 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSG-Transformer: Exchanging Local Spatial Information by Manipulating Messenger Tokens
May 31, 2021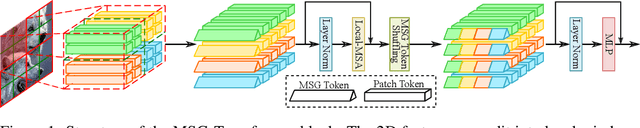
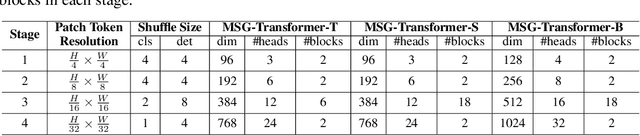
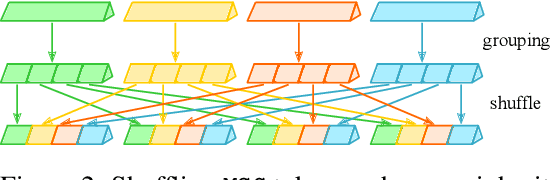
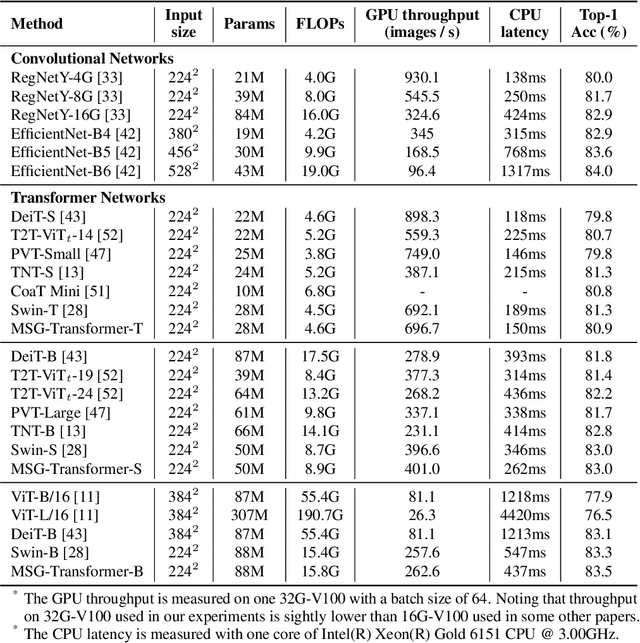
Transformers have offered a new methodology of designing neural networks for visual recognition. Compared to convolutional networks, Transformers enjoy the ability of referring to global features at each stage, yet the attention module brings higher computational overhead that obstructs the application of Transformers to process high-resolution visual data. This paper aims to alleviate the conflict between efficiency and flexibility, for which we propose a specialized token for each region that serves as a messenger (MSG). Hence, by manipulating these MSG tokens, one can flexibly exchange visual information across regions and the computational complexity is reduced. We then integrate the MSG token into a multi-scale architecture named MSG-Transformer. In standard image classification and object detection, MSG-Transformer achieves competitive performance and the inference on both GPU and CPU is accelerated. The code will be available at https://github.com/hustvl/MSG-Transformer.
What Is Considered Complete for Visual Recognition?
May 28, 2021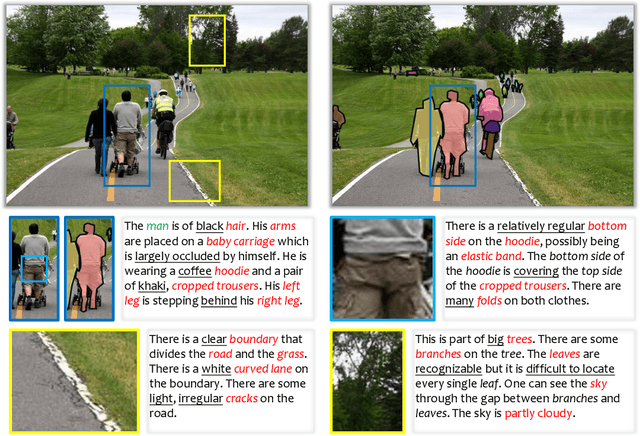


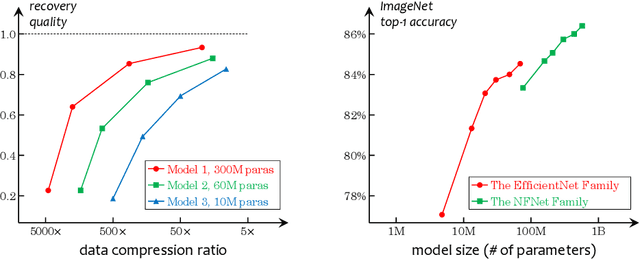
This is an opinion paper. We hope to deliver a key message that current visual recognition systems are far from complete, i.e., recognizing everything that human can recognize, yet it is very unlikely that the gap can be bridged by continuously increasing human annotations. Based on the observation, we advocate for a new type of pre-training task named learning-by-compression. The computational models (e.g., a deep network) are optimized to represent the visual data using compact features, and the features preserve the ability to recover the original data. Semantic annotations, when available, play the role of weak supervision. An important yet challenging issue is the evaluation of image recovery, where we suggest some design principles and future research directions. We hope our proposal can inspire the community to pursue the compression-recovery tradeoff rather than the accuracy-complexity tradeoff.
