 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-core fiber enabled fading noise suppression in φ-OFDR based quantitative distributed vibration sensing
May 03, 2022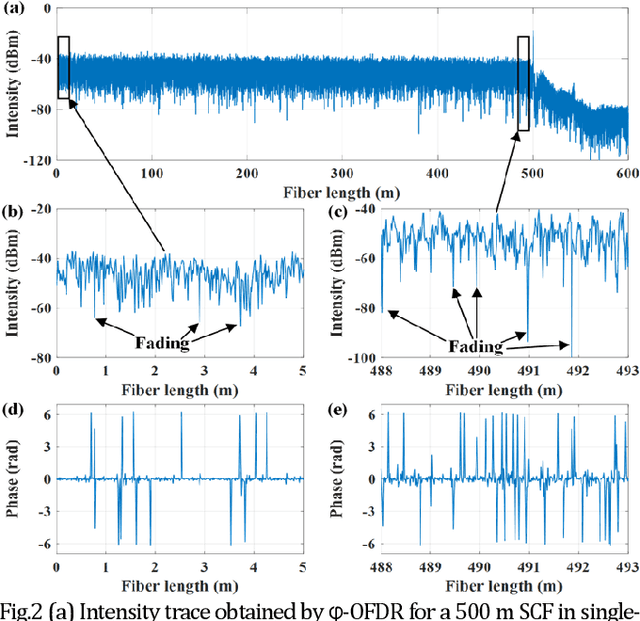
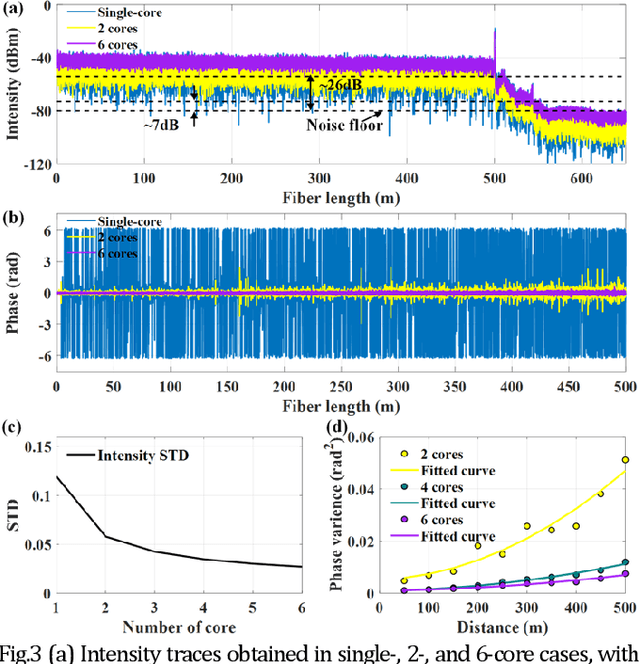
Coherent fading has been regarded as a critical issue in phase-sensitive optical frequency domain reflectometry ({\phi}-OFDR) based distributed fiber-optic sensing. Here, we report on an approach for fading noise suppression in {\phi}-OFDR with multi-core fiber. By exploiting the independent nature of the randomness in the distribution of reflective index in each of the cores, the drastic phase fluctuations due to the fading phenomina can be effectively alleviated by applying weighted vectorial averaging for the Rayleigh backscattering traces from each of the cores with distinct fading distributions. With the consistent linear response with respect to external excitation of interest for each of the cores, demonstration for the propsoed {\phi}-OFDR with a commercial seven-core fiber has achieved highly sensitive quantitative distributed vibration sensing with about 2.2 nm length precision and 2 cm sensing resolution along the 500 m fiber, corresponding to a range resolution factor as high as about about 4E-5. Featuring long distance, high sensitivity, high resolution, and fading robustness, this approach has shown promising potentials in various sensing techniques for a wide range of practical scenarios.
