 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Decoder Scaling Strategy for Neural Routing Solvers
Feb 28, 2026Construction-based neural routing solvers, typically composed of an encoder and a decoder, have emerged as a promising approach for solving vehicle routing problems. While recent studies suggest that shifting parameters from the encoder to the decoder enhances performance, most works restrict the decoder size to 1-3M parameters, leaving the effects of scaling largely unexplored. To address this gap, we conduct a systematic study comparing two distinct strategies: scaling depth versus scaling width. We synthesize these strategies to construct a suite of 12 model configurations, spanning a parameter range from 1M to ~150M, and extensively evaluate their scaling behaviors across three critical dimensions: parameter efficiency, data efficiency, and compute efficiency. Our empirical results reveal that parameter count is insufficient to accurately predict the model performance, highlighting the critical and distinct roles of model depth (layer count) and width (embedding dimension). Crucially, we demonstrate that scaling depth yields superior performance gains to scaling width. Based on these findings, we provide and experimentally validate a set of design principles for the efficient allocation of parameters and compute resources to enhance the model performance.
Rethinking Neural Combinatorial Optimization for Vehicle Routing Problems with Different Constraint Tightness Degrees
May 30, 2025



Recent neural combinatorial optimization (NCO) methods have shown promising problem-solving ability without requiring domain-specific expertise. Most existing NCO methods use training and testing data with a fixed constraint value and lack research on the effect of constraint tightness on the performance of NCO methods. This paper takes the capacity-constrained vehicle routing problem (CVRP) as an example to empirically analyze the NCO performance under different tightness degrees of the capacity constraint. Our analysis reveals that existing NCO methods overfit the capacity constraint, and they can only perform satisfactorily on a small range of the constraint values but poorly on other values. To tackle this drawback of existing NCO methods, we develop an efficient training scheme that explicitly considers varying degrees of constraint tightness and proposes a multi-expert module to learn a generally adaptable solving strategy. Experimental results show that the proposed method can effectively overcome the overfitting issue, demonstrating superior performances on the CVRP and CVRP with time windows (CVRPTW) with various constraint tightness degrees.
Learning to Insert for Constructive Neural Vehicle Routing Solver
May 20, 2025



Neural Combinatorial Optimisation (NCO) is a promising learning-based approach for solving Vehicle Routing Problems (VRPs) without extensive manual design. While existing constructive NCO methods typically follow an appending-based paradigm that sequentially adds unvisited nodes to partial solutions, this rigid approach often leads to suboptimal results. To overcome this limitation, we explore the idea of insertion-based paradigm and propose Learning to Construct with Insertion-based Paradigm (L2C-Insert), a novel learning-based method for constructive NCO. Unlike traditional approaches, L2C-Insert builds solutions by strategically inserting unvisited nodes at any valid position in the current partial solution, which can significantly enhance the flexibility and solution quality. The proposed framework introduces three key components: a novel model architecture for precise insertion position prediction, an efficient training scheme for model optimization, and an advanced inference technique that fully exploits the insertion paradigm's flexibility. Extensive experiments on both synthetic and real-world instances of the Travelling Salesman Problem (TSP) and Capacitated Vehicle Routing Problem (CVRP) demonstrate that L2C-Insert consistently achieves superior performance across various problem sizes.
Self-Improved Learning for Scalable Neural Combinatorial Optimization
Mar 30, 2024The end-to-end neural combinatorial optimization (NCO) method shows promising performance in solving complex combinatorial optimization problems without the need for expert design. However, existing methods struggle with large-scale problems, hindering their practical applicability. To overcome this limitation, this work proposes a novel Self-Improved Learning (SIL) method for better scalability of neural combinatorial optimization. Specifically, we develop an efficient self-improved mechanism that enables direct model training on large-scale problem instances without any labeled data. Powered by an innovative local reconstruction approach, this method can iteratively generate better solutions by itself as pseudo-labels to guide efficient model training. In addition, we design a linear complexity attention mechanism for the model to efficiently handle large-scale combinatorial problem instances with low computation overhead. Comprehensive experiments on the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 100K nodes in both uniform and real-world distributions demonstrate the superior scalability of our method.
