 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing AI-based Generation of Software Exploits with Contextual Information
Aug 06, 2024



This practical experience report explores Neural Machine Translation (NMT) models' capability to generate offensive security code from natural language (NL) descriptions, highlighting the significance of contextual understanding and its impact on model performance. Our study employs a dataset comprising real shellcodes to evaluate the models across various scenarios, including missing information, necessary context, and unnecessary context. The experiments are designed to assess the models' resilience against incomplete descriptions, their proficiency in leveraging context for enhanced accuracy, and their ability to discern irrelevant information. The findings reveal that the introduction of contextual data significantly improves performance. However, the benefits of additional context diminish beyond a certain point, indicating an optimal level of contextual information for model training. Moreover, the models demonstrate an ability to filter out unnecessary context, maintaining high levels of accuracy in the generation of offensive security code. This study paves the way for future research on optimizing context use in AI-driven code generation, particularly for applications requiring a high degree of technical precision such as the generation of offensive code.
A Survey on Failure Analysis and Fault Injection in AI Systems
Jun 28, 2024



The rapid advancement of Artificial Intelligence (AI) has led to its integration into various areas, especially with Large Language Models (LLMs) significantly enhancing capabilities in Artificial Intelligence Generated Content (AIGC). However, the complexity of AI systems has also exposed their vulnerabilities, necessitating robust methods for failure analysis (FA) and fault injection (FI) to ensure resilience and reliability. Despite the importance of these techniques, there lacks a comprehensive review of FA and FI methodologies in AI systems. This study fills this gap by presenting a detailed survey of existing FA and FI approaches across six layers of AI systems. We systematically analyze 160 papers and repositories to answer three research questions including (1) what are the prevalent failures in AI systems, (2) what types of faults can current FI tools simulate, (3) what gaps exist between the simulated faults and real-world failures. Our findings reveal a taxonomy of AI system failures, assess the capabilities of existing FI tools, and highlight discrepancies between real-world and simulated failures. Moreover, this survey contributes to the field by providing a framework for fault diagnosis, evaluating the state-of-the-art in FI, and identifying areas for improvement in FI techniques to enhance the resilience of AI systems.
AI Code Generators for Security: Friend or Foe?
Feb 02, 2024



Recent advances of artificial intelligence (AI) code generators are opening new opportunities in software security research, including misuse by malicious actors. We review use cases for AI code generators for security and introduce an evaluation benchmark.
* Dataset available at: https://github.com/dessertlab/violent-python
Automating the Correctness Assessment of AI-generated Code for Security Contexts
Oct 28, 2023



In this paper, we propose a fully automated method, named ACCA, to evaluate the correctness of AI-generated code for security purposes. The method uses symbolic execution to assess whether the AI-generated code behaves as a reference implementation. We use ACCA to assess four state-of-the-art models trained to generate security-oriented assembly code and compare the results of the evaluation with different baseline solutions, including output similarity metrics, widely used in the field, and the well-known ChatGPT, the AI-powered language model developed by OpenAI. Our experiments show that our method outperforms the baseline solutions and assesses the correctness of the AI-generated code similar to the human-based evaluation, which is considered the ground truth for the assessment in the field. Moreover, ACCA has a very strong correlation with human evaluation (Pearson's correlation coefficient r=0.84 on average). Finally, since it is a fully automated solution that does not require any human intervention, the proposed method performs the assessment of every code snippet in ~0.17s on average, which is definitely lower than the average time required by human analysts to manually inspect the code, based on our experience.
Vulnerabilities in AI Code Generators: Exploring Targeted Data Poisoning Attacks
Aug 04, 2023



In this work, we assess the security of AI code generators via data poisoning, i.e., an attack that injects malicious samples into the training data to generate vulnerable code. We poison the training data by injecting increasing amounts of code containing security vulnerabilities and assess the attack's success on different state-of-the-art models for code generation. Our analysis shows that AI code generators are vulnerable to even a small amount of data poisoning. Moreover, the attack does not impact the correctness of code generated by pre-trained models, making it hard to detect.
Enhancing Robustness of AI Offensive Code Generators via Data Augmentation
Jun 08, 2023In this work, we present a method to add perturbations to the code descriptions, i.e., new inputs in natural language (NL) from well-intentioned developers, in the context of security-oriented code, and analyze how and to what extent perturbations affect the performance of AI offensive code generators. Our experiments show that the performance of the code generators is highly affected by perturbations in the NL descriptions. To enhance the robustness of the code generators, we use the method to perform data augmentation, i.e., to increase the variability and diversity of the training data, proving its effectiveness against both perturbed and non-perturbed code descriptions.
Who Evaluates the Evaluators? On Automatic Metrics for Assessing AI-based Offensive Code Generators
Dec 12, 2022