Hybrid Cloud-Edge Collaborative Data Anomaly Detection in Industrial Sensor Networks
Apr 21, 2022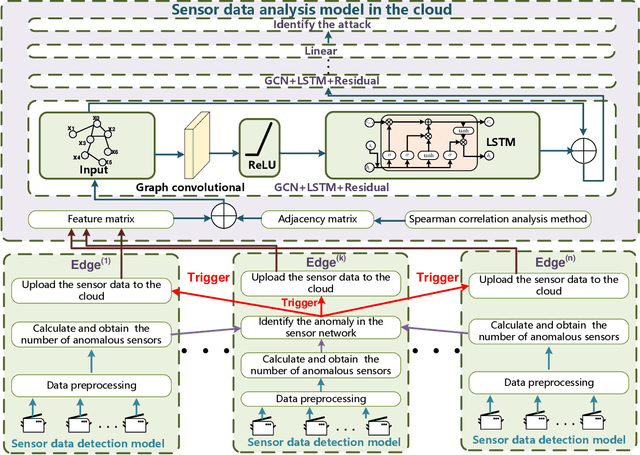
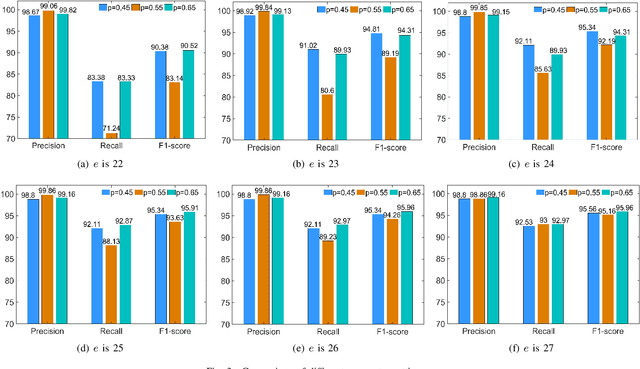
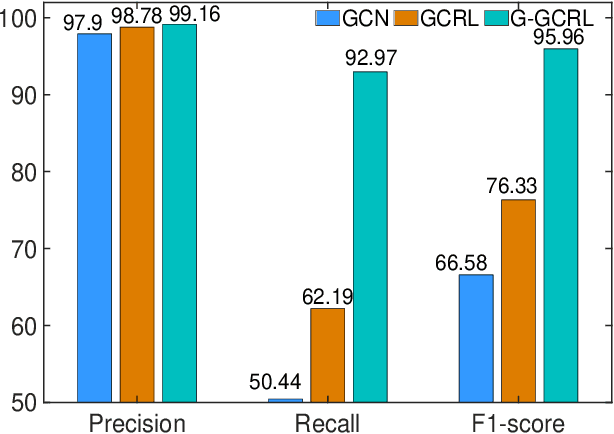
Industrial control systems (ICSs) are facing increasing cyber-physical attacks that can cause catastrophes in the physical system. Efficient anomaly detection models in the industrial sensor networks are essential for enhancing ICS reliability and security, due to the sensor data is related to the operational state of the ICS. Considering the limited availability of computing resources, this paper proposes a hybrid anomaly detection approach in cloud-edge collaboration industrial sensor networks. The hybrid approach consists of sensor data detection models deployed at the edges and a sensor data analysis model deployed in the cloud. The sensor data detection model based on Gaussian and Bayesian algorithms can detect the anomalous sensor data in real-time and upload them to the cloud for further analysis, filtering the normal sensor data and reducing traffic load. The sensor data analysis model based on Graph convolutional network, Residual algorithm and Long short-term memory network (GCRL) can effectively extract the spatial and temporal features and then identify the attack precisely. The proposed hybrid anomaly detection approach is evaluated using a benchmark dataset and baseline anomaly detection models. The experimental results show that the proposed approach can achieve an overall 11.19% increase in Recall and an impressive 14.29% improvement in F1-score, compared with the existing models.
