 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSV-Mamba: A Multiscale Vision Mamba Network for Echocardiography Segmentation
Jan 13, 2025



Ultrasound imaging frequently encounters challenges, such as those related to elevated noise levels, diminished spatiotemporal resolution, and the complexity of anatomical structures. These factors significantly hinder the model's ability to accurately capture and analyze structural relationships and dynamic patterns across various regions of the heart. Mamba, an emerging model, is one of the most cutting-edge approaches that is widely applied to diverse vision and language tasks. To this end, this paper introduces a U-shaped deep learning model incorporating a large-window Mamba scale (LMS) module and a hierarchical feature fusion approach for echocardiographic segmentation. First, a cascaded residual block serves as an encoder and is employed to incrementally extract multiscale detailed features. Second, a large-window multiscale mamba module is integrated into the decoder to capture global dependencies across regions and enhance the segmentation capability for complex anatomical structures. Furthermore, our model introduces auxiliary losses at each decoder layer and employs a dual attention mechanism to fuse multilayer features both spatially and across channels. This approach enhances segmentation performance and accuracy in delineating complex anatomical structures. Finally, the experimental results using the EchoNet-Dynamic and CAMUS datasets demonstrate that the model outperforms other methods in terms of both accuracy and robustness. For the segmentation of the left ventricular endocardium (${LV}_{endo}$), the model achieved optimal values of 95.01 and 93.36, respectively, while for the left ventricular epicardium (${LV}_{epi}$), values of 87.35 and 87.80, respectively, were achieved. This represents an improvement ranging between 0.54 and 1.11 compared with the best-performing model.
Harnessing Large Language Models for Disaster Management: A Survey
Jan 12, 2025



Large language models (LLMs) have revolutionized scientific research with their exceptional capabilities and transformed various fields. Among their practical applications, LLMs have been playing a crucial role in mitigating threats to human life, infrastructure, and the environment. Despite growing research in disaster LLMs, there remains a lack of systematic review and in-depth analysis of LLMs for natural disaster management. To address the gap, this paper presents a comprehensive survey of existing LLMs in natural disaster management, along with a taxonomy that categorizes existing works based on disaster phases and application scenarios. By collecting public datasets and identifying key challenges and opportunities, this study aims to guide the professional community in developing advanced LLMs for disaster management to enhance the resilience against natural disasters.
Re-Visible Dual-Domain Self-Supervised Deep Unfolding Network for MRI Reconstruction
Jan 07, 2025



Magnetic Resonance Imaging (MRI) is widely used in clinical practice, but suffered from prolonged acquisition time. Although deep learning methods have been proposed to accelerate acquisition and demonstrate promising performance, they rely on high-quality fully-sampled datasets for training in a supervised manner. However, such datasets are time-consuming and expensive-to-collect, which constrains their broader applications. On the other hand, self-supervised methods offer an alternative by enabling learning from under-sampled data alone, but most existing methods rely on further partitioned under-sampled k-space data as model's input for training, resulting in a loss of valuable information. Additionally, their models have not fully incorporated image priors, leading to degraded reconstruction performance. In this paper, we propose a novel re-visible dual-domain self-supervised deep unfolding network to address these issues when only under-sampled datasets are available. Specifically, by incorporating re-visible dual-domain loss, all under-sampled k-space data are utilized during training to mitigate information loss caused by further partitioning. This design enables the model to implicitly adapt to all under-sampled k-space data as input. Additionally, we design a deep unfolding network based on Chambolle and Pock Proximal Point Algorithm (DUN-CP-PPA) to achieve end-to-end reconstruction, incorporating imaging physics and image priors to guide the reconstruction process. By employing a Spatial-Frequency Feature Extraction (SFFE) block to capture global and local feature representation, we enhance the model's efficiency to learn comprehensive image priors. Experiments conducted on the fastMRI and IXI datasets demonstrate that our method significantly outperforms state-of-the-art approaches in terms of reconstruction performance.
KG-CF: Knowledge Graph Completion with Context Filtering under the Guidance of Large Language Models
Jan 06, 2025



Large Language Models (LLMs) have shown impressive performance in various tasks, including knowledge graph completion (KGC). However, current studies mostly apply LLMs to classification tasks, like identifying missing triplets, rather than ranking-based tasks, where the model ranks candidate entities based on plausibility. This focus limits the practical use of LLMs in KGC, as real-world applications prioritize highly plausible triplets. Additionally, while graph paths can help infer the existence of missing triplets and improve completion accuracy, they often contain redundant information. To address these issues, we propose KG-CF, a framework tailored for ranking-based KGC tasks. KG-CF leverages LLMs' reasoning abilities to filter out irrelevant contexts, achieving superior results on real-world datasets. The code and datasets are available at \url{https://anonymous.4open.science/r/KG-CF}.
Bridge the Inference Gaps of Neural Processes via Expectation Maximization
Jan 04, 2025



