 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Content-Weighted Deep Image Compression
Apr 01, 2019
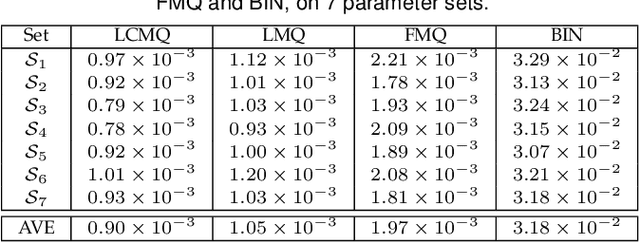
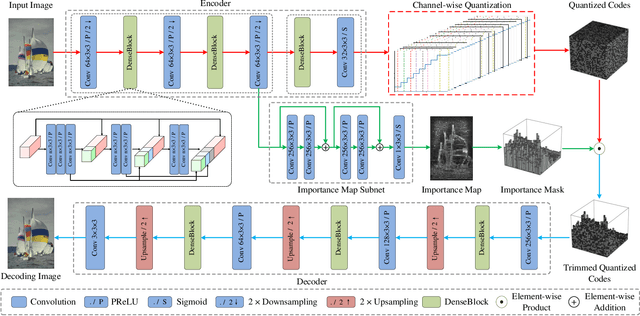
Learning-based lossy image compression usually involves the joint optimization of rate-distortion performance. Most existing methods adopt spatially invariant bit length allocation and incorporate discrete entropy approximation to constrain compression rate. Nonetheless, the information content is spatially variant, where the regions with complex and salient structures generally are more essential to image compression. Taking the spatial variation of image content into account, this paper presents a content-weighted encoder-decoder model, which involves an importance map subnet to produce the importance mask for locally adaptive bit rate allocation. Consequently, the summation of importance mask can thus be utilized as an alternative of entropy estimation for compression rate control. Furthermore, the quantized representations of the learned code and importance map are still spatially dependent, which can be losslessly compressed using arithmetic coding. To compress the codes effectively and efficiently, we propose a trimmed convolutional network to predict the conditional probability of quantized codes. Experiments show that the proposed method can produce visually much better results, and performs favorably in comparison with deep and traditional lossy image compression approaches.
Bag of Tricks for Image Classification with Convolutional Neural Networks
Dec 05, 2018
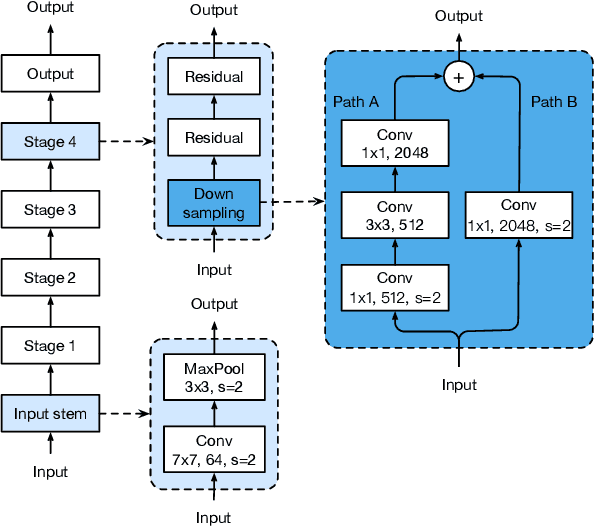
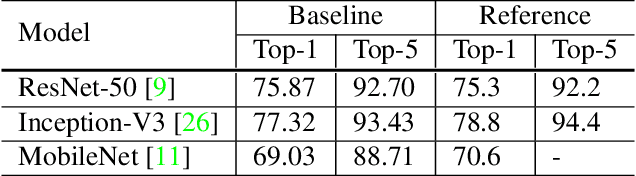
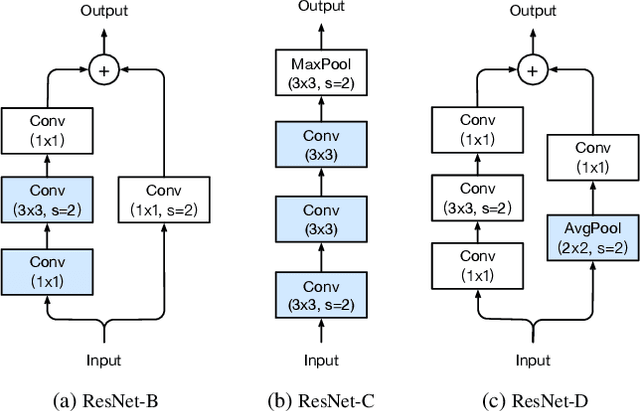
Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50's top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic segmentation.