No Free Lunch Theorem for Security and Utility in Federated Learning
Mar 20, 2022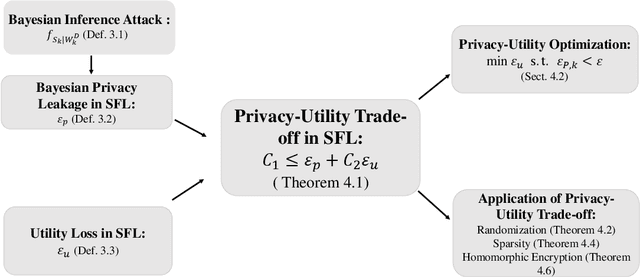

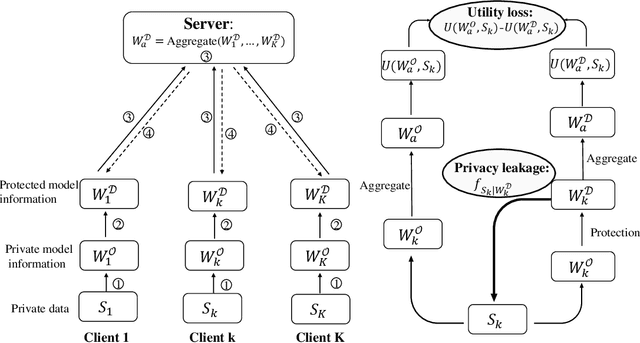
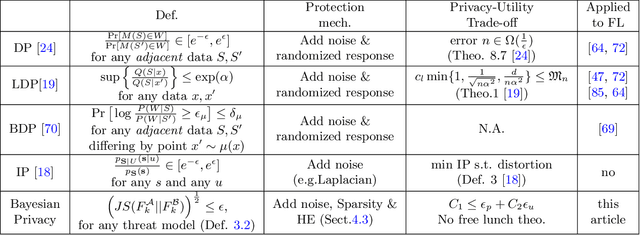
In a federated learning scenario where multiple parties jointly learn a model from their respective data, there exist two conflicting goals for the choice of appropriate algorithms. On one hand, private and sensitive training data must be kept secure as much as possible in the presence of \textit{semi-honest} partners, while on the other hand, a certain amount of information has to be exchanged among different parties for the sake of learning utility. Such a challenge calls for the privacy-preserving federated learning solution, which maximizes the utility of the learned model and maintains a provable privacy guarantee of participating parties' private data. This article illustrates a general framework that a) formulates the trade-off between privacy loss and utility loss from a unified information-theoretic point of view, and b) delineates quantitative bounds of privacy-utility trade-off when different protection mechanisms including Randomization, Sparsity, and Homomorphic Encryption are used. It was shown that in general \textit{there is no free lunch for the privacy-utility trade-off} and one had to trade the protection of privacy with a certain degree of degraded utility. The quantitative analysis illustrated in this article may serve as the guidance for the design of practical federated learning algorithms.
LoSAC: An Efficient Local Stochastic Average Control Method for Federated Optimization
Dec 20, 2021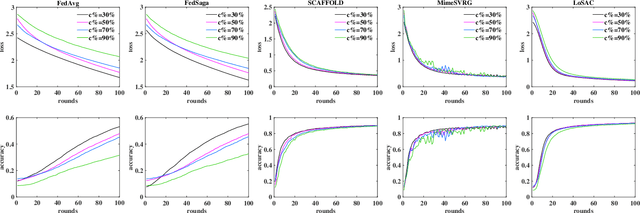
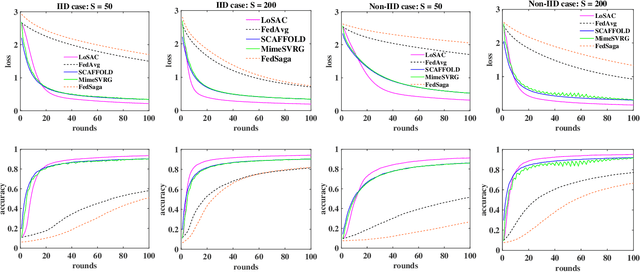
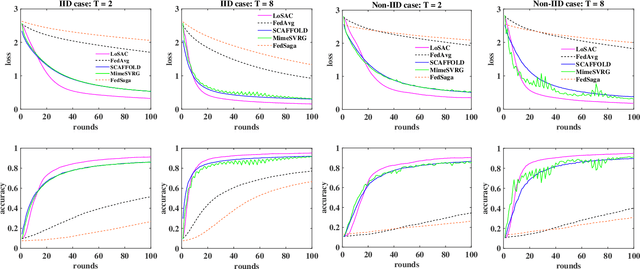
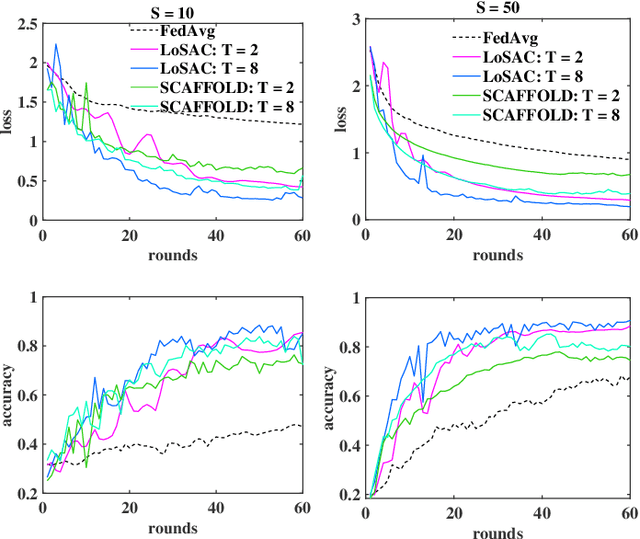
Federated optimization (FedOpt), which targets at collaboratively training a learning model across a large number of distributed clients, is vital for federated learning. The primary concerns in FedOpt can be attributed to the model divergence and communication efficiency, which significantly affect the performance. In this paper, we propose a new method, i.e., LoSAC, to learn from heterogeneous