 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Judge Decoding from First Principles via Training-Free Distributional Divergence
Jan 08, 2026Judge Decoding accelerates LLM inference by relaxing the strict verification of Speculative Decoding, yet it typically relies on expensive and noisy supervision. In this work, we revisit this paradigm from first principles, revealing that the ``criticality'' scores learned via costly supervision are intrinsically encoded in the draft-target distributional divergence. We theoretically prove a structural correspondence between learned linear judges and Kullback-Leibler (KL) divergence, demonstrating they rely on the same underlying logit primitives. Guided by this, we propose a simple, training-free verification mechanism based on KL divergence. Extensive experiments across reasoning and coding benchmarks show that our method matches or outperforms complex trained judges (e.g., AutoJudge), offering superior robustness to domain shifts and eliminating the supervision bottleneck entirely.
What Matters For Safety Alignment?
Jan 07, 2026This paper presents a comprehensive empirical study on the safety alignment capabilities. We evaluate what matters for safety alignment in LLMs and LRMs to provide essential insights for developing more secure and reliable AI systems. We systematically investigate and compare the influence of six critical intrinsic model characteristics and three external attack techniques. Our large-scale evaluation is conducted using 32 recent, popular LLMs and LRMs across thirteen distinct model families, spanning a parameter scale from 3B to 235B. The assessment leverages five established safety datasets and probes model vulnerabilities with 56 jailbreak techniques and four CoT attack strategies, resulting in 4.6M API calls. Our key empirical findings are fourfold. First, we identify the LRMs GPT-OSS-20B, Qwen3-Next-80B-A3B-Thinking, and GPT-OSS-120B as the top-three safest models, which substantiates the significant advantage of integrated reasoning and self-reflection mechanisms for robust safety alignment. Second, post-training and knowledge distillation may lead to a systematic degradation of safety alignment. We thus argue that safety must be treated as an explicit constraint or a core optimization objective during these stages, not merely subordinated to the pursuit of general capability. Third, we reveal a pronounced vulnerability: employing a CoT attack via a response prefix can elevate the attack success rate by 3.34x on average and from 0.6% to 96.3% for Seed-OSS-36B-Instruct. This critical finding underscores the safety risks inherent in text-completion interfaces and features that allow user-defined response prefixes in LLM services, highlighting an urgent need for architectural and deployment safeguards. Fourth, roleplay, prompt injection, and gradient-based search for adversarial prompts are the predominant methodologies for eliciting unaligned behaviors in modern models.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025



Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
Re$^{\text{2}}$MaP: Macro Placement by Recursively Prototyping and Packing Tree-based Relocating
Nov 11, 2025This work introduces the Re$^{\text{2}}$MaP method, which generates expert-quality macro placements through recursively prototyping and packing tree-based relocating. We first perform multi-level macro grouping and PPA-aware cell clustering to produce a unified connection matrix that captures both wirelength and dataflow among macros and clusters. Next, we use DREAMPlace to build a mixed-size placement prototype and obtain reference positions for each macro and cluster. Based on this prototype, we introduce ABPlace, an angle-based analytical method that optimizes macro positions on an ellipse to distribute macros uniformly near chip periphery, while optimizing wirelength and dataflow. A packing tree-based relocating procedure is then designed to jointly adjust the locations of macro groups and the macros within each group, by optimizing an expertise-inspired cost function that captures various design constraints through evolutionary search. Re$^{\text{2}}$MaP repeats the above process: Only a subset of macro groups are positioned in each iteration, and the remaining macros are deferred to the next iteration to improve the prototype's accuracy. Using a well-established backend flow with sufficient timing optimizations, Re$^{\text{2}}$MaP achieves up to 22.22% (average 10.26%) improvement in worst negative slack (WNS) and up to 97.91% (average 33.97%) improvement in total negative slack (TNS) compared to the state-of-the-art academic placer Hier-RTLMP. It also ranks higher on WNS, TNS, power, design rule check (DRC) violations, and runtime than the conference version ReMaP, across seven tested cases. Our code is available at https://github.com/lamda-bbo/Re2MaP.
