 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQing Zhang
A Hybrid Video Anomaly Detection Framework via Memory-Augmented Flow Reconstruction and Flow-Guided Frame Prediction
Aug 16, 2021
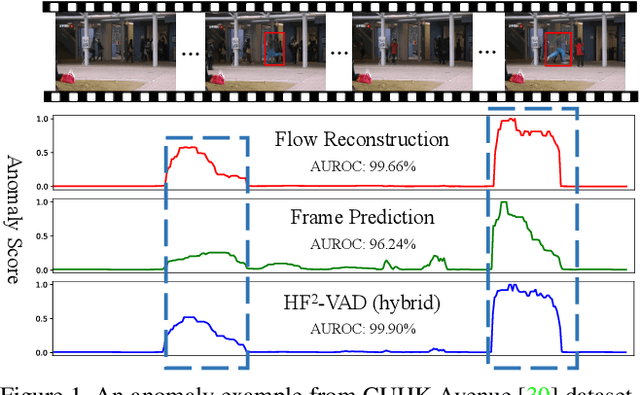
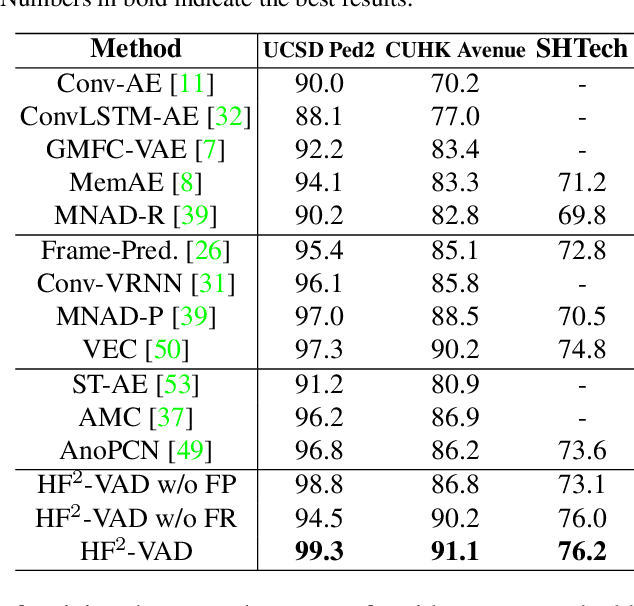
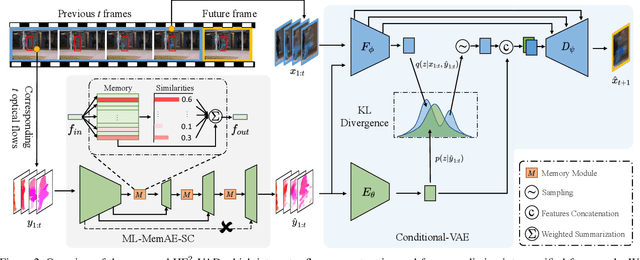
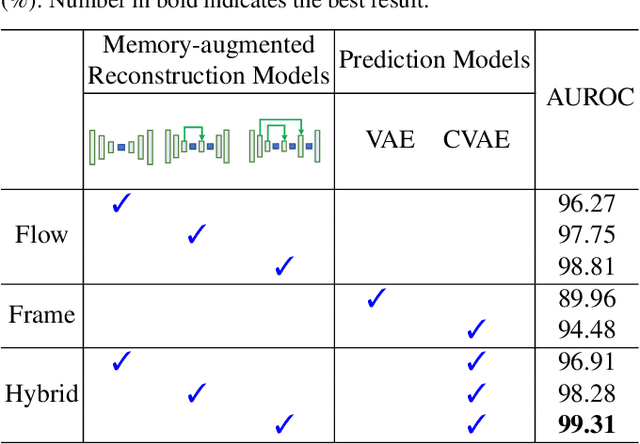
In this paper, we propose $\text{HF}^2$-VAD, a Hybrid framework that integrates Flow reconstruction and Frame prediction seamlessly to handle Video Anomaly Detection. Firstly, we design the network of ML-MemAE-SC (Multi-Level Memory modules in an Autoencoder with Skip Connections) to memorize normal patterns for optical flow reconstruction so that abnormal events can be sensitively identified with larger flow reconstruction errors. More importantly, conditioned on the reconstructed flows, we then employ a Conditional Variational Autoencoder (CVAE), which captures the high correlation between video frame and optical flow, to predict the next frame given several previous frames. By CVAE, the quality of flow reconstruction essentially influences that of frame prediction. Therefore, poorly reconstructed optical flows of abnormal events further deteriorate the quality of the final predicted future frame, making the anomalies more detectable. Experimental results demonstrate the effectiveness of the proposed method. Code is available at \href{https://github.com/LiUzHiAn/hf2vad}{https://github.com/LiUzHiAn/hf2vad}.
