 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-oriented Autonomous Driving
Dec 20, 2022



Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction and planning. As sensors and hardware get improved, there is trending popularity to devise a system that can perform a wide diversity of tasks to fulfill higher-level intelligence. Contemporary approaches resort to either deploying standalone models for individual tasks, or designing a multi-task paradigm with separate heads. These might suffer from accumulative error or negative transfer effect. Instead, we argue that a favorable algorithm framework should be devised and optimized in pursuit of the ultimate goal, i.e. planning of the self-driving-car. Oriented at this goal, we revisit the key components within perception and prediction. We analyze each module and prioritize the tasks hierarchically, such that all these tasks contribute to planning (the goal). To this end, we introduce Unified Autonomous Driving (UniAD), the first comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query design to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven to surpass previous state-of-the-arts by a large margin in all aspects. The full suite of codebase and models would be available to facilitate future research in the community.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.
Fast Point Cloud Generation with Straight Flows
Dec 04, 2022



Diffusion models have emerged as a powerful tool for point cloud generation. A key component that drives the impressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of learning steps has limited its applications to many 3D real-world. To address this limitation, we propose Point Straight Flow (PSF), a model that exhibits impressive performance using one step. Our idea is based on the reformulation of the standard diffusion model, which optimizes the curvy learning trajectory into a straight path. Further, we develop a distillation strategy to shorten the straight path into one step without a performance loss, enabling applications to 3D real-world with latency constraints. We perform evaluations on multiple 3D tasks and find that our PSF performs comparably to the standard diffusion model, outperforming other efficient 3D point cloud generation methods. On real-world applications such as point cloud completion and training-free text-guided generation in a low-latency setup, PSF performs favorably.
Distributed Node Covering Optimization for Large Scale Networks and Its Application on Social Advertising
Nov 16, 2022



Combinatorial optimizations are usually complex and inefficient, which limits their applications in large-scale networks with billions of links. We introduce a distributed computational method for solving a node-covering problem at the scale of factual scenarios. We first construct a genetic algorithm and then design a two-step strategy to initialize the candidate solutions. All the computational operations are designed and developed in a distributed form on \textit{Apache Spark} enabling fast calculation for practical graphs. We apply our method to social advertising of recalling back churn users in online mobile games, which was previously only treated as a traditional item recommending or ranking problem.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Atlas: Automate Online Service Configuration in Network Slicing
Oct 30, 2022



