 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMunchurl Kim
A HVS-inspired Attention Map to Improve CNN-based Perceptual Losses for Image Restoration
Mar 30, 2019
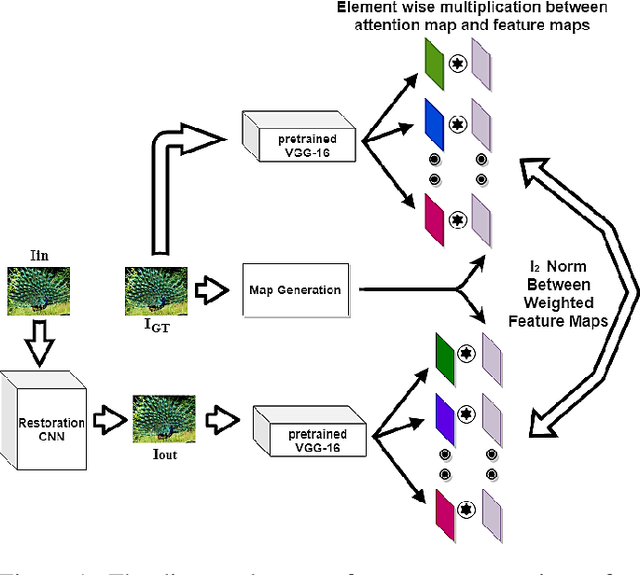
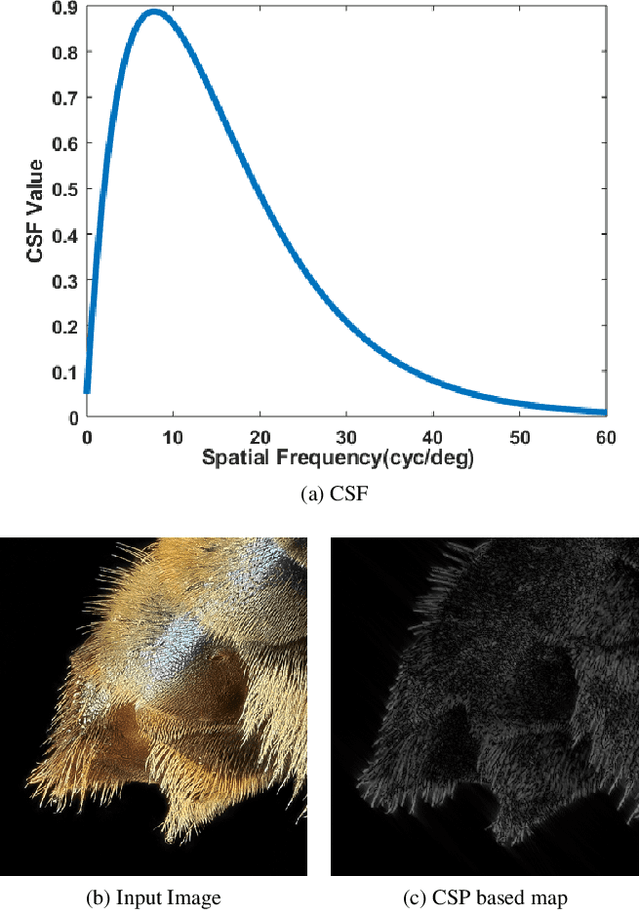
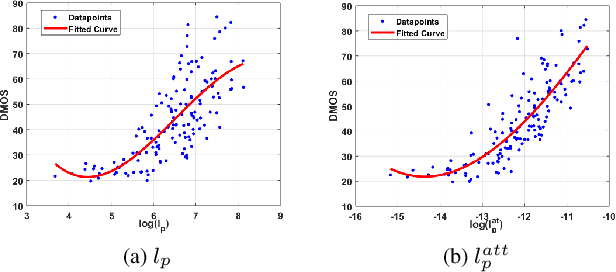
Deep Convolutional Neural Network (CNN) features have been demonstrated to be effective perceptual quality features. The perceptual loss, based on feature maps of pre-trained CNN's has proven to be remarkably effective for CNN based perceptual image restoration problems. In this work, taking inspiration from the the Human Visual System (HVS) and our visual perception, we propose a spatial attention mechanism based on the dependency human contrast sensitivity on spatial frequency. We identify regions in input images, based on underlying spatial frequency where the visual system might be most sensitive to distortions. Based on this prior, we design an attention map that is applied to feature maps in the perceptual loss, helping it to identify regions that are of more perceptual importance. The results will demonstrate that the proposed technique helps improving the correlation of the perceptual loss with human subjective assessment of perceptual quality and also results in a loss which delivers a better perception-distortion trade-off compared to the widely used perceptual loss in CNN based image restoration problems.
