 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Failure Analysis and Fault Injection in AI Systems
Jun 28, 2024



The rapid advancement of Artificial Intelligence (AI) has led to its integration into various areas, especially with Large Language Models (LLMs) significantly enhancing capabilities in Artificial Intelligence Generated Content (AIGC). However, the complexity of AI systems has also exposed their vulnerabilities, necessitating robust methods for failure analysis (FA) and fault injection (FI) to ensure resilience and reliability. Despite the importance of these techniques, there lacks a comprehensive review of FA and FI methodologies in AI systems. This study fills this gap by presenting a detailed survey of existing FA and FI approaches across six layers of AI systems. We systematically analyze 160 papers and repositories to answer three research questions including (1) what are the prevalent failures in AI systems, (2) what types of faults can current FI tools simulate, (3) what gaps exist between the simulated faults and real-world failures. Our findings reveal a taxonomy of AI system failures, assess the capabilities of existing FI tools, and highlight discrepancies between real-world and simulated failures. Moreover, this survey contributes to the field by providing a framework for fault diagnosis, evaluating the state-of-the-art in FI, and identifying areas for improvement in FI techniques to enhance the resilience of AI systems.
AesExpert: Towards Multi-modality Foundation Model for Image Aesthetics Perception
Apr 15, 2024



The highly abstract nature of image aesthetics perception (IAP) poses significant challenge for current multimodal large language models (MLLMs). The lack of human-annotated multi-modality aesthetic data further exacerbates this dilemma, resulting in MLLMs falling short of aesthetics perception capabilities. To address the above challenge, we first introduce a comprehensively annotated Aesthetic Multi-Modality Instruction Tuning (AesMMIT) dataset, which serves as the footstone for building multi-modality aesthetics foundation models. Specifically, to align MLLMs with human aesthetics perception, we construct a corpus-rich aesthetic critique database with 21,904 diverse-sourced images and 88K human natural language feedbacks, which are collected via progressive questions, ranging from coarse-grained aesthetic grades to fine-grained aesthetic descriptions. To ensure that MLLMs can handle diverse queries, we further prompt GPT to refine the aesthetic critiques and assemble the large-scale aesthetic instruction tuning dataset, i.e. AesMMIT, which consists of 409K multi-typed instructions to activate stronger aesthetic capabilities. Based on the AesMMIT database, we fine-tune the open-sourced general foundation models, achieving multi-modality Aesthetic Expert models, dubbed AesExpert. Extensive experiments demonstrate that the proposed AesExpert models deliver significantly better aesthetic perception performances than the state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision. Source data will be available at https://github.com/yipoh/AesExpert.
CPR++: Object Localization via Single Coarse Point Supervision
Jan 30, 2024



Point-based object localization (POL), which pursues high-performance object sensing under low-cost data annotation, has attracted increased attention. However, the point annotation mode inevitably introduces semantic variance due to the inconsistency of annotated points. Existing POL heavily rely on strict annotation rules, which are difficult to define and apply, to handle the problem. In this study, we propose coarse point refinement (CPR), which to our best knowledge is the first attempt to alleviate semantic variance from an algorithmic perspective. CPR reduces the semantic variance by selecting a semantic centre point in a neighbourhood region to replace the initial annotated point. Furthermore, We design a sampling region estimation module to dynamically compute a sampling region for each object and use a cascaded structure to achieve end-to-end optimization. We further integrate a variance regularization into the structure to concentrate the predicted scores, yielding CPR++. We observe that CPR++ can obtain scale information and further reduce the semantic variance in a global region, thus guaranteeing high-performance object localization. Extensive experiments on four challenging datasets validate the effectiveness of both CPR and CPR++. We hope our work can inspire more research on designing algorithms rather than annotation rules to address the semantic variance problem in POL. The dataset and code will be public at github.com/ucas-vg/PointTinyBenchmark.
AesBench: An Expert Benchmark for Multimodal Large Language Models on Image Aesthetics Perception
Jan 16, 2024With collective endeavors, multimodal large language models (MLLMs) are undergoing a flourishing development. However, their performances on image aesthetics perception remain indeterminate, which is highly desired in real-world applications. An obvious obstacle lies in the absence of a specific benchmark to evaluate the effectiveness of MLLMs on aesthetic perception. This blind groping may impede the further development of more advanced MLLMs with aesthetic perception capacity. To address this dilemma, we propose AesBench, an expert benchmark aiming to comprehensively evaluate the aesthetic perception capacities of MLLMs through elaborate design across dual facets. (1) We construct an Expert-labeled Aesthetics Perception Database (EAPD), which features diversified image contents and high-quality annotations provided by professional aesthetic experts. (2) We propose a set of integrative criteria to measure the aesthetic perception abilities of MLLMs from four perspectives, including Perception (AesP), Empathy (AesE), Assessment (AesA) and Interpretation (AesI). Extensive experimental results underscore that the current MLLMs only possess rudimentary aesthetic perception ability, and there is still a significant gap between MLLMs and humans. We hope this work can inspire the community to engage in deeper explorations on the aesthetic potentials of MLLMs. Source data will be available at https://github.com/yipoh/AesBench.
Semantic-aware SAM for Point-Prompted Instance Segmentation
Dec 26, 2023