Network slicing achieves cost-efficient slice customization to support heterogeneous applications and services. Configuring cross-domain resources to end-to-end slices based on service-level agreements, however, is challenging, due to the complicated underlying correlations and the simulation-to-reality discrepancy between simulators and real networks. In this paper, we propose Atlas, an online network slicing system, which automates the service configuration of slices via safe and sample-efficient learn-to-configure approaches in three interrelated stages. First, we design a learning-based simulator to reduce the sim-to-real discrepancy, which is accomplished by a new parameter searching method based on Bayesian optimization. Second, we offline train the policy in the augmented simulator via a novel offline algorithm with a Bayesian neural network and parallel Thompson sampling. Third, we online learn the policy in real networks with a novel online algorithm with safe exploration and Gaussian process regression. We implement Atlas on an end-to-end network prototype based on OpenAirInterface RAN, OpenDayLight SDN transport, OpenAir-CN core network, and Docker-based edge server. Experimental results show that, compared to state-of-the-art solutions, Atlas achieves 63.9% and 85.7% regret reduction on resource usage and slice quality of experience during the online learning stage, respectively.
Sampling with Mollified Interaction Energy Descent
Oct 24, 2022Sampling from a target measure whose density is only known up to a normalization constant is a fundamental problem in computational statistics and machine learning. In this paper, we present a new optimization-based method for sampling called mollified interaction energy descent (MIED). MIED minimizes a new class of energies on probability measures called mollified interaction energies (MIEs). These energies rely on mollifier functions -- smooth approximations of the Dirac delta originated from PDE theory. We show that as the mollifier approaches the Dirac delta, the MIE converges to the chi-square divergence with respect to the target measure and the gradient flow of the MIE agrees with that of the chi-square divergence. Optimizing this energy with proper discretization yields a practical first-order particle-based algorithm for sampling in both unconstrained and constrained domains. We show experimentally that for unconstrained sampling problems our algorithm performs on par with existing particle-based algorithms like SVGD, while for constrained sampling problems our method readily incorporates constrained optimization techniques to handle more flexible constraints with strong performance compared to alternatives.
Sampling in Constrained Domains with Orthogonal-Space Variational Gradient Descent
Oct 12, 2022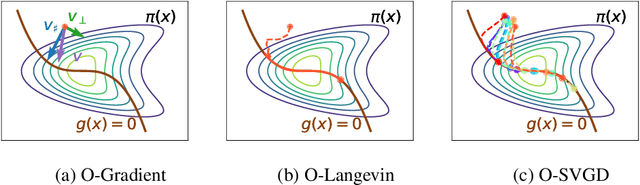
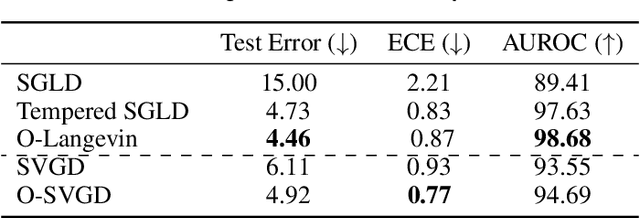
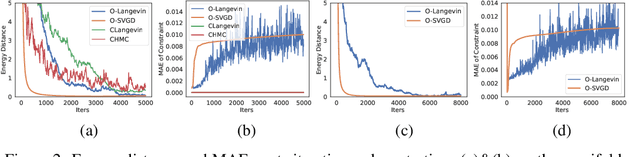
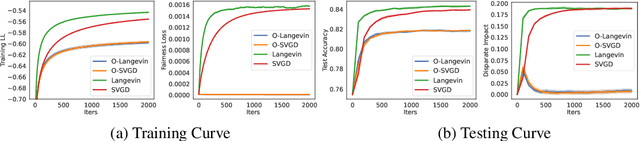
Sampling methods, as important inference and learning techniques, are typically designed for unconstrained domains. However, constraints are ubiquitous in machine learning problems, such as those on safety, fairness, robustness, and many other properties that must be satisfied to apply sampling results in real-life applications. Enforcing these constraints often leads to implicitly-defined manifolds, making efficient sampling with constraints very challenging. In this paper, we propose a new variational framework with a designed orthogonal-space gradient flow (O-Gradient) for sampling on a manifold $\mathcal{G}_0$ defined by general equality constraints. O-Gradient decomposes the gradient into two parts: one decreases the distance to $\mathcal{G}_0$ and the other decreases the KL divergence in the orthogonal space. While most existing manifold sampling methods require initialization on $\mathcal{G}_0$, O-Gradient does not require such prior knowledge. We prove that O-Gradient converges to the target constrained distribution with rate $\widetilde{O}(1/\text{the number of iterations})$ under mild conditions. Our proof relies on a new Stein characterization of conditional measure which could be of independent interest. We implement O-Gradient through both Langevin dynamics and Stein variational gradient descent and demonstrate its effectiveness in various experiments, including Bayesian deep neural networks.
Adversarial Contrastive Learning for Evidence-aware Fake News Detection with Graph Neural Networks
Oct 11, 2022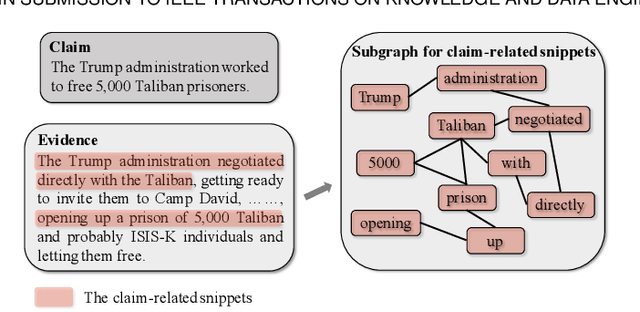

