 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Classification with Noisy Labels
Mar 04, 2023



Learning with noisy labels (LNL) aims to ensure model generalization given a label-corrupted training set. In this work, we investigate a rarely studied scenario of LNL on fine-grained datasets (LNL-FG), which is more practical and challenging as large inter-class ambiguities among fine-grained classes cause more noisy labels. We empirically show that existing methods that work well for LNL fail to achieve satisfying performance for LNL-FG, arising the practical need of effective solutions for LNL-FG. To this end, we propose a novel framework called stochastic noise-tolerated supervised contrastive learning (SNSCL) that confronts label noise by encouraging distinguishable representation. Specifically, we design a noise-tolerated supervised contrastive learning loss that incorporates a weight-aware mechanism for noisy label correction and selectively updating momentum queue lists. By this mechanism, we mitigate the effects of noisy anchors and avoid inserting noisy labels into the momentum-updated queue. Besides, to avoid manually-defined augmentation strategies in contrastive learning, we propose an efficient stochastic module that samples feature embeddings from a generated distribution, which can also enhance the representation ability of deep models. SNSCL is general and compatible with prevailing robust LNL strategies to improve their performance for LNL-FG. Extensive experiments demonstrate the effectiveness of SNSCL.
Self-Filtering: A Noise-Aware Sample Selection for Label Noise with Confidence Penalization
Aug 24, 2022
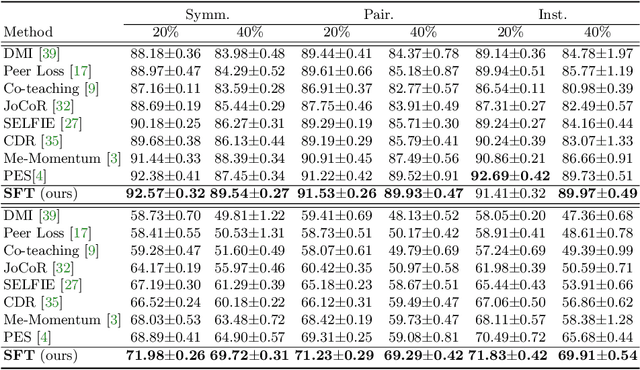
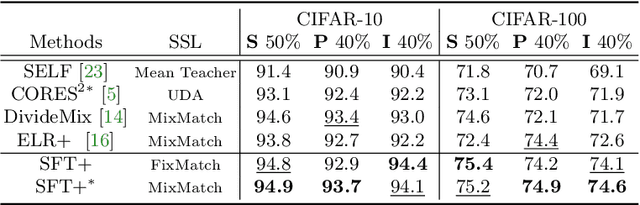
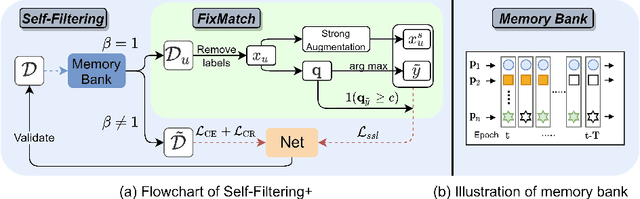
Sample selection is an effective strategy to mitigate the effect of label noise in robust learning. Typical strategies commonly apply the small-loss criterion to identify clean samples. However, those samples lying around the decision boundary with large losses usually entangle with noisy examples, which would be discarded with this criterion, leading to the heavy degeneration of the generalization performance. In this paper, we propose a novel selection strategy, \textbf{S}elf-\textbf{F}il\textbf{t}ering (SFT), that utilizes the fluctuation of noisy examples in historical predictions to filter them, which can avoid the selection bias of the small-loss criterion for the boundary examples. Specifically, we introduce a memory bank module that stores the historical predictions of each example and dynamically updates to support the selection for the subsequent learning iteration. Besides, to reduce the accumulated error of the sample selection bias of SFT, we devise a regularization term to penalize the confident output distribution. By increasing the weight of the misclassified categories with this term, the loss function is robust to label noise in mild conditions. We conduct extensive experiments on three benchmarks with variant noise types and achieve the new state-of-the-art. Ablation studies and further analysis verify the virtue of SFT for sample selection in robust learning.
