 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Animated Layouts as Structured Text Representations
May 02, 2025



Despite the remarkable progress in text-to-video models, achieving precise control over text elements and animated graphics remains a significant challenge, especially in applications such as video advertisements. To address this limitation, we introduce Animated Layout Generation, a novel approach to extend static graphic layouts with temporal dynamics. We propose a Structured Text Representation for fine-grained video control through hierarchical visual elements. To demonstrate the effectiveness of our approach, we present VAKER (Video Ad maKER), a text-to-video advertisement generation pipeline that combines a three-stage generation process with Unstructured Text Reasoning for seamless integration with LLMs. VAKER fully automates video advertisement generation by incorporating dynamic layout trajectories for objects and graphics across specific video frames. Through extensive evaluations, we demonstrate that VAKER significantly outperforms existing methods in generating video advertisements. Project Page: https://yeonsangshin.github.io/projects/Vaker
3DSRnet: Video Super-resolution using 3D Convolutional Neural Networks
Dec 21, 2018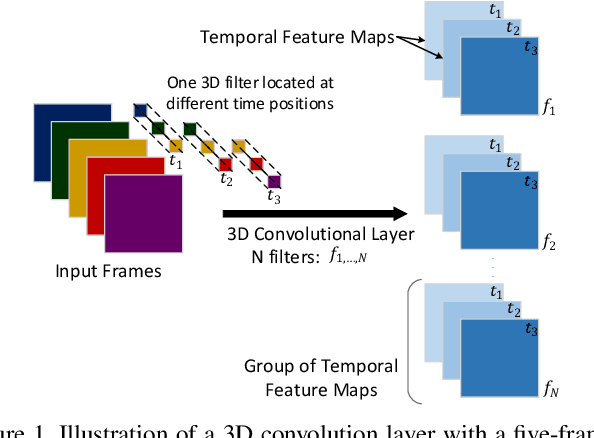
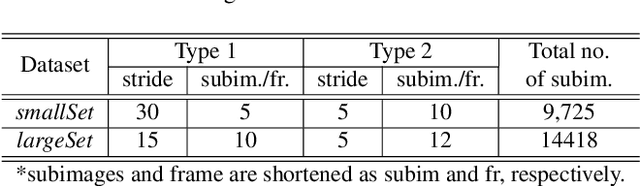
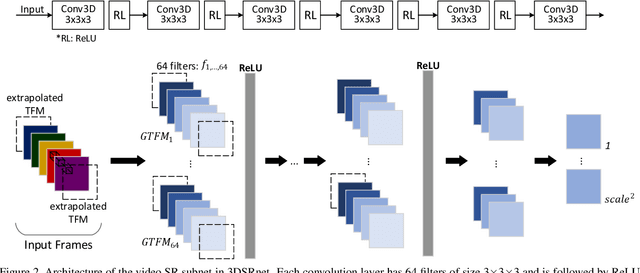
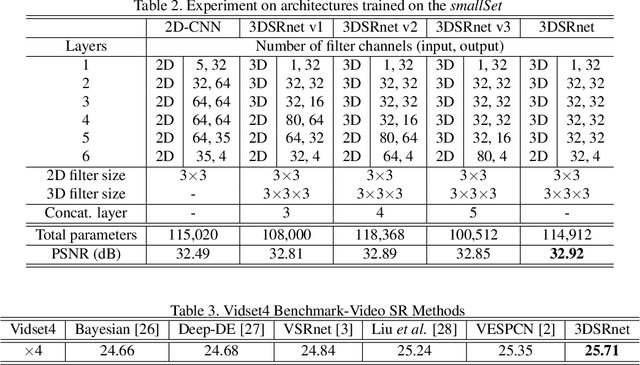
In video super-resolution, the spatio-temporal coherence between, and among the frames must be exploited appropriately for accurate prediction of the high resolution frames. Although 2D convolutional neural networks (CNNs) are powerful in modelling images, 3D-CNNs are more suitable for spatio-temporal feature extraction as they can preserve temporal information. To this end, we propose an effective 3D-CNN for video super-resolution, called the 3DSRnet that does not require motion alignment as preprocessing. Our 3DSRnet maintains the temporal depth of spatio-temporal feature maps to maximally capture the temporally nonlinear characteristics between low and high resolution frames, and adopts residual learning in conjunction with the sub-pixel outputs. It outperforms the most state-of-the-art method with average 0.45 and 0.36 dB higher in PSNR for scales 3 and 4, respectively, in the Vidset4 benchmark. Our 3DSRnet first deals with the performance drop due to scene change, which is important in practice but has not been previously considered.