 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022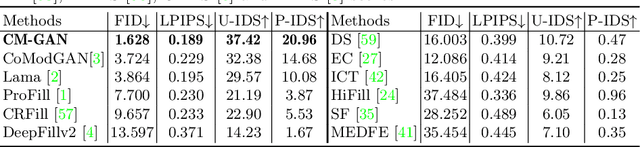
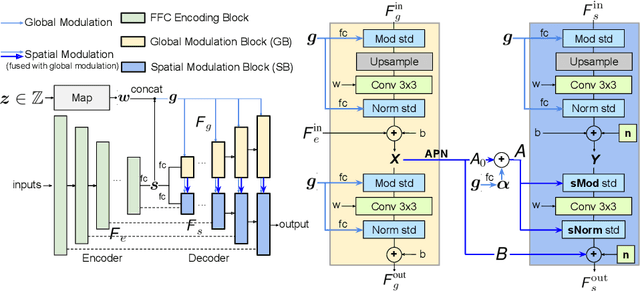
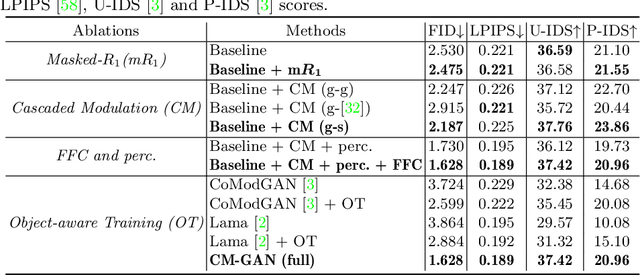

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
Wavelet Knowledge Distillation: Towards Efficient Image-to-Image Translation
Mar 12, 2022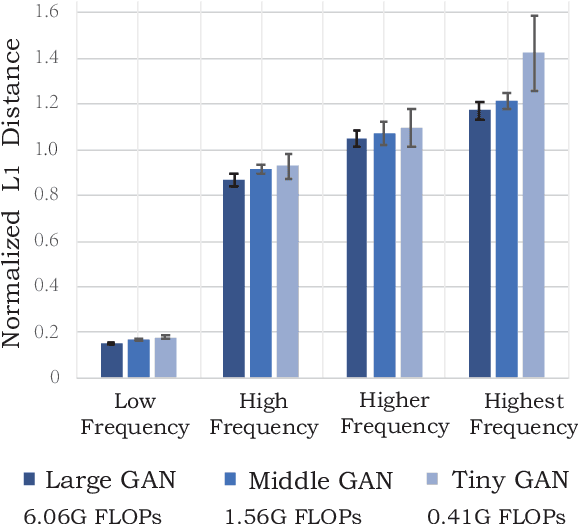
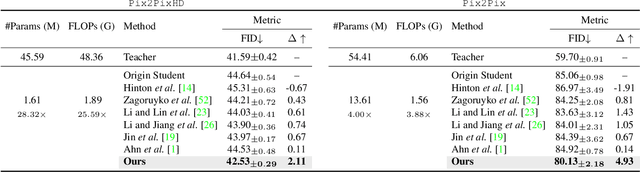
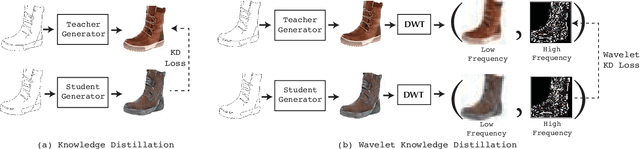
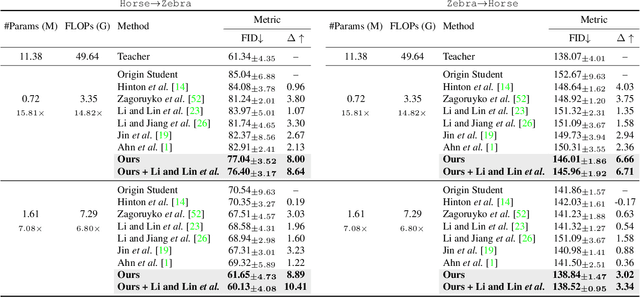
Remarkable achievements have been attained with Generative Adversarial Networks (GANs) in image-to-image translation. However, due to a tremendous amount of parameters, state-of-the-art GANs usually suffer from low efficiency and bulky memory usage. To tackle this challenge, firstly, this paper investigates GANs performance from a frequency perspective. The results show that GANs, especially small GANs lack the ability to generate high-quality high frequency information. To address this problem, we propose a novel knowledge distillation method referred to as wavelet knowledge distillation. Instead of directly distilling the generated images of teachers, wavelet knowledge distillation first decomposes the images into different frequency bands with discrete wavelet transformation and then only distills the high frequency bands. As a result, the student GAN can pay more attention to its learning on high frequency bands. Experiments demonstrate that our method leads to 7.08 times compression and 6.80 times acceleration on CycleGAN with almost no performance drop. Additionally, we have studied the relation between discriminators and generators which shows that the compression of discriminators can promote the performance of compressed generators.