From Synthetic to Real: Image Dehazing Collaborating with Unlabeled Real Data
Aug 06, 2021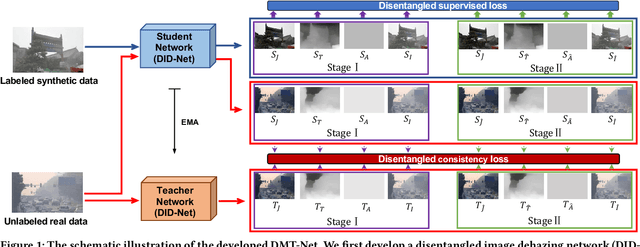
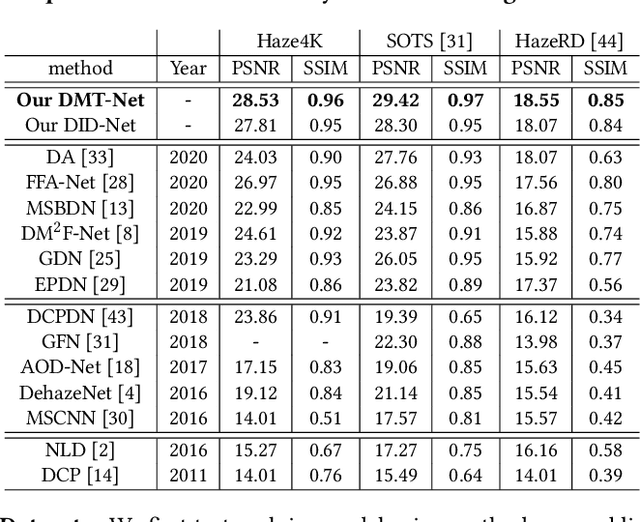
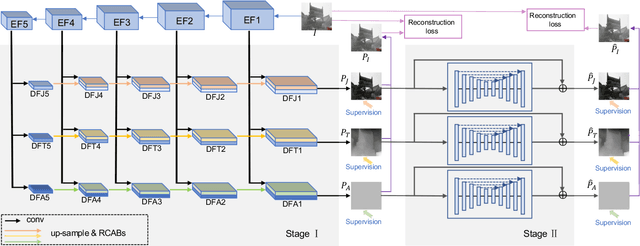
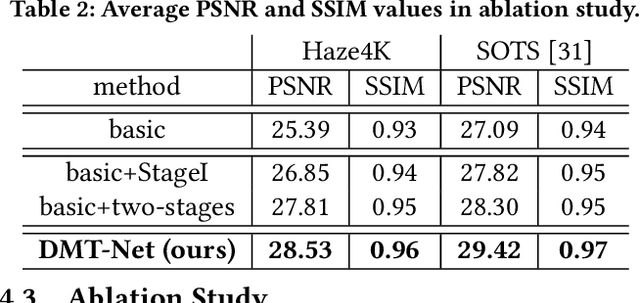
Single image dehazing is a challenging task, for which the domain shift between synthetic training data and real-world testing images usually leads to degradation of existing methods. To address this issue, we propose a novel image dehazing framework collaborating with unlabeled real data. First, we develop a disentangled image dehazing network (DID-Net), which disentangles the feature representations into three component maps, i.e. the latent haze-free image, the transmission map, and the global atmospheric light estimate, respecting the physical model of a haze process. Our DID-Net predicts the three component maps by progressively integrating features across scales, and refines each map by passing an independent refinement network. Then a disentangled-consistency mean-teacher network (DMT-Net) is employed to collaborate unlabeled real data for boosting single image dehazing. Specifically, we encourage the coarse predictions and refinements of each disentangled component to be consistent between the student and teacher networks by using a consistency loss on unlabeled real data. We make comparison with 13 state-of-the-art dehazing methods on a new collected dataset (Haze4K) and two widely-used dehazing datasets (i.e., SOTS and HazeRD), as well as on real-world hazy images. Experimental results demonstrate that our method has obvious quantitative and qualitative improvements over the existing methods.