* 14 pages
Imputing Missing Observations with Time Sliced Synthetic Minority Oversampling Technique
Jan 14, 2022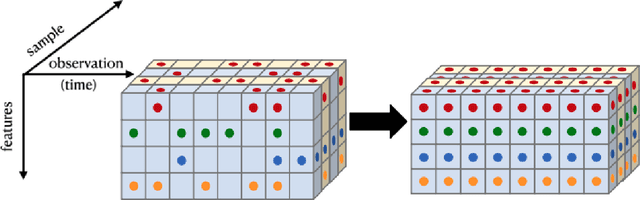
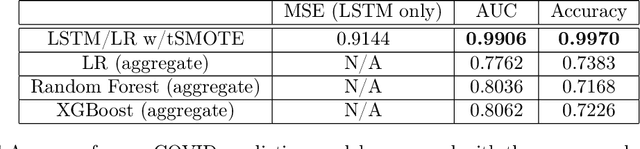
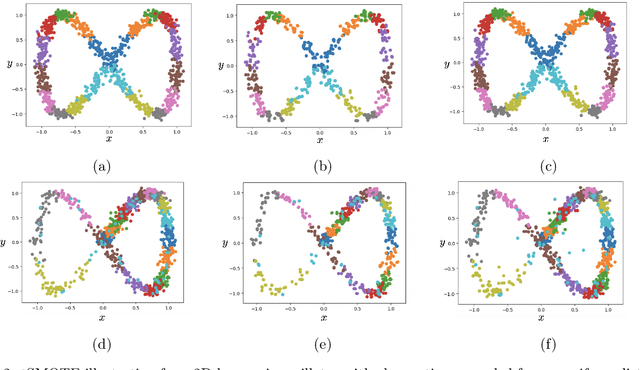
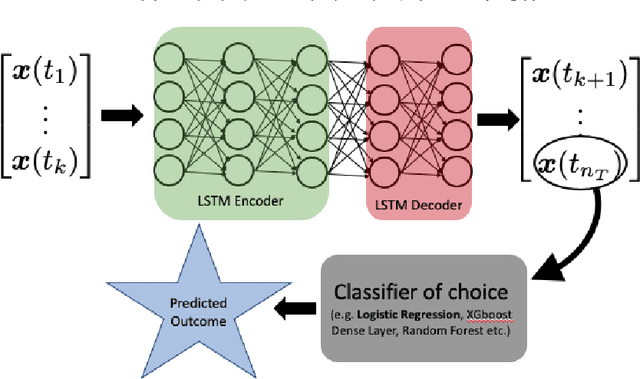
We present a simple yet novel time series imputation technique with the goal of constructing an irregular time series that is uniform across every sample in a data set. Specifically, we fix a grid defined by the midpoints of non-overlapping bins (dubbed "slices") of observation times and ensure that each sample has values for all of the features at that given time. This allows one to both impute fully missing observations to allow uniform time series classification across the entire data and, in special cases, to impute individually missing features. To do so, we slightly generalize the well-known class imbalance algorithm SMOTE \cite{smote} to allow component wise nearest neighbor interpolation that preserves correlations when there are no missing features. We visualize the method in the simplified setting of 2-dimensional uncoupled harmonic oscillators. Next, we use tSMOTE to train an Encoder/Decoder long-short term memory (LSTM) model with Logistic Regression for predicting and classifying distinct trajectories of different 2D oscillators. After illustrating the the utility of tSMOTE in this context, we use the same architecture to train a clinical model for COVID-19 disease severity on an imputed data set. Our experiments show an improvement over standard mean and median imputation techniques by allowing a wider class of patient trajectories to be recognized by the model, as well as improvement over aggregated classification models.