End-to-end video instance segmentation via spatial-temporal graph neural networks
Mar 07, 2022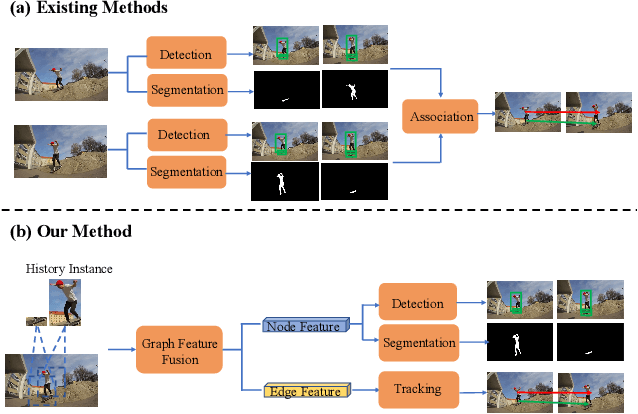
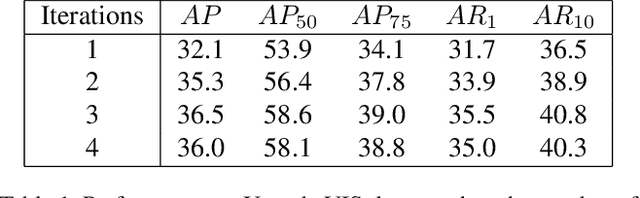
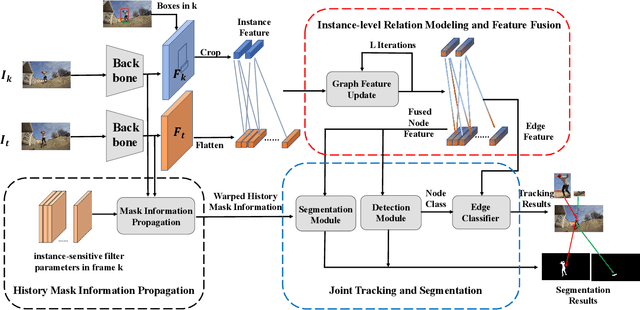
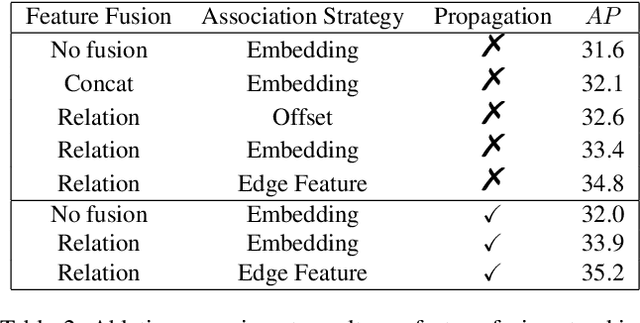
Video instance segmentation is a challenging task that extends image instance segmentation to the video domain. Existing methods either rely only on single-frame information for the detection and segmentation subproblems or handle tracking as a separate post-processing step, which limit their capability to fully leverage and share useful spatial-temporal information for all the subproblems. In this paper, we propose a novel graph-neural-network (GNN) based method to handle the aforementioned limitation. Specifically, graph nodes representing instance features are used for detection and segmentation while graph edges representing instance relations are used for tracking. Both inter and intra-frame information is effectively propagated and shared via graph updates and all the subproblems (i.e. detection, segmentation and tracking) are jointly optimized in an unified framework. The performance of our method shows great improvement on the YoutubeVIS validation dataset compared to existing methods and achieves 35.2% AP with a ResNet-50 backbone, operating at 22 FPS. Code is available at http://github.com/lucaswithai/visgraph.git .
