 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Assignment Techniques in Stochastic Computation Graphs
Jan 07, 2019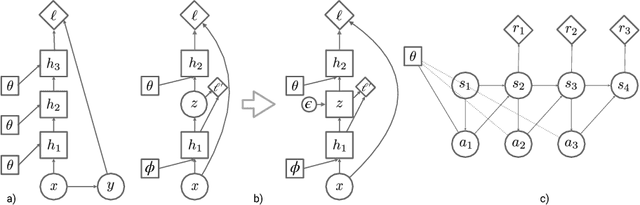
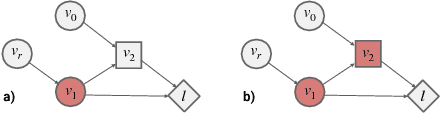

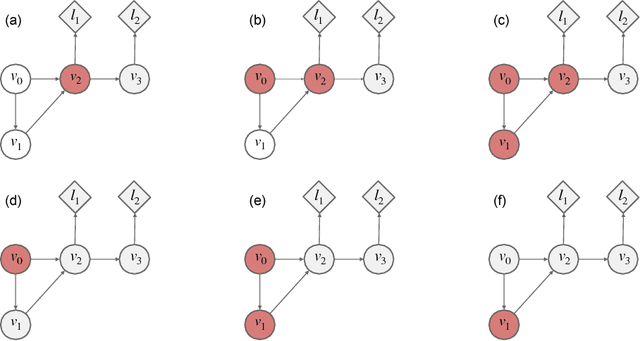
Stochastic computation graphs (SCGs) provide a formalism to represent structured optimization problems arising in artificial intelligence, including supervised, unsupervised, and reinforcement learning. Previous work has shown that an unbiased estimator of the gradient of the expected loss of SCGs can be derived from a single principle. However, this estimator often has high variance and requires a full model evaluation per data point, making this algorithm costly in large graphs. In this work, we address these problems by generalizing concepts from the reinforcement learning literature. We introduce the concepts of value functions, baselines and critics for arbitrary SCGs, and show how to use them to derive lower-variance gradient estimates from partial model evaluations, paving the way towards general and efficient credit assignment for gradient-based optimization. In doing so, we demonstrate how our results unify recent advances in the probabilistic inference and reinforcement learning literature.
Self-supervised Learning of Image Embedding for Continuous Control
Jan 03, 2019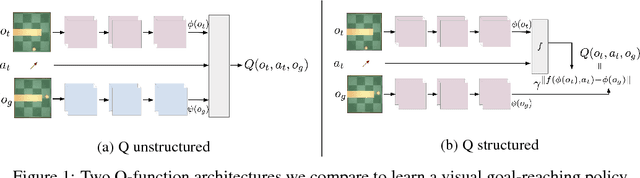
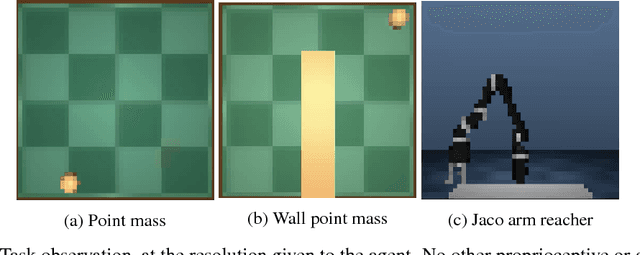
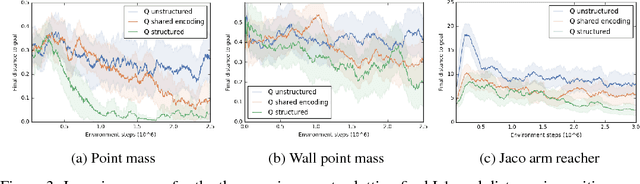
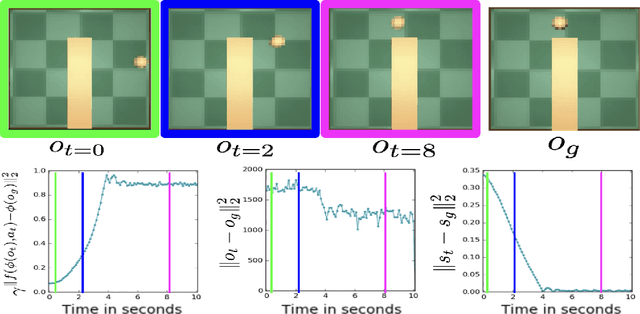
Operating directly from raw high dimensional sensory inputs like images is still a challenge for robotic control. Recently, Reinforcement Learning methods have been proposed to solve specific tasks end-to-end, from pixels to torques. However, these approaches assume the access to a specified reward which may require specialized instrumentation of the environment. Furthermore, the obtained policy and representations tend to be task specific and may not transfer well. In this work we investigate completely self-supervised learning of a general image embedding and control primitives, based on finding the shortest time to reach any state. We also introduce a new structure for the state-action value function that builds a connection between model-free and model-based methods, and improves the performance of the learning algorithm. We experimentally demonstrate these findings in three simulated robotic tasks.
