 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoding for Scalable and Generalizable Decision Making
Nov 23, 2022We are interested in learning scalable agents for reinforcement learning that can learn from large-scale, diverse sequential data similar to current large vision and language models. To this end, this paper presents masked decision prediction (MaskDP), a simple and scalable self-supervised pretraining method for reinforcement learning (RL) and behavioral cloning (BC). In our MaskDP approach, we employ a masked autoencoder (MAE) to state-action trajectories, wherein we randomly mask state and action tokens and reconstruct the missing data. By doing so, the model is required to infer masked-out states and actions and extract information about dynamics. We find that masking different proportions of the input sequence significantly helps with learning a better model that generalizes well to multiple downstream tasks. In our empirical study, we find that a MaskDP model gains the capability of zero-shot transfer to new BC tasks, such as single and multiple goal reaching, and it can zero-shot infer skills from a few example transitions. In addition, MaskDP transfers well to offline RL and shows promising scaling behavior w.r.t. to model size. It is amenable to data-efficient finetuning, achieving competitive results with prior methods based on autoregressive pretraining.
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models
Nov 21, 2022Diffusion models have shown impressive results in text-to-image synthesis. Using massive datasets of captioned images, diffusion models learn to generate raster images of highly diverse objects and scenes. However, designers frequently use vector representations of images like Scalable Vector Graphics (SVGs) for digital icons or art. Vector graphics can be scaled to any size, and are compact. We show that a text-conditioned diffusion model trained on pixel representations of images can be used to generate SVG-exportable vector graphics. We do so without access to large datasets of captioned SVGs. By optimizing a differentiable vector graphics rasterizer, our method, VectorFusion, distills abstract semantic knowledge out of a pretrained diffusion model. Inspired by recent text-to-3D work, we learn an SVG consistent with a caption using Score Distillation Sampling. To accelerate generation and improve fidelity, VectorFusion also initializes from an image sample. Experiments show greater quality than prior work, and demonstrate a range of styles including pixel art and sketches. See our project webpage at https://ajayj.com/vectorfusion .
StereoPose: Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS
Nov 03, 2022



Most existing methods for category-level pose estimation rely on object point clouds. However, when considering transparent objects, depth cameras are usually not able to capture meaningful data, resulting in point clouds with severe artifacts. Without a high-quality point cloud, existing methods are not applicable to challenging transparent objects. To tackle this problem, we present StereoPose, a novel stereo image framework for category-level object pose estimation, ideally suited for transparent objects. For a robust estimation from pure stereo images, we develop a pipeline that decouples category-level pose estimation into object size estimation, initial pose estimation, and pose refinement. StereoPose then estimates object pose based on representation in the normalized object coordinate space~(NOCS). To address the issue of image content aliasing, we further define a back-view NOCS map for the transparent object. The back-view NOCS aims to reduce the network learning ambiguity caused by content aliasing, and leverage informative cues on the back of the transparent object for more accurate pose estimation. To further improve the performance of the stereo framework, StereoPose is equipped with a parallax attention module for stereo feature fusion and an epipolar loss for improving the stereo-view consistency of network predictions. Extensive experiments on the public TOD dataset demonstrate the superiority of the proposed StereoPose framework for category-level 6D transparent object pose estimation.
Sim-to-Real via Sim-to-Seg: End-to-end Off-road Autonomous Driving Without Real Data
Oct 25, 2022



Autonomous driving is complex, requiring sophisticated 3D scene understanding, localization, mapping, and control. Rather than explicitly modelling and fusing each of these components, we instead consider an end-to-end approach via reinforcement learning (RL). However, collecting exploration driving data in the real world is impractical and dangerous. While training in simulation and deploying visual sim-to-real techniques has worked well for robot manipulation, deploying beyond controlled workspace viewpoints remains a challenge. In this paper, we address this challenge by presenting Sim2Seg, a re-imagining of RCAN that crosses the visual reality gap for off-road autonomous driving, without using any real-world data. This is done by learning to translate randomized simulation images into simulated segmentation and depth maps, subsequently enabling real-world images to also be translated. This allows us to train an end-to-end RL policy in simulation, and directly deploy in the real-world. Our approach, which can be trained in 48 hours on 1 GPU, can perform equally as well as a classical perception and control stack that took thousands of engineering hours over several months to build. We hope this work motivates future end-to-end autonomous driving research.