Two New Stenoses Detection Methods of Coronary Angiograms
Aug 03, 2021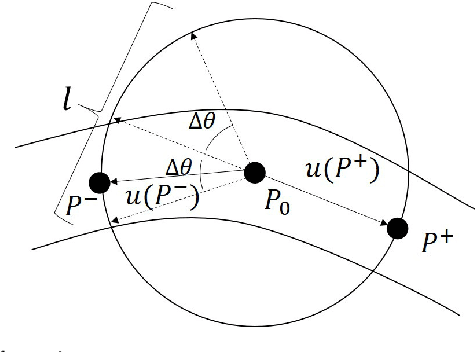
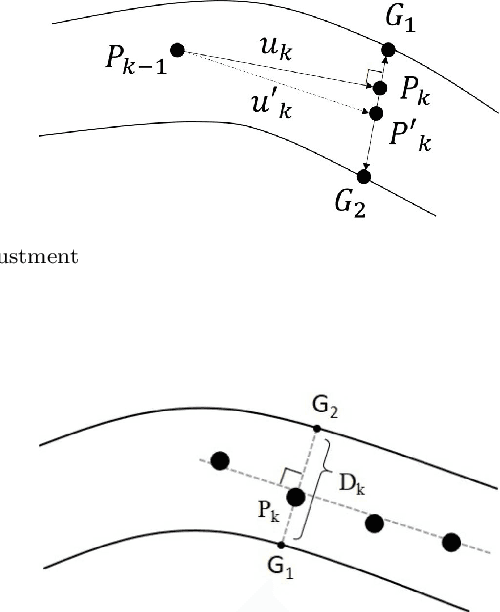
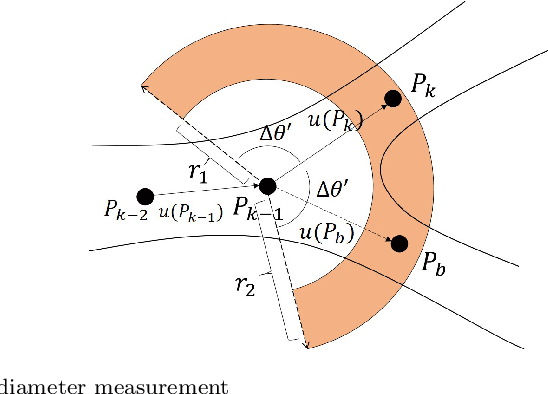
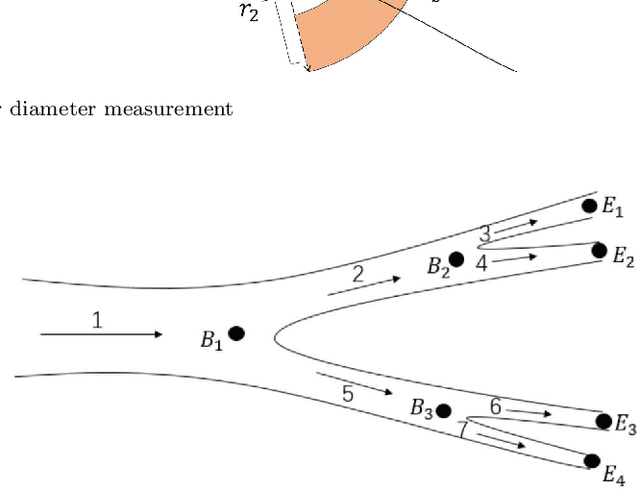
Coronary angiography is the "gold standard" for the diagnosis of coronary heart disease. At present, the methods for detecting coronary artery stenoses and evaluating the degree of it in coronary angiograms are either subjective or not efficient enough. Two vascular stenoses detection methods in coronary angiograms are proposed to assist the diagnosis. The first one is an automatic method, which can automatically segment the entire coronary vessels and mark the stenoses. The second one is an interactive method. With this method, the user only needs to give a start point and an end point to detect the stenoses of a certain vascular segment. We have shown that the proposed tracking methods are robust for angiograms with various vessel structure. The automatic detection method can effectively measure the diameter of the vessel and mark the stenoses in different angiograms. Further investigation proves that the results of interactive detection method can accurately reflect the true stenoses situation. The proposed automatic method and interactive method are effective in various angiograms and can complement each other in clinical practice. The first method can be used for preliminary screening and the second method can be used for further quantitative analysis. It has the potential to improve the level of clinical diagnosis of coronary heart disease.