An Example of Evolutionary Computation + Large Language Model Beating Human: Design of Efficient Guided Local Search
Jan 04, 2024It is often very tedious for human experts to design efficient algorithms. Recently, we have proposed a novel Algorithm Evolution using Large Language Model (AEL) framework for automatic algorithm design. AEL combines the power of a large language model and the paradigm of evolutionary computation to design, combine, and modify algorithms automatically. In this paper, we use AEL to design the guide algorithm for guided local search (GLS) to solve the well-known traveling salesman problem (TSP). AEL automatically evolves elite GLS algorithms in two days, with minimal human effort and no model training. Experimental results on 1,000 TSP20-TSP100 instances and TSPLib instances show that AEL-designed GLS outperforms state-of-the-art human-designed GLS with the same iteration budget. It achieves a 0% gap on TSP20 and TSP50 and a 0.032% gap on TSP100 in 1,000 iterations. Our findings mark the emergence of a new era in automatic algorithm design.
Neural Combinatorial Optimization with Heavy Decoder: Toward Large Scale Generalization
Oct 12, 2023Neural combinatorial optimization (NCO) is a promising learning-based approach for solving challenging combinatorial optimization problems without specialized algorithm design by experts. However, most constructive NCO methods cannot solve problems with large-scale instance sizes, which significantly diminishes their usefulness for real-world applications. In this work, we propose a novel Light Encoder and Heavy Decoder (LEHD) model with a strong generalization ability to address this critical issue. The LEHD model can learn to dynamically capture the relationships between all available nodes of varying sizes, which is beneficial for model generalization to problems of various scales. Moreover, we develop a data-efficient training scheme and a flexible solution construction mechanism for the proposed LEHD model. By training on small-scale problem instances, the LEHD model can generate nearly optimal solutions for the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 1000 nodes, and also generalizes well to solve real-world TSPLib and CVRPLib problems. These results confirm our proposed LEHD model can significantly improve the state-of-the-art performance for constructive NCO. The code is available at https://github.com/CIAM-Group/NCO_code/tree/main/single_objective/LEHD.
Dynamic Multi-objective Ensemble of Acquisition Functions in Batch Bayesian Optimization
Jun 22, 2022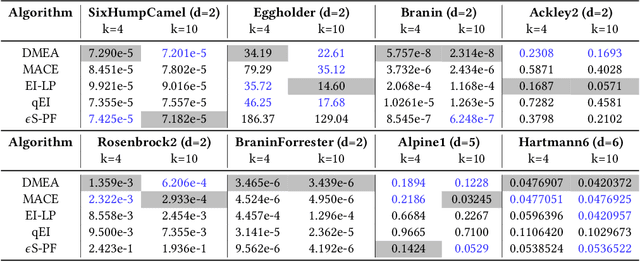
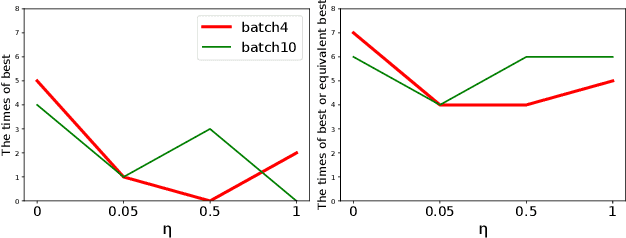
Bayesian optimization (BO) is a typical approach to solve expensive optimization problems. In each iteration of BO, a Gaussian process(GP) model is trained using the previously evaluated solutions; then next candidate solutions for expensive evaluation are recommended by maximizing a cheaply-evaluated acquisition function on the trained surrogate model. The acquisition function plays a crucial role in the optimization process. However, each acquisition function has its own strengths and weaknesses, and no single acquisition function can consistently outperform the others on all kinds of problems. To better leverage the advantages of different acquisition functions, we propose a new method for batch BO. In each iteration, three acquisition functions are dynamically selected from a set based on their current and historical performance to form a multi-objective optimization problem (MOP). Using an evolutionary multi-objective algorithm to optimize such a MOP, a set of non-dominated solutions can be obtained. To select batch candidate solutions, we rank these non-dominated solutions into several layers according to their relative performance on the three acquisition functions. The empirical results show that the proposed method is competitive with the state-of-the-art methods on different problems.