 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Super-Resolution with Recurrent Structure-Detail Network
Aug 02, 2020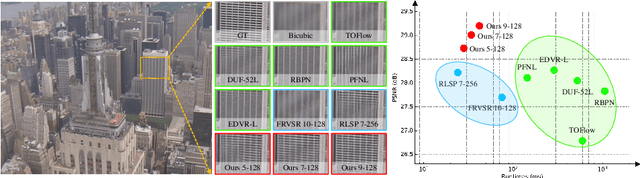

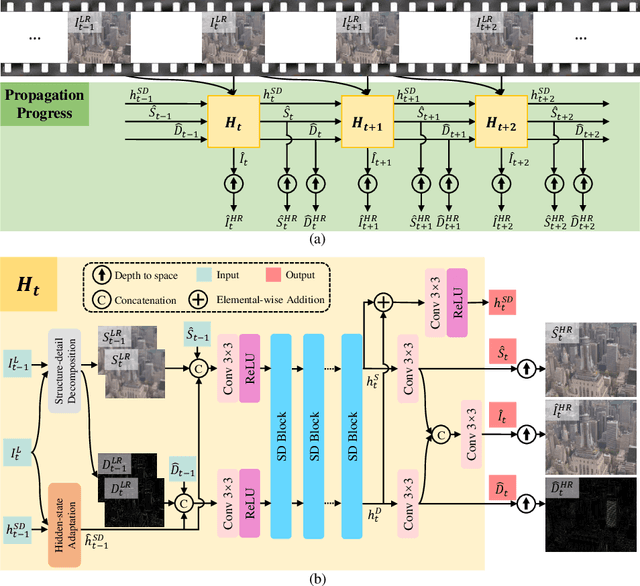

Most video super-resolution methods super-resolve a single reference frame with the help of neighboring frames in a temporal sliding window. They are less efficient compared to the recurrent-based methods. In this work, we propose a novel recurrent video super-resolution method which is both effective and efficient in exploiting previous frames to super-resolve the current frame. It divides the input into structure and detail components which are fed to a recurrent unit composed of several proposed two-stream structure-detail blocks. In addition, a hidden state adaptation module that allows the current frame to selectively use information from hidden state is introduced to enhance its robustness to appearance change and error accumulation. Extensive ablation study validate the effectiveness of the proposed modules. Experiments on several benchmark datasets demonstrate the superior performance of the proposed method compared to state-of-the-art methods on video super-resolution.
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
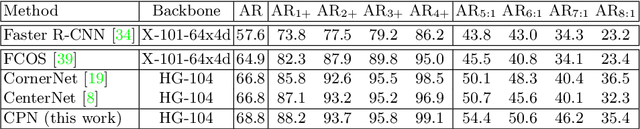

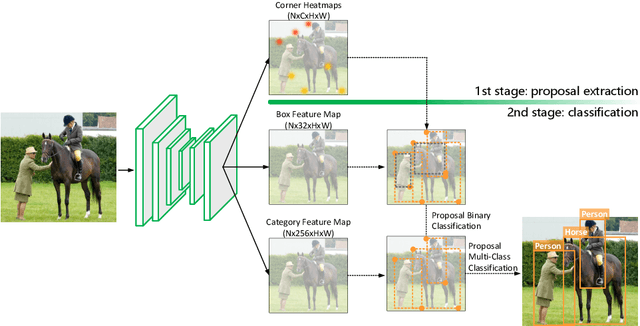
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
Learning Task-oriented Disentangled Representations for Unsupervised Domain Adaptation
Jul 27, 2020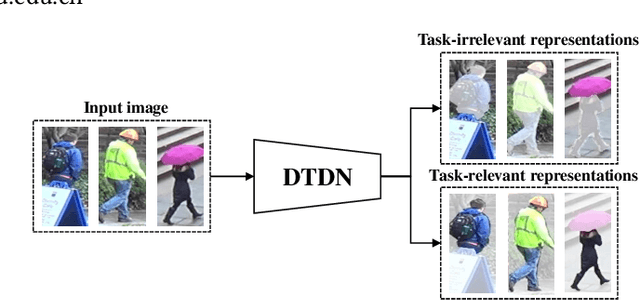
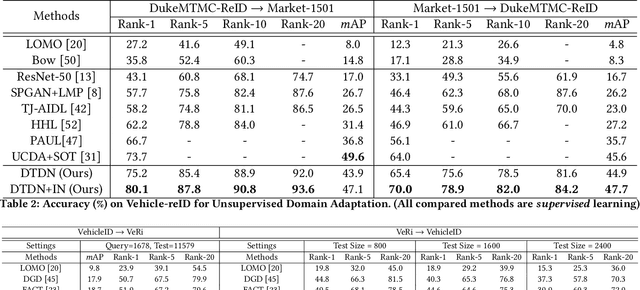
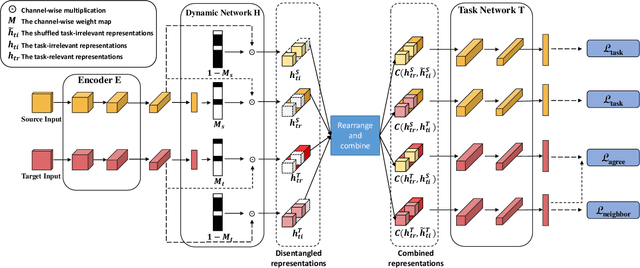
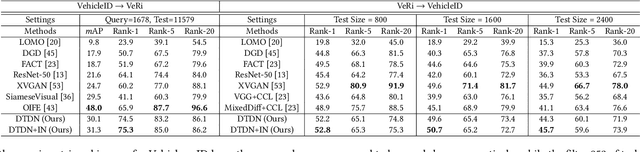
Unsupervised domain adaptation (UDA) aims to address the domain-shift problem between a labeled source domain and an unlabeled target domain. Many efforts have been made to address the mismatch between the distributions of training and testing data, but unfortunately, they ignore the task-oriented information across domains and are inflexible to perform