Approximate Distribution Matching for Sequence-to-Sequence Learning
Sep 02, 2018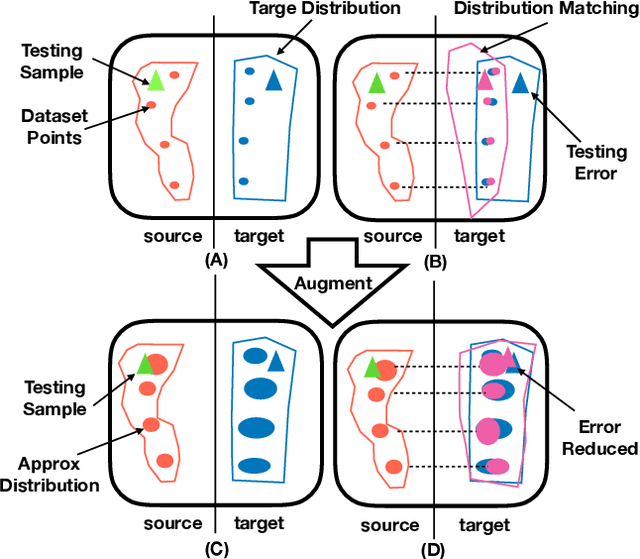
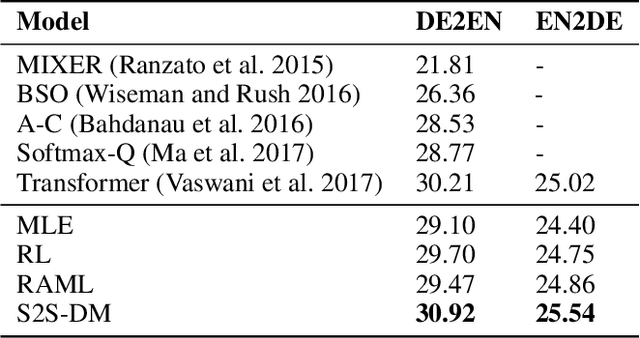
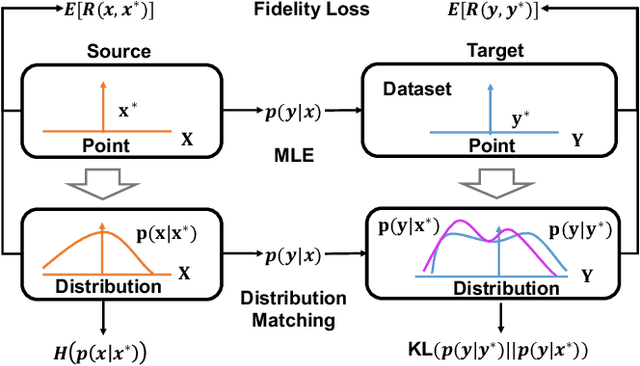
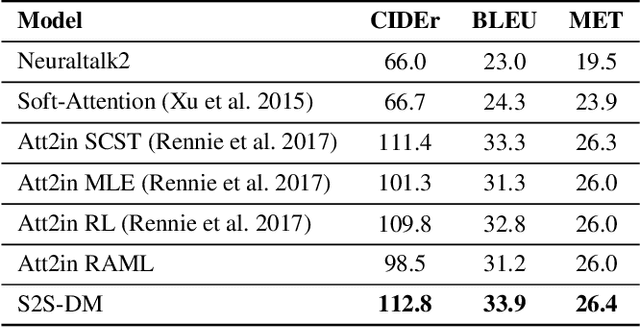
Sequence-to-Sequence models were introduced to tackle many real-life problems like machine translation, summarization, image captioning, etc. The standard optimization algorithms are mainly based on example-to-example matching like maximum likelihood estimation, which is known to suffer from data sparsity problem. Here we present an alternate view to explain sequence-to-sequence learning as a distribution matching problem, where each source or target example is viewed to represent a local latent distribution in the source or target domain. Then, we interpret sequence-to-sequence learning as learning a transductive model to transform the source local latent distributions to match their corresponding target distributions. In our framework, we approximate both the source and target latent distributions with recurrent neural networks (augmenter). During training, the parallel augmenters learn to better approximate the local latent distributions, while the sequence prediction model learns to minimize the KL-divergence of the transformed source distributions and the approximated target distributions. This algorithm can alleviate the data sparsity issues in sequence learning by locally augmenting more unseen data pairs and increasing the model's robustness. Experiments conducted on machine translation and image captioning consistently demonstrate the superiority of our proposed algorithm over the other competing algorithms.