Adaptive Cross-Layer Attention for Image Restoration
Mar 04, 2022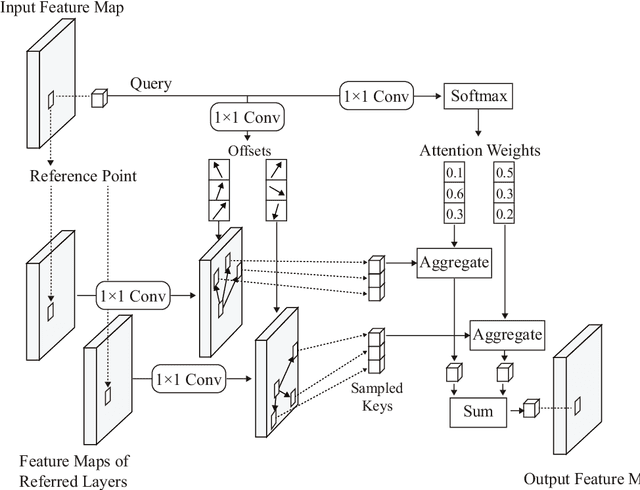
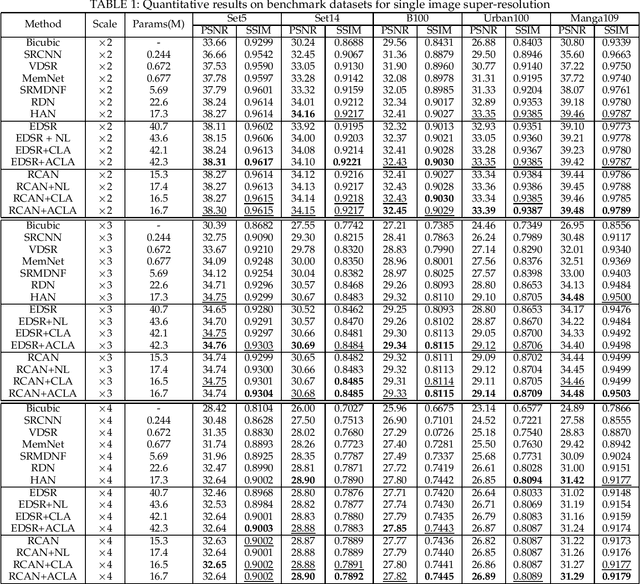
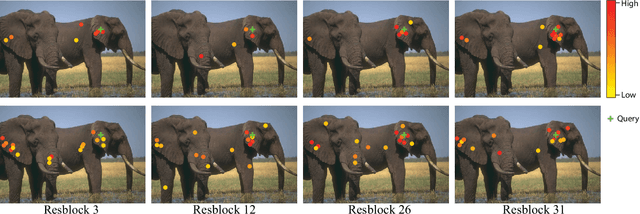
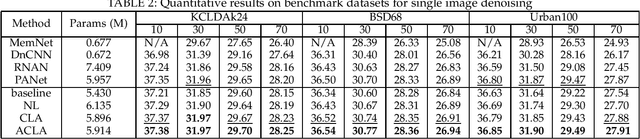
Non-local attention module has been proven to be crucial for image restoration. Conventional non-local attention processes features of each layer separately, so it risks missing correlation between features among different layers. To address this problem, we propose Cross-Layer Attention (CLA) module in this paper. Instead of finding correlated key pixels within the same layer, each query pixel can attend to key pixels at previous layers of the network. In order to further enhance the learning capability and reduce the inference cost of CLA, we further propose Adaptive CLA, or ACLA, as an improved CLA. Two adaptive designs are proposed for ACLA: 1) adaptively selecting the keys for non-local attention at each layer; 2) automatically searching for the insertion locations for ACLA modules. By these two adaptive designs, ACLA dynamically selects the number of keys to be aggregated for non-local attention at layer. In addition, ACLA searches for the optimal insert positions of ACLA modules by a neural architecture search method to render a compact neural network with compelling performance. Extensive experiments on image restoration tasks, including single image super-resolution, image denoising, image demosaicing, and image compression artifacts reduction, validate the effectiveness and efficiency of ACLA.