Instruction-Following Agents with Jointly Pre-Trained Vision-Language Models
Oct 24, 2022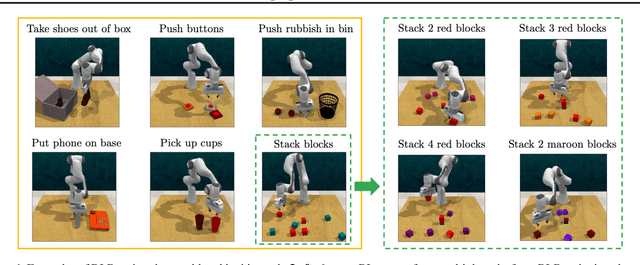
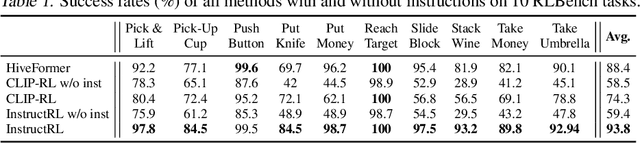
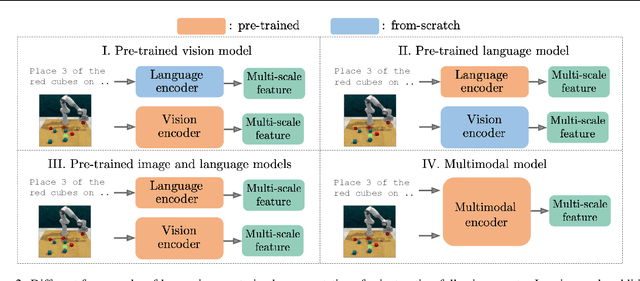

Humans are excellent at understanding language and vision to accomplish a wide range of tasks. In contrast, creating general instruction-following embodied agents remains a difficult challenge. Prior work that uses pure language-only models lack visual grounding, making it difficult to connect language instructions with visual observations. On the other hand, methods that use pre-trained vision-language models typically come with divided language and visual representations, requiring designing specialized network architecture to fuse them together. We propose a simple yet effective model for robots to solve instruction-following tasks in vision-based environments. Our \ours method consists of a multimodal transformer that encodes visual observations and language instructions, and a policy transformer that predicts actions based on encoded representations. The multimodal transformer is pre-trained on millions of image-text pairs and natural language text, thereby producing generic cross-modal representations of observations and instructions. The policy transformer keeps track of the full history of observations and actions, and predicts actions autoregressively. We show that this unified transformer model outperforms all state-of-the-art pre-trained or trained-from-scratch methods in both single-task and multi-task settings. Our model also shows better model scalability and generalization ability than prior work.
FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners
Oct 24, 2022



Large language models (LLM) trained using the next-token-prediction objective, such as GPT3 and PaLM, have revolutionized natural language processing in recent years by showing impressive zero-shot and few-shot capabilities across a wide range of tasks. In this work, we propose a simple technique that significantly boosts the performance of LLMs without adding computational cost. Our key observation is that, by performing the next token prediction task with randomly selected past tokens masked out, we can improve the quality of the learned representations for downstream language understanding tasks. We hypothesize that randomly masking past tokens prevents over-attending to recent tokens and encourages attention to tokens in the distant past. By randomly masking input tokens in the PaLM model, we show that we can significantly improve 1B and 8B PaLM's zero-shot performance on the SuperGLUE benchmark from 55.7 to 59.2 and from 61.6 to 64.0, respectively. Our largest 8B model matches the score of PaLM with an average score of 64, despite the fact that PaLM is trained on a much larger dataset (780B tokens) of high-quality conversation and webpage data, while ours is trained on the smaller C4 dataset (180B tokens). Experimental results show that our method also improves PaLM's zero and few-shot performance on a diverse suite of tasks, including commonsense reasoning, natural language inference and cloze completion. Moreover, we show that our technique also helps representation learning, significantly improving PaLM's finetuning results.
