 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024



Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
ASGEA: Exploiting Logic Rules from Align-Subgraphs for Entity Alignment
Feb 16, 2024



Entity alignment (EA) aims to identify entities across different knowledge graphs that represent the same real-world objects. Recent embedding-based EA methods have achieved state-of-the-art performance in EA yet faced interpretability challenges as they purely rely on the embedding distance and neglect the logic rules behind a pair of aligned entities. In this paper, we propose the Align-Subgraph Entity Alignment (ASGEA) framework to exploit logic rules from Align-Subgraphs. ASGEA uses anchor links as bridges to construct Align-Subgraphs and spreads along the paths across KGs, which distinguishes it from the embedding-based methods. Furthermore, we design an interpretable Path-based Graph Neural Network, ASGNN, to effectively identify and integrate the logic rules across KGs. We also introduce a node-level multi-modal attention mechanism coupled with multi-modal enriched anchors to augment the Align-Subgraph. Our experimental results demonstrate the superior performance of ASGEA over the existing embedding-based methods in both EA and Multi-Modal EA (MMEA) tasks. Our code will be available soon.
HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy
Jan 26, 2024



Full-parameter fine-tuning has become the go-to choice for adapting language models (LMs) to downstream tasks due to its excellent performance. As LMs grow in size, fine-tuning the full parameters of LMs requires a prohibitively large amount of GPU memory. Existing approaches utilize zeroth-order optimizer to conserve GPU memory, which can potentially compromise the performance of LMs as non-zero order optimizers tend to converge more readily on most downstream tasks. In this paper, we propose a novel optimizer-independent end-to-end hierarchical fine-tuning strategy, HiFT, which only updates a subset of parameters at each training step. HiFT can significantly reduce the amount of gradients and optimizer state parameters residing in GPU memory at the same time, thereby reducing GPU memory usage. Our results demonstrate that: (1) HiFT achieves comparable performance to parameter-efficient fine-tuning and standard full parameter fine-tuning. (2) HiFT supports various optimizers including AdamW, AdaGrad, SGD, etc. (3) HiFT can save more than 60\% GPU memory compared with standard full-parameter fine-tuning for 7B model. (4) HiFT enables full-parameter fine-tuning of a 7B model on single 48G A6000 with a precision of 32 using the AdamW optimizer, without using any memory saving techniques.
Text-Video Retrieval via Variational Multi-Modal Hypergraph Networks
Jan 06, 2024Text-video retrieval is a challenging task that aims to identify relevant videos given textual queries. Compared to conventional textual retrieval, the main obstacle for text-video retrieval is the semantic gap between the textual nature of queries and the visual richness of video content. Previous works primarily focus on aligning the query and the video by finely aggregating word-frame matching signals. Inspired by the human cognitive process of modularly judging the relevance between text and video, the judgment needs high-order matching signal due to the consecutive and complex nature of video contents. In this paper, we propose chunk-level text-video matching, where the query chunks are extracted to describe a specific retrieval unit, and the video chunks are segmented into distinct clips from videos. We formulate the chunk-level matching as n-ary correlations modeling between words of the query and frames of the video and introduce a multi-modal hypergraph for n-ary correlation modeling. By representing textual units and video frames as nodes and using hyperedges to depict their relationships, a multi-modal hypergraph is constructed. In this way, the query and the video can be aligned in a high-order semantic space. In addition, to enhance the model's generalization ability, the extracted features are fed into a variational inference component for computation, obtaining the variational representation under the Gaussian distribution. The incorporation of hypergraphs and variational inference allows our model to capture complex, n-ary interactions among textual and visual contents. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on the text-video retrieval task.
Multi-spatial Multi-temporal Air Quality Forecasting with Integrated Monitoring and Reanalysis Data
Dec 31, 2023