EBHI:A New Enteroscope Biopsy Histopathological H&E Image Dataset for Image Classification Evaluation
Feb 17, 2022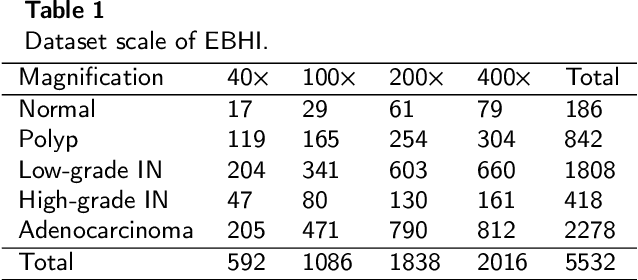
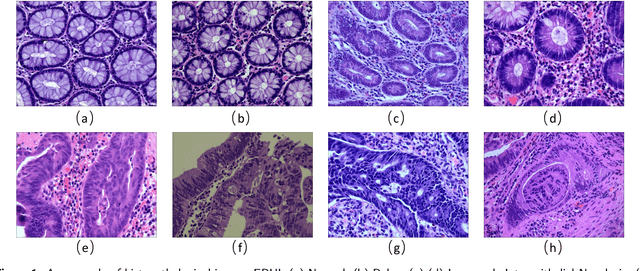
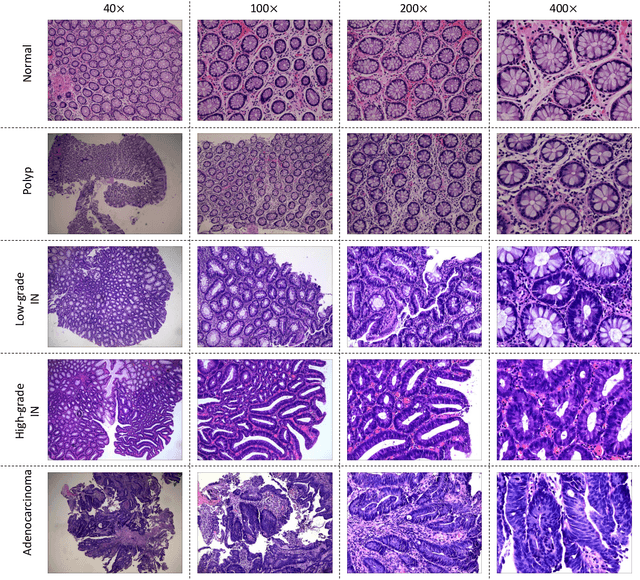
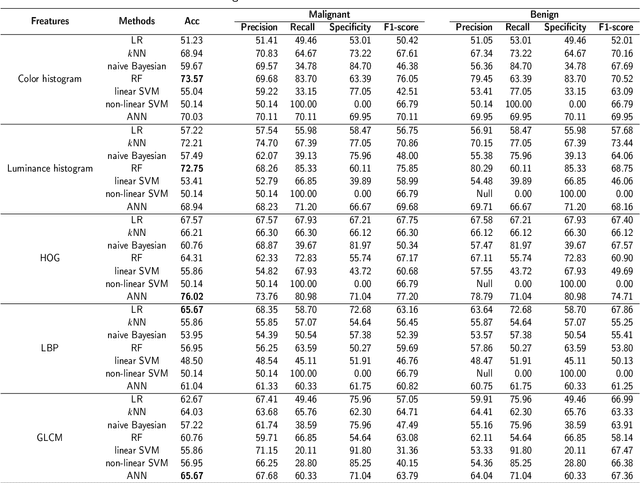
Background and purpose: Colorectal cancer has become the third most common cancer worldwide, accounting for approximately 10% of cancer patients. Early detection of the disease is important for the treatment of colorectal cancer patients. Histopathological examination is the gold standard for screening colorectal cancer. However, the current lack of histopathological image datasets of colorectal cancer, especially enteroscope biopsies, hinders the accurate evaluation of computer-aided diagnosis techniques. Methods: A new publicly available Enteroscope Biopsy Histopathological H&E Image Dataset (EBHI) is published in this paper. To demonstrate the effectiveness of the EBHI dataset, we have utilized several machine learning, convolutional neural networks and novel transformer-based classifiers for experimentation and evaluation, using an image with a magnification of 200x. Results: Experimental results show that the deep learning method performs well on the EBHI dataset. Traditional machine learning methods achieve maximum accuracy of 76.02% and deep learning method achieves a maximum accuracy of 95.37%. Conclusion: To the best of our knowledge, EBHI is the first publicly available colorectal histopathology enteroscope biopsy dataset with four magnifications and five types of images of tumor differentiation stages, totaling 5532 images. We believe that EBHI could attract researchers to explore new classification algorithms for the automated diagnosis of colorectal cancer, which could help physicians and patients in clinical settings.