well in complicated open-set scenarios. Many efforts have been made to eliminate the mismatch between the distributions of training and testing data by learning domain-invariant representations. However, the learned representations are usually not task-oriented, i.e., being class-discriminative and domain-transferable simultaneously. This drawback limits the flexibility of UDA in complicated open-set tasks where no labels are shared between domains. In this paper, we break the concept of task-orientation into task-relevance and task-irrelevance, and propose a dynamic task-oriented disentangling network (DTDN) to learn disentangled representations in an end-to-end fashion for UDA. The dynamic disentangling network effectively disentangles data representations into two components: the task-relevant ones embedding critical information associated with the task across domains, and the task-irrelevant ones with the remaining non-transferable or disturbing information. These two components are regularized by a group of task-specific objective functions across domains. Such regularization explicitly encourages disentangling and avoids the use of generative models or decoders. Experiments in complicated, open-set scenarios (retrieval tasks) and empirical benchmarks (classification tasks) demonstrate that the proposed method captures rich disentangled information and achieves superior performance.
Dual Distribution Alignment Network for Generalizable Person Re-Identification
Jul 27, 2020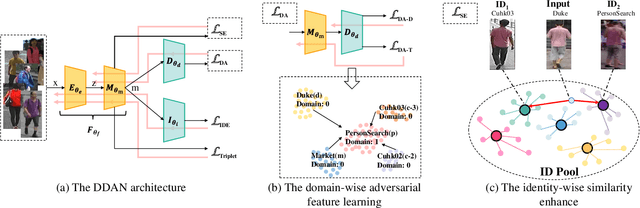
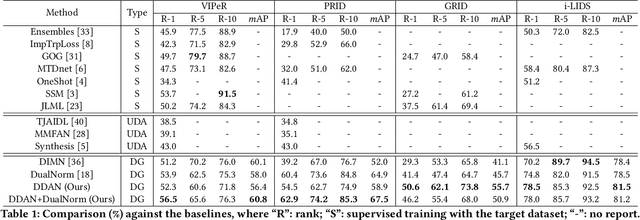
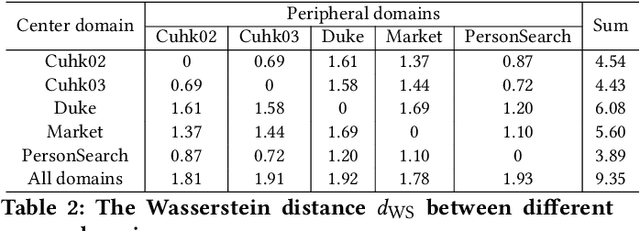
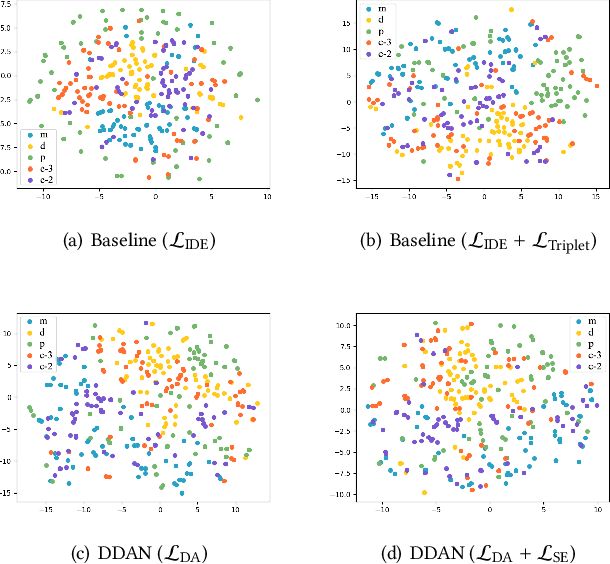
Domain generalization (DG) serves as a promising solution to handle person Re-Identification (Re-ID), which trains the model using labels from the source domain alone, and then directly adopts the trained model to the target domain without model updating. However, existing DG approaches are usually disturbed by serious domain variations due to