 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
Mar 11, 2024



Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fall short of generating images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM's in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models.
Contrastive Region Guidance: Improving Grounding in Vision-Language Models without Training
Mar 04, 2024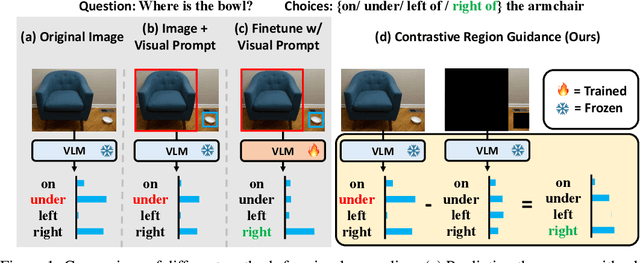
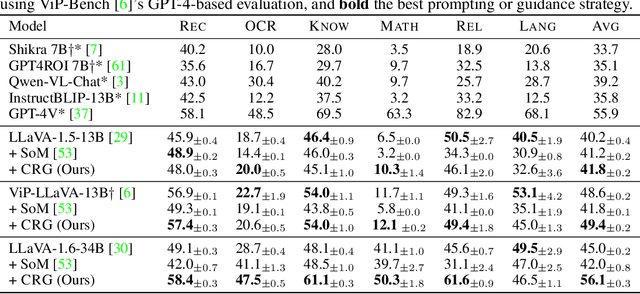
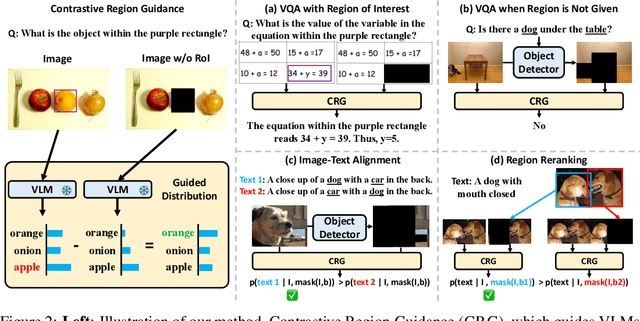
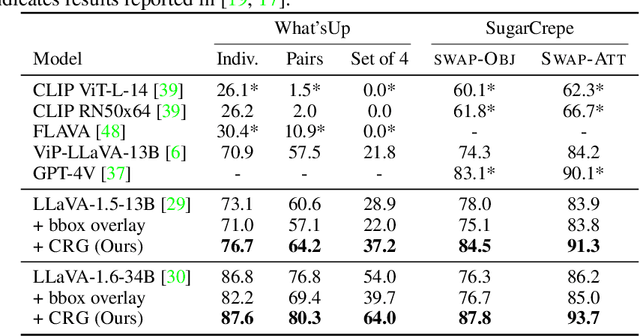
Highlighting particularly relevant regions of an image can improve the performance of vision-language models (VLMs) on various vision-language (VL) tasks by guiding the model to attend more closely to these regions of interest. For example, VLMs can be given a "visual prompt", where visual markers such as bounding boxes delineate key image regions. However, current VLMs that can incorporate visual guidance are either proprietary and expensive or require costly training on curated data that includes visual prompts. We introduce Contrastive Region Guidance (CRG), a training-free guidance method that enables open-source VLMs to respond to visual prompts. CRG contrasts model outputs produced with and without visual prompts, factoring out biases revealed by the model when answering without the information required to produce a correct answer (i.e., the model's prior). CRG achieves substantial improvements in a wide variety of VL tasks: When region annotations are provided, CRG increases absolute accuracy by up to 11.1% on ViP-Bench, a collection of six diverse region-based tasks such as recognition, math, and object relationship reasoning. We also show CRG's applicability to spatial reasoning, with 10% improvement on What'sUp, as well as to compositional generalization -- improving accuracy by 11.5% and 7.5% on two challenging splits from SugarCrepe -- and to image-text alignment for generated images, where we improve by up to 8.4 AUROC and 6.8 F1 points on SeeTRUE. When reference regions are absent, CRG allows us to re-rank proposed regions in referring expression comprehension and phrase grounding benchmarks like RefCOCO/+/g and Flickr30K Entities, with an average gain of 3.2% in accuracy. Our analysis explores alternative masking strategies for CRG, quantifies CRG's probability shift, and evaluates the role of region guidance strength, empirically validating CRG's design choices.
NewsQs: Multi-Source Question Generation for the Inquiring Mind
Feb 28, 2024