A Novel Monocular Disparity Estimation Network with Domain Transformation and Ambiguity Learning
Mar 20, 2019

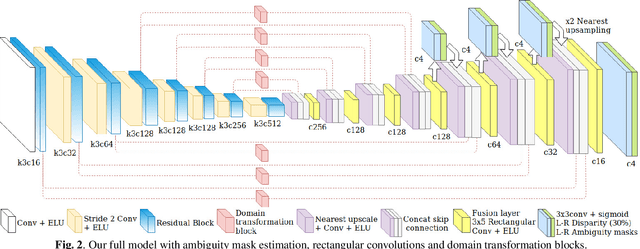
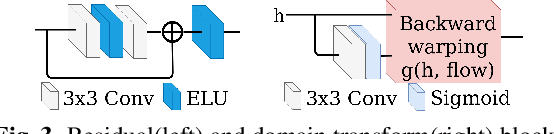
Convolutional neural networks (CNN) have shown state-of-the-art results for low-level computer vision problems such as stereo and monocular disparity estimations, but still, have much room to further improve their performance in terms of accuracy, numbers of parameters, etc. Recent works have uncovered the advantages of using an unsupervised scheme to train CNN's to estimate monocular disparity, where only the relatively-easy-to-obtain stereo images are needed for training. We propose a novel encoder-decoder architecture that outperforms previous unsupervised monocular depth estimation networks by (i) taking into account ambiguities, (ii) efficient fusion between encoder and decoder features with rectangular convolutions and (iii) domain transformations between encoder and decoder. Our architecture outperforms the Monodepth baseline in all metrics, even with a considerable reduction of parameters. Furthermore, our architecture is capable of estimating a full disparity map in a single forward pass, whereas the baseline needs two passes. We perform extensive experiments to verify the effectiveness of our method on the KITTI dataset.
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks
Feb 14, 2019
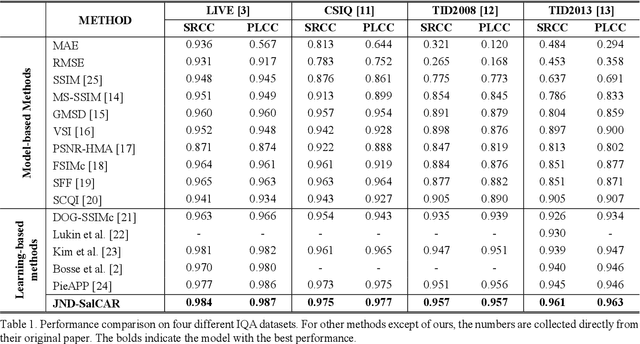
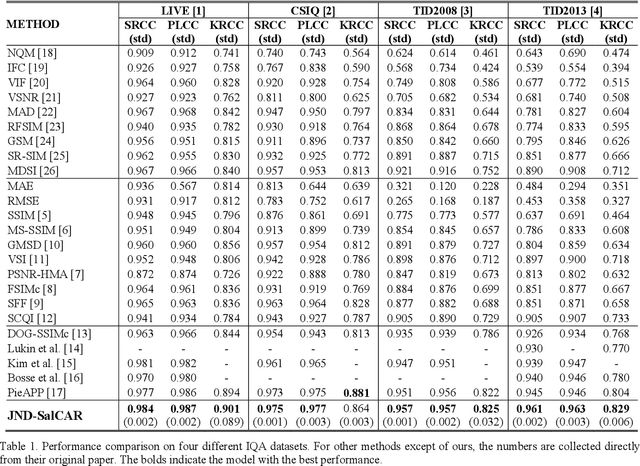
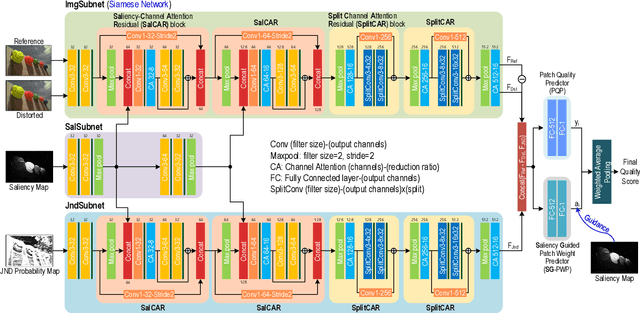