Style Transfer as Unsupervised Machine Translation
Aug 23, 2018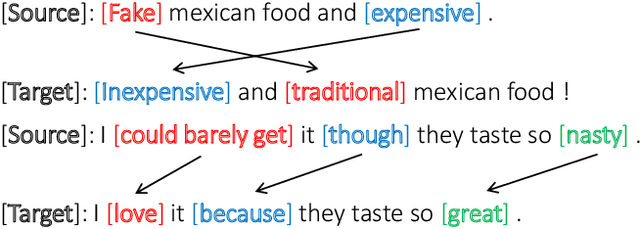
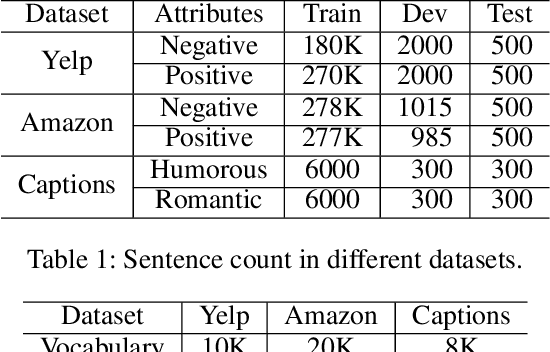
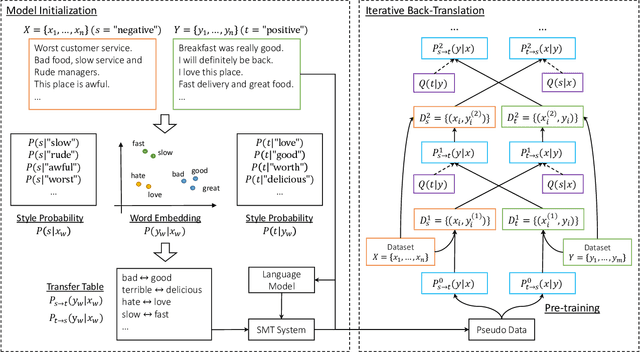
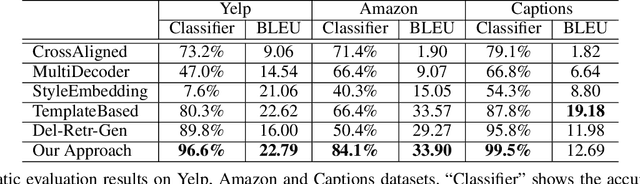
Language style transferring rephrases text with specific stylistic attributes while preserving the original attribute-independent content. One main challenge in learning a style transfer system is a lack of parallel data where the source sentence is in one style and the target sentence in another style. With this constraint, in this paper, we adapt unsupervised machine translation methods for the task of automatic style transfer. We first take advantage of style-preference information and word embedding similarity to produce pseudo-parallel data with a statistical machine translation (SMT) framework. Then the iterative back-translation approach is employed to jointly train two neural machine translation (NMT) based transfer systems. To control the noise generated during joint training, a style classifier is introduced to guarantee the accuracy of style transfer and penalize bad candidates in the generated pseudo data. Experiments on benchmark datasets show that our proposed method outperforms previous state-of-the-art models in terms of both accuracy of style transfer and quality of input-output correspondence.
