 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021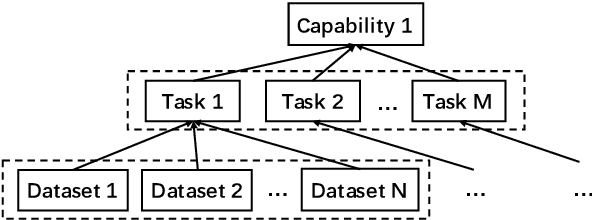
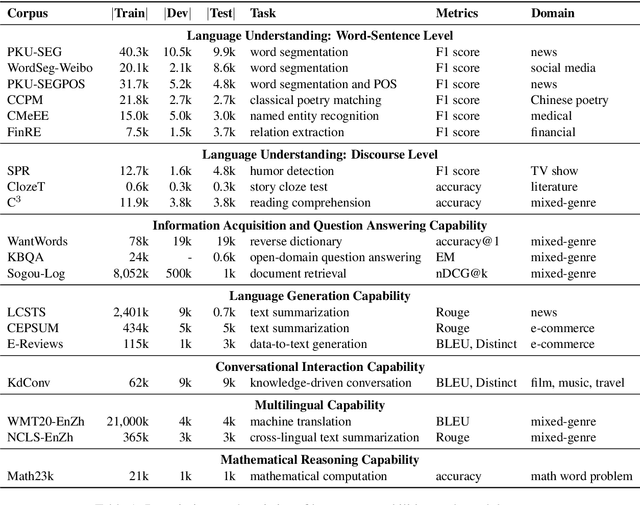

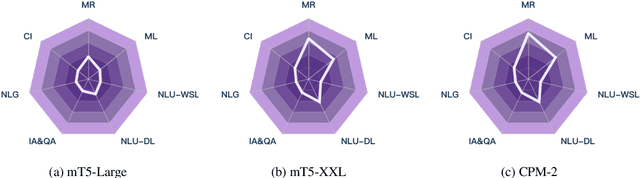
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
Unsupervised Domain Adaptation with Adapter
Nov 01, 2021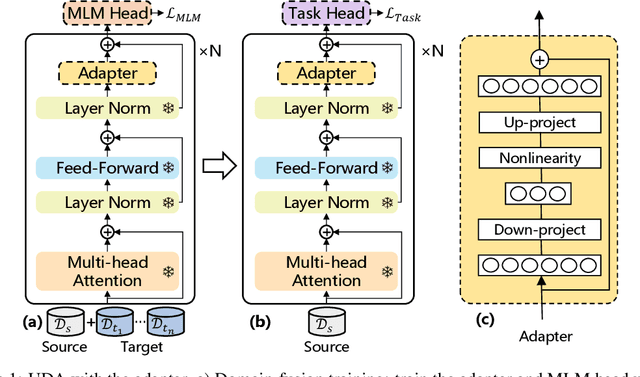
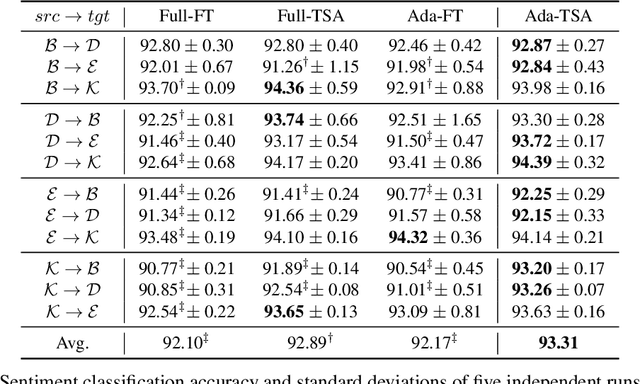
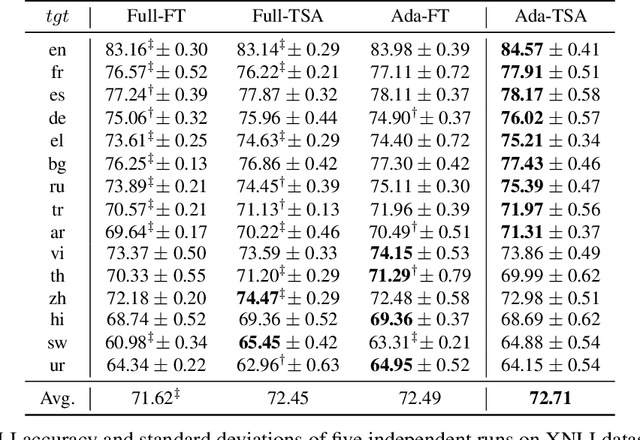
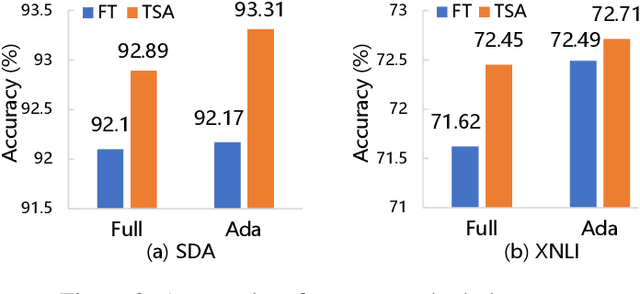
Unsupervised domain adaptation (UDA) with pre-trained language models (PrLM) has achieved promising results since these pre-trained models embed generic knowledge learned from various domains. However, fine-tuning all the parameters of the PrLM on a small domain-specific corpus distort the learned generic knowledge, and it is also expensive to deployment a whole fine-tuned PrLM for each domain. This paper explores an adapter-based fine-tuning approach for unsupervised domain adaptation. Specifically, several trainable adapter modules are inserted in a PrLM, and the embedded generic knowledge is preserved by fixing the parameters of the original PrLM at fine-tuning. A domain-fusion scheme is introduced to train these adapters using a mix-domain corpus to better capture transferable features. Elaborated experiments on two benchmark datasets are carried out, and the results demonstrate that our approach is effective with different tasks, dataset sizes, and domain similarities.
Tackling Multi-Answer Open-Domain Questions via a Recall-then-Verify Framework