Single-point annotation in visual tasks, with the goal of minimizing labelling costs, is becoming increasingly prominent in research. Recently, visual foundation models, such as Segment Anything (SAM), have gained widespread usage due to their robust zero-shot capabilities and exceptional annotation performance. However, SAM's class-agnostic output and high confidence in local segmentation introduce 'semantic ambiguity', posing a challenge for precise category-specific segmentation. In this paper, we introduce a cost-effective category-specific segmenter using SAM. To tackle this challenge, we have devised a Semantic-Aware Instance Segmentation Network (SAPNet) that integrates Multiple Instance Learning (MIL) with matching capability and SAM with point prompts. SAPNet strategically selects the most representative mask proposals generated by SAM to supervise segmentation, with a specific focus on object category information. Moreover, we introduce the Point Distance Guidance and Box Mining Strategy to mitigate inherent challenges: 'group' and 'local' issues in weakly supervised segmentation. These strategies serve to further enhance the overall segmentation performance. The experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed SAPNet, emphasizing its semantic matching capabilities and its potential to advance point-prompted instance segmentation. The code will be made publicly available.
Spatial Self-Distillation for Object Detection with Inaccurate Bounding Boxes
Aug 15, 2023



Object detection via inaccurate bounding boxes supervision has boosted a broad interest due to the expensive high-quality annotation data or the occasional inevitability of low annotation quality (\eg tiny objects). The previous works usually utilize multiple instance learning (MIL), which highly depends on category information, to select and refine a low-quality box. Those methods suffer from object drift, group prediction and part domination problems without exploring spatial information. In this paper, we heuristically propose a \textbf{Spatial Self-Distillation based Object Detector (SSD-Det)} to mine spatial information to refine the inaccurate box in a self-distillation fashion. SSD-Det utilizes a Spatial Position Self-Distillation \textbf{(SPSD)} module to exploit spatial information and an interactive structure to combine spatial information and category information, thus constructing a high-quality proposal bag. To further improve the selection procedure, a Spatial Identity Self-Distillation \textbf{(SISD)} module is introduced in SSD-Det to obtain spatial confidence to help select the best proposals. Experiments on MS-COCO and VOC datasets with noisy box annotation verify our method's effectiveness and achieve state-of-the-art performance. The code is available at https://github.com/ucas-vg/PointTinyBenchmark/tree/SSD-Det.
HyperTuner: A Cross-Layer Multi-Objective Hyperparameter Auto-Tuning Framework for Data Analytic Services
Apr 20, 2023