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021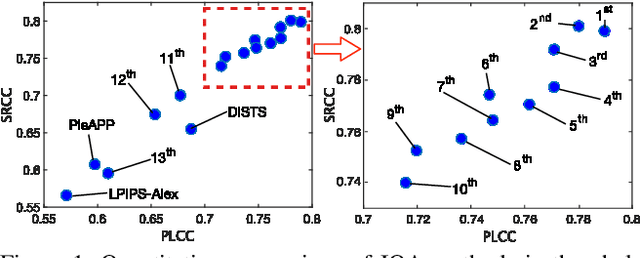
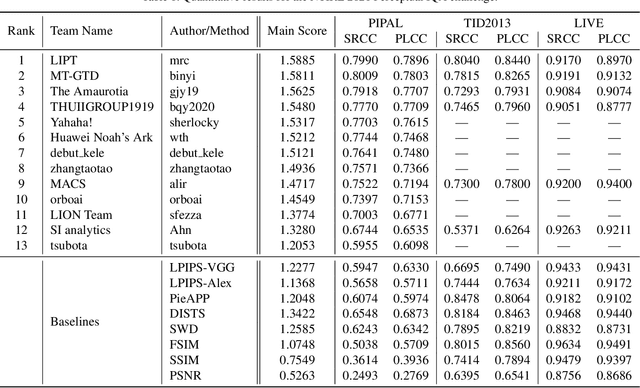

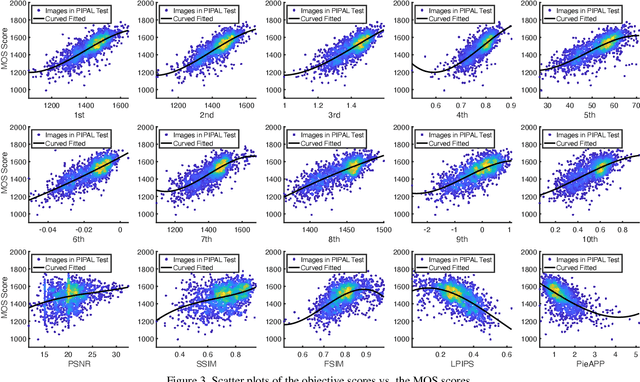
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Automatic sampling and training method for wood-leaf classification based on tree terrestrial point cloud
Dec 06, 2020

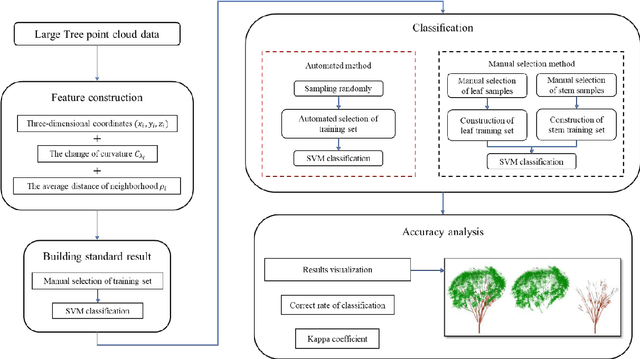
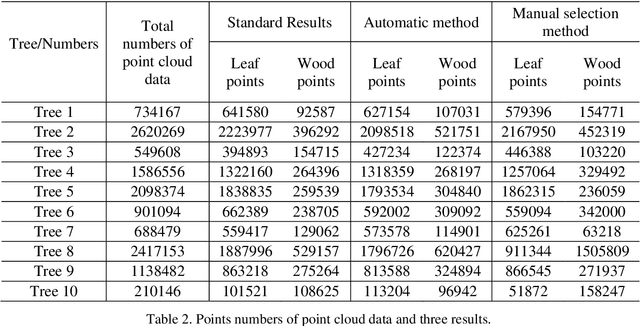
Terrestrial laser scanning technology provides an efficient and accuracy solution for acquiring three-dimensional information of plants. The leaf-wood classification of plant point cloud data is a fundamental step for some forestry and biological research. An automatic sampling and training method for classification was proposed based on tree point cloud data. The plane fitting method was used for selecting leaf sample points and wood sample points automatically, then two local features were calculated for training and classification by using support vector machine (SVM) algorithm. The point cloud data of ten trees were tested by using the proposed method and a manual selection method. The average correct classification rate and kappa coefficient are 0.9305 and 0.7904, respectively. The results show that the proposed method had better efficiency and accuracy comparing to the manual selection method.