EMDS-6: Environmental Microorganism Image Dataset Sixth Version for Image Denoising, Segmentation, Feature Extraction, Classification and Detection Methods Evaluation
Dec 14, 2021
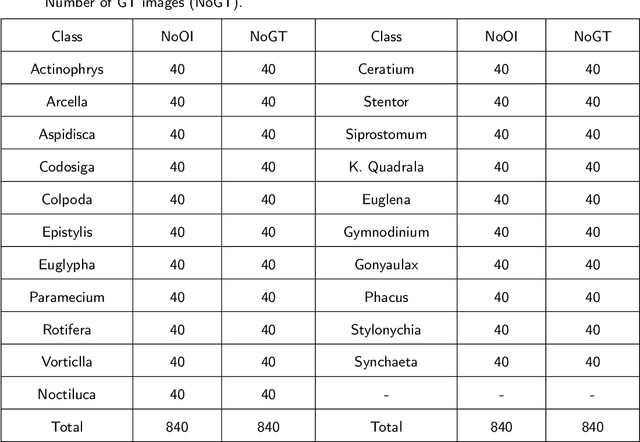
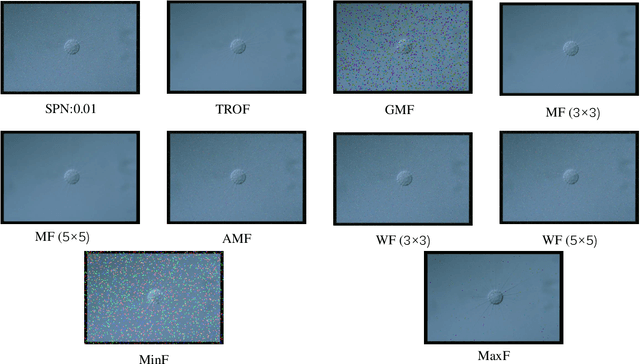
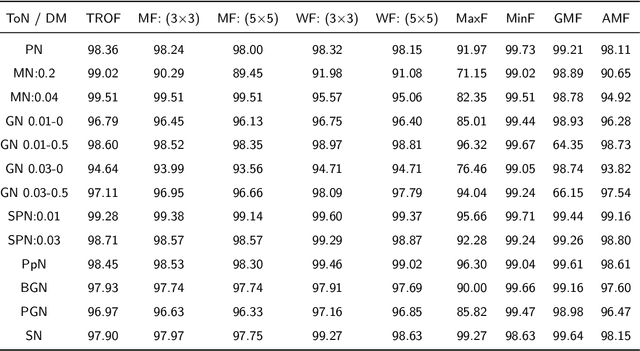
Environmental microorganisms (EMs) are ubiquitous around us and have an important impact on the survival and development of human society. However, the high standards and strict requirements for the preparation of environmental microorganism (EM) data have led to the insufficient of existing related databases, not to mention the databases with GT images. This problem seriously affects the progress of related experiments. Therefore, This study develops the Environmental Microorganism Dataset Sixth Version (EMDS-6), which contains 21 types of EMs. Each type of EM contains 40 original and 40 GT images, in total 1680 EM images. In this study, in order to test the effectiveness of EMDS-6. We choose the classic algorithms of image processing methods such as image denoising, image segmentation and target detection. The experimental result shows that EMDS-6 can be used to evaluate the performance of image denoising, image segmentation, image feature extraction, image classification, and object detection methods.