Dichotomy of Control: Separating What You Can Control from What You Cannot
Oct 24, 2022



Future- or return-conditioned supervised learning is an emerging paradigm for offline reinforcement learning (RL), where the future outcome (i.e., return) associated with an observed action sequence is used as input to a policy trained to imitate those same actions. While return-conditioning is at the heart of popular algorithms such as decision transformer (DT), these methods tend to perform poorly in highly stochastic environments, where an occasional high return can arise from randomness in the environment rather than the actions themselves. Such situations can lead to a learned policy that is inconsistent with its conditioning inputs; i.e., using the policy to act in the environment, when conditioning on a specific desired return, leads to a distribution of real returns that is wildly different than desired. In this work, we propose the dichotomy of control (DoC), a future-conditioned supervised learning framework that separates mechanisms within a policy's control (actions) from those beyond a policy's control (environment stochasticity). We achieve this separation by conditioning the policy on a latent variable representation of the future, and designing a mutual information constraint that removes any information from the latent variable associated with randomness in the environment. Theoretically, we show that DoC yields policies that are consistent with their conditioning inputs, ensuring that conditioning a learned policy on a desired high-return future outcome will correctly induce high-return behavior. Empirically, we show that DoC is able to achieve significantly better performance than DT on environments that have highly stochastic rewards and transition
Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions
Oct 23, 2022



One of the most important AI research questions is to trade off computation versus performance since ``perfect rationality" exists in theory but is impossible to achieve in practice. Recently, Monte-Carlo tree search (MCTS) has attracted considerable attention due to the significant performance improvement in various challenging domains. However, the expensive time cost during search severely restricts its scope for applications. This paper proposes the Virtual MCTS (V-MCTS), a variant of MCTS that spends more search time on harder states and less search time on simpler states adaptively. We give theoretical bounds of the proposed method and evaluate the performance and computations on $9 \times 9$ Go board games and Atari games. Experiments show that our method can achieve comparable performances to the original search algorithm while requiring less than $50\%$ search time on average. We believe that this approach is a viable alternative for tasks under limited time and resources. The code is available at \url{https://github.com/YeWR/V-MCTS.git}.
CLUTR: Curriculum Learning via Unsupervised Task Representation Learning
Oct 19, 2022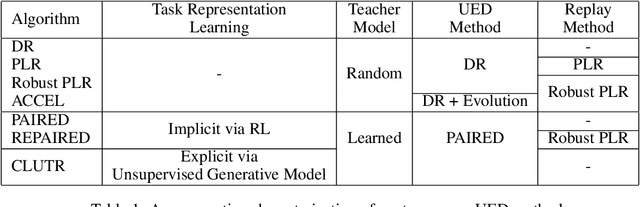
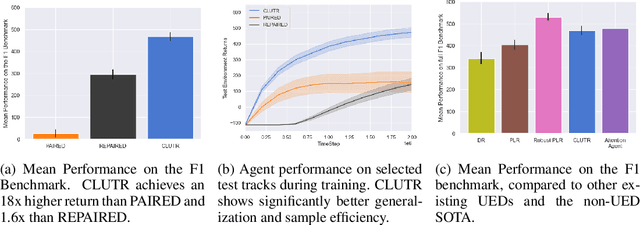
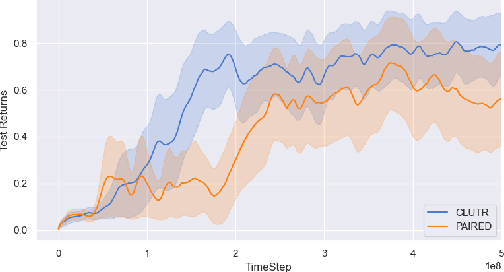
