 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
Feb 11, 2026Equipping embodied agents with the ability to reason about tasks, foresee physical outcomes, and generate precise actions is essential for general-purpose manipulation. While recent Vision-Language-Action (VLA) models have leveraged pre-trained foundation models, they typically focus on either linguistic planning or visual forecasting in isolation. These methods rarely integrate both capabilities simultaneously to guide action generation, leading to suboptimal performance in complex, long-horizon manipulation tasks. To bridge this gap, we propose BagelVLA, a unified model that integrates linguistic planning, visual forecasting, and action generation within a single framework. Initialized from a pretrained unified understanding and generative model, BagelVLA is trained to interleave textual reasoning and visual prediction directly into the action execution loop. To efficiently couple these modalities, we introduce Residual Flow Guidance (RFG), which initializes from current observation and leverages single-step denoising to extract predictive visual features, guiding action generation with minimal latency. Extensive experiments demonstrate that BagelVLA outperforms existing baselines by a significant margin on multiple simulated and real-world benchmarks, particularly in tasks requiring multi-stage reasoning.
Hydra-Nav: Object Navigation via Adaptive Dual-Process Reasoning
Feb 10, 2026While large vision-language models (VLMs) show promise for object goal navigation, current methods still struggle with low success rates and inefficient localization of unseen objects--failures primarily attributed to weak temporal-spatial reasoning. Meanwhile, recent attempts to inject reasoning into VLM-based agents improve success rates but incur substantial computational overhead. To address both the ineffectiveness and inefficiency of existing approaches, we introduce Hydra-Nav, a unified VLM architecture that adaptively switches between a deliberative slow system for analyzing exploration history and formulating high-level plans, and a reactive fast system for efficient execution. We train Hydra-Nav through a three-stage curriculum: (i) spatial-action alignment to strengthen trajectory planning, (ii) memory-reasoning integration to enhance temporal-spatial reasoning over long-horizon exploration, and (iii) iterative rejection fine-tuning to enable selective reasoning at critical decision points. Extensive experiments demonstrate that Hydra-Nav achieves state-of-the-art performance on the HM3D, MP3D, and OVON benchmarks, outperforming the second-best methods by 11.1%, 17.4%, and 21.2%, respectively. Furthermore, we introduce SOT (Success weighted by Operation Time), a new metric to measure search efficiency across VLMs with varying reasoning intensity. Results show that adaptive reasoning significantly enhances search efficiency over fixed-frequency baselines.
VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Jan 13, 2026VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.
UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
Dec 10, 2025Autonomous driving (AD) systems struggle in long-tail scenarios due to limited world knowledge and weak visual dynamic modeling. Existing vision-language-action (VLA)-based methods cannot leverage unlabeled videos for visual causal learning, while world model-based methods lack reasoning capabilities from large language models. In this paper, we construct multiple specialized datasets providing reasoning and planning annotations for complex scenarios. Then, a unified Understanding-Generation-Planning framework, named UniUGP, is proposed to synergize scene reasoning, future video generation, and trajectory planning through a hybrid expert architecture. By integrating pre-trained VLMs and video generation models, UniUGP leverages visual dynamics and semantic reasoning to enhance planning performance. Taking multi-frame observations and language instructions as input, it produces interpretable chain-of-thought reasoning, physically consistent trajectories, and coherent future videos. We introduce a four-stage training strategy that progressively builds these capabilities across multiple existing AD datasets, along with the proposed specialized datasets. Experiments demonstrate state-of-the-art performance in perception, reasoning, and decision-making, with superior generalization to challenging long-tail situations.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Network On Network for Tabular Data Classification in Real-world Applications
May 29, 2020
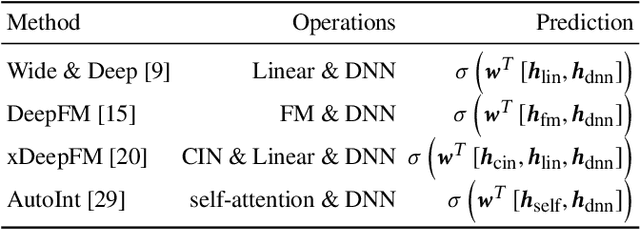
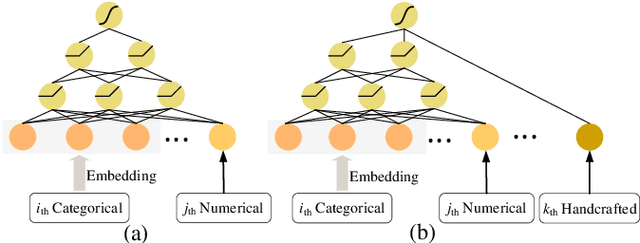
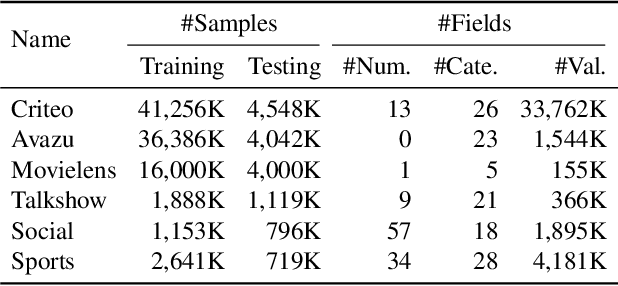
Tabular data is the most common data format adopted by our customers ranging from retail, finance to E-commerce, and tabular data classification plays an essential role to their businesses. In this paper, we present Network On Network (NON), a practical tabular data classification model based on deep neural network to provide accurate predictions. Various deep methods have been proposed and promising progress has been made. However, most of them use operations like neural network and factorization machines to fuse the embeddings of different features directly, and linearly combine the outputs of those operations to get the final prediction. As a result, the intra-field information and the non-linear interactions between those operations (e.g. neural network and factorization machines) are ignored. Intra-field information is the information that features inside each field belong to the same field. NON is proposed to take full advantage of intra-field information and non-linear interactions. It consists of three components: field-wise network at the bottom to capture the intra-field information, across field network in the middle to choose suitable operations data-drivenly, and operation fusion network on the top to fuse outputs of the chosen operations deeply. Extensive experiments on six real-world datasets demonstrate NON can outperform the state-of-the-art models significantly. Furthermore, both qualitative and quantitative study of the features in the embedding space show NON can capture intra-field information effectively.