Towards Compact CNNs via Collaborative Compression
May 24, 2021
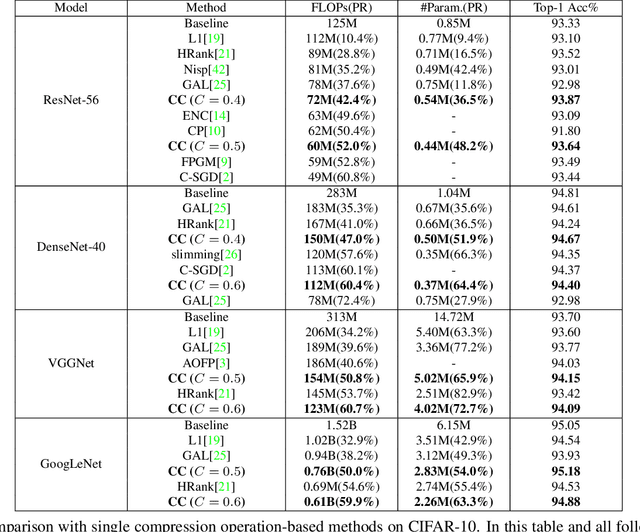
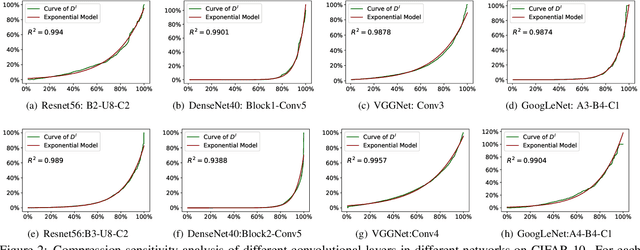
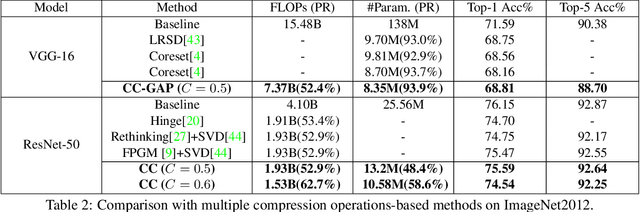
Channel pruning and tensor decomposition have received extensive attention in convolutional neural network compression. However, these two techniques are traditionally deployed in an isolated manner, leading to significant accuracy drop when pursuing high compression rates. In this paper, we propose a Collaborative Compression (CC) scheme, which joints channel pruning and tensor decomposition to compress CNN models by simultaneously learning the model sparsity and low-rankness. Specifically, we first investigate the compression sensitivity of each layer in the network, and then propose a Global Compression Rate Optimization that transforms the decision problem of compression rate into an optimization problem. After that, we propose multi-step heuristic compression to remove redundant compression units step-by-step, which fully considers the effect of the remaining compression space (i.e., unremoved compression units). Our method demonstrates superior performance gains over previous ones on various datasets and backbone architectures. For example, we achieve 52.9% FLOPs reduction by removing 48.4% parameters on ResNet-50 with only a Top-1 accuracy drop of 0.56% on ImageNet 2012.