In image quality enhancement processing, it is the most important to predict how humans perceive processed images since human observers are the ultimate receivers of the images. Thus, objective image quality assessment (IQA) methods based on human visual sensitivity from psychophysical experiments have been extensively studied. Thanks to the powerfulness of deep convolutional neural networks (CNN), many CNN based IQA models have been studied. However, previous CNN-based IQA models have not fully utilized the characteristics of human visual systems (HVS) for IQA problems by simply entrusting everything to CNN where the CNN-based models are often trained as a regressor to predict the scores of subjective quality assessment obtained from IQA datasets. In this paper, we propose a novel HVS-inspired deep IQA network, called Deep HVS-IQA Net, where the human psychophysical characteristics such as visual saliency and just noticeable difference (JND) are incorporated at the front-end of the Deep HVS-IQA Net. To our best knowledge, our work is the first HVS-inspired trainable IQA network that considers both the visual saliency and JND characteristics of HVS. Furthermore, we propose a rank loss to train our Deep HVS-IQA Net effectively so that perceptually important features can be extracted for image quality prediction. The rank loss can penalize the Deep HVS-IQA Net when the order of its predicted quality scores is different from that of the ground truth scores. We evaluate the proposed Deep HVS-IQA Net on large IQA datasets where it outperforms all the recent state-of-the-art IQA methods.