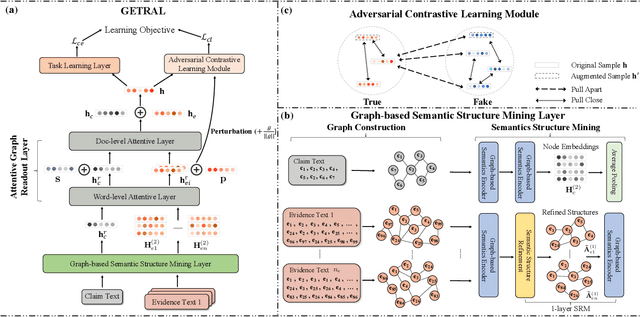

The prevalence and perniciousness of fake news have been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on attention mechanisms. Despite their effectiveness, they still suffer from three weaknesses. Firstly, sequential models fail to integrate the relevant information that is scattered far apart in evidences. Secondly, they underestimate much redundant information in evidences may be useless or harmful. Thirdly, insufficient data utilization limits the separability and reliability of representations captured by the model. To solve these problems, we propose a unified Graph-based sEmantic structure mining framework with ConTRAstive Learning, namely GETRAL in short. Specifically, we first model claims and evidences as graph-structured data to capture the long-distance semantic dependency. Consequently, we reduce information redundancy by performing graph structure learning. Then the fine-grained semantic representations are fed into the claim-evidence interaction module for predictions. Finally, an adversarial contrastive learning module is applied to make full use of data and strengthen representation learning. Comprehensive experiments have demonstrated the superiority of GETRAL over the state-of-the-arts and validated the efficacy of semantic mining with graph structure and contrastive learning.
Neural Volumetric Mesh Generator
Oct 06, 2022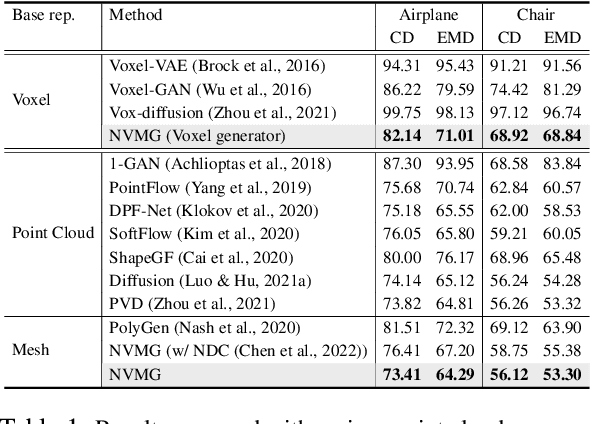
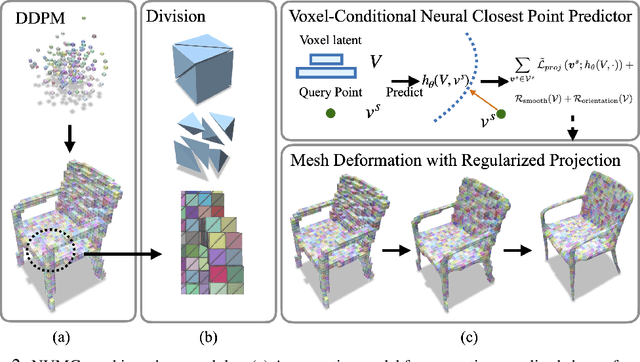

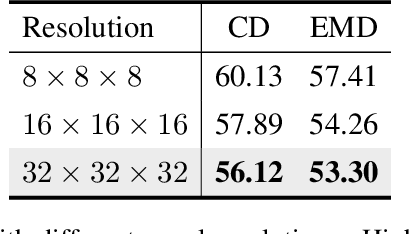
Deep generative models have shown success in generating 3D shapes with different representations. In this work, we propose Neural Volumetric Mesh Generator(NVMG) which can generate novel and high-quality volumetric meshes. Unlike the previous 3D generative model for point cloud, voxel, and implicit surface, the volumetric mesh representation is a ready-to-use representation in industry with details on both the surface and interior. Generating this such highly-structured data thus brings a significant challenge. We first propose a diffusion-based generative model to tackle this problem by generating voxelized shapes with close-to-reality outlines and structures. We can simply obtain a tetrahedral mesh as a template with the voxelized shape. Further, we use a voxel-conditional neural network to predict the smooth implicit surface conditioned on the voxels, and progressively project the tetrahedral mesh to the predicted surface under regularizations. The regularization terms are carefully designed so that they can (1) get rid of the defects like flipping and high distortion; (2) force the regularity of the interior and surface structure during the deformation procedure for a high-quality final mesh. As shown in the experiments, our pipeline can generate high-quality artifact-free volumetric and surface meshes from random noise or a reference image without any post-processing. Compared with the state-of-the-art voxel-to-mesh deformation method, we show more robustness and better performance when taking generated voxels as input.