A Fourier-based Framework for Domain Generalization
May 24, 2021
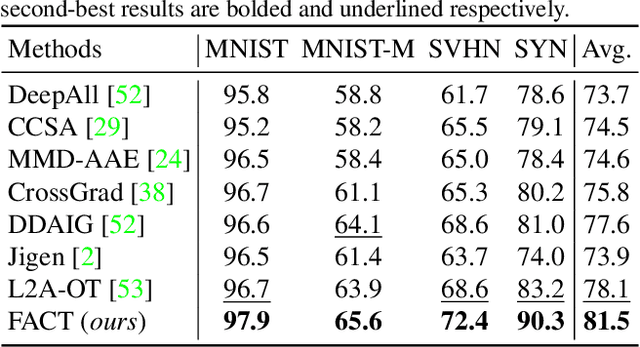
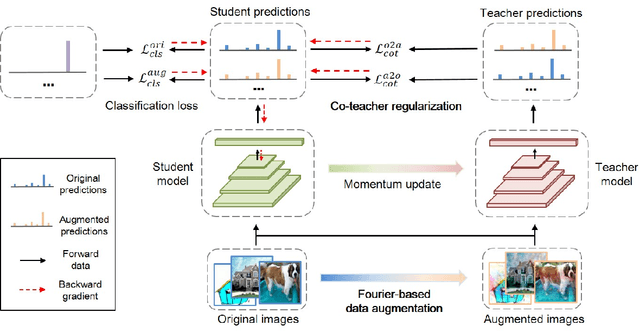
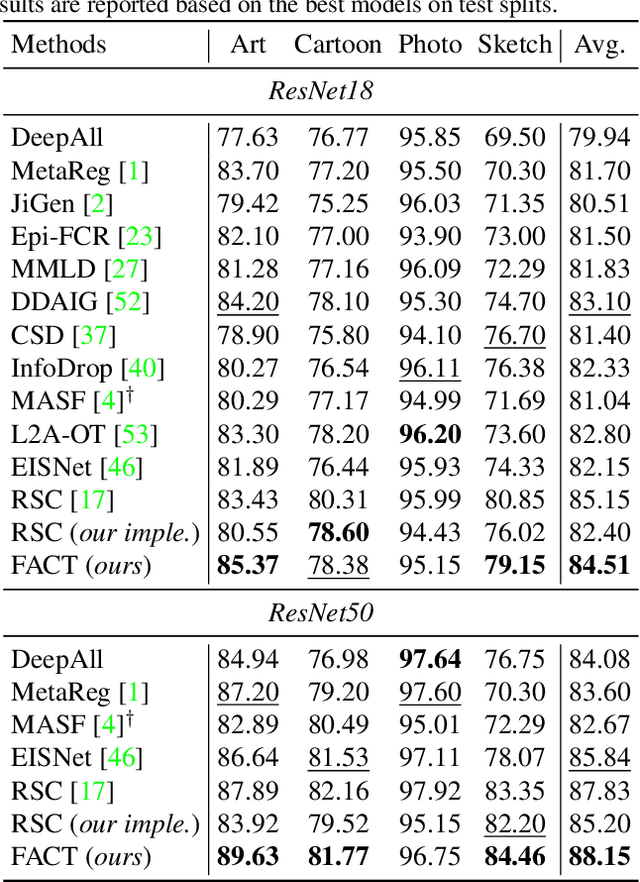
Modern deep neural networks suffer from performance degradation when evaluated on testing data under different distributions from training data. Domain generalization aims at tackling this problem by learning transferable knowledge from multiple source domains in order to generalize to unseen target domains. This paper introduces a novel Fourier-based perspective for domain generalization. The main assumption is that the Fourier phase information contains high-level semantics and is not easily affected by domain shifts. To force the model to capture phase information, we develop a novel Fourier-based data augmentation strategy called amplitude mix which linearly interpolates between the amplitude spectrums of two images. A dual-formed consistency loss called co-teacher regularization is further introduced between the predictions induced from original and augmented images. Extensive experiments on three benchmarks have demonstrated that the proposed method is able to achieve state-of-the-arts performance for domain generalization.