Automated classification of stems and leaves of potted plants based on point cloud data
Feb 28, 2020

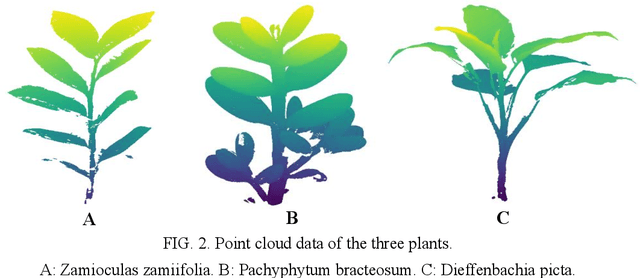

The accurate classification of plant organs is a key step in monitoring the growing status and physiology of plants. A classification method was proposed to classify the leaves and stems of potted plants automatically based on the point cloud data of the plants, which is a nondestructive acquisition. The leaf point training samples were automatically extracted by using the three-dimensional convex hull algorithm, while stem point training samples were extracted by using the point density of a two-dimensional projection. The two training sets were used to classify all the points into leaf points and stem points by utilizing the support vector machine (SVM) algorithm. The proposed method was tested by using the point cloud data of three potted plants and compared with two other methods, which showed that the proposed method can classify leaf and stem points accurately and efficiently.
Automatic marker-free registration of tree point-cloud data based on rotating projection
Jan 30, 2020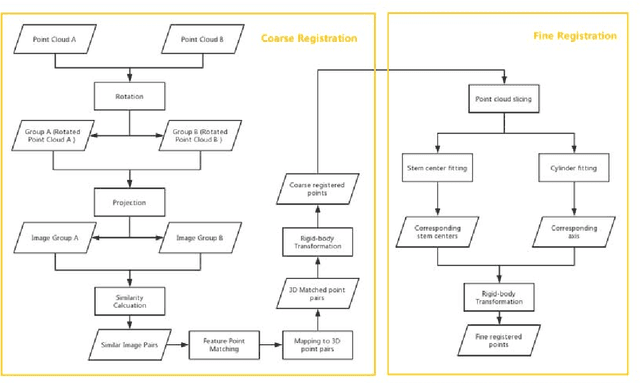
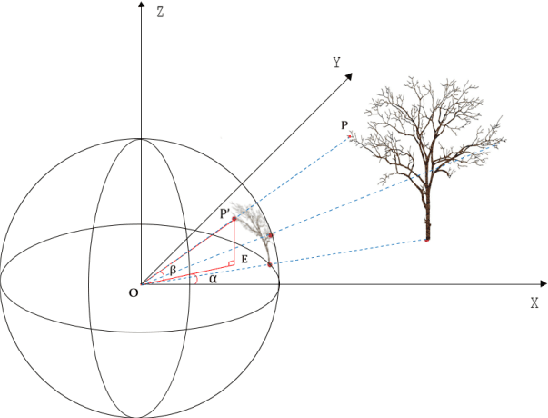
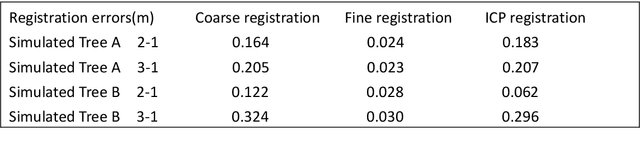
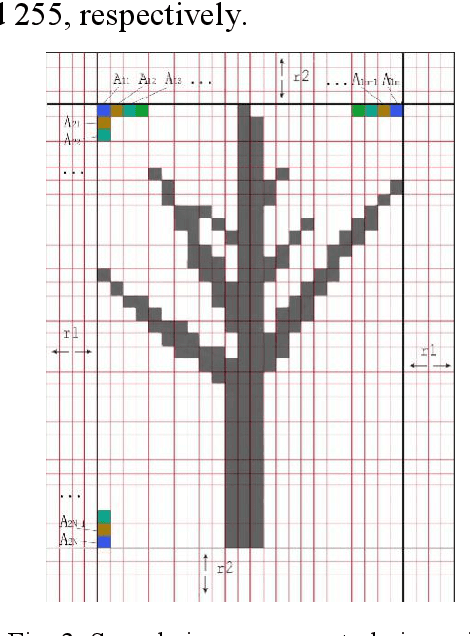
Point-cloud data acquired using a terrestrial laser scanner (TLS) play an important role in digital forestry research. Multiple scans are generally used to overcome occlusion effects and obtain complete tree structural information. However, it is time-consuming and difficult to place artificial reflectors in a forest with complex terrain for marker-based registration, a process that reduces registration automation and efficiency. In this study, we propose an automatic coarse-to-fine method for the registration of point-cloud data from multiple scans of a single tree. In coarse registration, point clouds produced by each scan are