AI-based code generators are an emerging solution for automatically writing programs starting from descriptions in natural language, by using deep neural networks (Neural Machine Translation, NMT). In particular, code generators have been used for ethical hacking and offensive security testing by generating proof-of-concept attacks. Unfortunately, the evaluation of code generators still faces several issues. The current practice uses automatic metrics, which compute the textual similarity of generated code with ground-truth references. However, it is not clear what metric to use, and which metric is most suitable for specific contexts. This practical experience report analyzes a large set of output similarity metrics on offensive code generators. We apply the metrics on two state-of-the-art NMT models using two datasets containing offensive assembly and Python code with their descriptions in the English language. We compare the estimates from the automatic metrics with human evaluation and provide practical insights into their strengths and limitations.
Automatic Mapping of Unstructured Cyber Threat Intelligence: An Experimental Study
Aug 25, 2022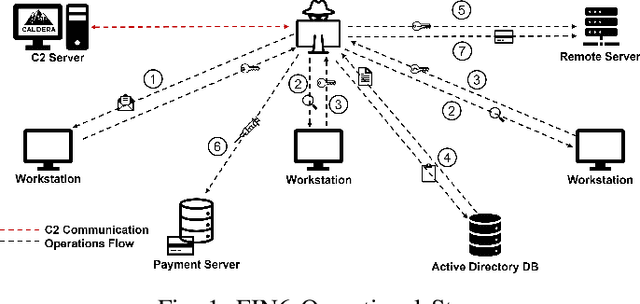
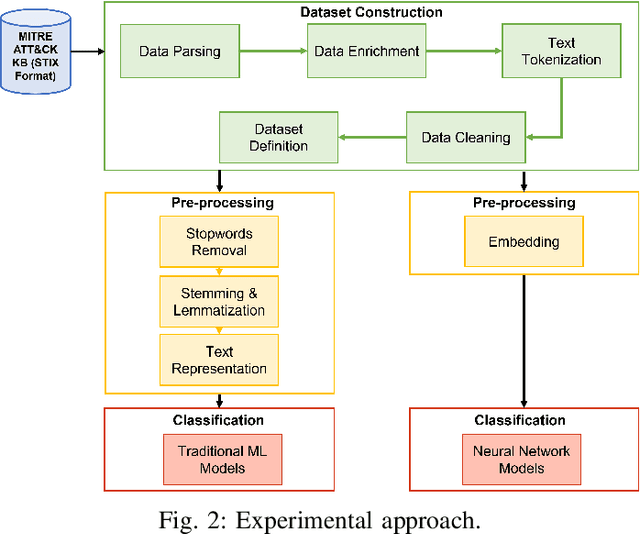
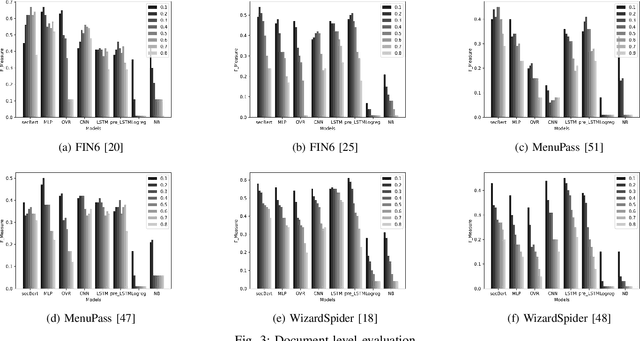

Proactive approaches to security, such as adversary emulation, leverage information about threat actors and their techniques (Cyber Threat Intelligence, CTI). However, most CTI still comes in unstructured forms (i.e., natural language), such as incident reports and leaked documents. To support proactive security efforts, we present an experimental study on the automatic classification of unstructured CTI into attack techniques using machine learning (ML). We contribute with two new datasets for CTI analysis, and we evaluate several ML models, including both traditional and deep learning-based ones. We present several lessons learned about how ML can perform at this task, which classifiers perform best and under which conditions, which are the main causes of classification errors, and the challenges ahead for CTI analysis.
Can NMT Understand Me? Towards Perturbation-based Evaluation of NMT Models for Code Generation
Mar 30, 2022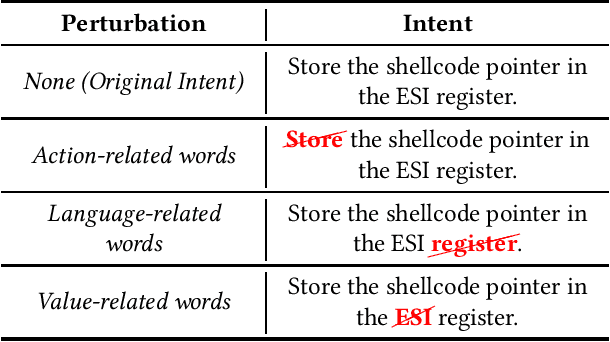