Relative Entropy Regularized Policy Iteration
Dec 05, 2018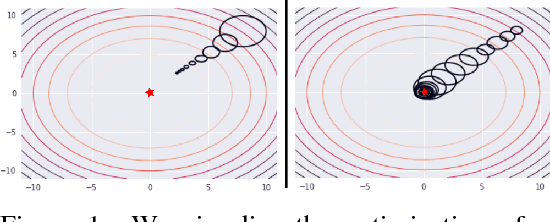
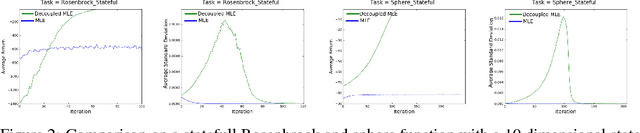

We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .
Entropic Policy Composition with Generalized Policy Improvement and Divergence Correction
Dec 05, 2018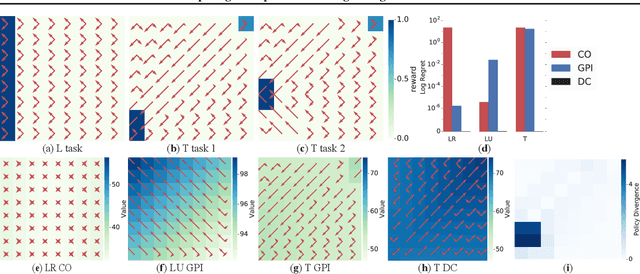

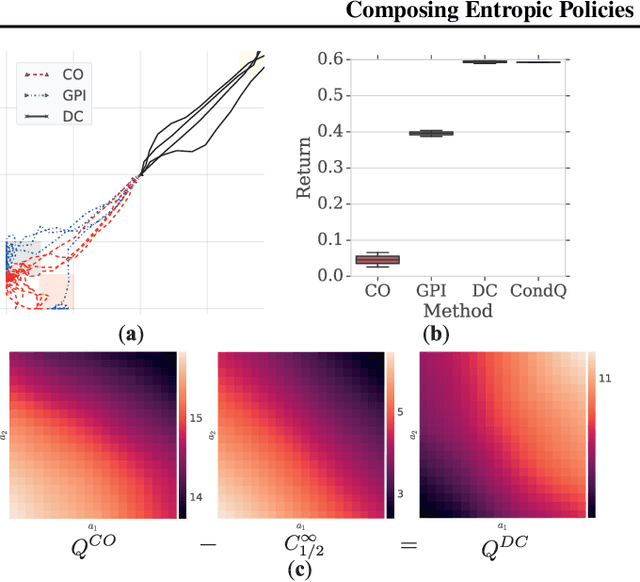

Deep reinforcement learning (RL) algorithms have made great strides in recent years. An important remaining challenge is the ability to quickly transfer existing skills to novel tasks, and to combine existing skills with newly acquired ones. In domains where tasks are solved by composing skills this capacity holds the promise of dramatically reducing the data requirements of deep RL algorithms, and hence increasing their applicability. Recent work has studied ways of composing behaviors represented in the form of action-value functions. We analyze these methods to highlight their strengths and weaknesses, and point out situations where each of them is susceptible to poor performance. To perform this analysis we extend generalized policy improvement to the max-entropy framework and introduce a method for the practical implementation of successor features in continuous action spaces. Then we propose a novel approach which, in principle, recovers the optimal policy during transfer. This method works by explicitly learning the (discounted, future) divergence between policies. We study this approach in the tabular case and propose a scalable variant that is applicable in multi-dimensional continuous action spaces. We compare our approach with existing ones on a range of non-trivial continuous control problems with compositional structure, and demonstrate qualitatively better performance despite not requiring simultaneous observation of all task rewards.
Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures
Dec 04, 2018
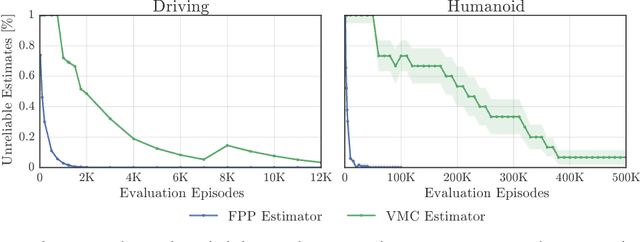
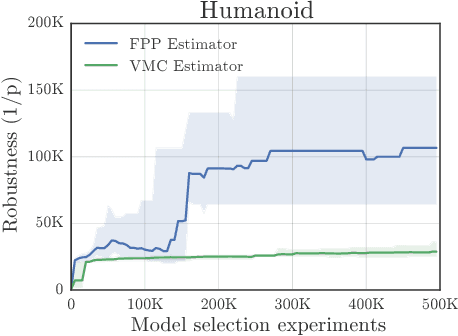

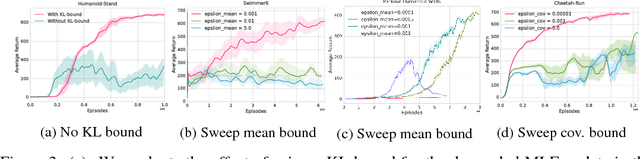
This paper addresses the problem of evaluating learning systems in safety critical domains such as autonomous driving, where failures can have catastrophic consequences. We focus on two problems: searching for scenarios when learned agents fail and assessing their probability of failure. The standard method for agent evaluation in reinforcement learning, Vanilla Monte Carlo, can miss failures entirely, leading to the deployment of unsafe agents. We demonstrate this is an issue for current agents, where even matching the compute used for training is sometimes insufficient for evaluation. To address this shortcoming, we draw upon the rare event probability estimation literature and propose an adversarial evaluation approach. Our approach focuses evaluation on adversarially chosen situations, while still providing unbiased estimates of failure probabilities. The key difficulty is in identifying these adversarial situations -- since failures are rare there is little signal to drive optimization. To solve this we propose a continuation approach that learns failure modes in related but less robust agents. Our approach also allows reuse of data already collected for training the agent. We demonstrate the efficacy of adversarial evaluation on two standard domains: humanoid control and simulated driving. Experimental results show that our methods can find catastrophic failures and estimate failures rates of agents multiple orders of magnitude faster than standard evaluation schemes, in minutes to hours rather than days.
