 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingxuan Wang
DUB: Discrete Unit Back-translation for Speech Translation
May 19, 2023
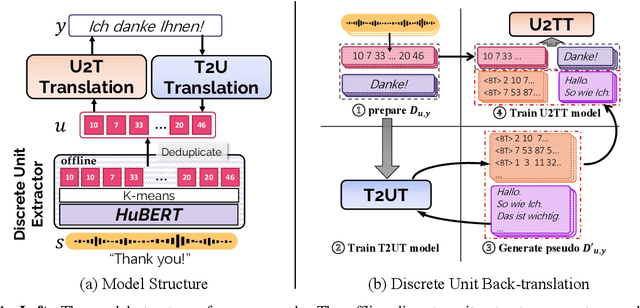

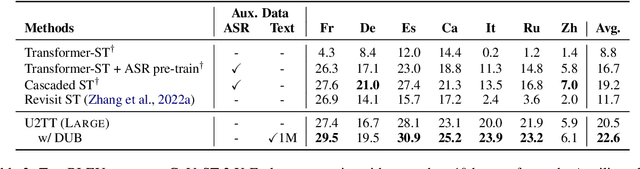
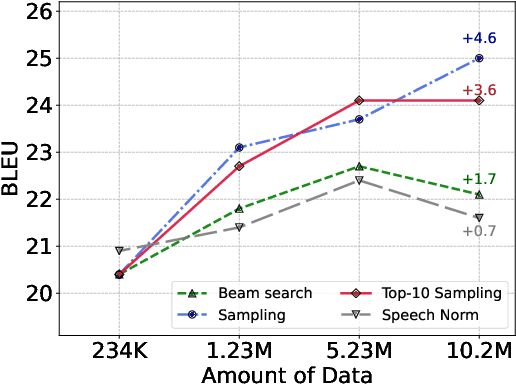
How can speech-to-text translation (ST) perform as well as machine translation (MT)? The key point is to bridge the modality gap between speech and text so that useful MT techniques can be applied to ST. Recently, the approach of representing speech with unsupervised discrete units yields a new way to ease the modality problem. This motivates us to propose Discrete Unit Back-translation (DUB) to answer two questions: (1) Is it better to represent speech with discrete units than with continuous features in direct ST? (2) How much benefit can useful MT techniques bring to ST? With DUB, the back-translation technique can successfully be applied on direct ST and obtains an average boost of 5.5 BLEU on MuST-C En-De/Fr/Es. In the low-resource language scenario, our method achieves comparable performance to existing methods that rely on large-scale external data. Code and models are available at https://github.com/0nutation/DUB.
DINOISER: Diffused Conditional Sequence Learning by Manipulating Noises
Feb 20, 2023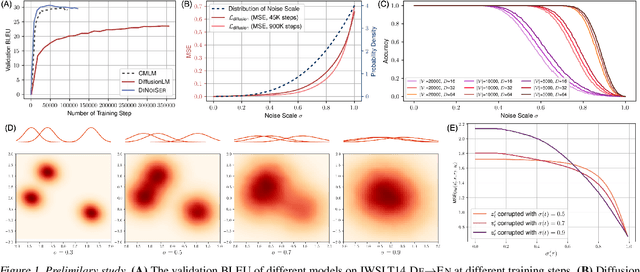
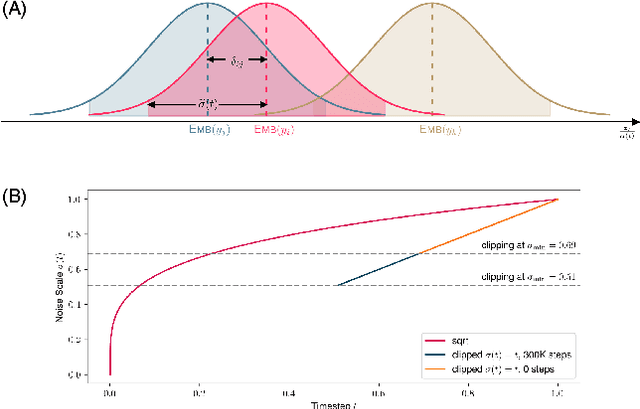
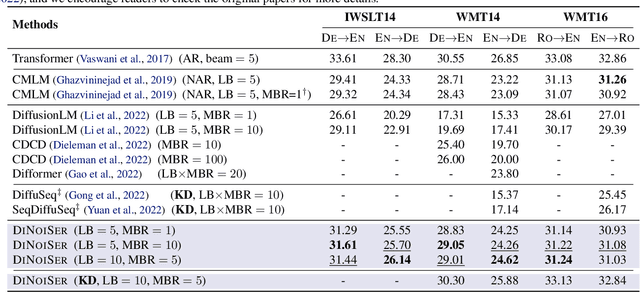
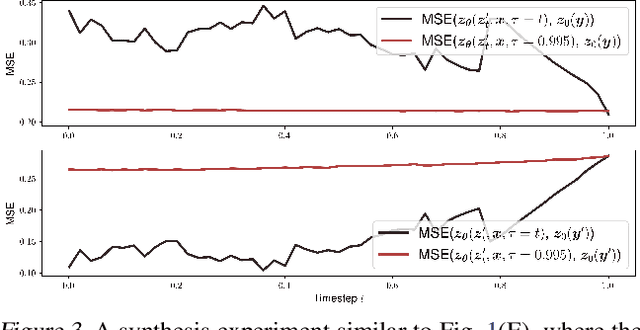
While diffusion models have achieved great success in generating continuous signals such as images and audio, it remains elusive for diffusion models in learning discrete sequence data like natural languages. Although recent advances circumvent this challenge of discreteness by embedding discrete tokens as continuous surrogates, they still fall short of satisfactory generation quality. To understand this, we first dive deep into the denoised