 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VIndexer: A Generative Video Indexer for Efficient Text-Video Retrieval
Aug 21, 2024



Current text-video retrieval methods mainly rely on cross-modal matching between queries and videos to calculate their similarity scores, which are then sorted to obtain retrieval results. This method considers the matching between each candidate video and the query, but it incurs a significant time cost and will increase notably with the increase of candidates. Generative models are common in natural language processing and computer vision, and have been successfully applied in document retrieval, but their application in multimodal retrieval remains unexplored. To enhance retrieval efficiency, in this paper, we introduce a model-based video indexer named T2VIndexer, which is a sequence-to-sequence generative model directly generating video identifiers and retrieving candidate videos with constant time complexity. T2VIndexer aims to reduce retrieval time while maintaining high accuracy. To achieve this goal, we propose video identifier encoding and query-identifier augmentation approaches to represent videos as short sequences while preserving their semantic information. Our method consistently enhances the retrieval efficiency of current state-of-the-art models on four standard datasets. It enables baselines with only 30\%-50\% of the original retrieval time to achieve better retrieval performance on MSR-VTT (+1.0%), MSVD (+1.8%), ActivityNet (+1.5%), and DiDeMo (+0.2%). The code is available at https://github.com/Lilidamowang/T2VIndexer-generativeSearch.
Navigating Beyond Instructions: Vision-and-Language Navigation in Obstructed Environments
Jul 31, 2024Real-world navigation often involves dealing with unexpected obstructions such as closed doors, moved objects, and unpredictable entities. However, mainstream Vision-and-Language Navigation (VLN) tasks typically assume instructions perfectly align with the fixed and predefined navigation graphs without any obstructions. This assumption overlooks potential discrepancies in actual navigation graphs and given instructions, which can cause major failures for both indoor and outdoor agents. To address this issue, we integrate diverse obstructions into the R2R dataset by modifying both the navigation graphs and visual observations, introducing an innovative dataset and task, R2R with UNexpected Obstructions (R2R-UNO). R2R-UNO contains various types and numbers of path obstructions to generate instruction-reality mismatches for VLN research. Experiments on R2R-UNO reveal that state-of-the-art VLN methods inevitably encounter significant challenges when facing such mismatches, indicating that they rigidly follow instructions rather than navigate adaptively. Therefore, we propose a novel method called ObVLN (Obstructed VLN), which includes a curriculum training strategy and virtual graph construction to help agents effectively adapt to obstructed environments. Empirical results show that ObVLN not only maintains robust performance in unobstructed scenarios but also achieves a substantial performance advantage with unexpected obstructions.
XLIP: Cross-modal Attention Masked Modelling for Medical Language-Image Pre-Training
Jul 28, 2024



Vision-and-language pretraining (VLP) in the medical field utilizes contrastive learning on image-text pairs to achieve effective transfer across tasks. Yet, current VLP approaches with the masked modelling strategy face two challenges when applied to the medical domain. First, current models struggle to accurately reconstruct key pathological features due to the scarcity of medical data. Second, most methods only adopt either paired image-text or image-only data, failing to exploit the combination of both paired and unpaired data. To this end, this paper proposes a XLIP (Masked modelling for medical Language-Image Pre-training) framework to enhance pathological learning and feature learning via unpaired data. First, we introduce the attention-masked image modelling (AttMIM) and entity-driven masked language modelling module (EntMLM), which learns to reconstruct pathological visual and textual tokens via multi-modal feature interaction, thus improving medical-enhanced features. The AttMIM module masks a portion of the image features that are highly responsive to textual features. This allows XLIP to improve the reconstruction of highly similar image data in medicine efficiency. Second, our XLIP capitalizes unpaired data to enhance multimodal learning by introducing disease-kind prompts. The experimental results show that XLIP achieves SOTA for zero-shot and fine-tuning classification performance on five datasets. Our code will be available at https://github.com/White65534/XLIP
Visual-Semantic Decomposition and Partial Alignment for Document-based Zero-Shot Learning
Jul 23, 2024