significant dataset variations. Subsequently, DG highly relies on designing domain-invariant features, which is however not well exploited, since most existing approaches directly mix multiple datasets to train DG based models without considering the local dataset similarities, i.e., examples that are very similar but from different domains. In this paper, we present a Dual Distribution Alignment Network (DDAN), which handles this challenge by mapping images into a domain-invariant feature space by selectively aligning distributions of multiple source domains. Such an alignment is conducted by dual-level constraints, i.e., the domain-wise adversarial feature learning and the identity-wise similarity enhancement. We evaluate our DDAN on a large-scale Domain Generalization Re-ID (DG Re-ID) benchmark. Quantitative results demonstrate that the proposed DDAN can well align the distributions of various source domains, and significantly outperforms all existing domain generalization approaches.
Video Super-resolution with Temporal Group Attention
Jul 21, 2020
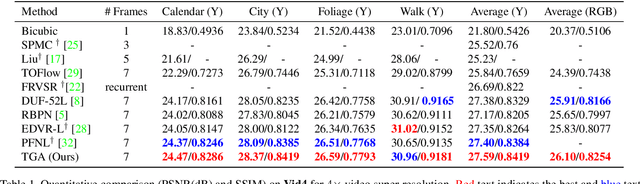
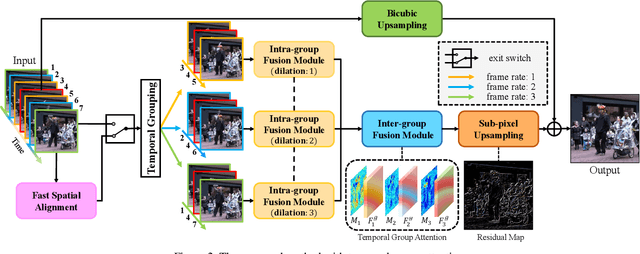

Video super-resolution, which aims at producing a high-resolution video from its corresponding low-resolution version, has recently drawn increasing attention. In this work, we propose a novel method that can effectively incorporate temporal information in a hierarchical way. The input sequence is divided into several groups, with each one corresponding to a kind of frame rate. These groups provide complementary information to recover missing details in the reference frame, which is further integrated with an attention module and a deep intra-group fusion module. In addition, a fast spatial alignment is proposed to handle videos with large motion. Extensive results demonstrate the capability of the proposed model in handling videos with various motion. It achieves favorable performance against state-of-the-art methods on several benchmark datasets.