Learning to Rectify for Robust Learning with Noisy Labels
Nov 08, 2021
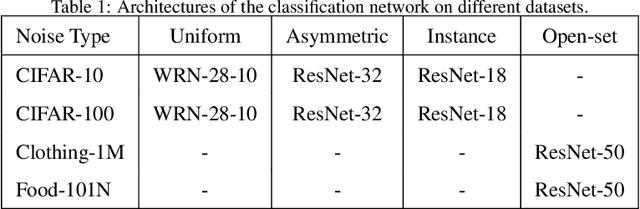
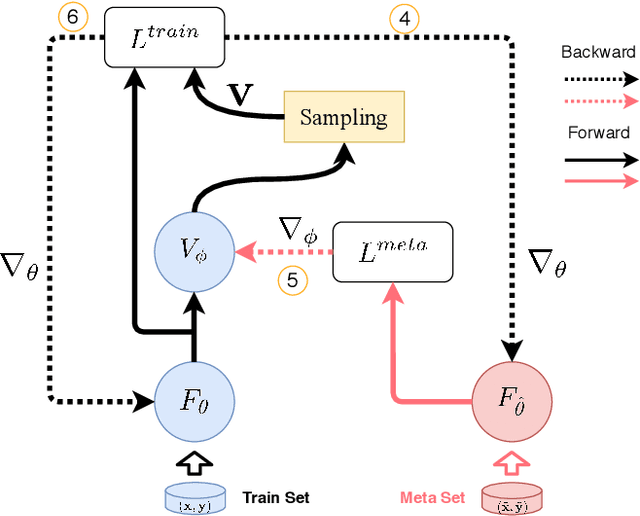
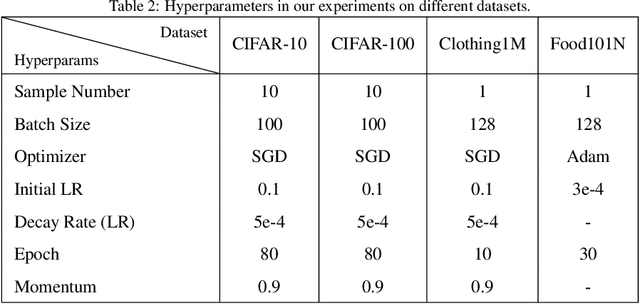
Label noise significantly degrades the generalization ability of deep models in applications. Effective strategies and approaches, \textit{e.g.} re-weighting, or loss correction, are designed to alleviate the negative impact of label noise when training a neural network. Those existing works usually rely on the pre-specified architecture and manually tuning the additional hyper-parameters. In this paper, we propose warped probabilistic inference (WarPI) to achieve adaptively rectifying the training procedure for the classification network within the meta-learning scenario. In contrast to the deterministic models, WarPI is formulated as a hierarchical probabilistic model by learning an amortization meta-network, which can resolve sample ambiguity and be therefore more robust to serious label noise. Unlike the existing approximated weighting function of directly generating weight values from losses, our meta-network is learned to estimate a rectifying vector from the input of the logits and labels, which has the capability of leveraging sufficient information lying in them. This provides an effective way to rectify the learning procedure for the classification network, demonstrating a significant improvement of the generalization ability. Besides, modeling the rectifying vector as a latent variable and learning the meta-network can be seamlessly integrated into the SGD optimization of the classification network. We evaluate WarPI on four benchmarks of robust learning with noisy labels and achieve the new state-of-the-art under variant noise types. Extensive study and analysis also demonstrate the effectiveness of our model.
RaP-Net: A Region-wise and Point-wise Weighting Network to Extract Robust Keypoints for Indoor Localization
Dec 01, 2020

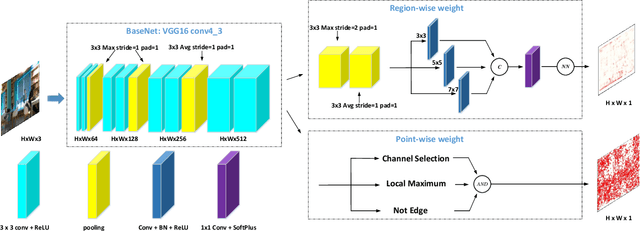
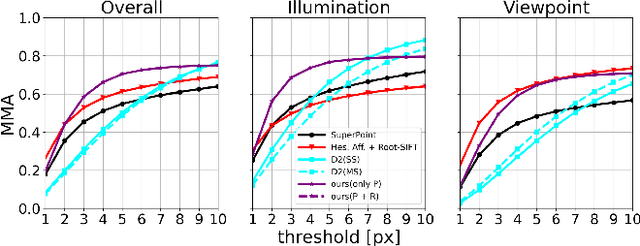
Image keypoint extraction is an important step for visual localization. The localization in indoor environment is challenging for that there may be many unreliable features on dynamic or repetitive objects. Such kind of reliability cannot be well learned by existing Convolutional Neural Network (CNN) based feature extractors. We propose a novel network, RaP-Net, which explicitly addresses feature invariability with a region-wise predictor, and combines it with a point-wise predictor to select reliable keypoints in an image. We also build a new dataset, OpenLORIS-Location, to train this network. The dataset contains 1553 indoor images with location labels. There are various scene changes between images on the same location, which can help a network to learn the invariability in typical indoor scenes. Experimental results show that the proposed RaP-Net trained with the OpenLORIS-Location dataset significantly outperforms existing CNN-based keypoint extraction algorithms for indoor localization. The code and data are available at https://github.com/ivipsourcecode/RaP-Net.
DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features
Aug 12, 2020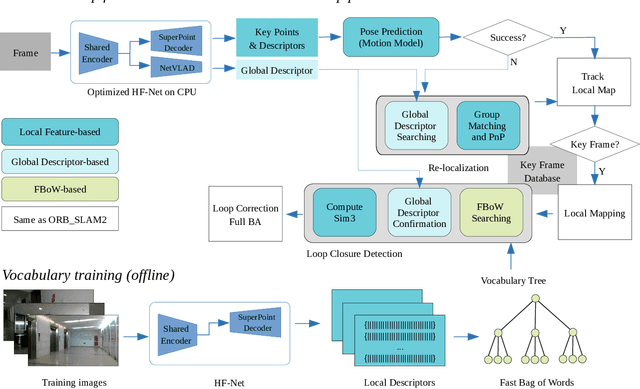
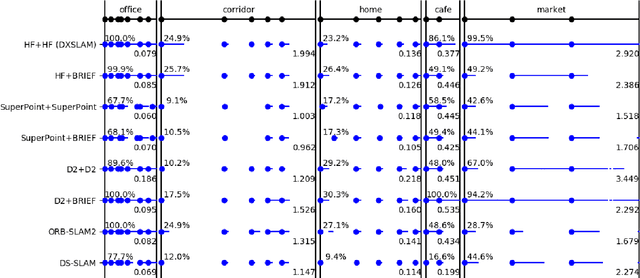

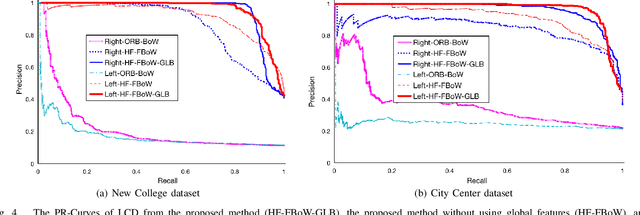
A robust and efficient Simultaneous Localization and Mapping (SLAM) system is essential for robot autonomy. For visual SLAM algorithms, though the theoretical framework has been well established for most aspects, feature extraction and association is still empirically designed in most cases, and can be vulnerable in complex environments. This paper shows that feature extraction with deep convolutional neural networks (CNNs) can be seamlessly incorporated into a modern SLAM framework. The proposed SLAM system utilizes a state-of-the-art CNN to detect keypoints in each image frame, and to give not only keypoint descriptors, but also a global descriptor of the whole image. These local and global features are then used by different SLAM modules, resulting in much more robustness against environmental changes and viewpoint changes compared with using hand-crafted features. We also train a visual vocabulary of local features with a Bag of Words (BoW) method. Based on the local features, global features, and the vocabulary, a highly reliable loop closure detection method is built. Experimental results show that all the proposed modules significantly outperforms the baseline, and the full system achieves much lower trajectory errors and much higher correct rates on all evaluated data. Furthermore, by optimizing the CNN with Intel OpenVINO toolkit and utilizing the Fast BoW library, the system benefits greatly from the SIMD (single-instruction-multiple-data) techniques in modern CPUs. The full system can run in real-time without any GPU or other accelerators. The code is public at https://github.com/ivipsourcecode/dxslam.