MOSS: Efficient and Accurate FP8 LLM Training with Microscaling and Automatic Scaling
Nov 08, 2025Training large language models with FP8 formats offers significant efficiency gains. However, the reduced numerical precision of FP8 poses challenges for stable and accurate training. Current frameworks preserve training performance using mixed-granularity quantization, i.e., applying per-group quantization for activations and per-tensor/block quantization for weights. While effective, per-group quantization requires scaling along the inner dimension of matrix multiplication, introducing additional dequantization overhead. Moreover, these frameworks often rely on just-in-time scaling to dynamically adjust scaling factors based on the current data distribution. However, this online quantization is inefficient for FP8 training, as it involves multiple memory reads and writes that negate the performance benefits of FP8. To overcome these limitations, we propose MOSS, a novel FP8 training framework that ensures both efficiency and numerical stability. MOSS introduces two key innovations: (1) a two-level microscaling strategy for quantizing sensitive activations, which balances precision and dequantization cost by combining a high-precision global scale with compact, power-of-two local scales; and (2) automatic scaling for weights in linear layers, which eliminates the need for costly max-reduction operations by predicting and adjusting scaling factors during training. Leveraging these techniques, MOSS enables efficient FP8 training of a 7B parameter model, achieving performance comparable to the BF16 baseline while achieving up to 34% higher training throughput.
Beyond Tokens: Enhancing RTL Quality Estimation via Structural Graph Learning
Aug 26, 2025



Estimating the quality of register transfer level (RTL) designs is crucial in the electronic design automation (EDA) workflow, as it enables instant feedback on key metrics like area and delay without the need for time-consuming logic synthesis. While recent approaches have leveraged large language models (LLMs) to derive embeddings from RTL code and achieved promising results, they overlook the structural semantics essential for accurate quality estimation. In contrast, the control data flow graph (CDFG) view exposes the design's structural characteristics more explicitly, offering richer cues for representation learning. In this work, we introduce a novel structure-aware graph self-supervised learning framework, StructRTL, for improved RTL design quality