SpaceEdit: Learning a Unified Editing Space for Open-Domain Image Editing
Nov 30, 2021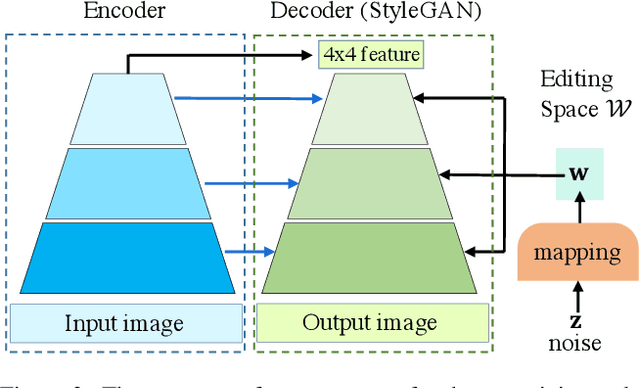
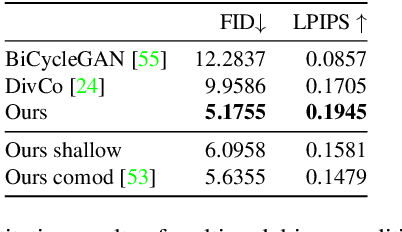


Recently, large pretrained models (e.g., BERT, StyleGAN, CLIP) have shown great knowledge transfer and generalization capability on various downstream tasks within their domains. Inspired by these efforts, in this paper we propose a unified model for open-domain image editing focusing on color and tone adjustment of open-domain images while keeping their original content and structure. Our model learns a unified editing space that is more semantic, intuitive, and easy to manipulate than the operation space (e.g., contrast, brightness, color curve) used in many existing photo editing softwares. Our model belongs to the image-to-image translation framework which consists of an image encoder and decoder, and is trained on pairs of before- and after-images to produce multimodal outputs. We show that by inverting image pairs into latent codes of the learned editing space, our model can be leveraged for various downstream editing tasks such as language-guided image editing, personalized editing, editing-style clustering, retrieval, etc. We extensively study the unique properties of the editing space in experiments and demonstrate superior performance on the aforementioned tasks.
Exploring the Semi-supervised Video Object Segmentation Problem from a Cyclic Perspective
Nov 02, 2021
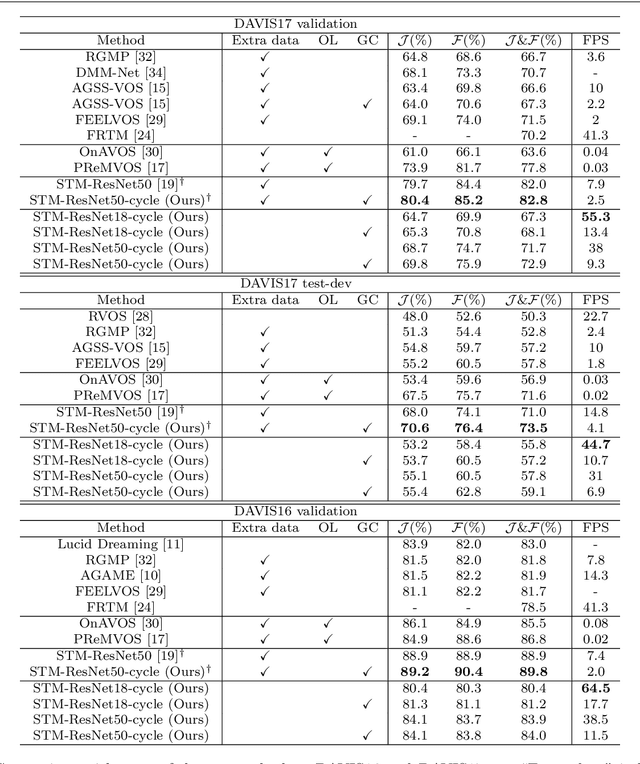
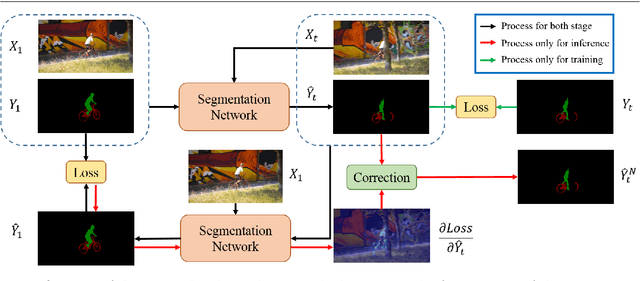
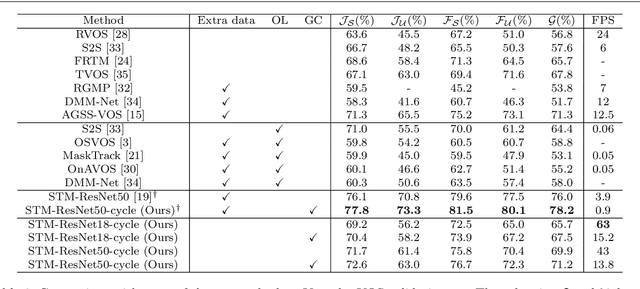
Modern video object segmentation (VOS) algorithms have achieved remarkably high performance in a sequential processing order, while most of currently prevailing pipelines still show some obvious inadequacy like accumulative error, unknown robustness or lack of proper interpretation tools. In this paper, we place the semi-supervised video object segmentation problem into a cyclic workflow and find the defects above can be collectively addressed via the inherent cyclic property of semi-supervised VOS systems. Firstly, a cyclic mechanism incorporated to the standard sequential flow can produce more consistent representations for pixel-wise correspondance. Relying on the accurate reference mask in the starting frame, we show that the error propagation problem can be mitigated. Next, a simple gradient correction module, which naturally extends the offline cyclic