Social Adaptive Module for Weakly-supervised Group Activity Recognition
Jul 18, 2020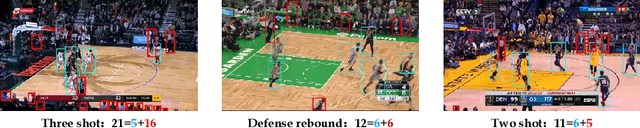
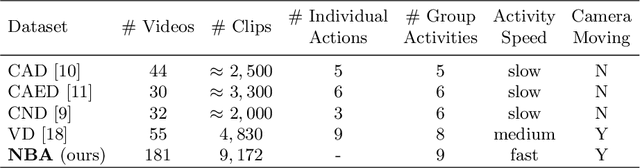

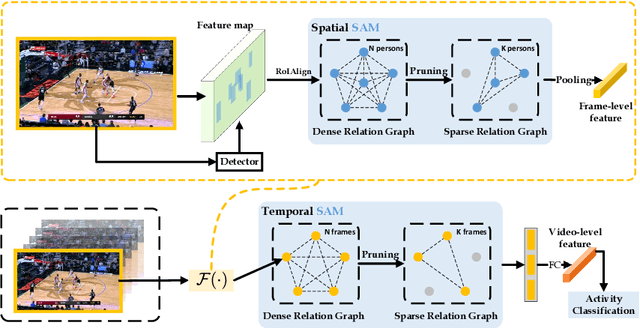
This paper presents a new task named weakly-supervised group activity recognition (GAR) which differs from conventional GAR tasks in that only video-level labels are available, yet the important persons within each frame are not provided even in the training data. This eases us to collect and annotate a large-scale NBA dataset and thus raise new challenges to GAR. To mine useful information from weak supervision, we present a key insight that key instances are likely to be related to each other, and thus design a social adaptive module (SAM) to reason about key persons and frames from noisy data. Experiments show significant improvement on the NBA dataset as well as the popular volleyball dataset. In particular, our model trained on video-level annotation achieves comparable accuracy to prior algorithms which required strong labels.
Wavelet-Based Dual-Branch Network for Image Demoireing
Jul 17, 2020

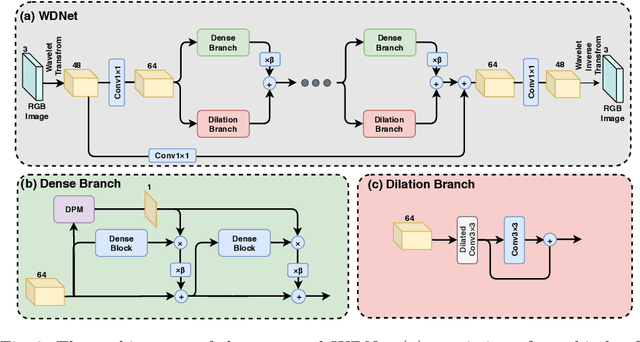

When smartphone cameras are used to take photos of digital screens, usually moire patterns result, severely degrading photo quality. In this paper, we design a wavelet-based dual-branch network (WDNet) with a spatial attention mechanism for image demoireing. Existing image restoration methods working in the RGB domain have difficulty in distinguishing moire patterns from true scene texture. Unlike these methods, our network removes moire patterns in the wavelet domain to separate the frequencies of moire patterns from the image content. The network combines dense convolution modules and dilated convolution modules supporting large receptive fields. Extensive experiments demonstrate the effectiveness of our method, and we further show that WDNet generalizes to removing moire artifacts on non-screen images. Although designed for image demoireing, WDNet has been applied to two other low-levelvision tasks, outperforming state-of-the-art image deraining and derain-drop methods on the Rain100h and Raindrop800 data sets, respectively.