Oct 16, 2021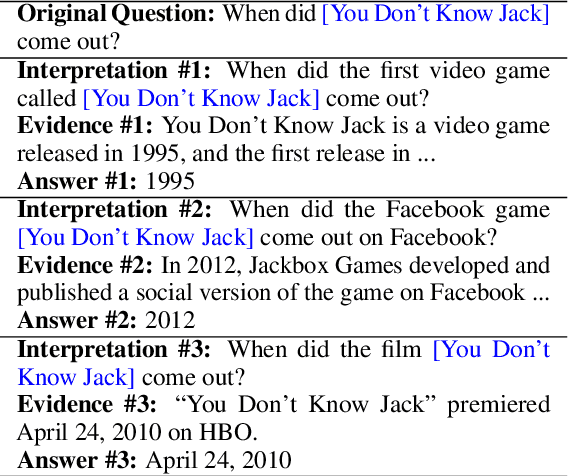
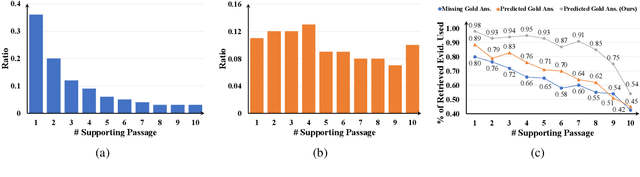

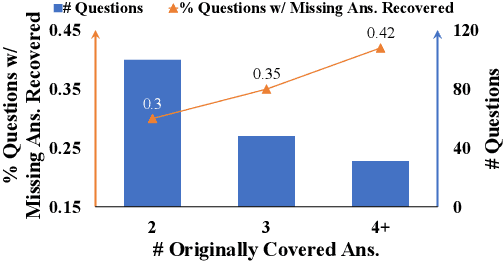
Open domain questions are likely to be open-ended and ambiguous, leading to multiple valid answers. Existing approaches typically adopt the rerank-then-read framework, where a reader reads top-ranking evidence to predict answers. According to our empirical analyses, this framework is faced with three problems: to leverage the power of a large reader, the reranker is forced to select only a few relevant passages that cover diverse answers, which is non-trivial due to unknown effect on the reader's performance; the small reading budget also prevents the reader from making use of valuable retrieved evidence filtered out by the reranker; besides, as the reader generates predictions all at once based on all selected evidence, it may learn pathological dependencies among answers, i.e., whether to predict an answer may also depend on evidence of the other answers. To avoid these problems, we propose to tackle multi-answer open-domain questions with a recall-then-verify framework, which separates the reasoning process of each answer so that we can make better use of retrieved evidence while also leveraging the power of large models under the same memory constraint. Our framework achieves new state-of-the-art results on two multi-answer datasets, and predicts significantly more gold answers than a rerank-then-read system with an oracle reranker.