pipeline to an online manner, can highlight the high-frequent and detailed part of results to further improve the segmentation quality while keeping feasible computation cost. Meanwhile such correction can protect the network from severe performance degration resulted from interference signals. Finally we develop cycle effective receptive field (cycle-ERF) based on gradient correction process to provide a new perspective into analyzing object-specific regions of interests. We conduct comprehensive comparison and detailed analysis on challenging benchmarks of DAVIS16, DAVIS17 and Youtube-VOS, demonstrating that the cyclic mechanism is helpful to enhance segmentation quality, improve the robustness of VOS systems, and further provide qualitative comparison and interpretation on how different VOS algorithms work. The code of this project can be found at https://github.com/lyxok1/STM-Training
Instance-Dependent Partial Label Learning
Oct 26, 2021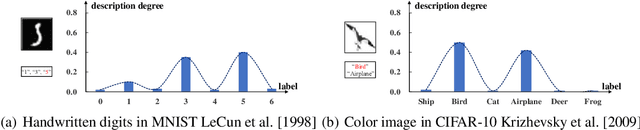
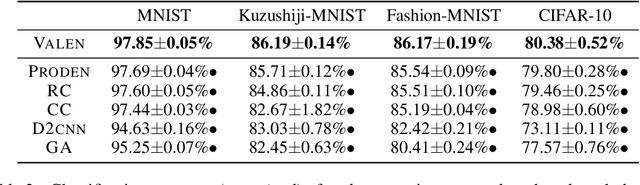
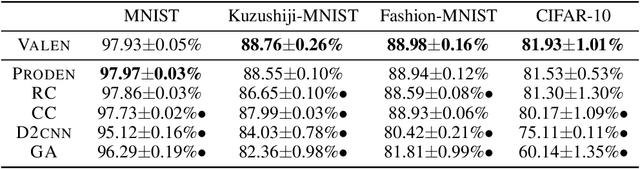
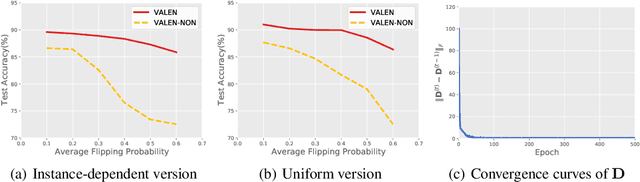
Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels. However, this assumption is not realistic since the candidate labels are always instance-dependent. In this paper, we consider instance-dependent PLL and assume that each example is associated with a latent label distribution constituted by the real number of each label, representing the degree to each label describing the feature. The incorrect label with a high degree is more likely to be annotated as the candidate label. Therefore, the latent label distribution is the essential labeling information in partially labeled examples and worth being leveraged for predictive model training. Motivated by this consideration, we propose a novel PLL method that recovers the label distribution as a label enhancement (LE) process and trains the predictive model iteratively in every epoch. Specifically, we assume the true posterior density of the latent label distribution takes on the variational approximate Dirichlet density parameterized by an inference model. Then the evidence lower bound is deduced for optimizing the inference model and the label distributions generated from the variational posterior are utilized for training the predictive model. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method. Source code is available at https://github.com/palm-ml/valen.