Semi-supervised Contrastive Learning with Similarity Co-calibration
May 16, 2021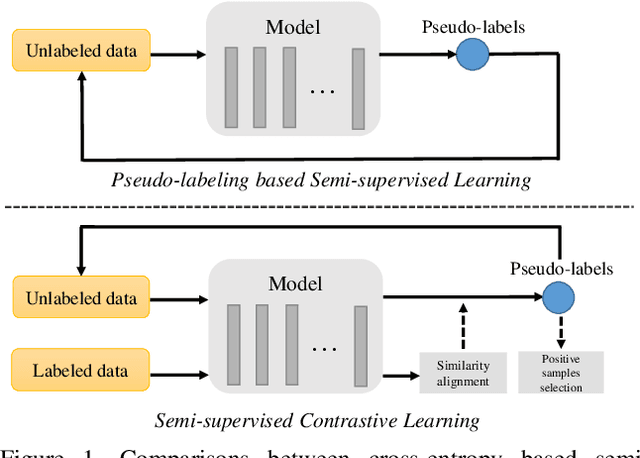
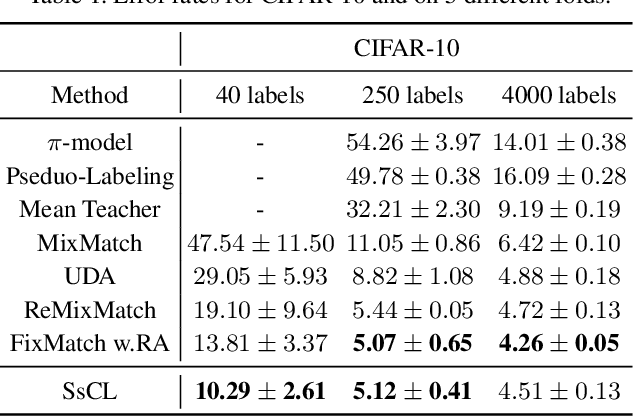
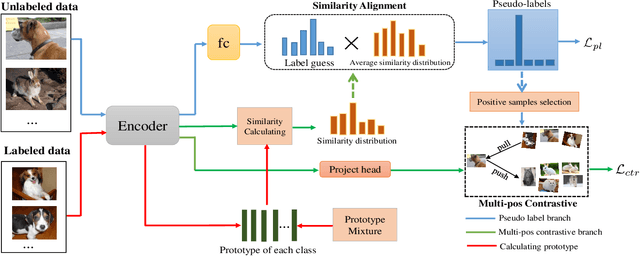
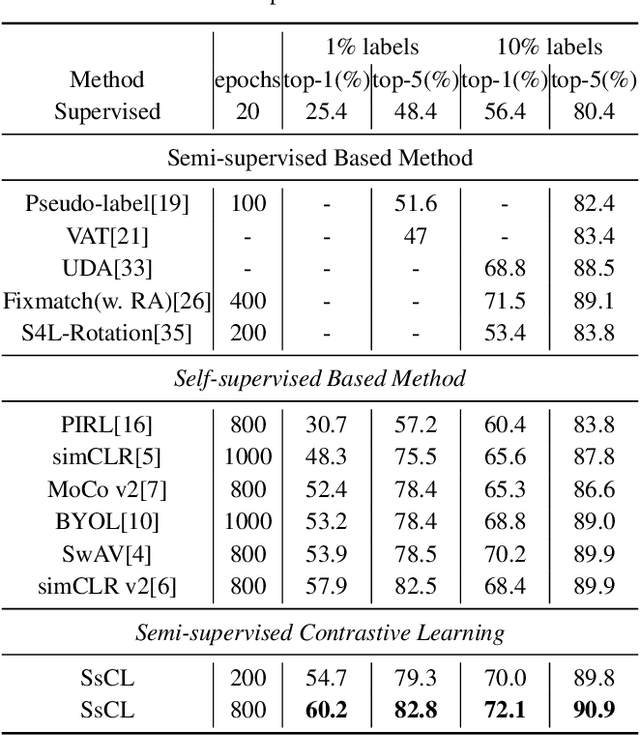
Semi-supervised learning acts as an effective way to leverage massive unlabeled data. In this paper, we propose a novel training strategy, termed as Semi-supervised Contrastive Learning (SsCL), which combines the well-known contrastive loss in self-supervised learning with the cross entropy loss in semi-supervised learning, and jointly optimizes the two objectives in an end-to-end way. The highlight is that different from self-training based semi-supervised learning that conducts prediction and retraining over the same model weights, SsCL interchanges the predictions over the unlabeled data between the two branches, and thus formulates a co-calibration procedure, which we find is beneficial for better prediction and avoid being trapped in local minimum. Towards this goal, the contrastive loss branch models pairwise similarities among samples, using the nearest neighborhood generated from the cross entropy branch, and in turn calibrates the prediction distribution of the cross entropy branch with the contrastive similarity. We show that SsCL produces more discriminative representation and is beneficial to few shot learning. Notably, on ImageNet with ResNet50 as the backbone, SsCL achieves 60.2% and 72.1% top-1 accuracy with 1% and 10% labeled samples, respectively, which significantly outperforms the baseline, and is better than previous semi-supervised and self-supervised methods.