estimation. By learning structure-informed representations from CDFGs, our method significantly outperforms prior art on various quality estimation tasks. To further boost performance, we incorporate a knowledge distillation strategy that transfers low-level insights from post-mapping netlists into the CDFG predictor. Experiments show that our approach establishes new state-of-the-art results, demonstrating the effectiveness of combining structural learning with cross-stage supervision.
ELF: Efficient Logic Synthesis by Pruning Redundancy in Refactoring
Aug 11, 2025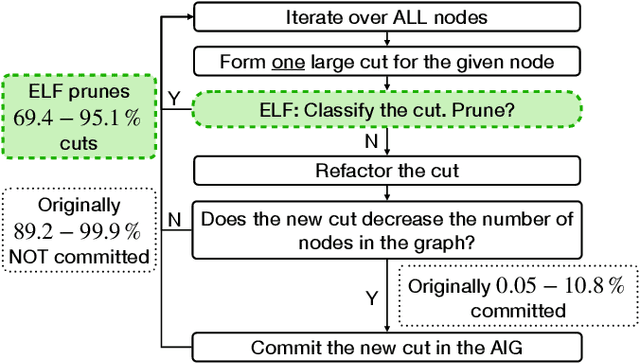
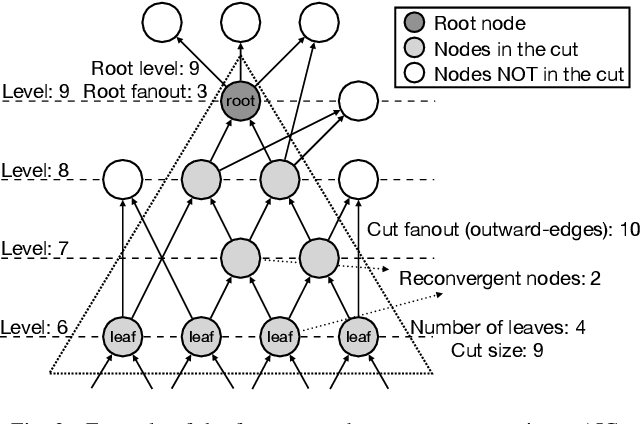
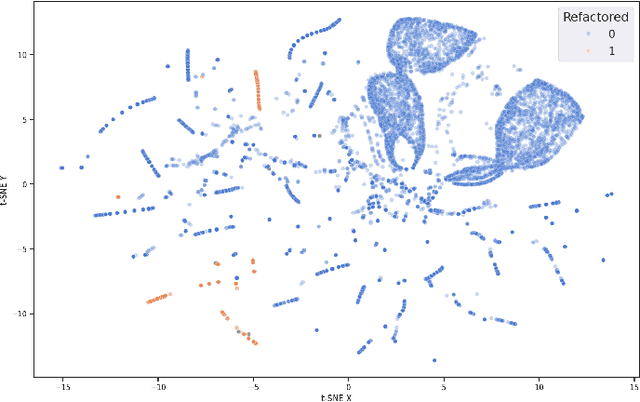
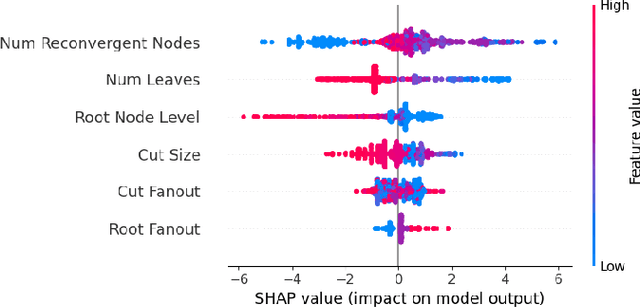
In electronic design automation, logic optimization operators play a crucial role in minimizing the gate count of logic circuits. However, their computation demands are high. Operators such as refactor conventionally form iterative cuts for each node, striving for a more compact representation - a task which often fails 98% on average. Prior research has sought to mitigate computational cost through parallelization. In contrast, our approach leverages a classifier to prune unsuccessful cuts preemptively, thus eliminating unnecessary resynthesis operations. Experiments on the refactor operator using the EPFL benchmark suite and 10 large industrial designs demonstrate that this technique can speedup logic optimization by 3.9x on average compared with the state-of-the-art ABC implementation.
Discovering Interpretable Programmatic Policies via Multimodal LLM-assisted Evolutionary Search
Aug 07, 2025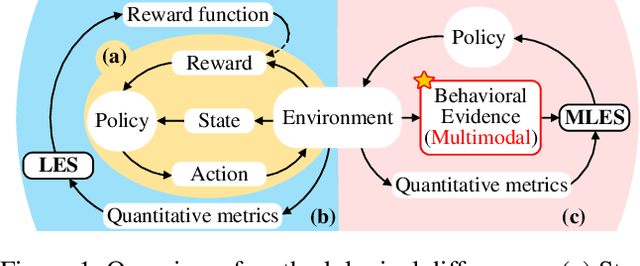
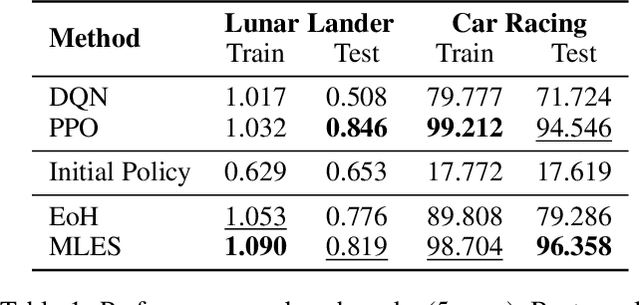
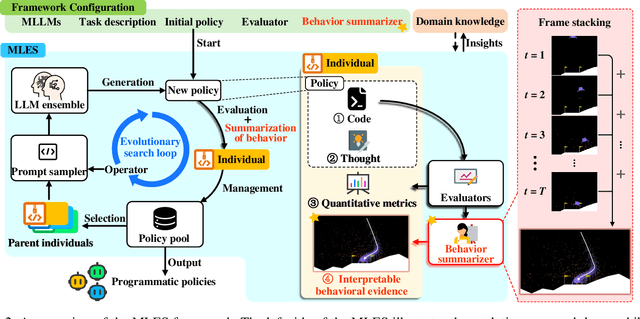
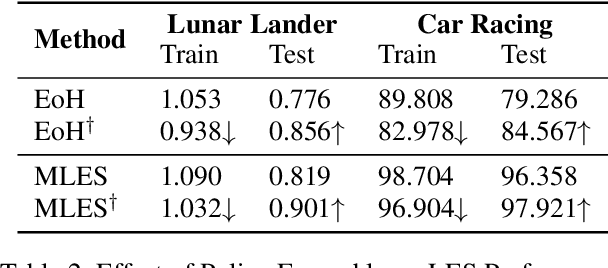
Interpretability and high performance are essential goals in designing control policies, particularly for safety-critical tasks. Deep reinforcement learning has greatly enhanced performance, yet its inherent lack of interpretability often undermines trust and hinders real-world deployment. This work addresses these dual challenges by introducing a novel approach for programmatic policy discovery, called Multimodal Large Language Model-assisted Evolutionary Search (MLES). MLES utilizes multimodal large language models as policy generators, combining them with evolutionary mechanisms for automatic policy optimization. It integrates visual feedback-driven behavior analysis within the policy generation process to identify failure patterns and