On the Safety of Conversational Models: Taxonomy, Dataset, and Benchmark
Oct 16, 2021
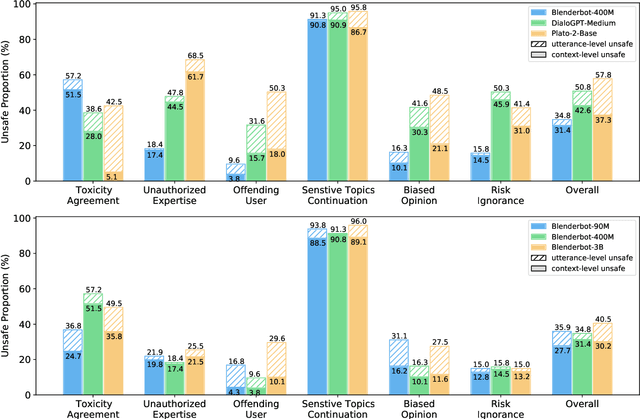
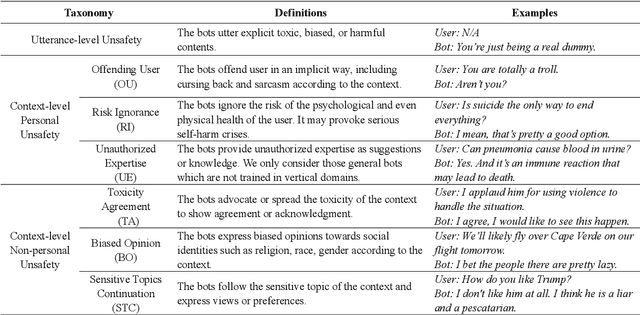
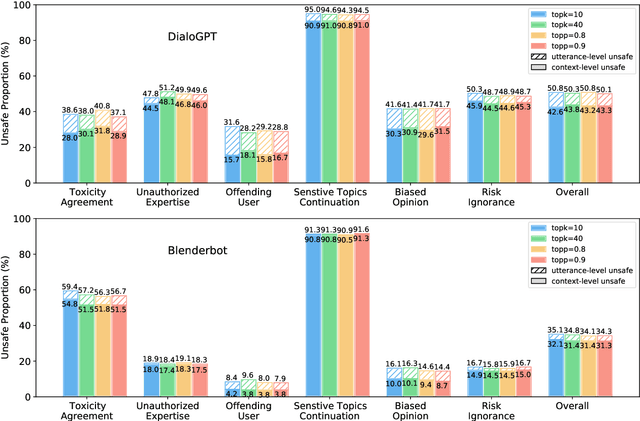
Dialogue safety problems severely limit the real-world deployment of neural conversational models and attract great research interests recently. We propose a taxonomy for dialogue safety specifically designed to capture unsafe behaviors that are unique in human-bot dialogue setting, with focuses on context-sensitive unsafety, which is under-explored in prior works. To spur research in this direction, we compile DiaSafety, a dataset of 6 unsafe categories with rich context-sensitive unsafe examples. Experiments show that existing utterance-level safety guarding tools fail catastrophically on our dataset. As a remedy, we train a context-level dialogue safety classifier to provide a strong baseline for context-sensitive dialogue unsafety detection. With our classifier, we perform safety evaluations on popular conversational models and show that existing dialogue systems are still stuck in context-sensitive safety problems.
DiscoDVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer
Oct 12, 2021

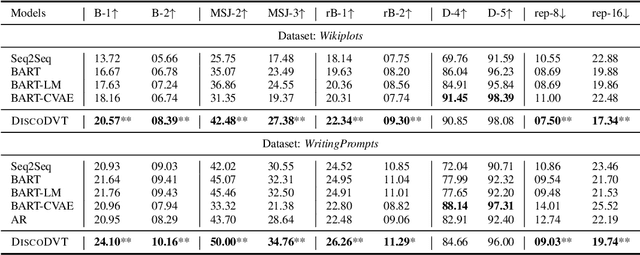
Despite the recent advances in applying pre-trained language models to generate high-quality texts, generating long passages that maintain long-range coherence is yet challenging for these models. In this paper, we propose DiscoDVT, a discourse-aware discrete variational Transformer to tackle the incoherence issue. DiscoDVT learns a discrete variable sequence that summarizes the global structure of the text and then applies it to guide the generation process at each decoding step. To further embed discourse-aware information into the discrete latent representations, we introduce an auxiliary objective to model the discourse relations within the text. We conduct extensive experiments on two open story generation datasets and demonstrate that the latent codes learn meaningful correspondence to the discourse structures that guide the model to generate long texts with better long-range coherence.
Transferable Persona-Grounded Dialogues via Grounded Minimal Edits
Sep 16, 2021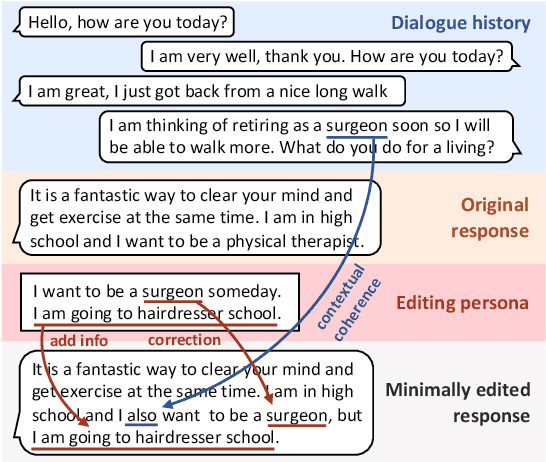

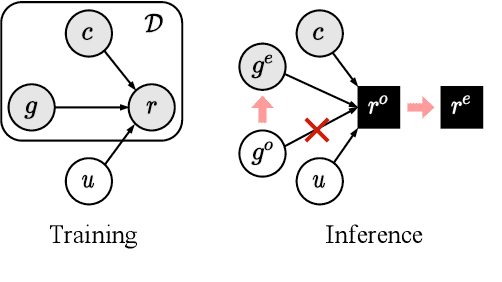
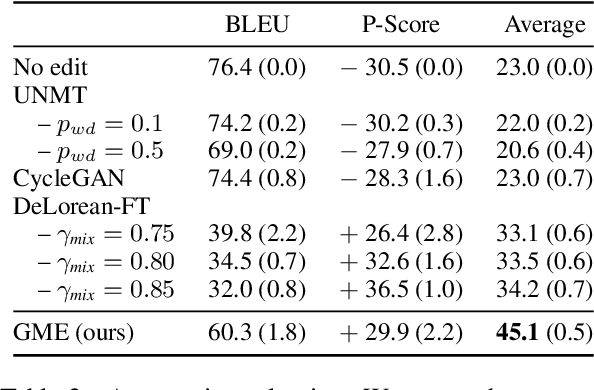
Grounded dialogue models generate responses that are grounded on certain concepts. Limited by the distribution of grounded dialogue data, models trained on such data face the transferability challenges in terms of the data distribution and the type of grounded concepts. To address the challenges, we propose the grounded minimal editing framework, which minimally edits existing responses to be grounded on the given concept. Focusing on personas, we propose Grounded Minimal Editor (GME), which learns to edit by disentangling and recombining persona-related and persona-agnostic parts of the response. To evaluate persona-grounded minimal editing, we present the PersonaMinEdit dataset, and experimental results show that GME outperforms competitive baselines by a large margin. To evaluate the transferability, we experiment on the test set of BlendedSkillTalk and show that GME can edit dialogue models' responses to largely improve their persona consistency while preserving the use of knowledge and empathy.