Learning Models for Query by Vocal Percussion: A Comparative Study
Oct 18, 2021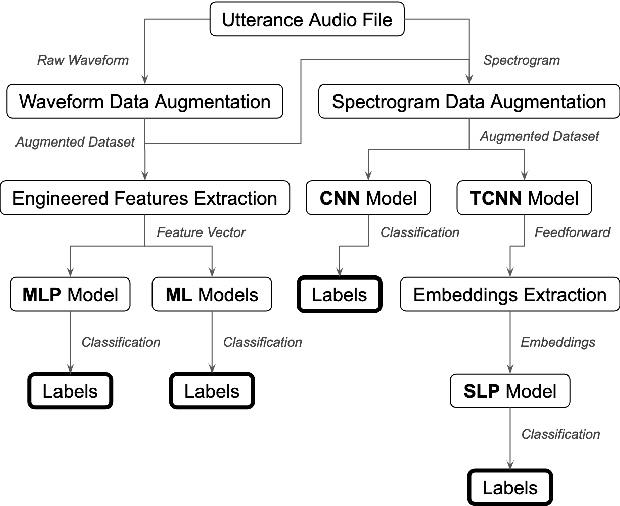
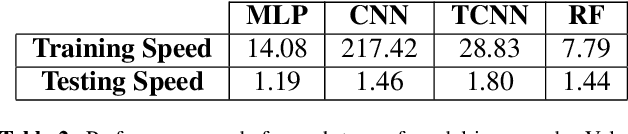
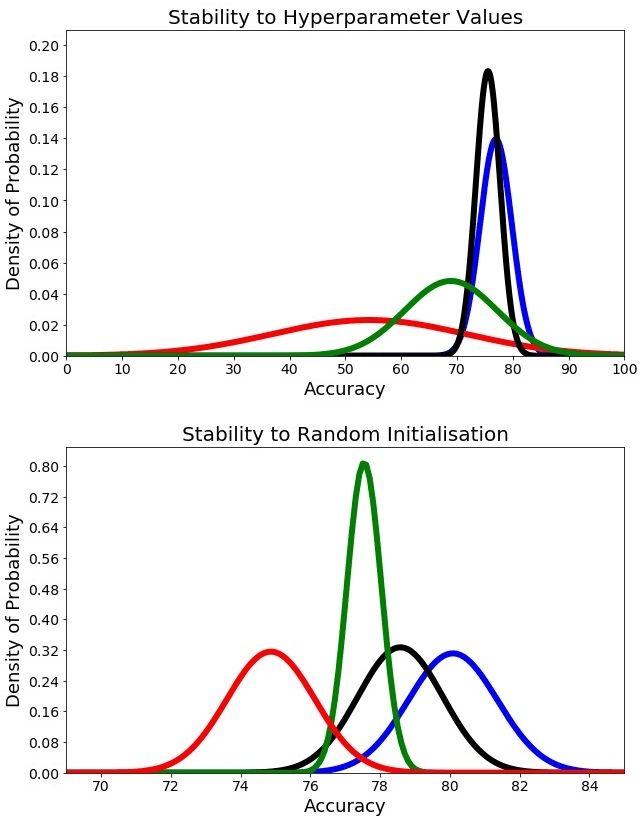
The imitation of percussive sounds via the human voice is a natural and effective tool for communicating rhythmic ideas on the fly. Thus, the automatic retrieval of drum sounds using vocal percussion can help artists prototype drum patterns in a comfortable and quick way, smoothing the creative workflow as a result. Here we explore different strategies to perform this type of query, making use of both traditional machine learning algorithms and recent deep learning techniques. The main hyperparameters from the models involved are carefully selected by feeding performance metrics to a grid search algorithm. We also look into several audio data augmentation techniques, which can potentially regularise deep learning models and improve generalisation. We compare the final performances in terms of effectiveness (classification accuracy), efficiency (computational speed), stability (performance consistency), and interpretability (decision patterns), and discuss the relevance of these results when it comes to the design of successful query-by-vocal-percussion systems.