projected onto a spherical surface to generate a series of two-dimensional (2D) images, which are used to estimate the initial positions of multiple scans. Corresponding feature-point pairs are then extracted from these series of 2D images. In fine registration, point-cloud data slicing and fitting methods are used to extract corresponding central stem and branch centers for use as tie points to calculate fine transformation parameters. To evaluate the accuracy of registration results, we propose a model of error evaluation via calculating the distances between center points from corresponding branches in adjacent scans. For accurate evaluation, we conducted experiments on two simulated trees and a real-world tree. Average registration errors of the proposed method were 0.26m around on simulated tree point clouds, and 0.05m around on real-world tree point cloud.
Zero-Shot Paraphrase Generation with Multilingual Language Models
Nov 09, 2019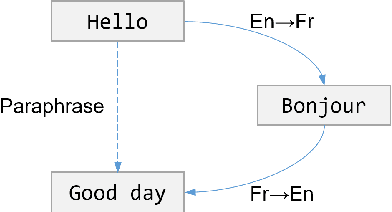
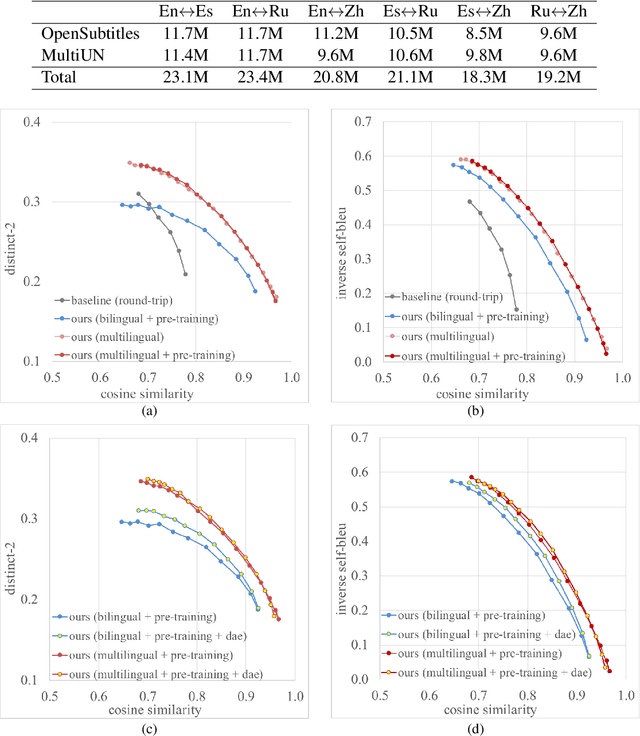
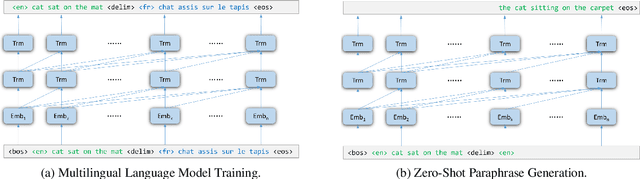
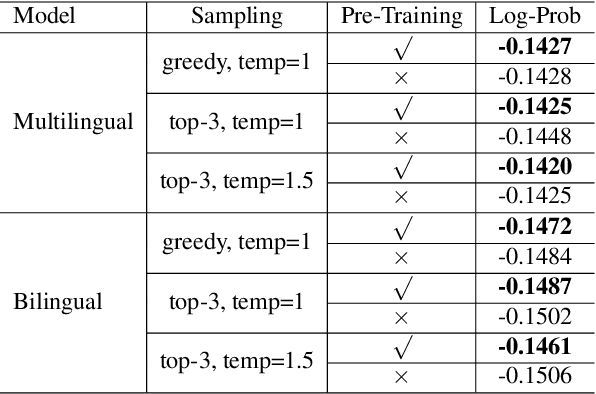
Leveraging multilingual parallel texts to automatically generate paraphrases has drawn much attention as size of high-quality paraphrase corpus is limited. Round-trip translation, also known as the pivoting method, is a typical approach to this end. However, we notice that the pivoting process involves multiple machine translation models and is likely to incur semantic drift during the two-step translations. In this paper, inspired by the Transformer-based language models, we propose a simple and unified paraphrasing model, which is purely trained on multilingual parallel data and can conduct zero-shot paraphrase generation in one step. Compared with the pivoting approach, paraphrases generated by our model is more semantically similar to the input sentence. Moreover, since our model shares the same architecture