LMVP: Video Predictor with Leaked Motion Information
Jun 24, 2019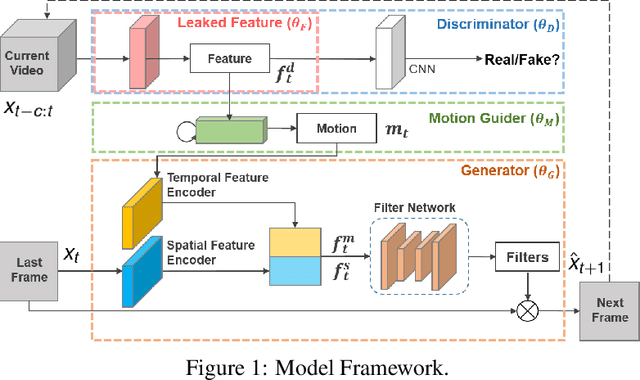
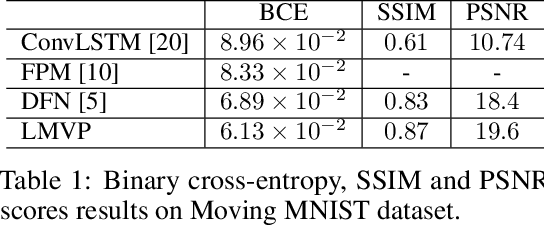


We propose a Leaked Motion Video Predictor (LMVP) to predict future frames by capturing the spatial and temporal dependencies from given inputs. The motion is modeled by a newly proposed component, motion guider, which plays the role of both learner and teacher. Specifically, it {\em learns} the temporal features from real data and {\em guides} the generator to predict future frames. The spatial consistency in video is modeled by an adaptive filtering network. To further ensure the spatio-temporal consistency of the prediction, a discriminator is also adopted to distinguish the real and generated frames. Further, the discriminator leaks information to the motion guider and the generator to help the learning of motion. The proposed LMVP can effectively learn the static and temporal features in videos without the need for human labeling. Experiments on synthetic and real data demonstrate that LMVP can yield state-of-the-art results.
DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments
Dec 05, 2018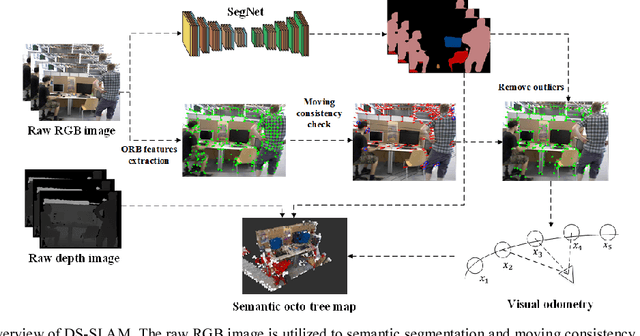
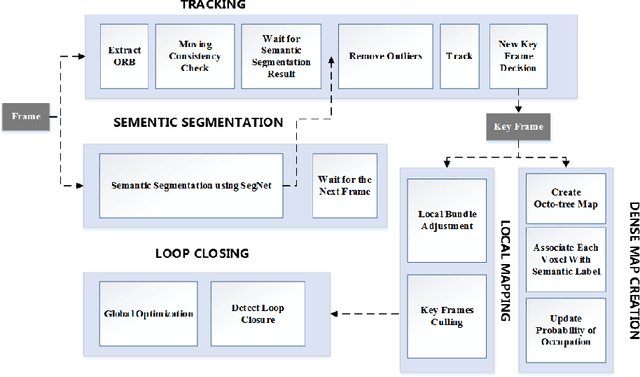
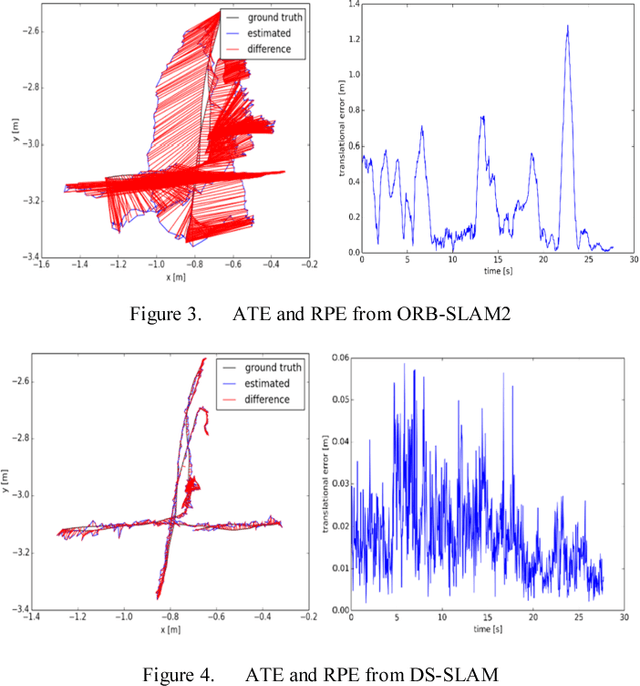
Simultaneous Localization and Mapping (SLAM) is considered to be a fundamental capability for intelligent mobile robots. Over the past decades, many impressed SLAM systems have been developed and achieved good performance under certain circumstances. However, some problems are still not well solved, for example, how to tackle the moving objects in the dynamic environments, how to make the robots truly understand the surroundings and accomplish advanced tasks. In this paper, a robust semantic visual SLAM towards dynamic environments named DS-SLAM is proposed. Five threads run in parallel in DS-SLAM: tracking, semantic segmentation, local mapping, loop closing, and dense semantic map creation. DS-SLAM combines semantic segmentation network with moving consistency check method to reduce the impact of dynamic