Regularizing Neural Machine Translation by Target-bidirectional Agreement
Aug 13, 2018
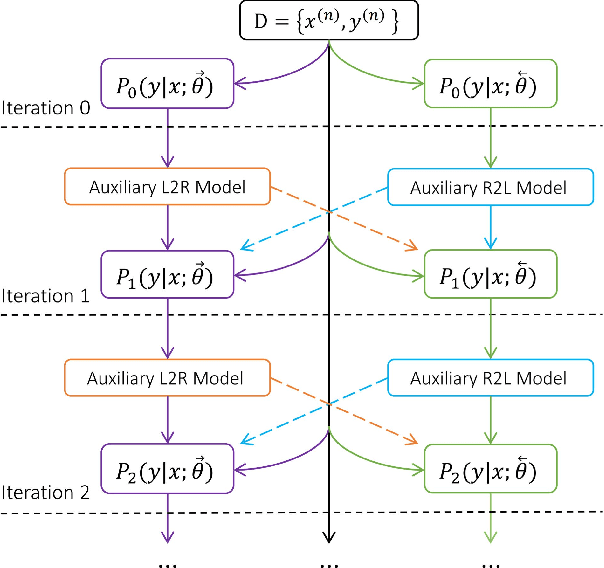

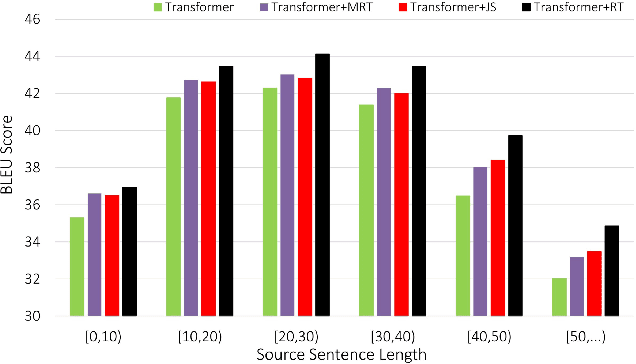
Although Neural Machine Translation (NMT) has achieved remarkable progress in the past several years, most NMT systems still suffer from a fundamental shortcoming as in other sequence generation tasks: errors made early in generation process are fed as inputs to the model and can be quickly amplified, harming subsequent sequence generation. To address this issue, we propose a novel model regularization method for NMT training, which aims to improve the agreement between translations generated by left-to-right (L2R) and right-to-left (R2L) NMT decoders. This goal is achieved by introducing two Kullback-Leibler divergence regularization terms into the NMT training objective to reduce the mismatch between output probabilities of L2R and R2L models. In addition, we also employ a joint training strategy to allow L2R and R2L models to improve each other in an interactive update process. Experimental results show that our proposed method significantly outperforms state-of-the-art baselines on Chinese-English and English-German translation tasks.
