 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited-Resource Adapters Are Regularizers, Not Linguists
May 30, 2025Cross-lingual transfer from related high-resource languages is a well-established strategy to enhance low-resource language technologies. Prior work has shown that adapters show promise for, e.g., improving low-resource machine translation (MT). In this work, we investigate an adapter souping method combined with cross-attention fine-tuning of a pre-trained MT model to leverage language transfer for three low-resource Creole languages, which exhibit relatedness to different language groups across distinct linguistic dimensions. Our approach improves performance substantially over baselines. However, we find that linguistic relatedness -- or even a lack thereof -- does not covary meaningfully with adapter performance. Surprisingly, our cross-attention fine-tuning approach appears equally effective with randomly initialized adapters, implying that the benefit of adapters in this setting lies in parameter regularization, and not in meaningful information transfer. We provide analysis supporting this regularization hypothesis. Our findings underscore the reality that neural language processing involves many success factors, and that not all neural methods leverage linguistic knowledge in intuitive ways.
DialUp! Modeling the Language Continuum by Adapting Models to Dialects and Dialects to Models
Jan 27, 2025



Most of the world's languages and dialects are low-resource, and lack support in mainstream machine translation (MT) models. However, many of them have a closely-related high-resource language (HRL) neighbor, and differ in linguistically regular ways from it. This underscores the importance of model robustness to dialectical variation and cross-lingual generalization to the HRL dialect continuum. We present DialUp, consisting of a training-time technique for adapting a pretrained model to dialectical data (M->D), and an inference-time intervention adapting dialectical data to the model expertise (D->M). M->D induces model robustness to potentially unseen and unknown dialects by exposure to synthetic data exemplifying linguistic mechanisms of dialectical variation, whereas D->M treats dialectical divergence for known target dialects. These methods show considerable performance gains for several dialects from four language families, and modest gains for two other language families. We also conduct feature and error analyses, which show that language varieties with low baseline MT performance are more likely to benefit from these approaches.
AL-QASIDA: Analyzing LLM Quality and Accuracy Systematically in Dialectal Arabic
Dec 05, 2024



Dialectal Arabic (DA) varieties are under-served by language technologies, particularly large language models (LLMs). This trend threatens to exacerbate existing social inequalities and limits language modeling applications, yet the research community lacks operationalized LLM performance measurements in DA. We present a method that comprehensively evaluates LLM fidelity, understanding, quality, and diglossia in modeling DA. We evaluate nine LLMs in eight DA varieties across these four dimensions and provide best practice recommendations. Our evaluation suggests that LLMs do not produce DA as well as they understand it, but does not suggest deterioration in quality when they do. Further analysis suggests that current post-training can degrade DA capabilities, that few-shot examples can overcome this and other LLM deficiencies, and that otherwise no measurable features of input text correlate well with LLM DA performance.
Kreyòl-MT: Building MT for Latin American, Caribbean and Colonial African Creole Languages
May 08, 2024



A majority of language technologies are tailored for a small number of high-resource languages, while relatively many low-resource languages are neglected. One such group, Creole languages, have long been marginalized in academic study, though their speakers could benefit from machine translation (MT). These languages are predominantly used in much of Latin America, Africa and the Caribbean. We present the largest cumulative dataset to date for Creole language MT, including 14.5M unique Creole sentences with parallel translations -- 11.6M of which we release publicly, and the largest bitexts gathered to date for 41 languages -- the first ever for 21. In addition, we provide MT models supporting all 41 Creole languages in 172 translation directions. Given our diverse dataset, we produce a model for Creole language MT exposed to more genre diversity than ever before, which outperforms a genre-specific Creole MT model on its own benchmark for 23 of 34 translation directions.
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024



Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
Automating Sound Change Prediction for Phylogenetic Inference: A Tukanoan Case Study
Feb 02, 2024