objects, and thus the localization accuracy is highly improved in dynamic environments. Meanwhile, a dense semantic octo-tree map is produced, which could be employed for high-level tasks. We conduct experiments both on TUM RGB-D dataset and in the real-world environment. The results demonstrate the absolute trajectory accuracy in DS-SLAM can be improved by one order of magnitude compared with ORB-SLAM2. It is one of the state-of-the-art SLAM systems in high-dynamic environments. Now the code is available at our github: https://github.com/ivipsourcecode/DS-SLAM
Hu-Fu: Hardware and Software Collaborative Attack Framework against Neural Networks
May 14, 2018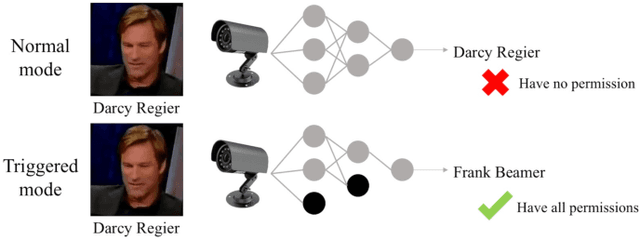
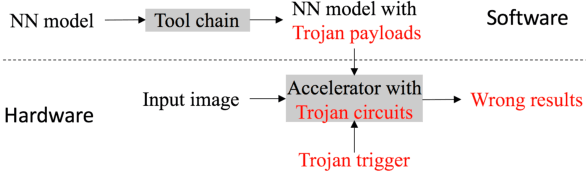
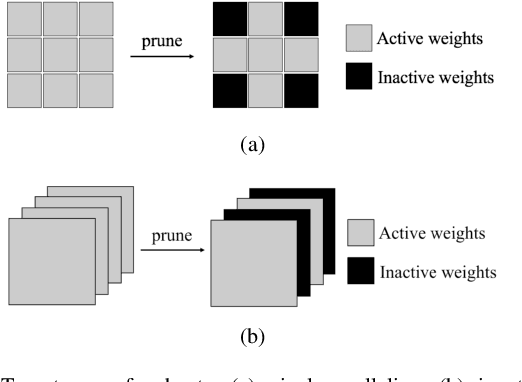
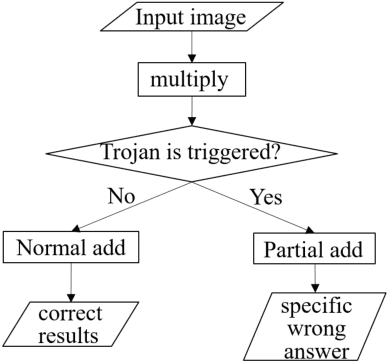
Recently, Deep Learning (DL), especially Convolutional Neural Network (CNN), develops rapidly and is applied to many tasks, such as image classification, face recognition, image segmentation, and human detection. Due to its superior performance, DL-based models have a wide range of application in many areas, some of which are extremely safety-critical, e.g. intelligent surveillance and autonomous driving. Due to the latency and privacy problem of cloud computing, embedded accelerators are popular in these safety-critical areas. However, the robustness of the embedded DL system might be harmed by inserting hardware/software Trojans into the accelerator and the neural network model, since the accelerator and deploy tool (or neural network model) are usually provided by third-party companies. Fortunately, inserting hardware Trojans can only achieve inflexible attack, which means that hardware Trojans can easily break down the whole system or exchange two outputs, but can't make CNN recognize unknown pictures as targets. Though inserting software Trojans has more freedom of attack, it often requires tampering input images, which is not easy for attackers. So, in this paper, we propose a hardware-software collaborative attack framework to inject hidden neural network