Triangular Architecture for Rare Language Translation
Jul 11, 2018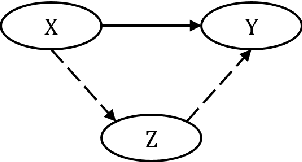
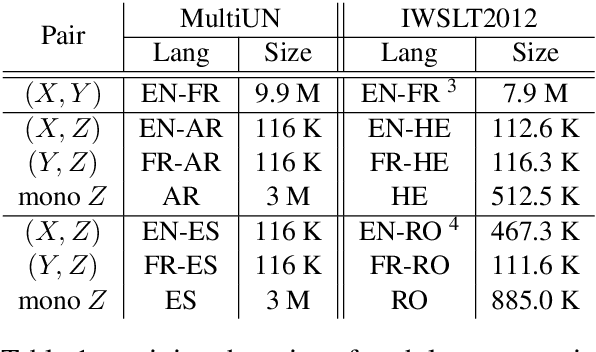
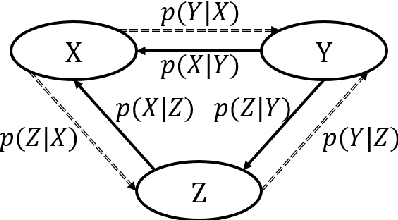

Neural Machine Translation (NMT) performs poor on the low-resource language pair $(X,Z)$, especially when $Z$ is a rare language. By introducing another rich language $Y$, we propose a novel triangular training architecture (TA-NMT) to leverage bilingual data $(Y,Z)$ (may be small) and $(X,Y)$ (can be rich) to improve the translation performance of low-resource pairs. In this triangular architecture, $Z$ is taken as the intermediate latent variable, and translation models of $Z$ are jointly optimized with a unified bidirectional EM algorithm under the goal of maximizing the translation likelihood of $(X,Y)$. Empirical results demonstrate that our method significantly improves the translation quality of rare languages on MultiUN and IWSLT2012 datasets, and achieves even better performance combining back-translation methods.
Enlarging Context with Low Cost: Efficient Arithmetic Coding with Trimmed Convolution
Jul 03, 2018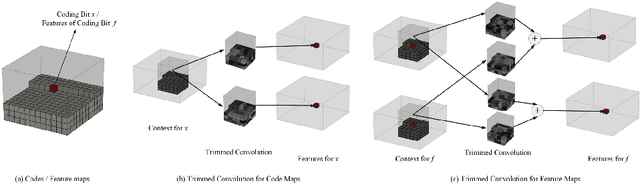
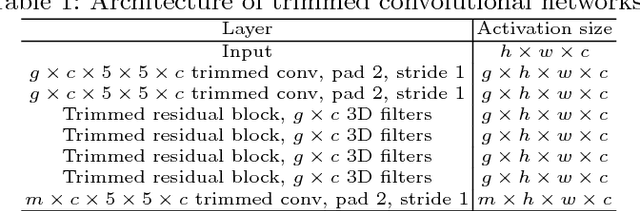
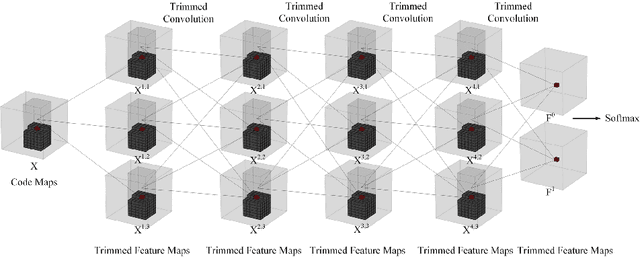
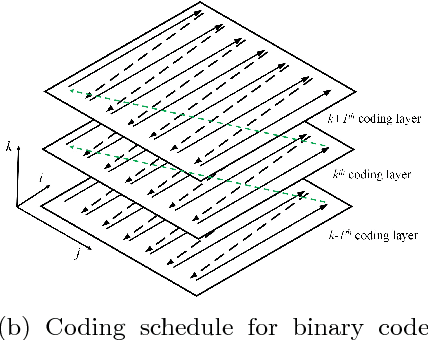
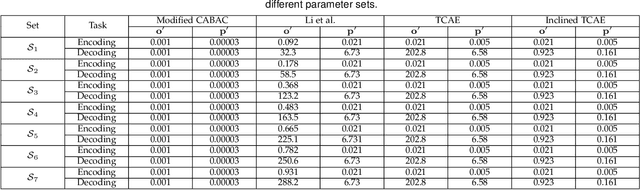
Arithmetic coding is an essential class of coding techniques. One key issue of arithmetic encoding method is to predict the probability of the current coding symbol from its context, i.e., the preceding encoded symbols, which usually can be executed by building a look-up table (LUT). However, the complexity of LUT increases exponentially with the length of context. Thus, such solutions are limited to modeling large context, which inevitably restricts the compression performance. Several recent deep neural network-based solutions have been developed to account for large context, but are still costly in computation. The inefficiency of the existing methods are mainly attributed to that probability prediction is performed independently for the neighboring symbols, which actually can be efficiently conducted by shared computation. To this end, we propose a trimmed convolutional network for arithmetic encoding (TCAE) to model large context while maintaining computational efficiency. As for trimmed convolution, the convolutional