Recent work shows that documents from encyclopedias serve as helpful auxiliary information for zero-shot learning. Existing methods align the entire semantics of a document with corresponding images to transfer knowledge. However, they disregard that semantic information is not equivalent between them, resulting in a suboptimal alignment. In this work, we propose a novel network to extract multi-view semantic concepts from documents and images and align the matching rather than entire concepts. Specifically, we propose a semantic decomposition module to generate multi-view semantic embeddings from visual and textual sides, providing the basic concepts for partial alignment. To alleviate the issue of information redundancy among embeddings, we propose the local-to-semantic variance loss to capture distinct local details and multiple semantic diversity loss to enforce orthogonality among embeddings. Subsequently, two losses are introduced to partially align visual-semantic embedding pairs according to their semantic relevance at the view and word-to-patch levels. Consequently, we consistently outperform state-of-the-art methods under two document sources in three standard benchmarks for document-based zero-shot learning. Qualitatively, we show that our model learns the interpretable partial association.
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
Jul 17, 2024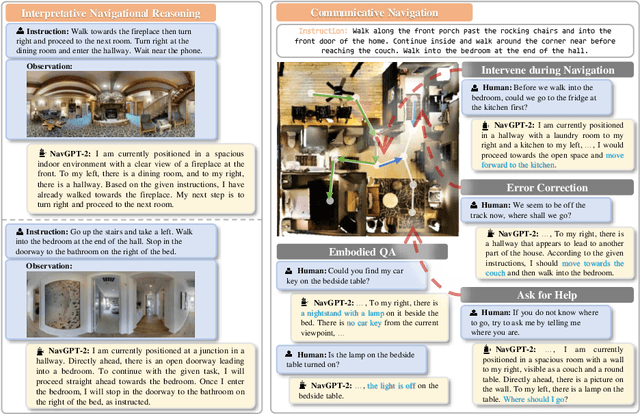
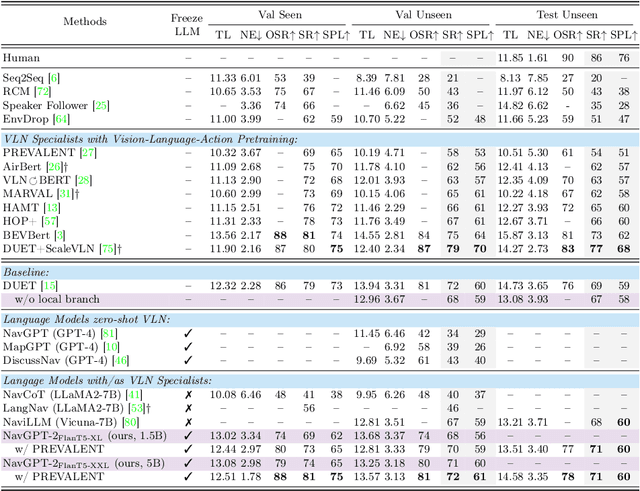
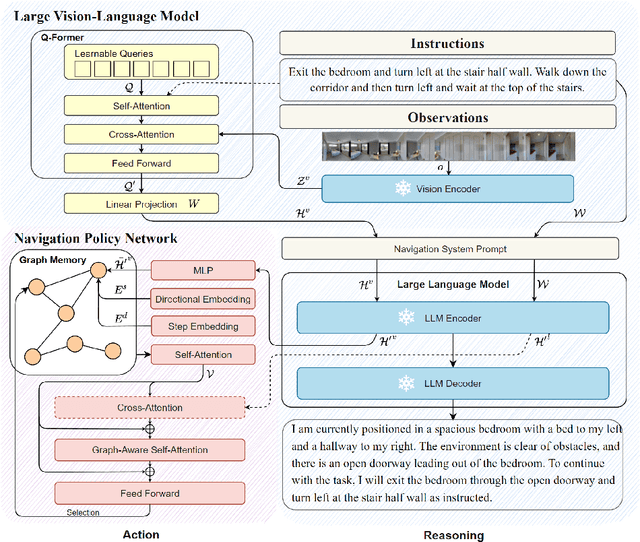

Capitalizing on the remarkable advancements in Large Language Models (LLMs), there is a burgeoning initiative to harness LLMs for instruction following robotic navigation. Such a trend underscores the potential of LLMs to generalize navigational reasoning and diverse language understanding. However, a significant discrepancy in agent performance is observed when integrating LLMs in the Vision-and-Language navigation (VLN) tasks compared to previous downstream specialist models. Furthermore, the inherent capacity of language to interpret and facilitate communication in agent interactions is often underutilized in these integrations. In this work, we strive to bridge the divide between VLN-specialized models and LLM-based navigation paradigms, while maintaining the interpretative prowess of LLMs in generating linguistic navigational reasoning. By aligning visual content in a frozen LLM, we encompass visual observation comprehension for LLMs and exploit a way to incorporate LLMs and navigation policy networks for effective action predictions and navigational reasoning. We demonstrate the data efficiency of the proposed methods and eliminate the gap between LM-based agents and state-of-the-art VLN specialists.
Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models
Jul 09, 2024