Accurate air quality forecasting is crucial for public health, environmental monitoring and protection, and urban planning. However, existing methods fail to effectively utilize multi-scale information, both spatially and temporally. Spatially, there is a lack of integration between individual monitoring stations and city-wide scales. Temporally, the periodic nature of air quality variations is often overlooked or inadequately considered. To address these limitations, we present a novel Multi-spatial Multi-temporal air quality forecasting method based on Graph Convolutional Networks and Gated Recurrent Units (M2G2), bridging the gap in air quality forecasting across spatial and temporal scales. The proposed framework consists of two modules: Multi-scale Spatial GCN (MS-GCN) for spatial information fusion and Multi-scale Temporal GRU(MT-GRU) for temporal information integration. In the spatial dimension, the MS-GCN module employs a bidirectional learnable structure and a residual structure, enabling comprehensive information exchange between individual monitoring stations and the city-scale graph. Regarding the temporal dimension, the MT-GRU module adaptively combines information from different temporal scales through parallel hidden states. Leveraging meteorological indicators and four air quality indicators, we present comprehensive comparative analyses and ablation experiments, showcasing the higher accuracy of M2G2 in comparison to nine currently available advanced approaches across all aspects. The improvements of M2G2 over the second-best method on RMSE of the 24h/48h/72h are as follows: PM2.5: (7.72%, 6.67%, 10.45%); PM10: (6.43%, 5.68%, 7.73%); NO2: (5.07%, 7.76%, 16.60%); O3: (6.46%, 6.86%, 9.79%). Furthermore, we demonstrate the effectiveness of each module of M2G2 by ablation study.
An Adaptive Framework of Geographical Group-Specific Network on O2O Recommendation
Dec 28, 2023



Online to offline recommendation strongly correlates with the user and service's spatiotemporal information, therefore calling for a higher degree of model personalization. The traditional methodology is based on a uniform model structure trained by collected centralized data, which is unlikely to capture all user patterns over different geographical areas or time periods. To tackle this challenge, we propose a geographical group-specific modeling method called GeoGrouse, which simultaneously studies the common knowledge as well as group-specific knowledge of user preferences. An automatic grouping paradigm is employed and verified based on users' geographical grouping indicators. Offline and online experiments are conducted to verify the effectiveness of our approach, and substantial business improvement is achieved.
Focus on Hiders: Exploring Hidden Threats for Enhancing Adversarial Training
Dec 12, 2023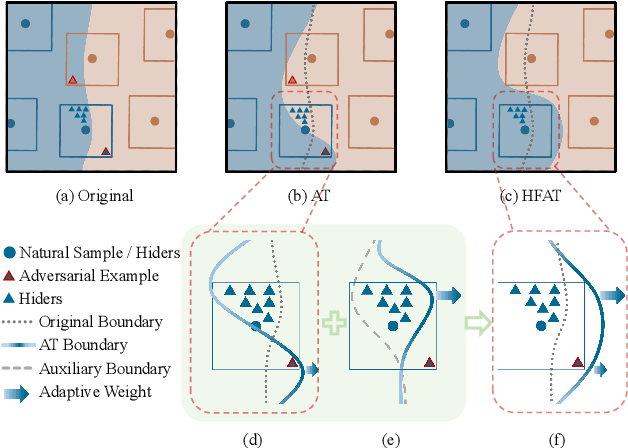
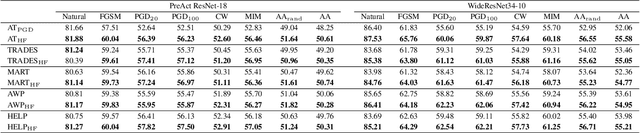
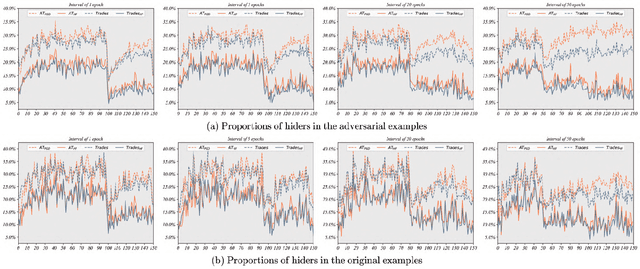
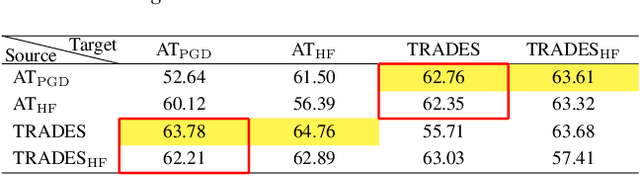
Adversarial training is often formulated as a min-max problem, however, concentrating only on the worst adversarial examples causes alternating repetitive confusion of the model, i.e., previously defended or correctly classified samples are not defensible or accurately classifiable in subsequent adversarial training. We characterize such non-ignorable samples as "hiders", which reveal the hidden high-risk regions within the secure area obtained through adversarial training and prevent the model from finding the real worst cases. We demand the model to prevent hiders when defending against adversarial examples for improving accuracy and robustness simultaneously. By rethinking and redefining the min-max optimization problem for adversarial training, we propose a generalized adversarial training algorithm called Hider-Focused Adversarial Training (HFAT). HFAT introduces the iterative evolution optimization strategy to simplify the optimization problem and employs an auxiliary model to reveal hiders, effectively combining the optimization directions of standard adversarial training and prevention hiders. Furthermore, we introduce an adaptive weighting mechanism that facilitates the model in adaptively adjusting its focus between adversarial examples and hiders during different training periods. We demonstrate the effectiveness of our method based on extensive experiments, and ensure that HFAT can provide higher robustness and accuracy.
Collapse-Oriented Adversarial Training with Triplet Decoupling for Robust Image Retrieval
Dec 12, 2023