Hyper-parameters optimization (HPO) is vital for machine learning models. Besides model accuracy, other tuning intentions such as model training time and energy consumption are also worthy of attention from data analytic service providers. Hence, it is essential to take both model hyperparameters and system parameters into consideration to execute cross-layer multi-objective hyperparameter auto-tuning. Towards this challenging target, we propose HyperTuner in this paper. To address the formulated high-dimensional black-box multi-objective optimization problem, HyperTuner first conducts multi-objective parameter importance ranking with its MOPIR algorithm and then leverages the proposed ADUMBO algorithm to find the Pareto-optimal configuration set. During each iteration, ADUMBO selects the most promising configuration from the generated Pareto candidate set via maximizing a new well-designed metric, which can adaptively leverage the uncertainty as well as the predicted mean across all the surrogate models along with the iteration times. We evaluate HyperTuner on our local distributed TensorFlow cluster and experimental results show that it is always able to find a better Pareto configuration front superior in both convergence and diversity compared with the other four baseline algorithms. Besides, experiments with different training datasets, different optimization objectives and different machine learning platforms verify that HyperTuner can well adapt to various data analytic service scenarios.
Point-to-Box Network for Accurate Object Detection via Single Point Supervision
Jul 14, 2022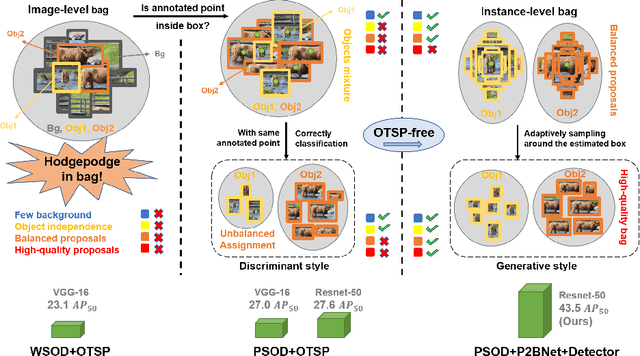
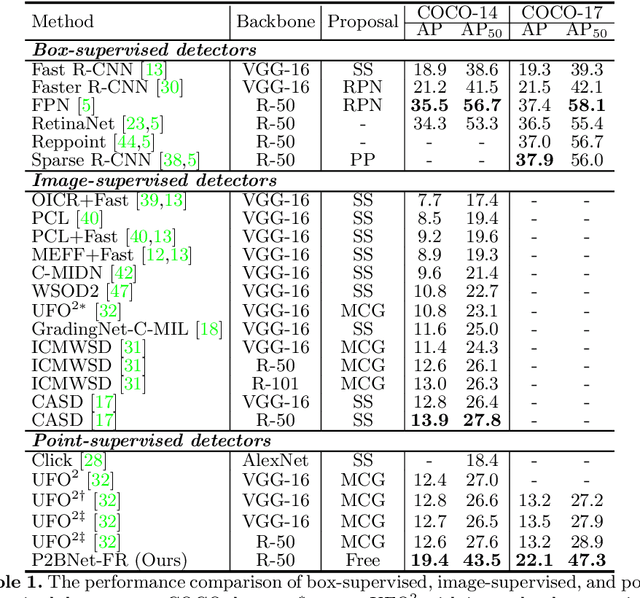
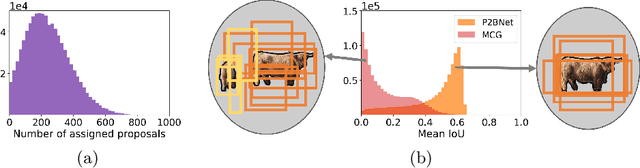
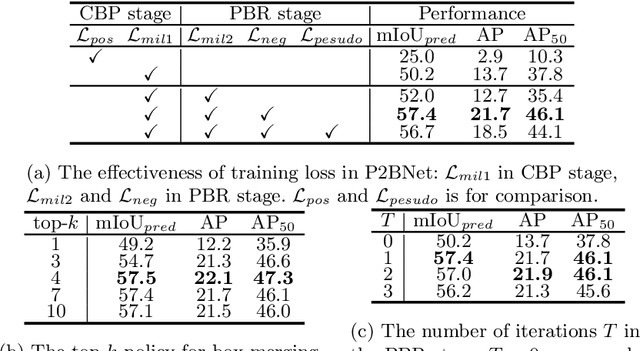
Object detection using single point supervision has received increasing attention over the years. In this paper, we attribute such a large performance gap to the failure of generating high-quality proposal bags which are crucial for multiple instance learning (MIL). To address this problem, we introduce a lightweight alternative to the off-the-shelf proposal (OTSP) method and thereby create the Point-to-Box Network (P2BNet), which can construct an inter-objects balanced proposal bag by generating proposals in an anchor-like way. By fully investigating the accurate position information, P2BNet further constructs an instance-level bag, avoiding the mixture of multiple objects. Finally, a coarse-to-fine policy in a cascade fashion is utilized to improve the IoU between proposals and ground-truth (GT). Benefiting from these strategies, P2BNet is able to produce high-quality instance-level bags for object detection. P2BNet improves the mean average precision (AP) by more than 50% relative to the previous best PSOD method on the MS COCO dataset. It also demonstrates the great potential to bridge the performance gap between point supervised and bounding-box supervised detectors. The code will be released at github.com/ucas-vg/P2BNet.