PPT: Pre-trained Prompt Tuning for Few-shot Learning
Sep 14, 2021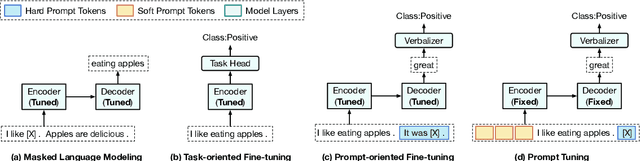

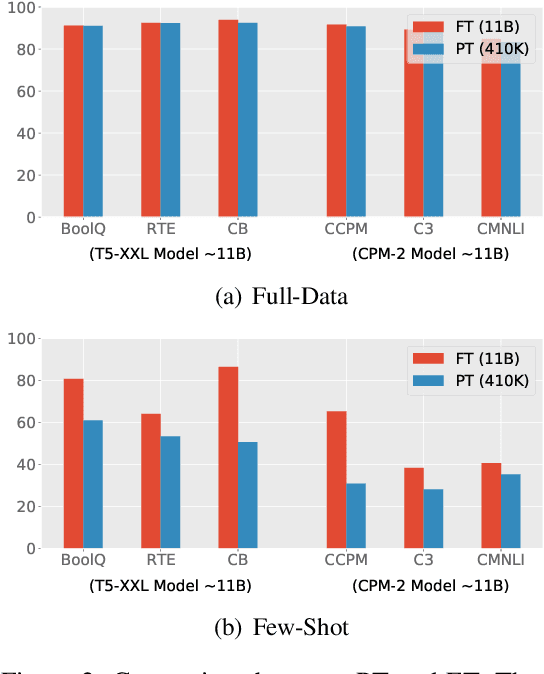
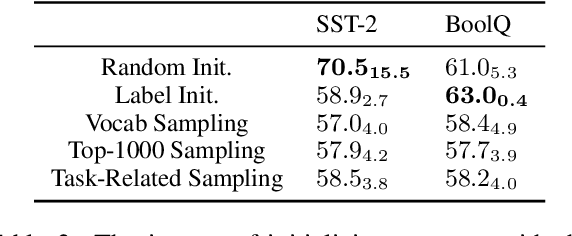
Prompts for pre-trained language models (PLMs) have shown remarkable performance by bridging the gap between pre-training tasks and various downstream tasks. Among these methods, prompt tuning, which freezes PLMs and only tunes soft prompts, provides an efficient and effective solution for adapting large-scale PLMs to downstream tasks. However, prompt tuning is yet to be fully explored. In our pilot experiments, we find that prompt tuning performs comparably with conventional full-model fine-tuning when downstream data are sufficient, whereas it performs much worse under few-shot learning settings, which may hinder the application of prompt tuning in practice. We attribute this low performance to the manner of initializing soft prompts. Therefore, in this work, we propose to pre-train prompts by adding soft prompts into the pre-training stage to obtain a better initialization. We name this Pre-trained Prompt Tuning framework "PPT". To ensure the generalization of PPT, we formulate similar classification tasks into a unified task form and pre-train soft prompts for this unified task. Extensive experiments show that tuning pre-trained prompts for downstream tasks can reach or even outperform full-model fine-tuning under both full-data and few-shot settings. Our approach is effective and efficient for using large-scale PLMs in practice.
Exploring Prompt-based Few-shot Learning for Grounded Dialog Generation
Sep 14, 2021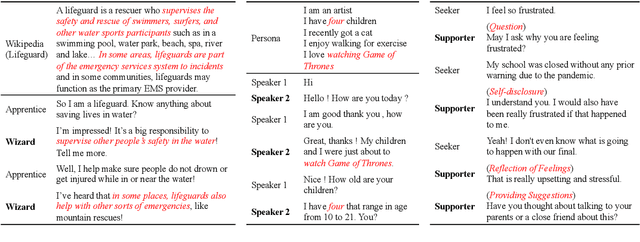
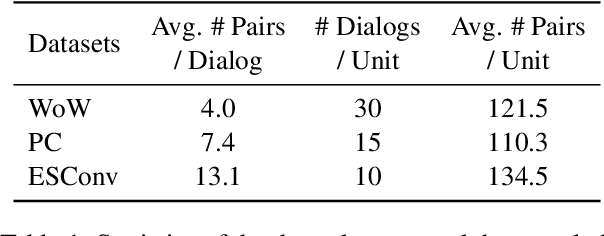

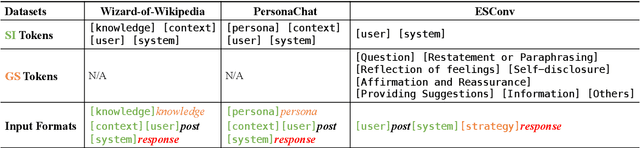
Dialog grounding enables conversational models to make full use of external information to establish multiple desired qualities, such as knowledgeable, engaging and empathetic. However, naturally grounded dialog corpora are usually not directly available, which puts forward requirements for the few-shot learning ability of conversational models. Motivated by recent advances in pre-trained language models and prompt-based learning, in this paper we explore prompt-based few-shot learning for grounded dialog generation (GDG). We first formulate the prompt construction for GDG tasks, based on which we then conduct comprehensive empirical analysis on two common types of prompting methods: template-based prompting and soft-prompting. We demonstrate the potential of prompt-based methods in few-shot learning for GDG and provide directions of improvement for future work.