3DSRnet: Video Super-resolution using 3D Convolutional Neural Networks
Dec 21, 2018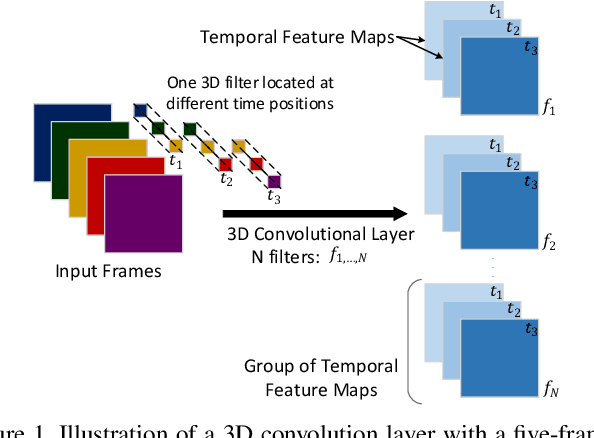
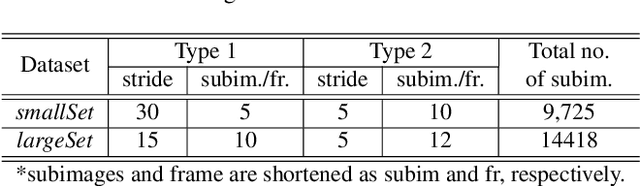
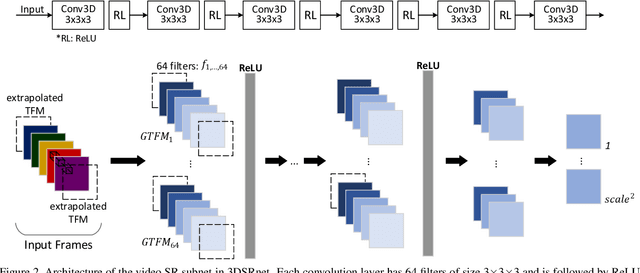
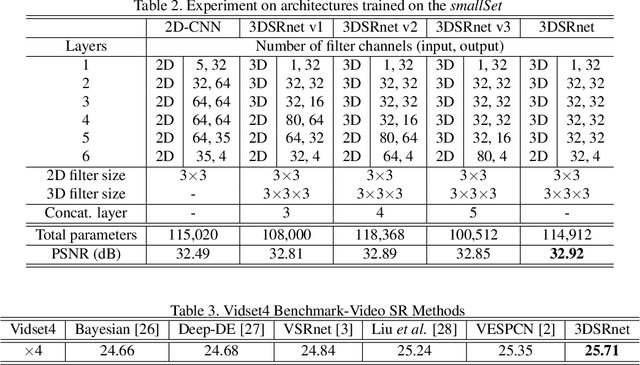
In video super-resolution, the spatio-temporal coherence between, and among the frames must be exploited appropriately for accurate prediction of the high resolution frames. Although 2D convolutional neural networks (CNNs) are powerful in modelling images, 3D-CNNs are more suitable for spatio-temporal feature extraction as they can preserve temporal information. To this end, we propose an effective 3D-CNN for video super-resolution, called the 3DSRnet that does not require motion alignment as preprocessing. Our 3DSRnet maintains the temporal depth of spatio-temporal feature maps to maximally capture the temporally nonlinear characteristics between low and high resolution frames, and adopts residual learning in conjunction with the sub-pixel outputs. It outperforms the most state-of-the-art method with average 0.45 and 0.36 dB higher in PSNR for scales 3 and 4, respectively, in the Vidset4 benchmark. Our 3DSRnet first deals with the performance drop due to scene change, which is important in practice but has not been previously considered.
A Psychovisual Analysis on Deep CNN Features for Perceptual Metrics and A Novel Psychovisual Loss
Dec 02, 2018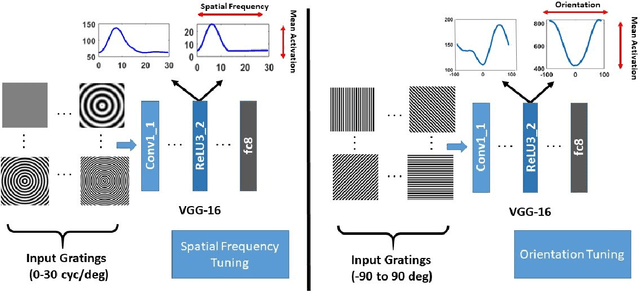
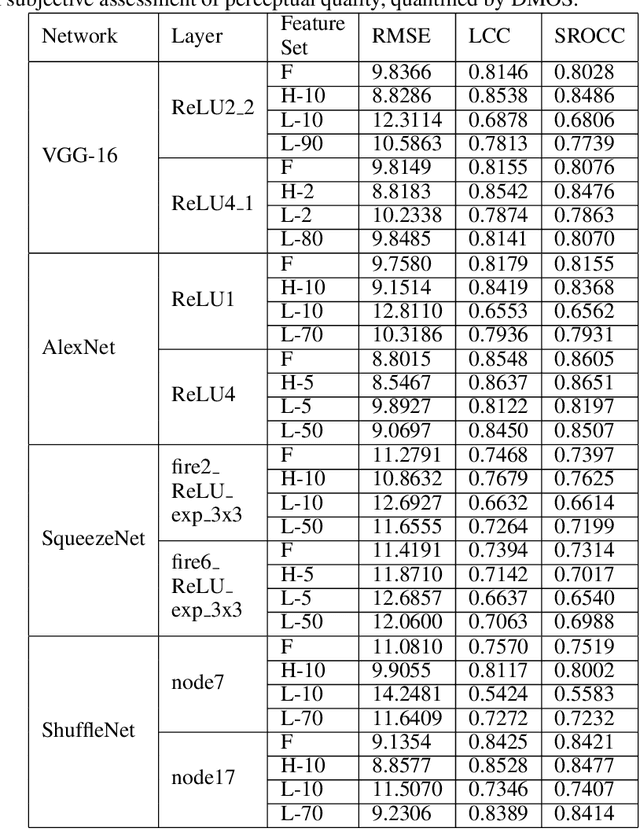
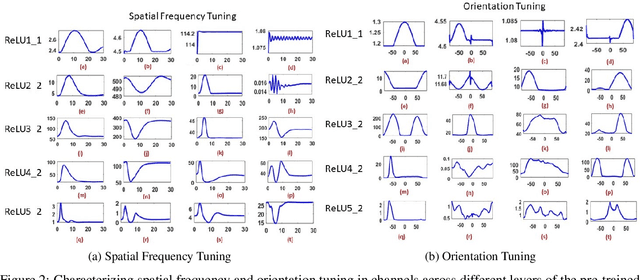
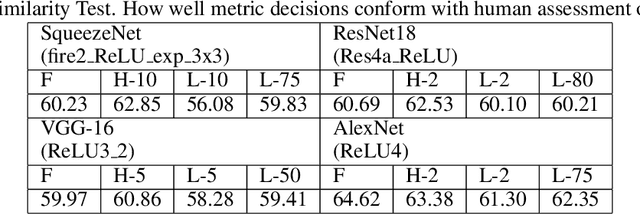
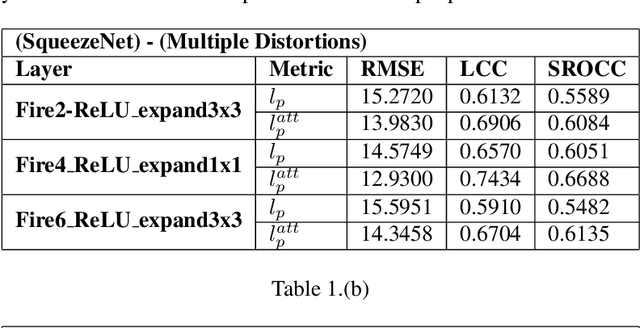