Adversarial training has achieved substantial performance in defending image retrieval systems against adversarial examples. However, existing studies still suffer from two major limitations: model collapse and weak adversary. This paper addresses these two limitations by proposing collapse-oriented (COLO) adversarial training with triplet decoupling (TRIDE). Specifically, COLO prevents model collapse by temporally orienting the perturbation update direction with a new collapse metric, while TRIDE yields a strong adversary by spatially decoupling the update targets of perturbation into the anchor and the two candidates of a triplet. Experimental results demonstrate that our COLO-TRIDE outperforms the current state of the art by 7% on average over 10 robustness metrics and across 3 popular datasets. In addition, we identify the fairness limitations of commonly used robustness metrics in image retrieval and propose a new metric for more meaningful robustness evaluation. Codes will be made publicly available on GitHub.
Long-term Dependency for 3D Reconstruction of Freehand Ultrasound Without External Tracker
Oct 16, 2023Objective: Reconstructing freehand ultrasound in 3D without any external tracker has been a long-standing challenge in ultrasound-assisted procedures. We aim to define new ways of parameterising long-term dependencies, and evaluate the performance. Methods: First, long-term dependency is encoded by transformation positions within a frame sequence. This is achieved by combining a sequence model with a multi-transformation prediction. Second, two dependency factors are proposed, anatomical image content and scanning protocol, for contributing towards accurate reconstruction. Each factor is quantified experimentally by reducing respective training variances. Results: 1) The added long-term dependency up to 400 frames at 20 frames per second (fps) indeed improved reconstruction, with an up to 82.4% lowered accumulated error, compared with the baseline performance. The improvement was found to be dependent on sequence length, transformation interval and scanning protocol and, unexpectedly, not on the use of recurrent networks with long-short term modules; 2) Decreasing either anatomical or protocol variance in training led to poorer reconstruction accuracy. Interestingly, greater performance was gained from representative protocol patterns, than from representative anatomical features. Conclusion: The proposed algorithm uses hyperparameter tuning to effectively utilise long-term dependency. The proposed dependency factors are of practical significance in collecting diverse training data, regulating scanning protocols and developing efficient networks. Significance: The proposed new methodology with publicly available volunteer data and code for parametersing the long-term dependency, experimentally shown to be valid sources of performance improvement, which could potentially lead to better model development and practical optimisation of the reconstruction application.
Towards Deep Learning Models Resistant to Transfer-based Adversarial Attacks via Data-centric Robust Learning
Oct 15, 2023Transfer-based adversarial attacks raise a severe threat to real-world deep learning systems since they do not require access to target models. Adversarial training (AT), which is recognized as the strongest defense against white-box attacks, has also guaranteed high robustness to (black-box) transfer-based attacks. However, AT suffers from heavy computational overhead since it optimizes the adversarial examples during the whole training process. In this paper, we demonstrate that such heavy optimization is not necessary for AT against transfer-based attacks. Instead, a one-shot adversarial augmentation prior to training is sufficient, and we name this new defense paradigm Data-centric Robust Learning (DRL). Our experimental results show that DRL outperforms widely-used AT techniques (e.g., PGD-AT, TRADES, EAT, and FAT) in terms of black-box robustness and even surpasses the top-1 defense on RobustBench when combined with diverse data augmentations and loss regularizations. We also identify other benefits of DRL, for instance, the model generalization capability and robust fairness.