training protocol of diffusion-based sequence generative models and determine their three severe problems, i.e., 1) failing to learn, 2) lack of scalability, and 3) neglecting source conditions. We argue that these problems can be boiled down to the pitfall of the not completely eliminated discreteness in the embedding space, and the scale of noises is decisive herein. In this paper, we introduce DINOISER to facilitate diffusion models for sequence generation by manipulating noises. We propose to adaptively determine the range of sampled noise scales for counter-discreteness training; and encourage the proposed diffused sequence learner to leverage source conditions with amplified noise scales during inference. Experiments show that DINOISER enables consistent improvement over the baselines of previous diffusion-based sequence generative models on several conditional sequence modeling benchmarks thanks to both effective training and inference strategies. Analyses further verify that DINOISER can make better use of source conditions to govern its generative process.
Beyond Triplet: Leveraging the Most Data for Multimodal Machine Translation
Dec 20, 2022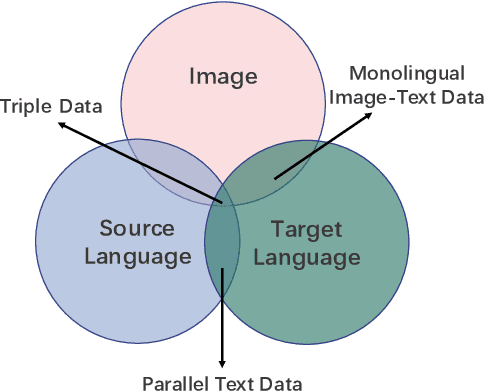
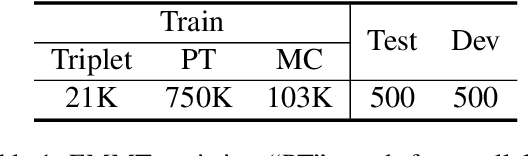
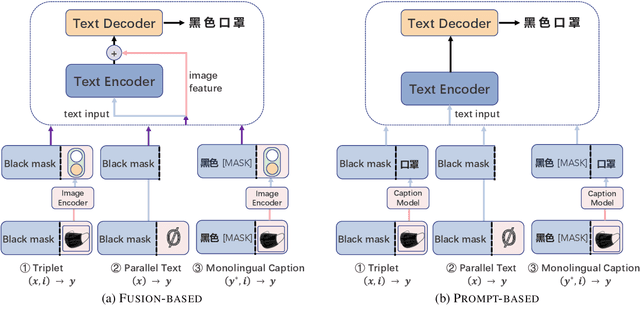
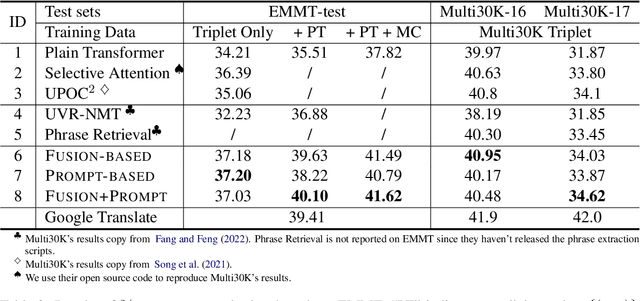
Multimodal machine translation (MMT) aims to improve translation quality by incorporating information from other modalities, such as vision. Previous MMT systems mainly focus on better access and use of visual information and tend to validate their methods on image-related datasets. These studies face two challenges. First, they can only utilize triple data (bilingual texts with images), which is scarce; second, current benchmarks are relatively restricted and do not correspond to realistic scenarios. Therefore, this paper correspondingly establishes new