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search
Nov 15, 2018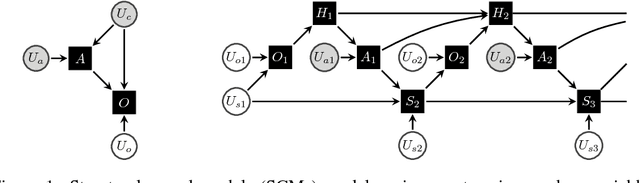
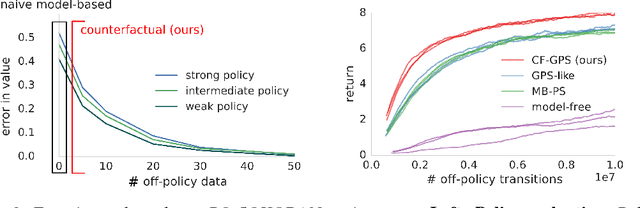
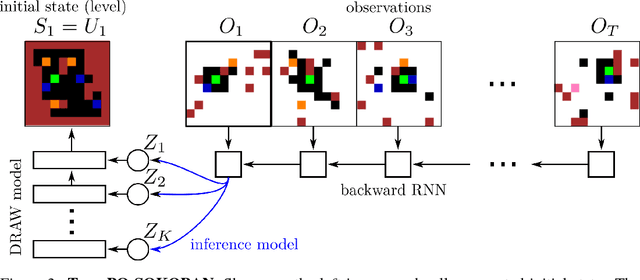
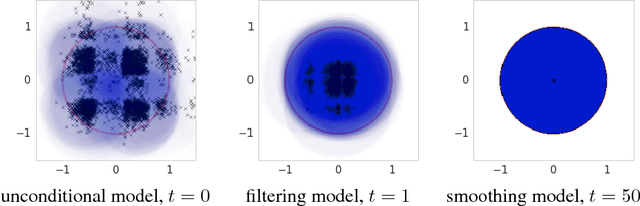
Learning policies on data synthesized by models can in principle quench the thirst of reinforcement learning algorithms for large amounts of real experience, which is often costly to acquire. However, simulating plausible experience de novo is a hard problem for many complex environments, often resulting in biases for model-based policy evaluation and search. Instead of de novo synthesis of data, here we assume logged, real experience and model alternative outcomes of this experience under counterfactual actions, actions that were not actually taken. Based on this, we propose the Counterfactually-Guided Policy Search (CF-GPS) algorithm for learning policies in POMDPs from off-policy experience. It leverages structural causal models for counterfactual evaluation of arbitrary policies on individual off-policy episodes. CF-GPS can improve on vanilla model-based RL algorithms by making use of available logged data to de-bias model predictions. In contrast to off-policy algorithms based on Importance Sampling which re-weight data, CF-GPS leverages a model to explicitly consider alternative outcomes, allowing the algorithm to make better use of experience data. We find empirically that these advantages translate into improved policy evaluation and search results on a non-trivial grid-world task. Finally, we show that CF-GPS generalizes the previously proposed Guided Policy Search and that reparameterization-based algorithms such Stochastic Value Gradient can be interpreted as counterfactual methods.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