kernels are specially trimmed to respect the compression order and context dependency of the input symbols. Benefited from trimmed convolution, the probability prediction of all symbols can be efficiently performed in one single forward pass via a fully convolutional network. Furthermore, to speed up the decoding process, a slope TCAE model is presented to divide the codes from a 3D code map into several blocks and remove the dependency between the codes inner one block for parallel decoding, which can 60x speed up the decoding process. Experiments show that our TCAE and slope TCAE attain better compression ratio in lossless gray image compression, and can be adopted in CNN-based lossy image compression to achieve state-of-the-art rate-distortion performance with real-time encoding speed.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018


Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
Shift-Net: Image Inpainting via Deep Feature Rearrangement
Apr 13, 2018
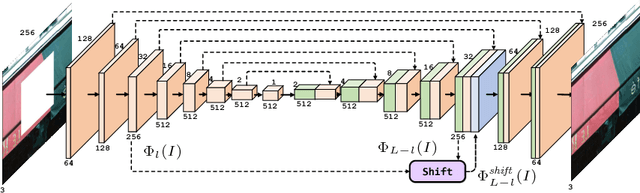


Deep convolutional networks (CNNs) have exhibited their potential in image inpainting for producing plausible results. However, in most existing methods, e.g., context encoder, the missing parts are predicted by propagating the surrounding convolutional features through a fully connected layer, which intends to produce semantically plausible but blurry result. In this paper, we introduce a special shift-connection layer to the U-Net architecture, namely Shift-Net, for filling in missing regions of any shape with sharp structures and fine-detailed textures. To this end, the encoder feature of the known region is shifted to serve as an estimation of the missing parts. A guidance loss is introduced on decoder feature to minimize the distance between the decoder feature after fully connected layer and the ground-truth encoder feature of the missing parts. With such constraint, the decoder feature in missing region can be used to guide the shift of encoder feature in known region. An end-to-end learning algorithm is further developed to train the Shift-Net. Experiments on the Paris StreetView and Places datasets demonstrate the efficiency and effectiveness of our Shift-Net in producing sharper, fine-detailed, and visually plausible results. The codes and pre-trained models are available at https://github.com/Zhaoyi-Yan/Shift-Net.