methods and new datasets for MMT. First, we propose a framework 2/3-Triplet with two new approaches to enhance MMT by utilizing large-scale non-triple data: monolingual image-text data and parallel text-only data. Second, we construct an English-Chinese {e}-commercial {m}ulti{m}odal {t}ranslation dataset (including training and testing), named EMMT, where its test set is carefully selected as some words are ambiguous and shall be translated mistakenly without the help of images. Experiments show that our method is more suitable for real-world scenarios and can significantly improve translation performance by using more non-triple data. In addition, our model also rivals various SOTA models in conventional multimodal translation benchmarks.
Diff-Glat: Diffusion Glancing Transformer for Parallel Sequence to Sequence Learning
Dec 20, 2022


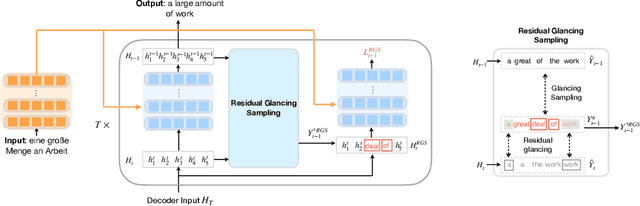
For sequence generation, both autoregressive models and non-autoregressive models have been developed in recent years. Autoregressive models can achieve high generation quality, but the sequential decoding scheme causes slow decoding speed. Non-autoregressive models accelerate the inference speed with parallel decoding, while their generation quality still needs to be improved due to the difficulty of modeling multi-modalities in data. To address the multi-modality issue, we propose Diff-Glat, a non-autoregressive model featured with a modality diffusion process and residual glancing training. The modality diffusion process decomposes the modalities and reduces the modalities to learn for each transition. And the residual glancing sampling further smooths the modality learning procedures. Experiments demonstrate that, without using knowledge distillation data, Diff-Glat can achieve superior performance in both decoding efficiency and accuracy compared with the autoregressive Transformer.