The neural process (NP) is a family of computationally efficient models for learning distributions over functions. However, it suffers from under-fitting and shows suboptimal performance in practice. Researchers have primarily focused on incorporating diverse structural inductive biases, \textit{e.g.} attention or convolution, in modeling. The topic of inference suboptimality and an analysis of the NP from the optimization objective perspective has hardly been studied in earlier work. To fix this issue, we propose a surrogate objective of the target log-likelihood of the meta dataset within the expectation maximization framework. The resulting model, referred to as the Self-normalized Importance weighted Neural Process (SI-NP), can learn a more accurate functional prior and has an improvement guarantee concerning the target log-likelihood. Experimental results show the competitive performance of SI-NP over other NPs objectives and illustrate that structural inductive biases, such as attention modules, can also augment our method to achieve SOTA performance. Our code is available at \url{https://github.com/hhq123gogogo/SI_NPs}.
MMO-IG: Multi-Class and Multi-Scale Object Image Generation for Remote Sensing
Dec 18, 2024



The rapid advancement of deep generative models (DGMs) has significantly advanced research in computer vision, providing a cost-effective alternative to acquiring vast quantities of expensive imagery. However, existing methods predominantly focus on synthesizing remote sensing (RS) images aligned with real images in a global layout view, which limits their applicability in RS image object detection (RSIOD) research. To address these challenges, we propose a multi-class and multi-scale object image generator based on DGMs, termed MMO-IG, designed to generate RS images with supervised object labels from global and local aspects simultaneously. Specifically, from the local view, MMO-IG encodes various RS instances using an iso-spacing instance map (ISIM). During the generation process, it decodes each instance region with iso-spacing value in ISIM-corresponding to both background and foreground instances-to produce RS images through the denoising process of diffusion models. Considering the complex interdependencies among MMOs, we construct a spatial-cross dependency knowledge graph (SCDKG). This ensures a realistic and reliable multidirectional distribution among MMOs for region embedding, thereby reducing the discrepancy between source and target domains. Besides, we propose a structured object distribution instruction (SODI) to guide the generation of synthesized RS image content from a global aspect with SCDKG-based ISIM together. Extensive experimental results demonstrate that our MMO-IG exhibits superior generation capabilities for RS images with dense MMO-supervised labels, and RS detectors pre-trained with MMO-IG show excellent performance on real-world datasets.
An Incremental Clustering Baseline for Event Detection on Twitter
Dec 16, 2024


Event detection in text streams is a crucial task for the analysis of online media and social networks. One of the current challenges in this field is establishing a performance standard while maintaining an acceptable level of computational complexity. In our study, we use an incremental clustering algorithm combined with recent advancements in sentence embeddings. Our objective is to compare our findings with previous studies, specifically those by Cao et al. (2024) and Mazoyer et al. (2020). Our results demonstrate significant improvements and could serve as a relevant baseline for future research in this area.
Unimodal and Multimodal Static Facial Expression Recognition for Virtual Reality Users with EmoHeVRDB
Dec 15, 2024