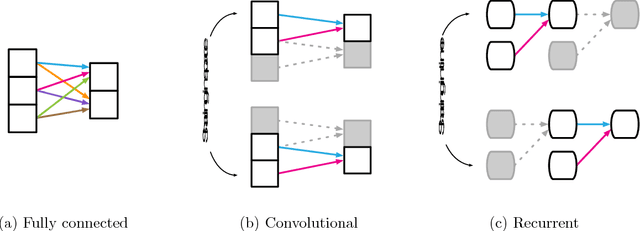
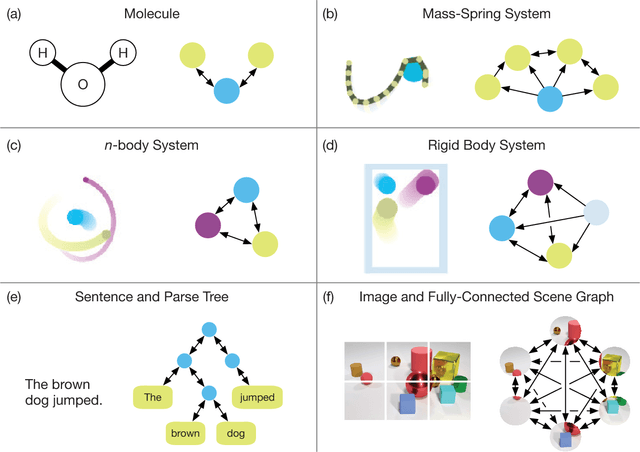
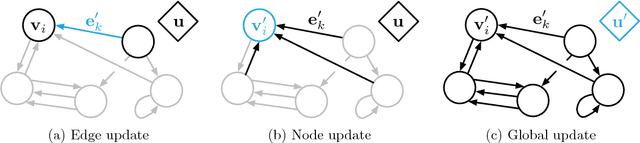
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Oct 08, 2018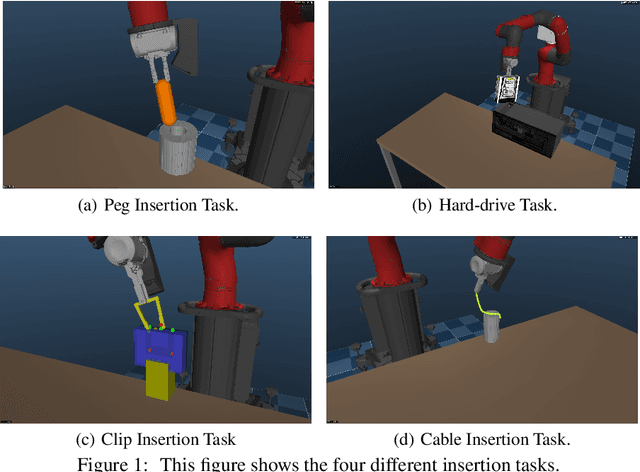

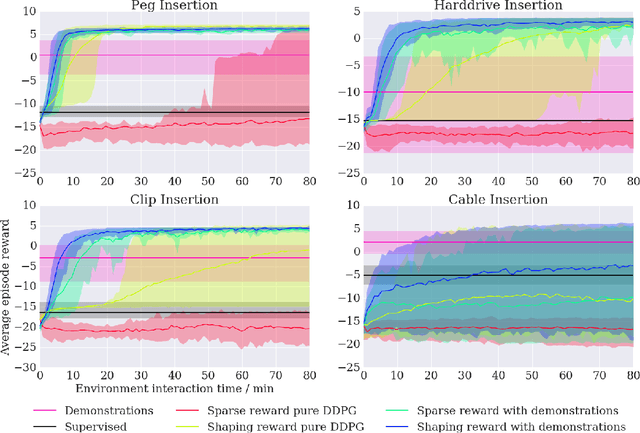
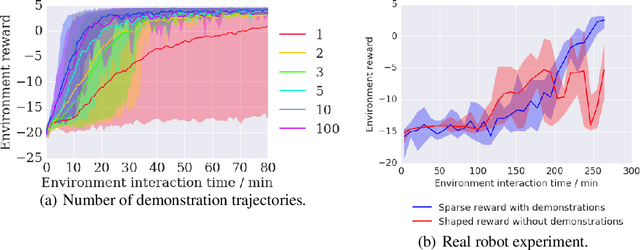
We propose a general and model-free approach for Reinforcement Learning (RL) on real robotics with sparse rewards. We build upon the Deep Deterministic Policy Gradient (DDPG) algorithm to use demonstrations. Both demonstrations and actual interactions are used to fill a replay buffer and the sampling ratio between demonstrations and transitions is automatically tuned via a prioritized replay mechanism. Typically, carefully engineered shaping rewards are required to enable the agents to efficiently explore on high dimensional control problems such as robotics. They are also required for model-based acceleration methods relying on local solvers such as iLQG (e.g. Guided Policy Search and Normalized Advantage Function). The demonstrations replace the need for carefully engineered rewards, and reduce the exploration problem encountered by classical RL approaches in these domains. Demonstrations are collected by a robot kinesthetically force-controlled by a human demonstrator. Results on four simulated insertion tasks show that DDPG from demonstrations out-performs DDPG, and does not require engineered rewards. Finally, we demonstrate the method on a real robotics task consisting of inserting a clip (flexible object) into a rigid object.