Vision-and-Language Navigation (VLN) has gained increasing attention over recent years and many approaches have emerged to advance their development. The remarkable achievements of foundation models have shaped the challenges and proposed methods for VLN research. In this survey, we provide a top-down review that adopts a principled framework for embodied planning and reasoning, and emphasizes the current methods and future opportunities leveraging foundation models to address VLN challenges. We hope our in-depth discussions could provide valuable resources and insights: on one hand, to milestone the progress and explore opportunities and potential roles for foundation models in this field, and on the other, to organize different challenges and solutions in VLN to foundation model researchers.
HumanPlus: Humanoid Shadowing and Imitation from Humans
Jun 15, 2024One of the key arguments for building robots that have similar form factors to human beings is that we can leverage the massive human data for training. Yet, doing so has remained challenging in practice due to the complexities in humanoid perception and control, lingering physical gaps between humanoids and humans in morphologies and actuation, and lack of a data pipeline for humanoids to learn autonomous skills from egocentric vision. In this paper, we introduce a full-stack system for humanoids to learn motion and autonomous skills from human data. We first train a low-level policy in simulation via reinforcement learning using existing 40-hour human motion datasets. This policy transfers to the real world and allows humanoid robots to follow human body and hand motion in real time using only a RGB camera, i.e. shadowing. Through shadowing, human operators can teleoperate humanoids to collect whole-body data for learning different tasks in the real world. Using the data collected, we then perform supervised behavior cloning to train skill policies using egocentric vision, allowing humanoids to complete different tasks autonomously by imitating human skills. We demonstrate the system on our customized 33-DoF 180cm humanoid, autonomously completing tasks such as wearing a shoe to stand up and walk, unloading objects from warehouse racks, folding a sweatshirt, rearranging objects, typing, and greeting another robot with 60-100% success rates using up to 40 demonstrations. Project website: https://humanoid-ai.github.io/
SMART: Scene-motion-aware human action recognition framework for mental disorder group
Jun 07, 2024



Patients with mental disorders often exhibit risky abnormal actions, such as climbing walls or hitting windows, necessitating intelligent video behavior monitoring for smart healthcare with the rising Internet of Things (IoT) technology. However, the development of vision-based Human Action Recognition (HAR) for these actions is hindered by the lack of specialized algorithms and datasets. In this paper, we innovatively propose to build a vision-based HAR dataset including abnormal actions often occurring in the mental disorder group and then introduce a novel Scene-Motion-aware Action Recognition Technology framework, named SMART, consisting of two technical modules. First, we propose a scene perception module to extract human motion trajectory and human-scene interaction features, which introduces additional scene information for a supplementary semantic representation of the above actions. Second, the multi-stage fusion module fuses the skeleton motion, motion trajectory, and human-scene interaction features, enhancing the semantic association between the skeleton motion and the above supplementary representation, thus generating a comprehensive representation with both human motion and scene information. The effectiveness of our proposed method has been validated on our self-collected HAR dataset (MentalHAD), achieving 94.9% and 93.1% accuracy in un-seen subjects and scenes and outperforming state-of-the-art approaches by 6.5% and 13.2%, respectively. The demonstrated subject- and scene- generalizability makes it possible for SMART's migration to practical deployment in smart healthcare systems for mental disorder patients in medical settings. The code and dataset will be released publicly for further research: https://github.com/Inowlzy/SMART.git.
Why Only Text: Empowering Vision-and-Language Navigation with Multi-modal Prompts
Jun 04, 2024



Current Vision-and-Language Navigation (VLN) tasks mainly employ textual instructions to guide agents. However, being inherently abstract, the same textual instruction can be associated with different visual signals, causing severe ambiguity and limiting the transfer of prior knowledge in the vision domain from the user to the agent. To fill this gap, we propose Vision-and-Language Navigation with Multi-modal Prompts (VLN-MP), a novel task augmenting traditional VLN by integrating both natural language and images in instructions. VLN-MP not only maintains backward compatibility by effectively handling text-only prompts but also consistently shows advantages with different quantities and relevance of visual prompts. Possible forms of visual prompts include both exact and similar object images, providing adaptability and versatility in diverse navigation scenarios. To evaluate VLN-MP under a unified framework, we implement a new benchmark that offers: (1) a training-free pipeline to transform textual instructions into multi-modal forms with landmark images; (2) diverse datasets with multi-modal instructions for different downstream tasks; (3) a novel module designed to process various image prompts for seamless integration with state-of-the-art VLN models. Extensive experiments on four VLN benchmarks (R2R, RxR, REVERIE, CVDN) show that incorporating visual prompts significantly boosts navigation performance. While maintaining efficiency with text-only prompts, VLN-MP enables agents to navigate in the pre-explore setting and outperform text-based models, showing its broader applicability.
Augmented Commonsense Knowledge for Remote Object Grounding
Jun 03, 2024



The vision-and-language navigation (VLN) task necessitates an agent to perceive the surroundings, follow natural language instructions, and act in photo-realistic unseen environments. Most of the existing methods employ the entire image or object features to represent navigable viewpoints. However, these representations are insufficient for proper action prediction, especially for the REVERIE task, which uses concise high-level instructions, such as ''Bring me the blue cushion in the master bedroom''. To address enhancing representation, we propose an augmented commonsense knowledge model (ACK) to leverage commonsense information as a spatio-temporal knowledge graph for improving agent navigation. Specifically, the proposed approach involves constructing a knowledge base by retrieving commonsense information from ConceptNet, followed by a refinement module to remove noisy and irrelevant knowledge. We further present ACK which consists of knowledge graph-aware cross-modal and concept aggregation modules to enhance visual representation and visual-textual data alignment by integrating visible objects, commonsense knowledge, and concept history, which includes object and knowledge temporal information. Moreover, we add a new pipeline for the commonsense-based decision-making process which leads to more accurate local action prediction. Experimental results demonstrate our proposed model noticeably outperforms the baseline and archives the state-of-the-art on the REVERIE benchmark.