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
May 12, 2021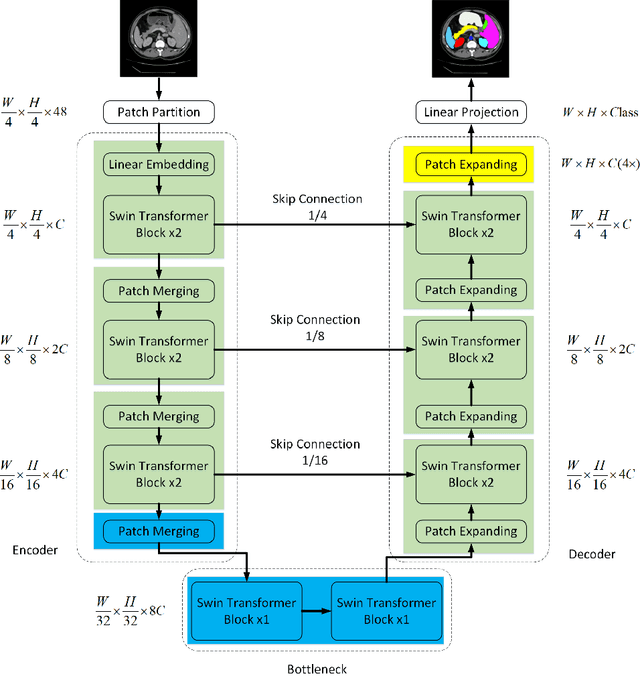
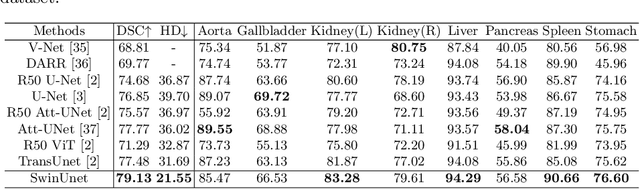
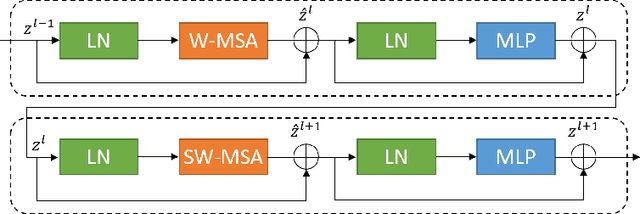
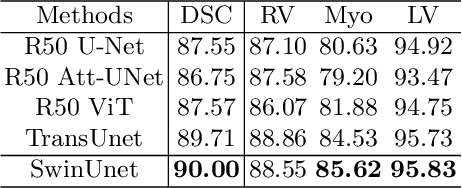
In the past few years, convolutional neural networks (CNNs) have achieved milestones in medical image analysis. Especially, the deep neural networks based on U-shaped architecture and skip-connections have been widely applied in a variety of medical image tasks. However, although CNN has achieved excellent performance, it cannot learn global and long-range semantic information interaction well due to the locality of the convolution operation. In this paper, we propose Swin-Unet, which is an Unet-like pure Transformer for medical image segmentation. The tokenized image patches are fed into the Transformer-based U-shaped Encoder-Decoder architecture with skip-connections for local-global semantic feature learning. Specifically, we use hierarchical Swin Transformer with shifted windows as the encoder to extract context features. And a symmetric Swin Transformer-based decoder with patch expanding layer is designed to perform the up-sampling operation to restore the spatial resolution of the feature maps. Under the direct down-sampling and up-sampling of the inputs and outputs by 4x, experiments on multi-organ and cardiac segmentation tasks demonstrate that the pure Transformer-based U-shaped Encoder-Decoder network outperforms those methods with full-convolution or the combination of transformer and convolution. The codes and trained models will be publicly available at https://github.com/HuCaoFighting/Swin-Unet.