distributed data more efficiently. Its key algorithmic insight is to locally update the estimate for the global full gradient after {each} regular local model update. Thus, LoSAC can keep clients' information refreshed in a more compact way. In particular, we have studied the convergence result for LoSAC. Besides, the bonus of LoSAC is the ability to defend the information leakage from the recent technique Deep Leakage Gradients (DLG). Finally, experiments have verified the superiority of LoSAC comparing with state-of-the-art FedOpt algorithms. Specifically, LoSAC significantly improves communication efficiency by more than $100\%$ on average, mitigates the model divergence problem and equips with the defense ability against DLG.
Defending Label Inference and Backdoor Attacks in Vertical Federated Learning
Dec 10, 2021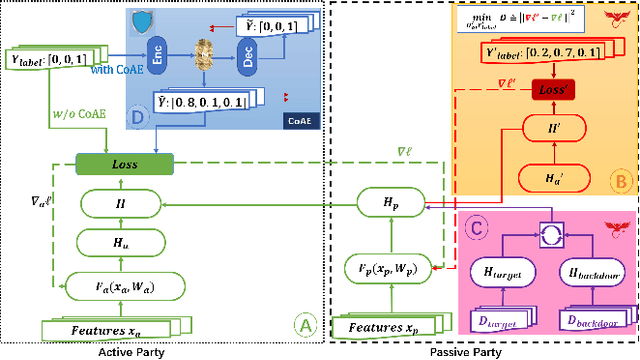

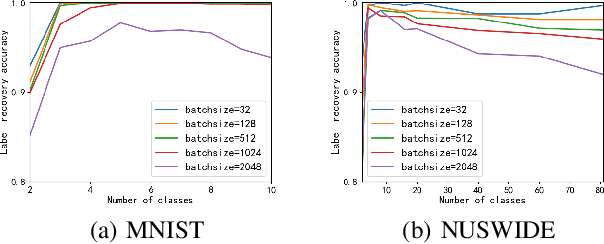
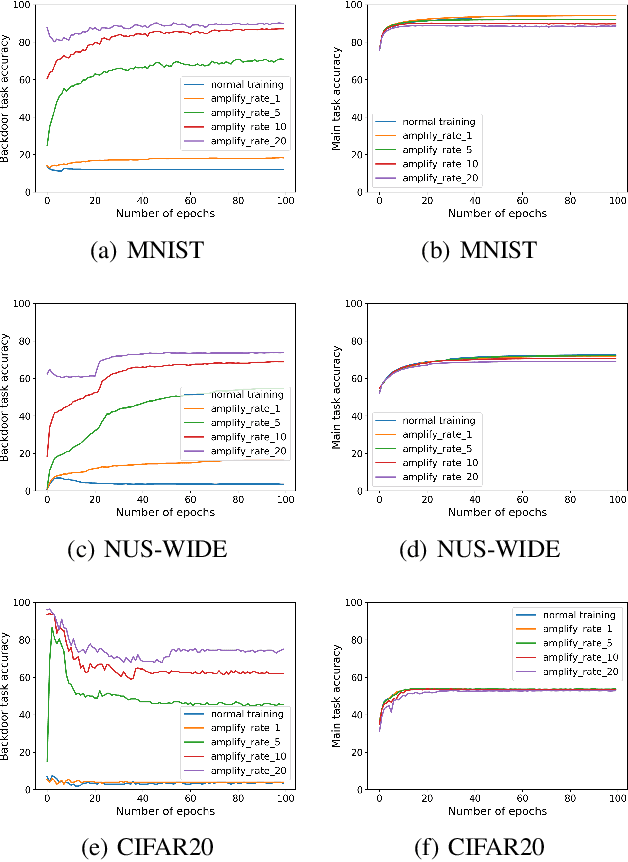
In collaborative learning settings like federated learning, curious parities might be honest but are attempting to infer other parties' private data through inference attacks while malicious parties might manipulate the learning process for their own purposes through backdoor attacks. However, most existing works only consider the federated learning scenario where data are partitioned by samples (HFL). The feature-partitioned federated learning (VFL) can be another important scenario in many real-world applications. Attacks and defenses in such scenarios are especially challenging when the attackers and the defenders are not able to access the features or model parameters of other participants. Previous works have only shown that private labels can be reconstructed from per-sample gradients. In this paper, we first show that private labels can be reconstructed when only batch-averaged gradients are revealed, which is against the common presumption. In addition, we show that a passive party in VFL can even replace its corresponding labels in the active party with a target label through a gradient-replacement attack. To defend against the first attack, we introduce a novel technique termed confusional autoencoder (CoAE), based