ATSO: Asynchronous Teacher-Student Optimization for Semi-Supervised Medical Image Segmentation
Jul 16, 2020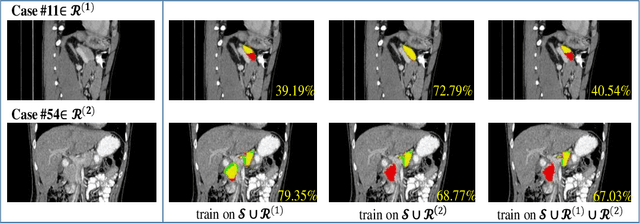
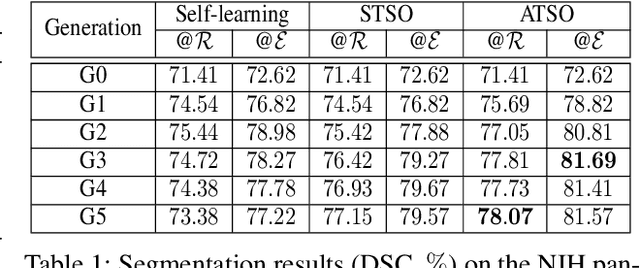
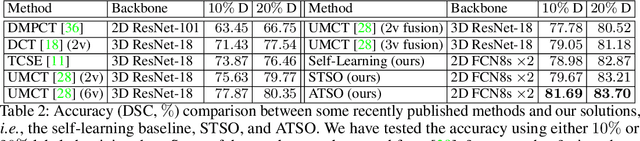
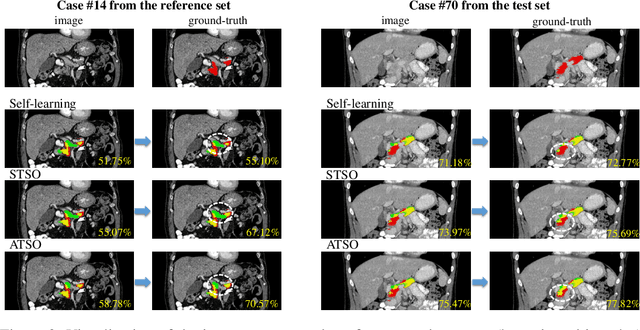
In medical image analysis, semi-supervised learning is an effective method to extract knowledge from a small amount of labeled data and a large amount of unlabeled data. This paper focuses on a popular pipeline known as self learning, and points out a weakness named lazy learning that refers to the difficulty for a model to learn from the pseudo labels generated by itself. To alleviate this issue, we propose ATSO, an asynchronous version of teacher-student optimization. ATSO partitions the unlabeled data into two subsets and alternately uses one subset to fine-tune the model and updates the label on the other subset. We evaluate ATSO on two popular medical image segmentation datasets and show its superior performance in various semi-supervised settings. With slight modification, ATSO transfers well to natural image segmentation for autonomous driving data.
Universal-to-Specific Framework for Complex Action Recognition
Jul 13, 2020
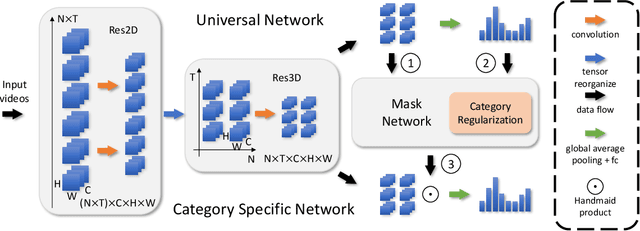

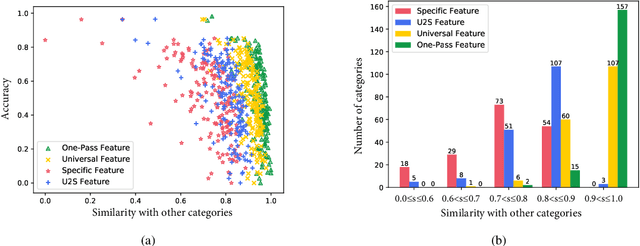
Video-based action recognition has recently attracted much attention in the field of computer vision. To solve more complex recognition tasks, it has become necessary to distinguish different levels of interclass variations. Inspired by a common flowchart based on the human decision-making process that first narrows down the probable classes and then applies a "rethinking" process for finer-level recognition, we propose an effective universal-to-specific (U2S) framework for complex action recognition. The U2S framework is composed of three subnetworks: a universal network, a category-specific network, and a mask network. The universal network first learns universal feature representations. The mask network then generates attention masks for confusing classes through category regularization based on the output of the universal network. The mask is further used to guide the category-specific network for class-specific feature representations. The entire framework is optimized in an end-to-end manner. Experiments on a variety of benchmark datasets, e.g., the Something-Something, UCF101, and HMDB51 datasets, demonstrate the effectiveness of the U2S framework; i.e., U2S can focus on discriminative spatiotemporal regions for confusing categories. We further visualize the relationship between different classes, showing that U2S indeed improves the discriminability of learned features. Moreover, the proposed U2S model is a general framework and may adopt any base recognition network.