Unsupervised Learning of 3D Structure from Images
Jun 19, 2018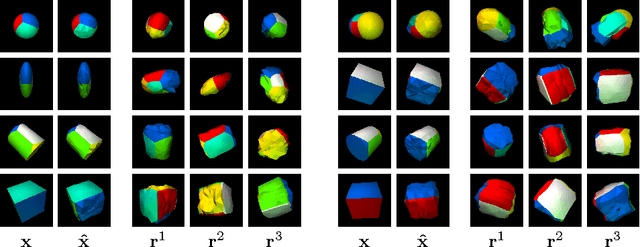
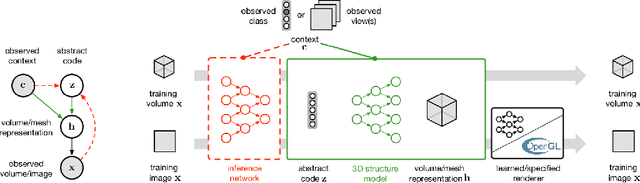


A key goal of computer vision is to recover the underlying 3D structure from 2D observations of the world. In this paper we learn strong deep generative models of 3D structures, and recover these structures from 3D and 2D images via probabilistic inference. We demonstrate high-quality samples and report log-likelihoods on several datasets, including ShapeNet [2], and establish the first benchmarks in the literature. We also show how these models and their inference networks can be trained end-to-end from 2D images. This demonstrates for the first time the feasibility of learning to infer 3D representations of the world in a purely unsupervised manner.
Maximum a Posteriori Policy Optimisation
Jun 14, 2018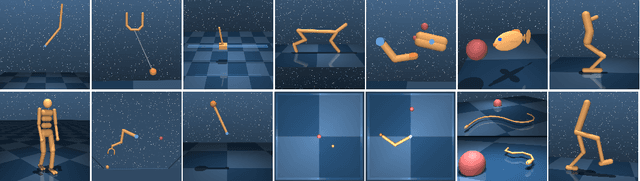
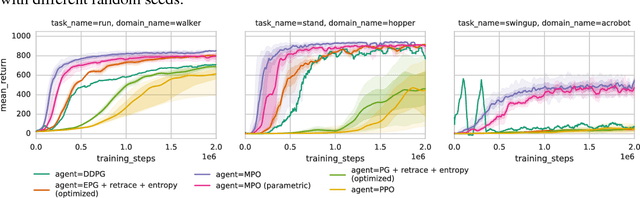
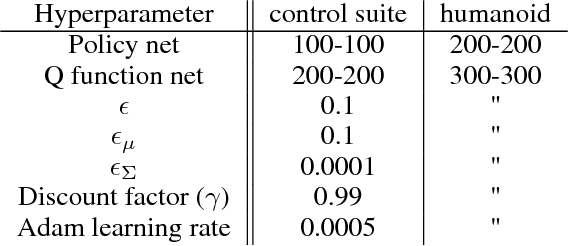
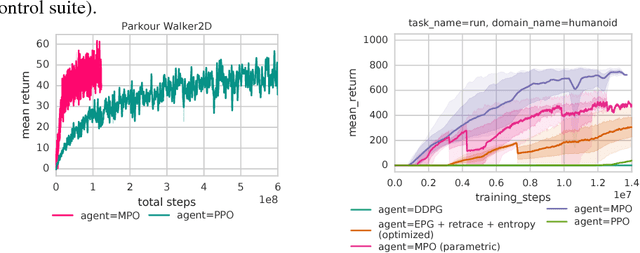
We introduce a new algorithm for reinforcement learning called Maximum aposteriori Policy Optimisation (MPO) based on coordinate ascent on a relative entropy objective. We show that several existing methods can directly be related to our derivation. We develop two off-policy algorithms and demonstrate that they are competitive with the state-of-the-art in deep reinforcement learning. In particular, for continuous control, our method outperforms existing methods with respect to sample efficiency, premature convergence and robustness to hyperparameter settings while achieving similar or better final performance.