on autoencoder and entropy regularization. We demonstrate that label inference attacks can be successfully blocked by this technique while hurting less main task accuracy compared to existing methods. Our CoAE technique is also effective in defending the gradient-replacement backdoor attack, making it an universal and practical defense strategy with no change to the original VFL protocol. We demonstrate the effectiveness of our approaches under both two-party and multi-party VFL settings. To the best of our knowledge, this is the first systematic study to deal with label inference and backdoor attacks in the feature-partitioned federated learning framework.
Privacy-preserving Federated Adversarial Domain Adaption over Feature Groups for Interpretability
Nov 22, 2021



We present a novel privacy-preserving federated adversarial domain adaptation approach ($\textbf{PrADA}$) to address an under-studied but practical cross-silo federated domain adaptation problem, in which the party of the target domain is insufficient in both samples and features. We address the lack-of-feature issue by extending the feature space through vertical federated learning with a feature-rich party and tackle the sample-scarce issue by performing adversarial domain adaptation from the sample-rich source party to the target party. In this work, we focus on financial applications where interpretability is critical. However, existing adversarial domain adaptation methods typically apply a single feature extractor to learn feature representations that are low-interpretable with respect to the target task. To improve interpretability, we exploit domain expertise to split the feature space into multiple groups that each holds relevant features, and we learn a semantically meaningful high-order feature from each feature group. In addition, we apply a feature extractor (along with a domain discriminator) for each feature group to enable a fine-grained domain adaptation. We design a secure protocol that enables performing the PrADA in a secure and efficient manner. We evaluate our approach on two tabular datasets. Experiments demonstrate both the effectiveness and practicality of our approach.
FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning
Nov 16, 2021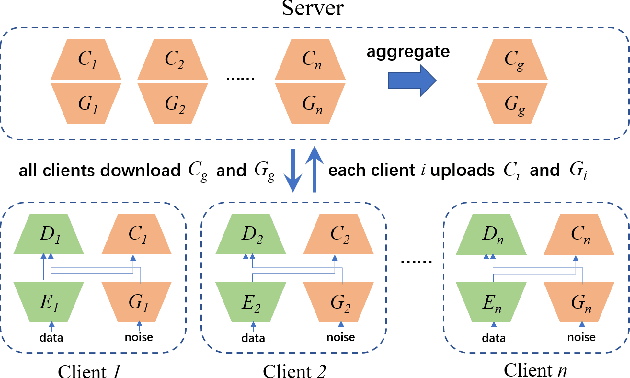
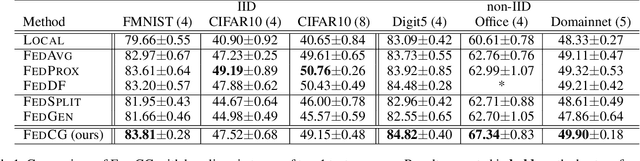
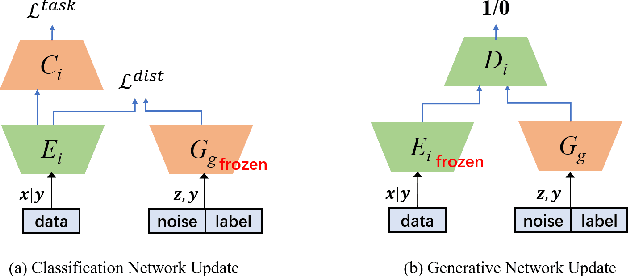

Federated learning (FL) aims to protect data privacy by enabling clients to collaboratively build machine learning models without sharing their private data. However, recent works demonstrate that FL is vulnerable to gradient-based data recovery attacks. Varieties of privacy-preserving technologies have been leveraged to further enhance the privacy of FL. Nonetheless, they either are computational or communication expensive (e.g., homomorphic encryption) or suffer from precision loss (e.g., differential privacy). In this work, we propose \textsc{FedCG}, a novel \underline{fed}erated learning method that leverages \underline{c}onditional \underline{g}enerative adversarial networks to achieve high-level privacy protection while still maintaining competitive model performance. More specifically, \textsc{FedCG} decomposes each client's local network into a private extractor and a public classifier and keeps the extractor local to protect privacy. Instead of exposing extractors which is the culprit of privacy leakage, \textsc{FedCG} shares clients' generators with the server for aggregating common knowledge aiming to enhance the performance of clients' local networks. Extensive experiments demonstrate that \textsc{FedCG} can achieve competitive model performance compared with baseline FL methods, and numerical privacy analysis shows that \textsc{FedCG} has high-level privacy-preserving capability.
