ penalties. Experiments on continual supervised and reinforcement learning tasks confirm that combining these two regularizers effectively preserves plasticity.
Benchmarking Partial Observability in Reinforcement Learning with a Suite of Memory-Improvable Domains
Jul 31, 2025Mitigating partial observability is a necessary but challenging task for general reinforcement learning algorithms. To improve an algorithm's ability to mitigate partial observability, researchers need comprehensive benchmarks to gauge progress. Most algorithms tackling partial observability are only evaluated on benchmarks with simple forms of state aliasing, such as feature masking and Gaussian noise. Such benchmarks do not represent the many forms of partial observability seen in real domains, like visual occlusion or unknown opponent intent. We argue that a partially observable benchmark should have two key properties. The first is coverage in its forms of partial observability, to ensure an algorithm's generalizability. The second is a large gap between the performance of a agents with more or less state information, all other factors roughly equal. This gap implies that an environment is memory improvable: where performance gains in a domain are from an algorithm's ability to cope with partial observability as opposed to other factors. We introduce best-practice guidelines for empirically benchmarking reinforcement learning under partial observability, as well as the open-source library POBAX: Partially Observable Benchmarks in JAX. We characterize the types of partial observability present in various environments and select representative environments for our benchmark. These environments include localization and mapping, visual control, games, and more. Additionally, we show that these tasks are all memory improvable and require hard-to-learn memory functions, providing a concrete signal for partial observability research. This framework includes recommended hyperparameters as well as algorithm implementations for fast, out-of-the-box evaluation, as well as highly performant environments implemented in JAX for GPU-scalable experimentation.
Geometry of Neural Reinforcement Learning in Continuous State and Action Spaces
Jul 28, 2025



Advances in reinforcement learning (RL) have led to its successful application in complex tasks with continuous state and action spaces. Despite these advances in practice, most theoretical work pertains to finite state and action spaces. We propose building a theoretical understanding of continuous state and action spaces by employing a geometric lens to understand the locally attained set of states. The set of all parametrised policies learnt through a semi-gradient based approach induces a set of attainable states in RL. We show that the training dynamics of a two-layer neural policy induce a low dimensional manifold of attainable states embedded in the high-dimensional nominal state space trained using an actor-critic algorithm. We prove that, under certain conditions, the dimensionality of this manifold is of the order of the dimensionality of the action space. This is the first result of its kind, linking the geometry of the state space to the dimensionality of the action space. We empirically corroborate this upper bound for four MuJoCo environments and also demonstrate the results in a toy environment with varying dimensionality. We also show the applicability of this theoretical result by introducing a local manifold learning layer to the policy and value function networks to improve the performance in control environments with very high degrees of freedom by changing one layer of the neural network to learn sparse representations.