The efficacy of Deep Convolutional Neural Network (CNN) features as perceptual metrics has been demonstrated by researchers. Nevertheless, any thorough analysis in the context of human visual perception on 'why deep CNN features perform well as perceptual metrics?', 'Which layers are better?', 'Which feature maps are better?' and most importantly, 'Why they are better?' has not been studied. In this paper, we address these issues and provide an analysis for deep CNN features in terms of Human Visual System (HVS) characteristics. We scrutinize the frequency tuning of feature maps in a trained deep CNN (e.g., VGG-16) by applying grating stimuli of different spatial frequencies as input, presenting a novel analytical technique that may help us to better understand and compare characteristics of CNNs with the human brain. We observe that feature maps behave as spatial frequency-selective filters which can be best explained by the well-established 'spatial frequency theory' for the visual cortex. We analyze the frequency sensitivity of deep features in relation to the human contrast sensitivity function. Based on this, we design a novel Visual Frequency Sensitivity Score (VFSS) to explain and quantify the efficacy of feature maps as perceptual metrics. Based on our psychovisual analysis, we propose a weighting mechanism to discriminate between feature maps on the basis of their perceptual properties and use this weighting to improve the VGG perceptual loss. The proposed psychovisual loss results in reconstructions with less distortion and better perceptive visual quality.