Visformer: The Vision-friendly Transformer
Apr 27, 2021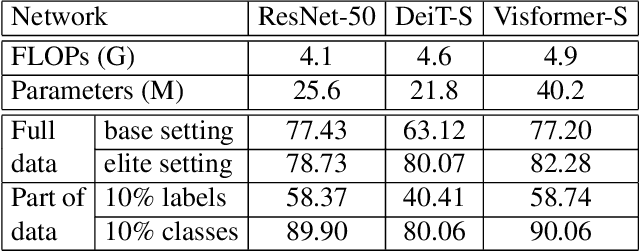
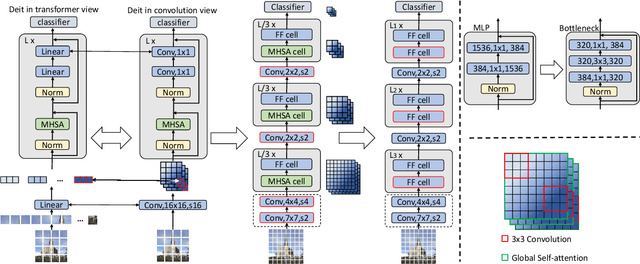
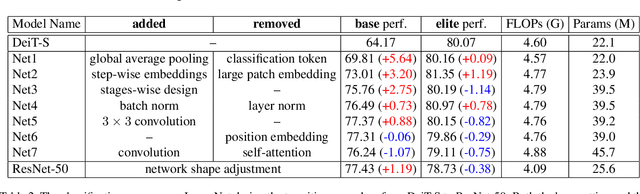
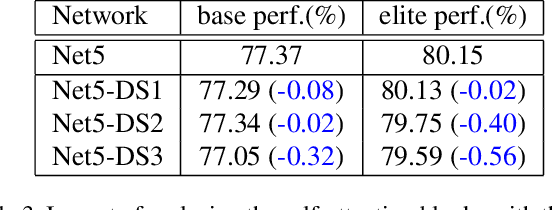
The past year has witnessed the rapid development of applying the Transformer module to vision problems. While some researchers have demonstrated that Transformer-based models enjoy a favorable ability of fitting data, there are still growing number of evidences showing that these models suffer over-fitting especially when the training data is limited. This paper offers an empirical study by performing step-by-step operations to gradually transit a Transformer-based model to a convolution-based model. The results we obtain during the transition process deliver useful messages for improving visual recognition. Based on these observations, we propose a new architecture named Visformer, which is abbreviated from the `Vision-friendly Transformer'. With the same computational complexity, Visformer outperforms both the Transformer-based and convolution-based models in terms of ImageNet classification accuracy, and the advantage becomes more significant when the model complexity is lower or the training set is smaller. The code is available at https://github.com/danczs/Visformer.
Location-Sensitive Visual Recognition with Cross-IOU Loss
Apr 11, 2021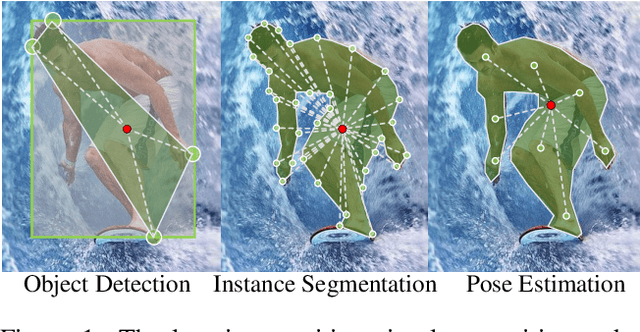
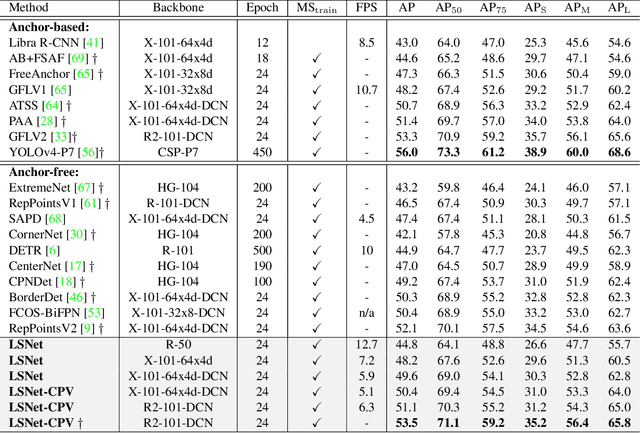
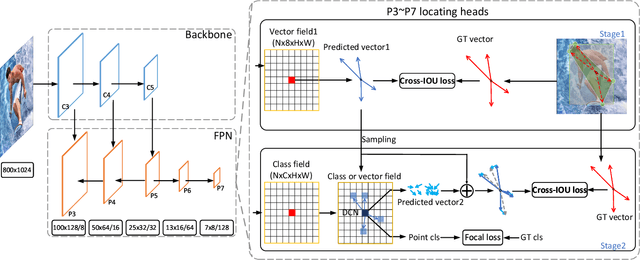
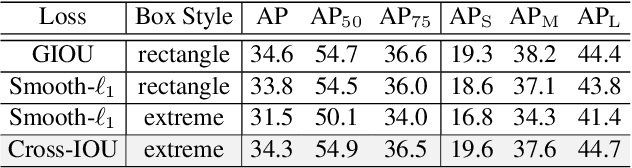
Object detection, instance segmentation, and pose estimation are popular visual recognition tasks which require localizing the object by internal or boundary landmarks. This paper summarizes these tasks as location-sensitive visual recognition and proposes a unified solution named location-sensitive network (LSNet). Based on a deep neural network as the backbone, LSNet predicts an anchor point and a set of landmarks which together define the shape of the target object. The key to optimizing the LSNet lies in the ability of fitting various scales, for which we design a novel loss function named cross-IOU loss that computes the cross-IOU of each anchor point-landmark pair to approximate the global IOU between the prediction and ground-truth. The flexibly located and accurately predicted landmarks also enable LSNet to incorporate richer contextual information for visual recognition. Evaluated on the MS-COCO dataset, LSNet set the new state-of-the-art accuracy for anchor-free object detection (a 53.5% box AP) and instance segmentation (a 40.2% mask AP), and shows promising performance in detecting multi-scale human poses. Code is available at https://github.com/Duankaiwen/LSNet