We present NewsQs (news-cues), a dataset that provides question-answer pairs for multiple news documents. To create NewsQs, we augment a traditional multi-document summarization dataset with questions automatically generated by a T5-Large model fine-tuned on FAQ-style news articles from the News On the Web corpus. We show that fine-tuning a model with control codes produces questions that are judged acceptable more often than the same model without them as measured through human evaluation. We use a QNLI model with high correlation with human annotations to filter our data. We release our final dataset of high-quality questions, answers, and document clusters as a resource for future work in query-based multi-document summarization.
Evaluating Very Long-Term Conversational Memory of LLM Agents
Feb 27, 2024Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
Soft Self-Consistency Improves Language Model Agents
Feb 20, 2024Generations from large language models (LLMs) can be improved by sampling and scoring multiple solutions to select a final answer. Current "sample and select" methods such as self-consistency (SC) rely on majority voting to score answers. However, when tasks have many distinct and valid answers, selection by voting requires a large number of samples. This makes SC prohibitively expensive for interactive tasks that involve generating multiple actions (answers) sequentially. After establishing that majority voting fails to provide consistent gains on such tasks, we demonstrate how to increase success rates by softening the scoring criterion. We introduce Soft Self-Consistency (Soft-SC), which replaces SC's discontinuous scoring with a continuous score computed from model likelihoods, allowing for selection even when actions are sparsely distributed. Soft-SC improves both performance and efficiency on long-horizon interactive tasks, requiring half as many samples as SC for comparable or better performance. For a fixed number of samples, Soft-SC leads to a 1.3% increase over SC in absolute success rate on writing bash programs, a 6.6% increase on online shopping (WebShop), and a 4.7% increase for an interactive household game (ALFWorld). Finally, we show that Soft-SC can be applied to both open-source and black-box models.
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Feb 19, 2024As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely-recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we investigate two key problems: (1) Characterizing game-theoretic reasoning of LLMs; (2) LLM-vs-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Open-source LLMs, e.g., CodeLlama-34b-Instruct, are less competitive than commercial LLMs, e.g., GPT-4, in complex games. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. Detailed error profiles are also provided for a better understanding of LLMs' behavior.
Rethinking Machine Unlearning for Large Language Models
Feb 15, 2024We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Inducing Systematicity in Transformers by Attending to Structurally Quantized Embeddings
Feb 09, 2024



Transformers generalize to novel compositions of structures and entities after being trained on a complex dataset, but easily overfit on datasets of insufficient complexity. We observe that when the training set is sufficiently complex, the model encodes sentences that have a common syntactic structure using a systematic attention pattern. Inspired by this observation, we propose SQ-Transformer (Structurally Quantized) that explicitly encourages systematicity in the embeddings and attention layers, even with a training set of low complexity. At the embedding level, we introduce Structure-oriented Vector Quantization (SoVQ) to cluster word embeddings into several classes of structurally equivalent entities. At the attention level, we devise the Systematic Attention Layer (SAL) and an alternative, Systematically Regularized Layer (SRL) that operate on the quantized word embeddings so that sentences of the same structure are encoded with invariant or similar attention patterns. Empirically, we show that SQ-Transformer achieves stronger compositional generalization than the vanilla Transformer on multiple low-complexity semantic parsing and machine translation datasets. In our analysis, we show that SoVQ indeed learns a syntactically clustered embedding space and SAL/SRL induces generalizable attention patterns, which lead to improved systematicity.
CREMA: Multimodal Compositional Video Reasoning via Efficient Modular Adaptation and Fusion
Feb 08, 2024Despite impressive advancements in multimodal compositional reasoning approaches, they are still limited in their flexibility and efficiency by processing fixed modality inputs while updating a lot of model parameters. This paper tackles these critical challenges and proposes CREMA, an efficient and modular modality-fusion framework for injecting any new modality into video reasoning. We first augment multiple informative modalities (such as optical flow, 3D point cloud, audio) from given videos without extra human annotation by leveraging existing pre-trained models. Next, we introduce a query transformer with multiple parameter-efficient modules associated with each accessible modality. It projects diverse modality features to the LLM token embedding space, allowing the model to integrate different data types for response generation. Furthermore, we propose a fusion module designed to compress multimodal queries, maintaining computational efficiency in the LLM while combining additional modalities. We validate our method on video-3D, video-audio, and video-language reasoning tasks and achieve better/equivalent performance against strong multimodal LLMs, including BLIP-2, 3D-LLM, and SeViLA while using 96% fewer trainable parameters. We provide extensive analyses of CREMA, including the impact of each modality on reasoning domains, the design of the fusion module, and example visualizations.
VLN-Video: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation
Feb 07, 2024



Outdoor Vision-and-Language Navigation (VLN) requires an agent to navigate through realistic 3D outdoor environments based on natural language instructions. The performance of existing VLN methods is limited by insufficient diversity in navigation environments and limited training data. To address these issues, we propose VLN-Video, which utilizes the diverse outdoor environments present in driving videos in multiple cities in the U.S. augmented with automatically generated navigation instructions and actions to improve outdoor VLN performance. VLN-Video combines the best of intuitive classical approaches and modern deep learning techniques, using template infilling to generate grounded navigation instructions, combined with an image rotation similarity-based navigation action predictor to obtain VLN style data from driving videos for pretraining deep learning VLN models. We pre-train the model on the Touchdown dataset and our video-augmented dataset created from driving videos with three proxy tasks: Masked Language Modeling, Instruction and Trajectory Matching, and Next Action Prediction, so as to learn temporally-aware and visually-aligned instruction representations. The learned instruction representation is adapted to the state-of-the-art navigator when fine-tuning on the Touchdown dataset. Empirical results demonstrate that VLN-Video significantly outperforms previous state-of-the-art models by 2.1% in task completion rate, achieving a new state-of-the-art on the Touchdown dataset.