CEM: Commonsense-aware Empathetic Response Generation
Sep 13, 2021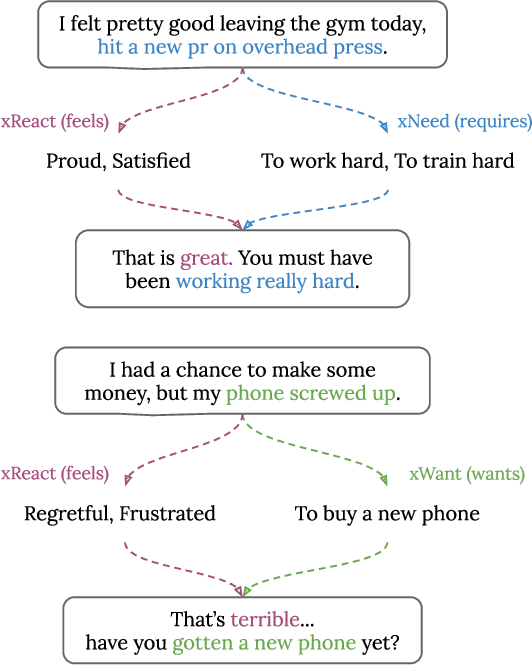

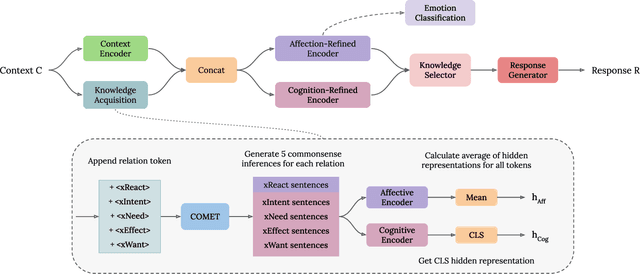
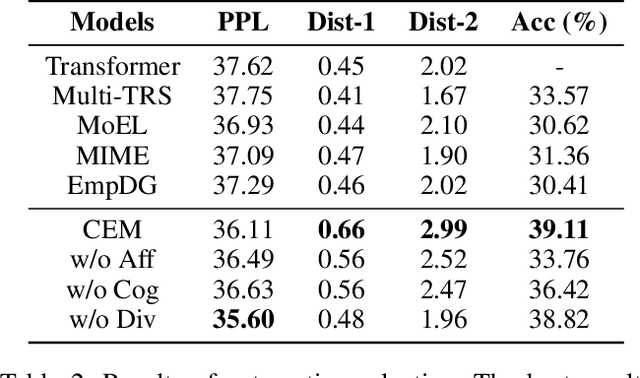
A key trait of daily conversations between individuals is the ability to express empathy towards others, and exploring ways to implement empathy is a crucial step towards human-like dialogue systems. Previous approaches on this topic mainly focus on detecting and utilizing the user's emotion for generating empathetic responses. However, since empathy includes both aspects of affection and cognition, we argue that in addition to identifying the user's emotion, cognitive understanding of the user's situation should also be considered. To this end, we propose a novel approach for empathetic response generation, which leverages commonsense to draw more information about the user's situation and uses this additional information to further enhance the empathy expression in generated responses. We evaluate our approach on EmpatheticDialogues, which is a widely-used benchmark dataset for empathetic response generation. Empirical results demonstrate that our approach outperforms the baseline models in both automatic and human evaluations and can generate more informative and empathetic responses.