GOLD-NAS: Gradual, One-Level, Differentiable
Jul 07, 2020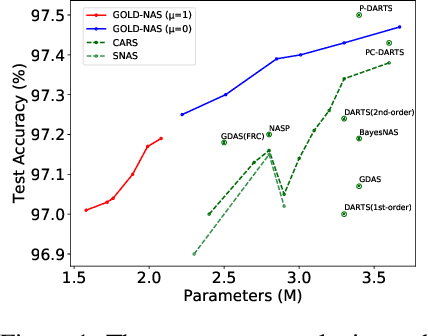
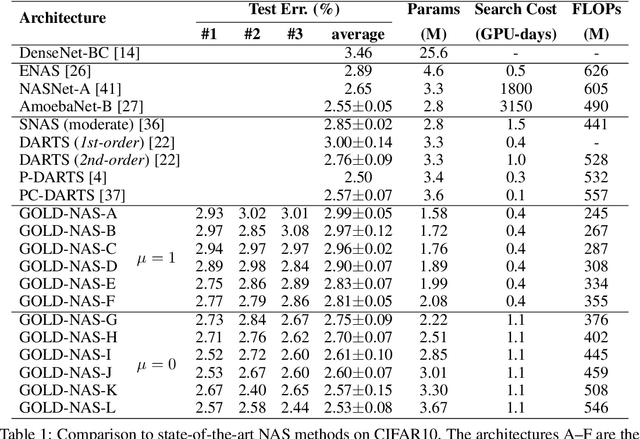
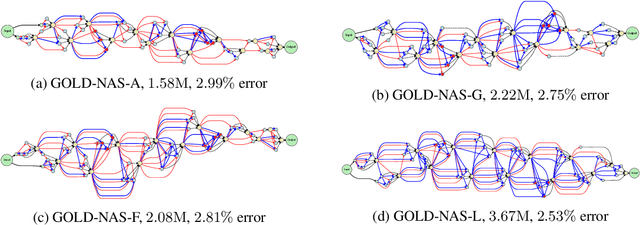
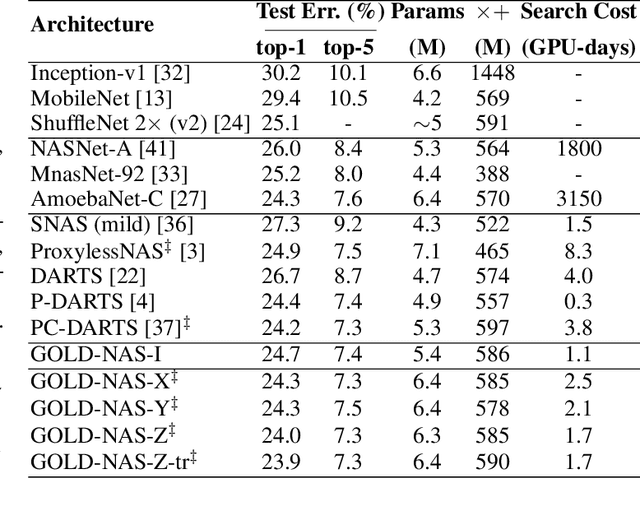
There has been a large literature of neural architecture search, but most existing work made use of heuristic rules that largely constrained the search flexibility. In this paper, we first relax these manually designed constraints and enlarge the search space to contain more than $10^{160}$ candidates. In the new space, most existing differentiable search methods can fail dramatically. We then propose a novel algorithm named Gradual One-Level Differentiable Neural Architecture Search (GOLD-NAS) which introduces a variable resource constraint to one-level optimization so that the weak operators are gradually pruned out from the super-network. In standard image classification benchmarks, GOLD-NAS can find a series of Pareto-optimal architectures within a single search procedure. Most of the discovered architectures were never studied before, yet they achieve a nice tradeoff between recognition accuracy and model complexity. We believe the new space and search algorithm can advance the search of differentiable NAS.