Finding Correspondences for Optical Flow and Disparity Estimations using a Sub-pixel Convolution-based Encoder-Decoder Network
Oct 07, 2018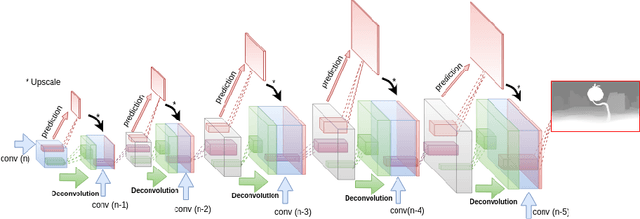
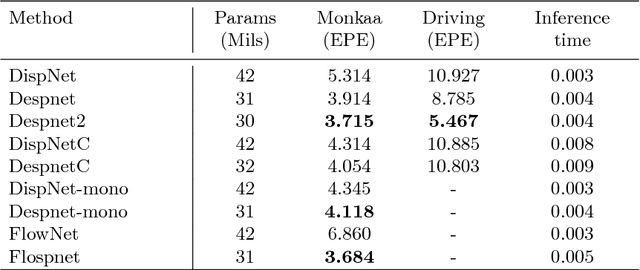
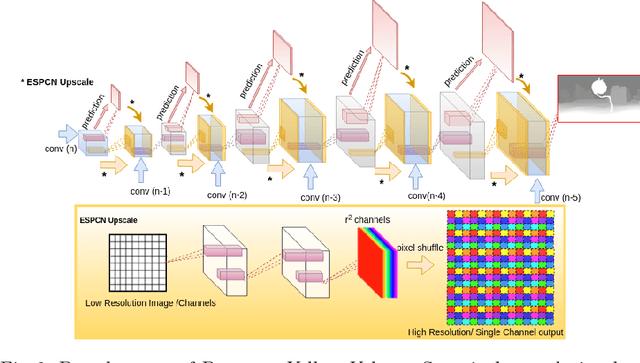
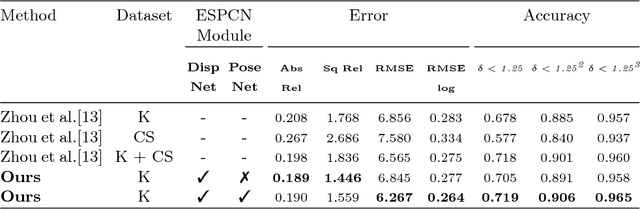
Deep convolutional neural networks (DCNN) have recently shown promising results in low-level computer vision problems such as optical flow and disparity estimation, but still, have much room to further improve their performance. In this paper, we propose a novel sub-pixel convolution-based encoder-decoder network for optical flow and disparity estimations, which can extend FlowNetS and DispNet by replacing the deconvolution layers with sup-pixel convolution blocks. By using sub-pixel refinement and estimation on the decoder stages instead of deconvolution, we can significantly improve the estimation accuracy for optical flow and disparity, even with reduced numbers of parameters. We show a supervised end-to-end training of our proposed networks for optical flow and disparity estimations, and an unsupervised end-to-end training for monocular depth and pose estimations. In order to verify the effectiveness of our proposed networks, we perform intensive experiments for (i) optical flow and disparity estimations, and (ii) monocular depth and pose estimations. Throughout the extensive experiments, our proposed networks outperform the baselines such as FlowNetS and DispNet in terms of estimation accuracy and training times.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
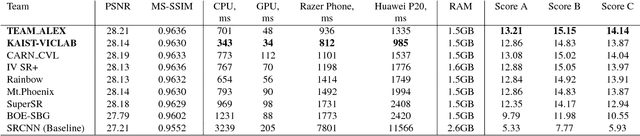

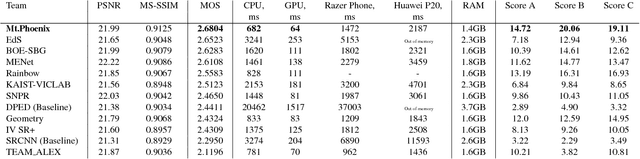
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.