SecureBoost+ : A High Performance Gradient Boosting Tree Framework for Large Scale Vertical Federated Learning
Oct 21, 2021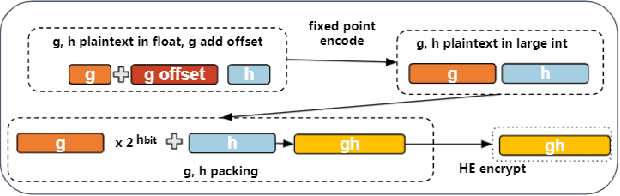
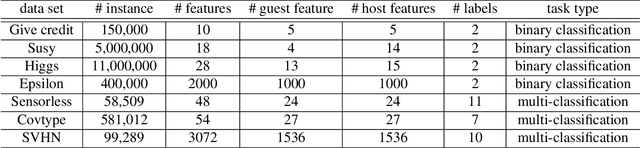
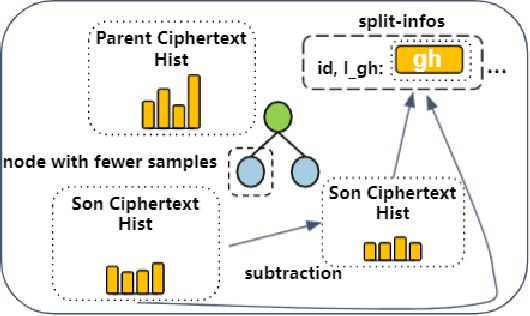
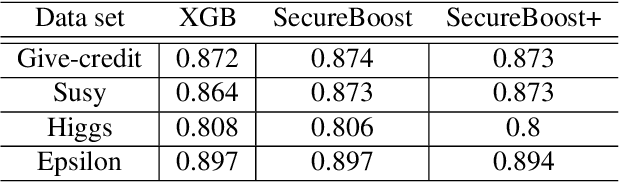
Gradient boosting decision tree (GBDT) is a widely used ensemble algorithm in the industry. Its vertical federated learning version, SecureBoost, is one of the most popular algorithms used in cross-silo privacy-preserving modeling. As the area of privacy computation thrives in recent years, demands for large-scale and high-performance federated learning have grown dramatically in real-world applications. In this paper, to fulfill these requirements, we propose SecureBoost+ that is both novel and improved from the prior work SecureBoost. SecureBoost+ integrates several ciphertext calculation optimizations and engineering optimizations. The experimental results demonstrate that Secureboost+ has significant performance improvements on large and high dimensional data sets compared to SecureBoost. It makes effective and efficient large-scale vertical federated learning possible.
SportsSum2.0: Generating High-Quality Sports News from Live Text Commentary
Oct 12, 2021
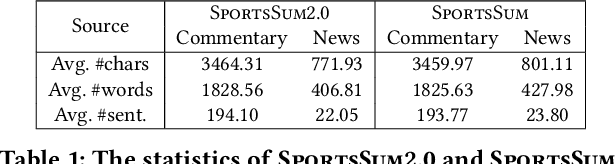
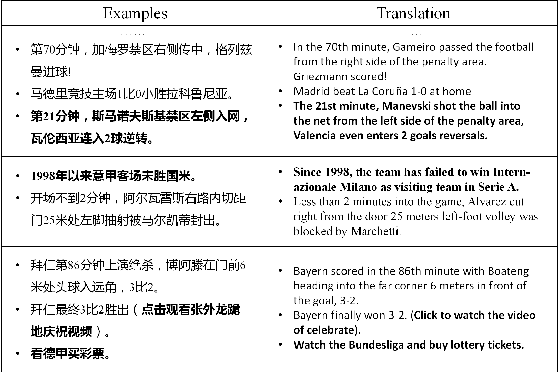
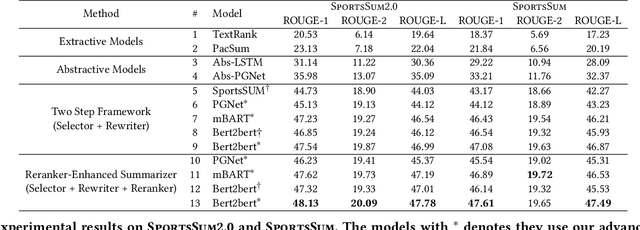
Sports game summarization aims to generate news articles from live text commentaries. A recent state-of-the-art work, SportsSum, not only constructs a large benchmark dataset, but also proposes a two-step framework. Despite its great contributions, the work has three main drawbacks: 1) the noise existed in SportsSum dataset degrades the summarization performance; 2) the neglect of lexical overlap between news and commentaries results in low-quality pseudo-labeling algorithm; 3) the usage of directly concatenating rewritten sentences to form news limits its practicability. In this paper, we publish a new benchmark dataset SportsSum2.0, together with a modified summarization framework. In particular, to obtain a clean dataset, we employ crowd workers to manually clean the original dataset. Moreover, the degree of lexical overlap is incorporated into the generation of pseudo labels. Further, we introduce a reranker-enhanced summarizer to take into account the fluency and expressiveness of the summarized news. Extensive experiments show that our model outperforms the state-of-the-art baseline.