In this study, we explored the potential of utilizing Facial Expression Activations (FEAs) captured via the Meta Quest Pro Virtual Reality (VR) headset for Facial Expression Recognition (FER) in VR settings. Leveraging the EmojiHeroVR Database (EmoHeVRDB), we compared several unimodal approaches and achieved up to 73.02% accuracy for the static FER task with seven emotion categories. Furthermore, we integrated FEA and image data in multimodal approaches, observing significant improvements in recognition accuracy. An intermediate fusion approach achieved the highest accuracy of 80.42%, significantly surpassing the baseline evaluation result of 69.84% reported for EmoHeVRDB's image data. Our study is the first to utilize EmoHeVRDB's unique FEA data for unimodal and multimodal static FER, establishing new benchmarks for FER in VR settings. Our findings highlight the potential of fusing complementary modalities to enhance FER accuracy in VR settings, where conventional image-based methods are severely limited by the occlusion caused by Head-Mounted Displays (HMDs).
Separable Mixture of Low-Rank Adaptation for Continual Visual Instruction Tuning
Nov 21, 2024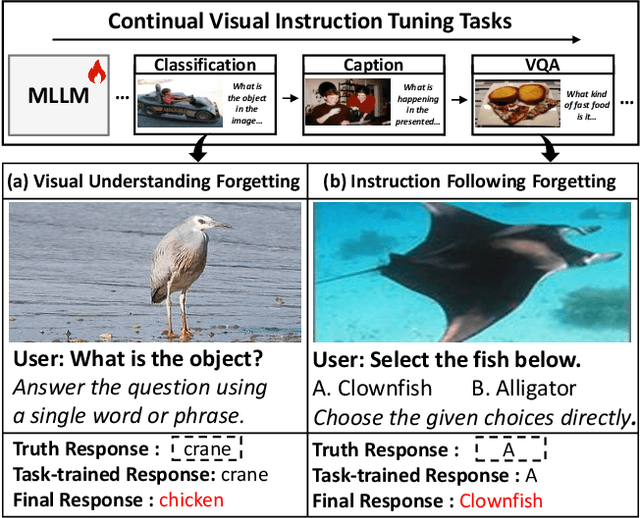
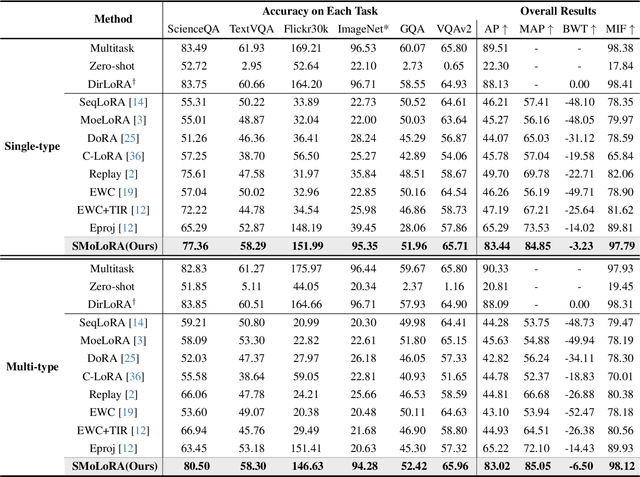
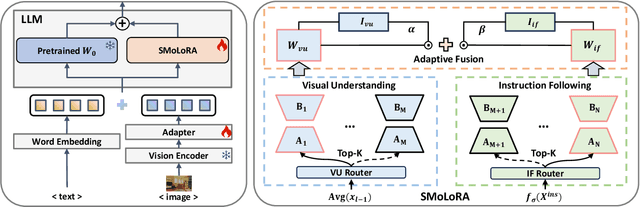
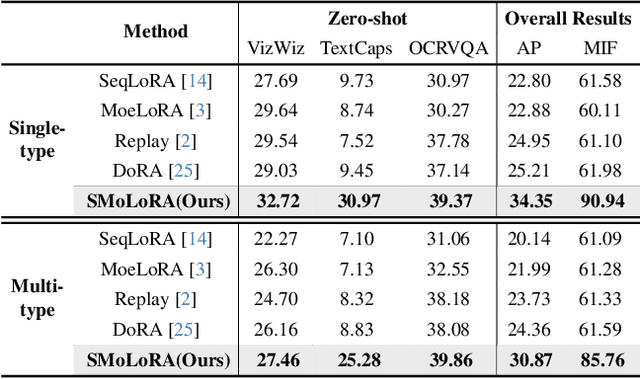
Visual instruction tuning (VIT) enables multimodal large language models (MLLMs) to effectively handle a wide range of vision tasks by framing them as language-based instructions. Building on this, continual visual instruction tuning (CVIT) extends the capability of MLLMs to incrementally learn new tasks, accommodating evolving functionalities. While prior work has advanced CVIT through the development of new benchmarks and approaches to mitigate catastrophic forgetting, these efforts largely follow traditional continual learning paradigms, neglecting the unique challenges specific to CVIT. We identify a dual form of catastrophic forgetting in CVIT, where MLLMs not only forget previously learned visual understanding but also experience a decline in instruction following abilities as they acquire new tasks. To address this, we introduce the Separable Mixture of Low-Rank Adaptation (SMoLoRA) framework, which employs separable routing through two distinct modules - one for visual understanding and another for instruction following. This dual-routing design enables specialized adaptation in both domains, preventing forgetting while improving performance. Furthermore, we propose a novel CVIT benchmark that goes beyond existing benchmarks by additionally evaluating a model's ability to generalize to unseen tasks and handle diverse instructions across various tasks. Extensive experiments demonstrate that SMoLoRA outperforms existing methods in mitigating dual forgetting, improving generalization to unseen tasks, and ensuring robustness in following diverse instructions.
Multi-perspective Contrastive Logit Distillation
Nov 16, 2024



We propose a novel and efficient logit distillation method, Multi-perspective Contrastive Logit Distillation (MCLD), which leverages contrastive learning to distill logits from multiple perspectives in knowledge distillation. Recent research on logit distillation has primarily focused on maximizing the information learned from the teacher model's logits to enhance the performance of the student model. To this end, we propose MCLD, which consists of three key components: Instance-wise CLD, Sample-wise CLD, and Category-wise CLD. These components are designed to facilitate the transfer of more information from the teacher's logits to the student model. Comprehensive evaluations on image classification tasks using CIFAR-100 and ImageNet, alongside representation transferability assessments on STL-10 and Tiny-ImageNet, highlight the significant advantages of our method. The knowledge distillation with our MCLD, surpasses existing state-of-the-art methods.