Robust Medical Image Classification from Noisy Labeled Data with Global and Local Representation Guided Co-training
May 10, 2022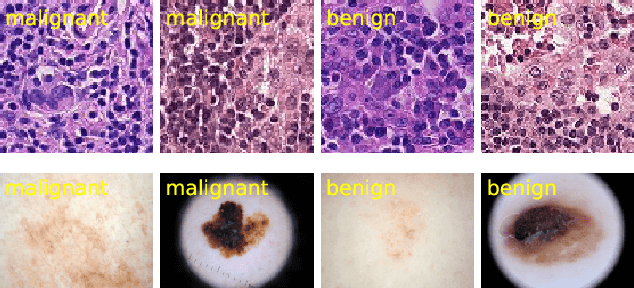
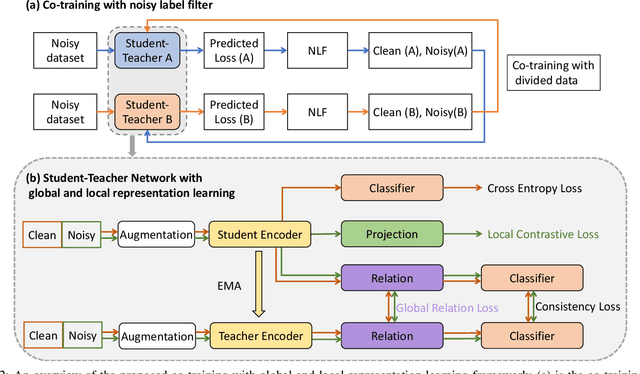
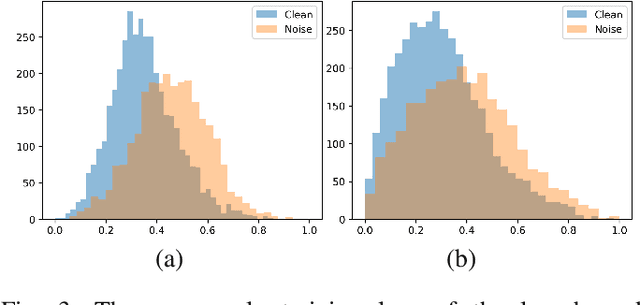
Deep neural networks have achieved remarkable success in a wide variety of natural image and medical image computing tasks. However, these achievements indispensably rely on accurately annotated training data. If encountering some noisy-labeled images, the network training procedure would suffer from difficulties, leading to a sub-optimal classifier. This problem is even more severe in the medical image analysis field, as the annotation quality of medical images heavily relies on the expertise and experience of annotators. In this paper, we propose a novel collaborative training paradigm with global and local representation learning for robust medical image classification from noisy-labeled data to combat the lack of high quality annotated medical data. Specifically, we employ the self-ensemble model with a noisy label filter to efficiently select the clean and noisy samples. Then, the clean samples are trained by a collaborative training strategy to eliminate the disturbance from imperfect labeled samples. Notably, we further design a novel global and local representation learning scheme to implicitly regularize the networks to utilize noisy samples in a self-supervised manner. We evaluated our proposed robust learning strategy on four public medical image classification datasets with three types of label noise,ie,random noise, computer-generated label noise, and inter-observer variability noise. Our method outperforms other learning from noisy label methods and we also conducted extensive experiments to analyze each component of our method.
Acknowledging the Unknown for Multi-label Learning with Single Positive Labels
Mar 30, 2022
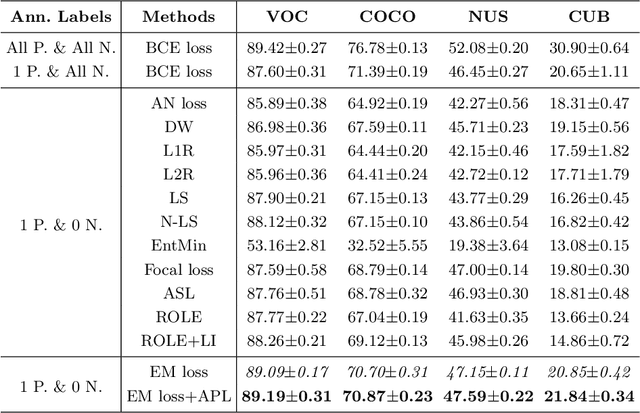
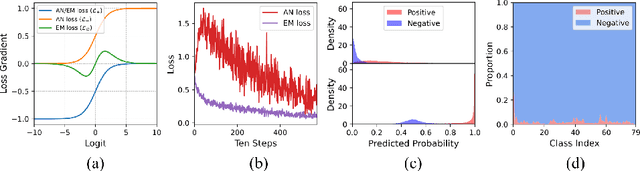

Due to the difficulty of collecting exhaustive multi-label annotations, multi-label training data often contains partial labels. We consider an extreme of this problem, called single positive multi-label learning (SPML), where each multi-label training image has only one positive label. Traditionally, all unannotated labels are assumed as negative labels in SPML, which would introduce false negative labels and make model training be dominated by assumed negative labels. In this work, we choose to treat all unannotated labels from a different perspective, \textit{i.e.} acknowledging they are unknown. Hence, we propose entropy-maximization (EM) loss to maximize the entropy of predicted probabilities for all unannotated labels. Considering the positive-negative label imbalance of unannotated labels, we propose asymmetric pseudo-labeling (APL) with asymmetric-tolerance strategies and a self-paced procedure to provide more precise supervision. Experiments show that our method significantly improves performance and achieves state-of-the-art results on all four benchmarks.