FedIPR: Ownership Verification for Federated Deep Neural Network Models
Sep 27, 2021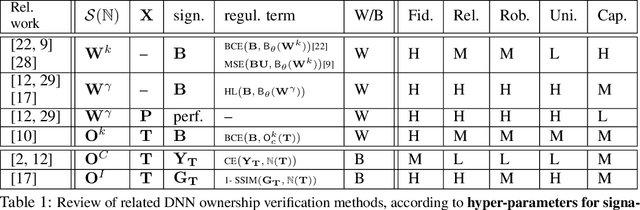
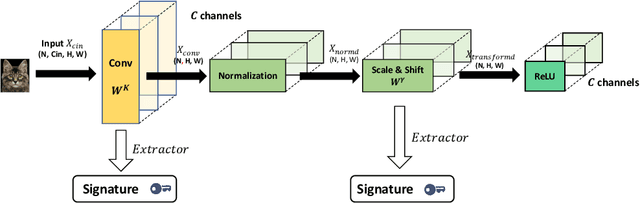
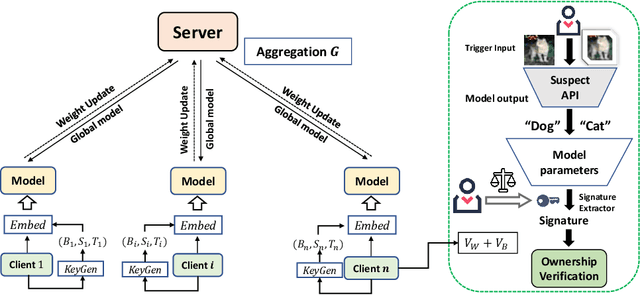
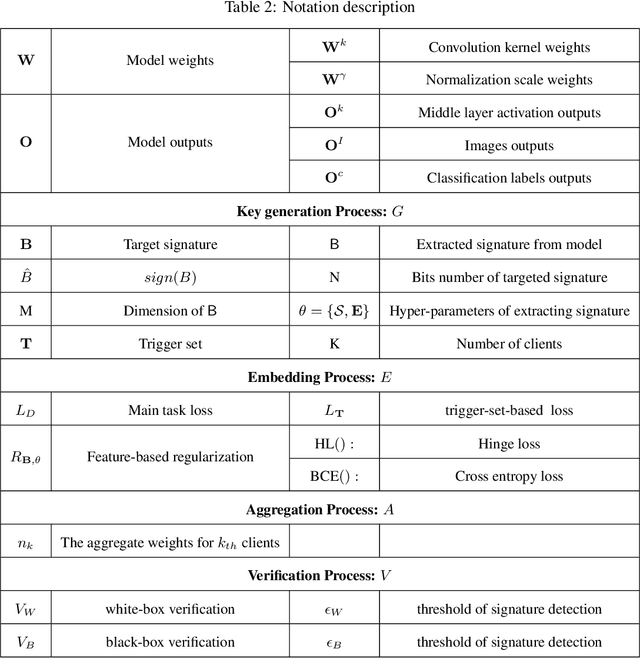
Federated learning models must be protected against plagiarism since these models are built upon valuable training data owned by multiple institutions or people.This paper illustrates a novel federated deep neural network (FedDNN) ownership verification scheme that allows ownership signatures to be embedded and verified to claim legitimate intellectual property rights (IPR) of FedDNN models, in case that models are illegally copied, re-distributed or misused. The effectiveness of embedded ownership signatures is theoretically justified by proved condition sunder which signatures can be embedded and detected by multiple clients with-out disclosing private signatures. Extensive experimental results on CIFAR10,CIFAR100 image datasets demonstrate that varying bit-lengths signatures can be embedded and reliably detected without affecting models classification performances. Signatures are also robust against removal attacks including fine-tuning and pruning.