Generative Bridging Network in Neural Sequence Prediction
Mar 17, 2018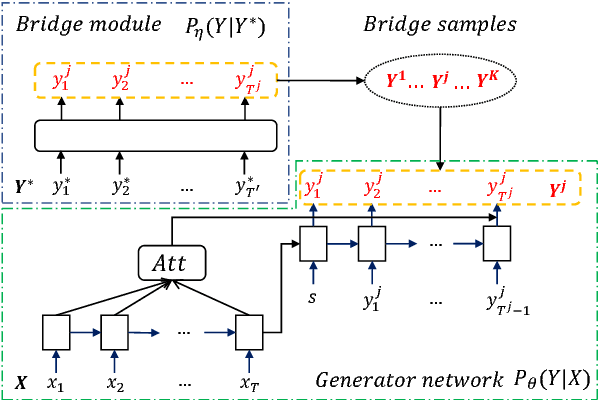
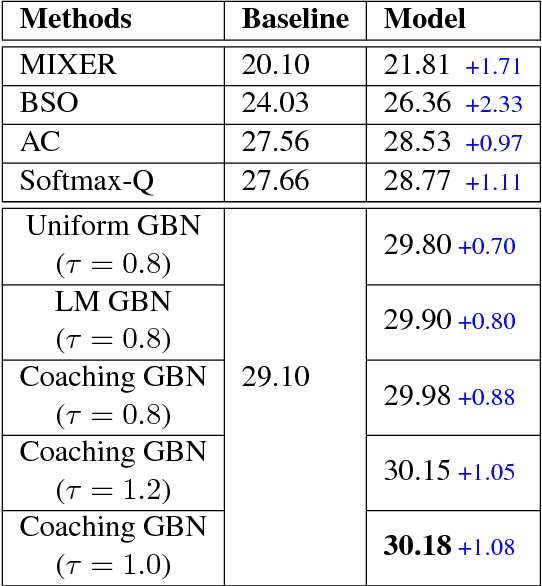
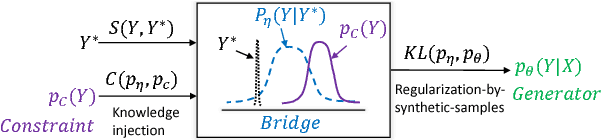
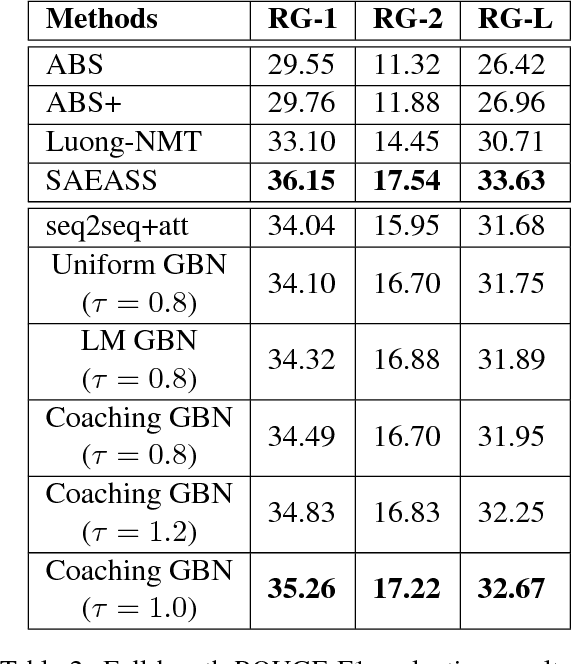
In order to alleviate data sparsity and overfitting problems in maximum likelihood estimation (MLE) for sequence prediction tasks, we propose the Generative Bridging Network (GBN), in which a novel bridge module is introduced to assist the training of the sequence prediction model (the generator network). Unlike MLE directly maximizing the conditional likelihood, the bridge extends the point-wise ground truth to a bridge distribution conditioned on it, and the generator is optimized to minimize their KL-divergence. Three different GBNs, namely uniform GBN, language-model GBN and coaching GBN, are proposed to penalize confidence, enhance language smoothness and relieve learning burden. Experiments conducted on two recognized sequence prediction tasks (machine translation and abstractive text summarization) show that our proposed GBNs can yield significant improvements over strong baselines. Furthermore, by analyzing samples drawn from different bridges, expected influences on the generator are verified.