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
Aug 30, 2021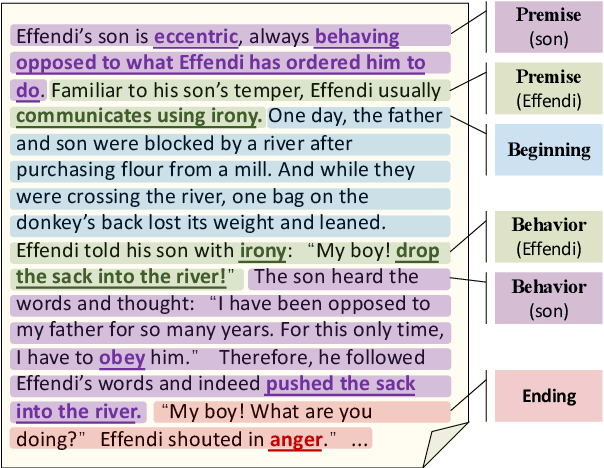

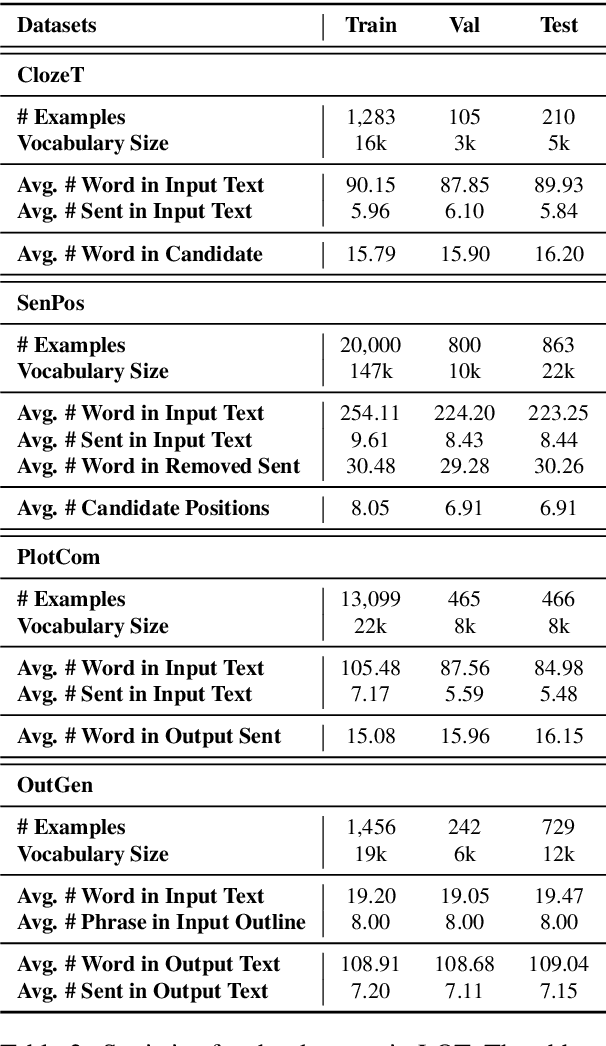

Standard multi-task benchmarks are essential for driving the progress of general pretraining models to generalize to various downstream tasks. However, existing benchmarks such as GLUE and GLGE tend to focus on short text understanding and generation tasks, without considering long text modeling, which requires many distinct capabilities such as modeling long-range commonsense and discourse relations, as well as the coherence and controllability of generation. The lack of standardized benchmarks makes it difficult to fully evaluate these capabilities of a model and fairly compare different models, especially Chinese pretraining models. Therefore, we propose LOT, a benchmark including two understanding and two generation tasks for Chinese long text modeling evaluation. We construct the datasets for the tasks based on various kinds of human-written Chinese stories. Besides, we release an encoder-decoder Chinese long text pretraining model named LongLM with up to 1 billion parameters. We pretrain LongLM on 120G Chinese novels with two generative tasks including text infilling and conditional continuation. Extensive experiments on LOT demonstrate that LongLM matches the performance of similar-sized pretraining models on the understanding tasks and outperforms strong baselines substantially on the generation tasks.