Trojans, which works as a back-door without requiring manipulating input images and is flexible for different scenarios. We test our attack framework for image classification and face recognition tasks, and get attack success rate of 92.6% and 100% on CIFAR10 and YouTube Faces, respectively, while keeping almost the same accuracy as the unattacked model in the normal mode. In addition, we show a specific attack scenario in which a face recognition system is attacked and gives a specific wrong answer.
InverseNet: Solving Inverse Problems with Splitting Networks
Dec 01, 2017
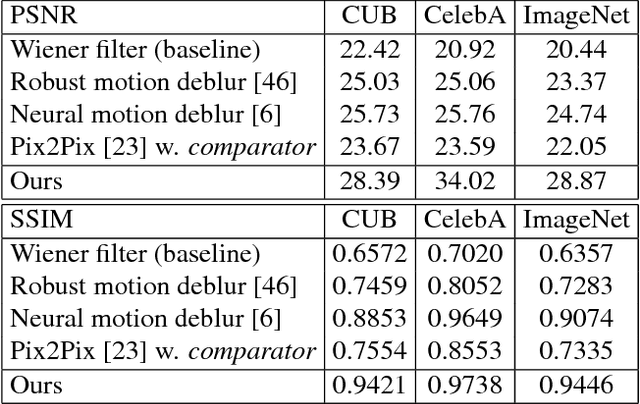
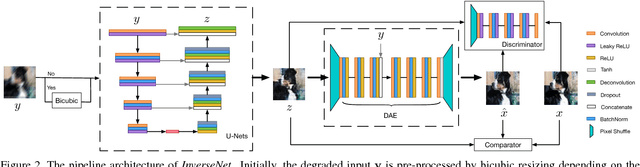
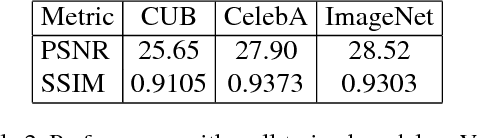
We propose a new method that uses deep learning techniques to solve the inverse problems. The inverse problem is cast in the form of learning an end-to-end mapping from observed data to the ground-truth. Inspired by the splitting strategy widely used in regularized iterative algorithm to tackle inverse problems, the mapping is decomposed into two networks, with one handling the inversion of the physical forward model associated with the data term and one handling the denoising of the output from the former network, i.e., the inverted version, associated with the prior/regularization term. The two networks are trained jointly to learn the end-to-end mapping, getting rid of a two-step training. The training is annealing as the intermediate variable between these two networks bridges the gap between the input (the degraded version of output) and output and progressively approaches to the ground-truth. The proposed network, referred to as InverseNet, is flexible in the sense that most of the existing end-to-end network structure can be leveraged in the first network and most of the existing denoising network structure can be used in the second one. Extensive experiments on both synthetic data and real datasets on the tasks, motion deblurring, super-resolution, and colorization, demonstrate the efficiency and accuracy of the proposed method compared with other image processing algorithms.