Can Maxout Units Downsize Restoration Networks? - Single Image Super-Resolution Using Lightweight CNN with Maxout Units
Nov 07, 2017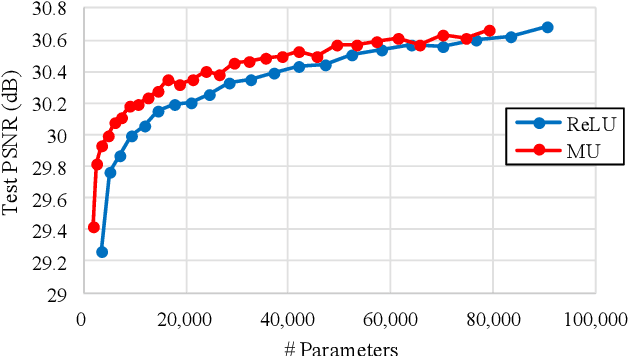
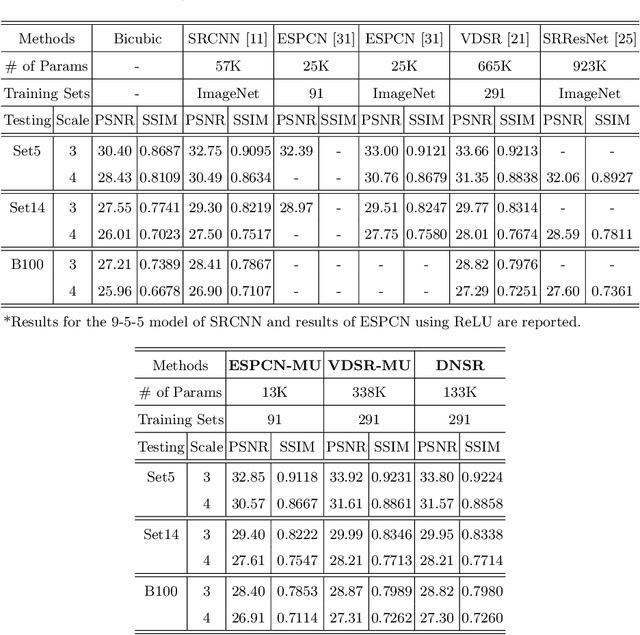
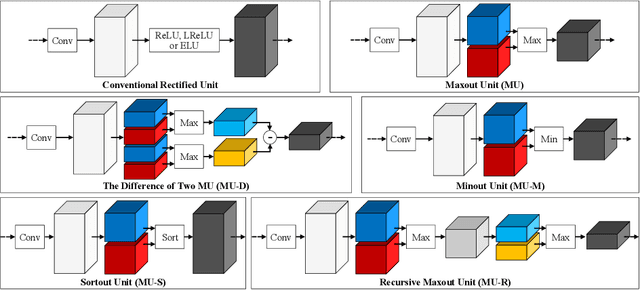
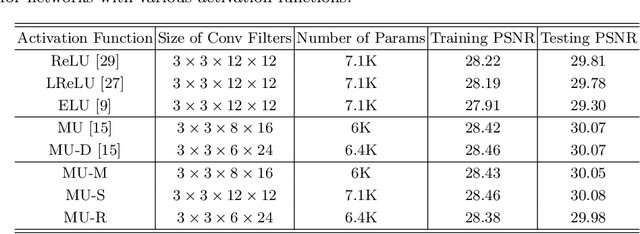
Rectified linear units (ReLU) are well-known to be helpful in obtaining faster convergence and thus higher performance for many deep-learning-based applications. However, networks with ReLU tend to perform poorly when the number of filter parameters is constrained to a small number. To overcome it, in this paper, we propose a novel network utilizing maxout units (MU), and show its effectiveness on super-resolution (SR) applications. In general, the MU has been known to make the filter sizes doubled in generating the feature maps of the same sizes in classification problems. In this paper, we first reveal that the MU can even make the filter sizes halved in restoration problems thus leading to compaction of the network sizes. To show this, our SR network is designed without increasing the filter sizes with MU, which outperforms the state of the art SR methods with a smaller number of filter parameters. To the best of our knowledge, we are the first to incorporate MU into SR applications and show promising performance results. In MU, feature maps from a previous convolutional layer are divided into two parts along channels, which are then compared element-wise and only their max values are passed to a next layer. Along with some interesting properties of MU to be analyzed, we further investigate other variants of MU and their effects. In addition, while ReLU have a trouble for learning in networks with a very small number of convolutional filter parameters, MU do not. For SR applications, our MU-based network reconstructs high-resolution images with comparable quality compared to previous deep-learning-based SR methods, with lower filter parameters.
Real-time detection and tracking of multiple objects with partial decoding in H.264/AVC bitstream domain
Feb 21, 2012In this paper, we show that we can apply probabilistic spatiotemporal macroblock filtering (PSMF) and partial decoding processes to effectively detect and track multiple objects in real time in H.264|AVC bitstreams with stationary background. Our contribution is that our method cannot only show fast processing time but also handle multiple moving objects that are articulated, changing in size or internally have monotonous color, even though they contain a chaotic set of non-homogeneous motion vectors inside. In addition, our partial decoding process for H.264|AVC bitstreams enables to improve the accuracy of object trajectories and overcome long occlusion by using extracted color information.
* SPIE Real-Time Image and Video Processing Conference 2009