We describe a set of new methods to partially automate linguistic phylogenetic inference given (1) cognate sets with their respective protoforms and sound laws, (2) a mapping from phones to their articulatory features and (3) a typological database of sound changes. We train a neural network on these sound change data to weight articulatory distances between phones and predict intermediate sound change steps between historical protoforms and their modern descendants, replacing a linguistic expert in part of a parsimony-based phylogenetic inference algorithm. In our best experiments on Tukanoan languages, this method produces trees with a Generalized Quartet Distance of 0.12 from a tree that used expert annotations, a significant improvement over other semi-automated baselines. We discuss potential benefits and drawbacks to our neural approach and parsimony-based tree prediction. We also experiment with a minimal generalization learner for automatic sound law induction, finding it comparably effective to sound laws from expert annotation. Our code is publicly available at https://github.com/cmu-llab/aiscp.
ChatGPT MT: Competitive for High- (but not Low-) Resource Languages
Sep 14, 2023



Large language models (LLMs) implicitly learn to perform a range of language tasks, including machine translation (MT). Previous studies explore aspects of LLMs' MT capabilities. However, there exist a wide variety of languages for which recent LLM MT performance has never before been evaluated. Without published experimental evidence on the matter, it is difficult for speakers of the world's diverse languages to know how and whether they can use LLMs for their languages. We present the first experimental evidence for an expansive set of 204 languages, along with MT cost analysis, using the FLORES-200 benchmark. Trends reveal that GPT models approach or exceed traditional MT model performance for some high-resource languages (HRLs) but consistently lag for low-resource languages (LRLs), under-performing traditional MT for 84.1% of languages we covered. Our analysis reveals that a language's resource level is the most important feature in determining ChatGPT's relative ability to translate it, and suggests that ChatGPT is especially disadvantaged for LRLs and African languages.
Data-adaptive Transfer Learning for Translation: A Case Study in Haitian and Jamaican
Sep 13, 2022
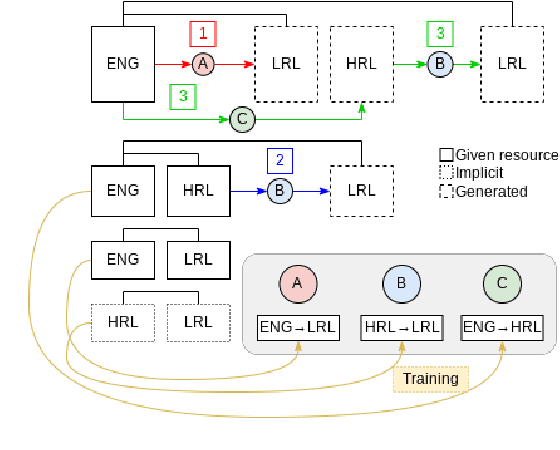
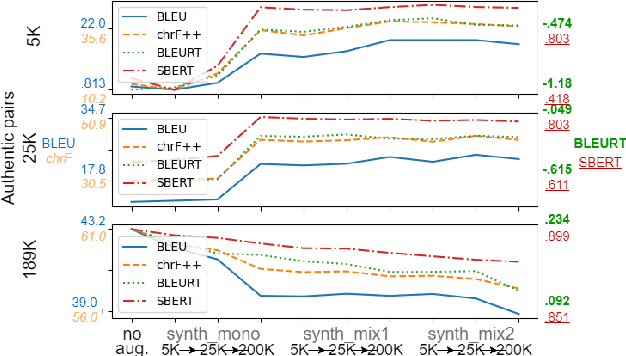
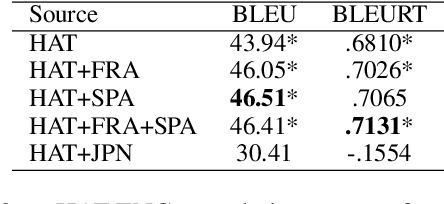
Multilingual transfer techniques often improve low-resource machine translation (MT). Many of these techniques are applied without considering data characteristics. We show in the context of Haitian-to-English translation that transfer effectiveness is correlated with amount of training data and relationships between knowledge-sharing languages. Our experiments suggest that for some languages beyond a threshold of authentic data, back-translation augmentation methods are counterproductive, while cross-lingual transfer from a sufficiently related language is preferred. We complement this finding by contributing a rule-based French-Haitian orthographic and syntactic engine and a novel method for phonological embedding. When used with multilingual techniques, orthographic transformation makes statistically significant improvements over conventional methods. And in very low-resource Jamaican MT, code-switching with a transfer language for orthographic resemblance yields a 6.63 BLEU point advantage.