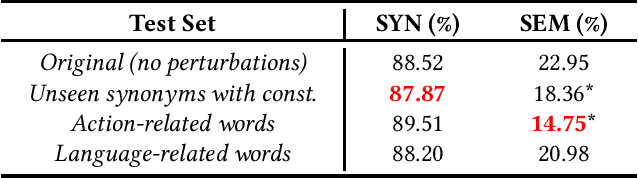
Neural Machine Translation (NMT) has reached a level of maturity to be recognized as the premier method for the translation between different languages and aroused interest in different research areas, including software engineering. A key step to validate the robustness of the NMT models consists in evaluating the performance of the models on adversarial inputs, i.e., inputs obtained from the original ones by adding small amounts of perturbation. However, when dealing with the specific task of the code generation (i.e., the generation of code starting from a description in natural language), it has not yet been defined an approach to validate the robustness of the NMT models. In this work, we address the problem by identifying a set of perturbations and metrics tailored for the robustness assessment of such models. We present a preliminary experimental evaluation, showing what type of perturbations affect the model the most and deriving useful insights for future directions.
Can We Generate Shellcodes via Natural Language? An Empirical Study
Feb 08, 2022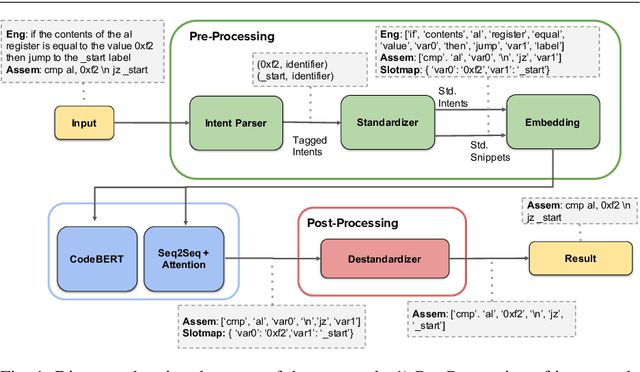


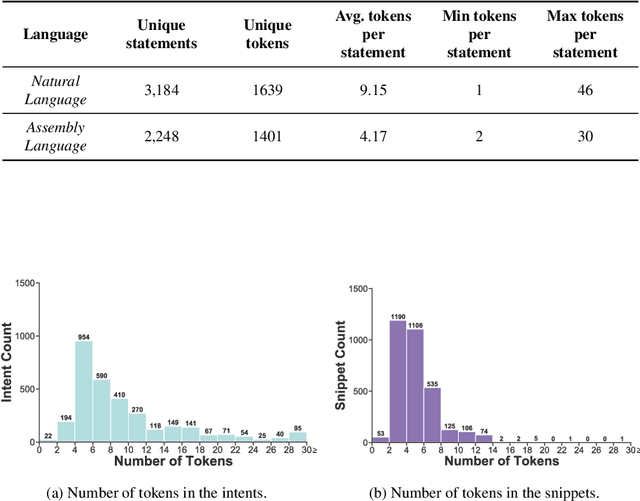
Writing software exploits is an important practice for offensive security analysts to investigate and prevent attacks. In particular, shellcodes are especially time-consuming and a technical challenge, as they are written in assembly language. In this work, we address the task of automatically generating shellcodes, starting purely from descriptions in natural language, by proposing an approach based on Neural Machine Translation (NMT). We then present an empirical study using a novel dataset (Shellcode_IA32), which consists of 3,200 assembly code snippets of real Linux/x86 shellcodes from public databases, annotated using natural language. Moreover, we propose novel metrics to evaluate the accuracy of NMT at generating shellcodes. The empirical analysis shows that NMT can generate assembly code snippets from the natural language with high accuracy and that in many cases can generate entire shellcodes with no errors.