facilitate targeted improvements, enhancing the efficiency of policy discovery and producing adaptable, human-aligned policies. Experimental results show that MLES achieves policy discovery capabilities and efficiency comparable to Proximal Policy Optimization (PPO) across two control tasks, while offering transparent control logic and traceable design processes. This paradigm overcomes the limitations of predefined domain-specific languages, facilitates knowledge transfer and reuse, and is scalable across various control tasks. MLES shows promise as a leading approach for the next generation of interpretable control policy discovery.
PreMoe: Lightening MoEs on Constrained Memory by Expert Pruning and Retrieval
May 23, 2025



Mixture-of-experts (MoE) architectures enable scaling large language models (LLMs) to vast parameter counts without a proportional rise in computational costs. However, the significant memory demands of large MoE models hinder their deployment across various computational environments, from cloud servers to consumer devices. This study first demonstrates pronounced task-specific specialization in expert activation patterns within MoE layers. Building on this, we introduce PreMoe, a novel framework that enables efficient deployment of massive MoE models in memory-constrained environments. PreMoe features two main components: probabilistic expert pruning (PEP) and task-adaptive expert retrieval (TAER). PEP employs a new metric, the task-conditioned expected selection score (TCESS), derived from router logits to quantify expert importance for specific tasks, thereby identifying a minimal set of critical experts. TAER leverages these task-specific expert importance profiles for efficient inference. It pre-computes and stores compact expert patterns for diverse tasks. When a user query is received, TAER rapidly identifies the most relevant stored task pattern and reconstructs the model by loading only the small subset of experts crucial for that task. This approach dramatically reduces the memory footprint across all deployment scenarios. DeepSeek-R1 671B maintains 97.2\% accuracy on MATH500 when pruned to 8/128 configuration (50\% expert reduction), and still achieves 72.0\% with aggressive 8/32 pruning (87.5\% expert reduction). Pangu-Ultra-MoE 718B achieves 97.15\% on MATH500 and 81.3\% on AIME24 with 8/128 pruning, while even more aggressive pruning to 4/64 (390GB memory) preserves 96.95\% accuracy on MATH500. We make our code publicly available at https://github.com/JarvisPei/PreMoe.