as GPT (Radford et al., 2018), we are able to pre-train the model on large-scale unparallel corpus, which further improves the fluency of the output sentences. In addition, we introduce the mechanism of denoising auto-encoder (DAE) to improve diversity and robustness of the model. Experimental results show that our model surpasses the pivoting method in terms of relevance, diversity, fluency and efficiency.
Dual Illumination Estimation for Robust Exposure Correction
Oct 30, 2019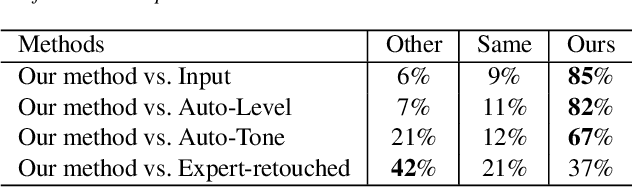

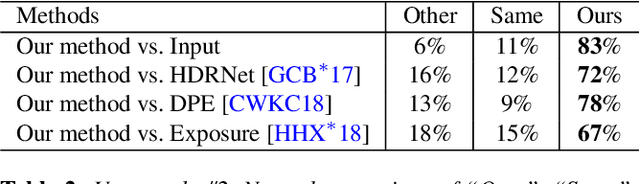

Exposure correction is one of the fundamental tasks in image processing and computational photography. While various methods have been proposed, they either fail to produce visually pleasing results, or only work well for limited types of image (e.g., underexposed images). In this paper, we present a novel automatic exposure correction method, which is able to robustly produce high-quality results for images of various exposure conditions (e.g., underexposed, overexposed, and partially under- and over-exposed). At the core of our approach is the proposed dual illumination estimation, where we separately cast the under- and over-exposure correction as trivial illumination estimation of the input image and the inverted input image. By performing dual illumination estimation, we obtain two intermediate exposure correction results for the input image, with one fixes the underexposed regions and the other one restores the overexposed regions. A multi-exposure image fusion technique is then employed to adaptively blend the visually best exposed parts in the two intermediate exposure correction images and the input image into a globally well-exposed image. Experiments on a number of challenging images demonstrate the effectiveness of the proposed approach and its superiority over the state-of-the-art methods and popular automatic exposure correction tools.