Reinforcement Learning (RL) algorithms are often known for sample inefficiency and difficult generalization. Recently, Unsupervised Environment Design (UED) emerged as a new paradigm for zero-shot generalization by simultaneously learning a task distribution and agent policies on the sampled tasks. This is a non-stationary process where the task distribution evolves along with agent policies, creating an instability over time. While past works demonstrated the potential of such approaches, sampling effectively from the task space remains an open challenge, bottlenecking these approaches. To this end, we introduce CLUTR: a novel curriculum learning algorithm that decouples task representation and curriculum learning into a two-stage optimization. It first trains a recurrent variational autoencoder on randomly generated tasks to learn a latent task manifold. Next, a teacher agent creates a curriculum by maximizing a minimax REGRET-based objective on a set of latent tasks sampled from this manifold. By keeping the task manifold fixed, we show that CLUTR successfully overcomes the non-stationarity problem and improves stability. Our experimental results show CLUTR outperforms PAIRED, a principled and popular UED method, in terms of generalization and sample efficiency in the challenging CarRacing and navigation environments: showing an 18x improvement on the F1 CarRacing benchmark. CLUTR also performs comparably to the non-UED state-of-the-art for CarRacing, outperforming it in nine of the 20 tracks. CLUTR also achieves a 33% higher solved rate than PAIRED on a set of 18 out-of-distribution navigation tasks.
Skill-Based Reinforcement Learning with Intrinsic Reward Matching
Oct 17, 2022
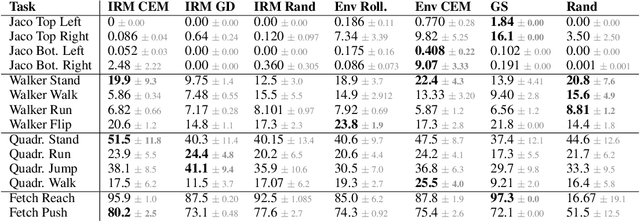
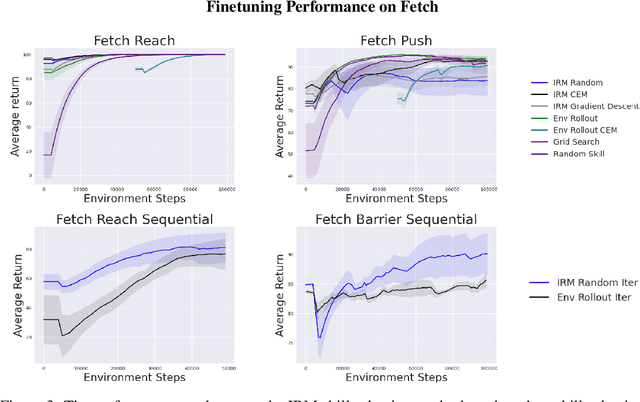
While unsupervised skill discovery has shown promise in autonomously acquiring behavioral primitives, there is still a large methodological disconnect between task-agnostic skill pretraining and downstream, task-aware finetuning. We present Intrinsic Reward Matching (IRM), which unifies these two phases of learning via the $\textit{skill discriminator}$, a pretraining model component often discarded during finetuning. Conventional approaches finetune pretrained agents directly at the policy level, often relying on expensive environment rollouts to empirically determine the optimal skill. However, often the most concise yet complete description of a task is the reward function itself, and skill learning methods learn an $\textit{intrinsic}$ reward function via the discriminator that corresponds to the skill policy. We propose to leverage the skill discriminator to $\textit{match}$ the intrinsic and downstream task rewards and determine the optimal skill for an unseen task without environment samples, consequently finetuning with greater sample-efficiency. Furthermore, we generalize IRM to sequence skills and solve more complex, long-horizon tasks. We demonstrate that IRM is competitive with previous skill selection methods on the Unsupervised Reinforcement Learning Benchmark and enables us to utilize pretrained skills far more effectively on challenging tabletop manipulation tasks.