CondenseNet V2: Sparse Feature Reactivation for Deep Networks
Apr 09, 2021



Reusing features in deep networks through dense connectivity is an effective way to achieve high computational efficiency. The recent proposed CondenseNet has shown that this mechanism can be further improved if redundant features are removed. In this paper, we propose an alternative approach named sparse feature reactivation (SFR), aiming at actively increasing the utility of features for reusing. In the proposed network, named CondenseNetV2, each layer can simultaneously learn to 1) selectively reuse a set of most important features from preceding layers; and 2) actively update a set of preceding features to increase their utility for later layers. Our experiments show that the proposed models achieve promising performance on image classification (ImageNet and CIFAR) and object detection (MS COCO) in terms of both theoretical efficiency and practical speed.
Adaptive Mutual Supervision for Weakly-Supervised Temporal Action Localization
Apr 06, 2021


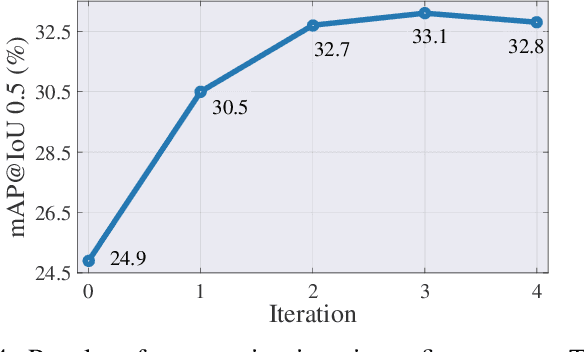
Weakly-supervised temporal action localization aims to localize actions in untrimmed videos with only video-level action category labels. Most of previous methods ignore the incompleteness issue of Class Activation Sequences (CAS), suffering from trivial localization results. To solve this issue, we introduce an adaptive mutual supervision framework (AMS) with two branches, where the base branch adopts CAS to localize the most discriminative action regions, while the supplementary branch localizes the less discriminative action regions through a novel adaptive sampler. The adaptive sampler dynamically updates the input of the supplementary branch with a sampling weight sequence negatively correlated with the CAS from the base branch, thereby prompting the supplementary branch to localize the action regions underestimated by the base branch. To promote mutual enhancement between these two branches, we construct mutual location supervision. Each branch leverages location pseudo-labels generated from the other branch as localization supervision. By alternately optimizing the two branches in multiple iterations, we progressively complete action regions. Extensive experiments on THUMOS14 and ActivityNet1.2 demonstrate that the proposed AMS method significantly outperforms the state-of-the-art methods.