SEScore2: Retrieval Augmented Pretraining for Text Generation Evaluation
Dec 19, 2022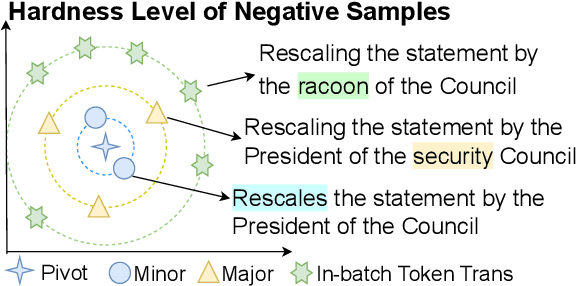
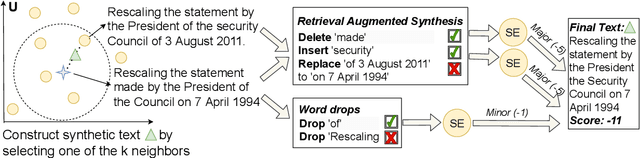
Is it possible to leverage large scale raw and raw parallel corpora to build a general learned metric? Existing learned metrics have gaps to human judgements, are model-dependent or are limited to the domains or tasks where human ratings are available. In this paper, we propose SEScore2, a model-based metric pretrained over million-scale synthetic dataset constructed by our novel retrieval augmented data synthesis pipeline. SEScore2 achieves high correlation to human judgements without any human rating supervisions. Importantly, our unsupervised SEScore2 can outperform supervised metrics, which are trained on the News human ratings, at the TED domain. We evaluate SEScore2 over four text generation tasks across three languages. SEScore2 outperforms all prior unsupervised evaluation metrics in machine translation, speech translation, data-to-text and dialogue generation, with average Kendall improvements 0.158. SEScore2 even outperforms SOTA supervised BLEURT at data-to-text, dialogue generation and overall correlation.
Controlling Styles in Neural Machine Translation with Activation Prompt
Dec 17, 2022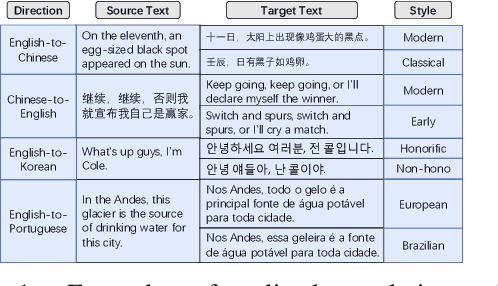

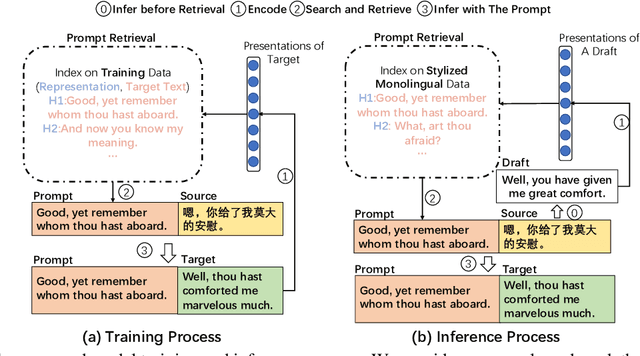

Neural machine translation(NMT) has aroused wide attention due to its impressive quality. Beyond quality, controlling translation styles is also an important demand for many languages. Previous related studies mainly focus on controlling formality and gain some improvements. However, they still face two challenges. The first is the evaluation limitation. Style contains abundant information including lexis, syntax, etc. But only formality is well studied. The second is the heavy reliance on iterative fine-tuning when new styles are required. Correspondingly, this paper contributes in terms of the benchmark and approach. First, we re-visit this task and propose a multiway stylized machine translation (MSMT) benchmark, which includes multiple categories of styles in four language directions to push the boundary of this task. Second, we propose a method named style activation prompt (StyleAP) by retrieving prompts from stylized monolingual corpus, which needs no extra fine-tuning. Experiments show that StyleAP could effectively control the style of translation and achieve remarkable performance. All of our data and code are released at https://github.com/IvanWang0730/StyleAP.
Better Datastore, Better Translation: Generating Datastores from Pre-Trained Models for Nearest Neural Machine Translation
Dec 17, 2022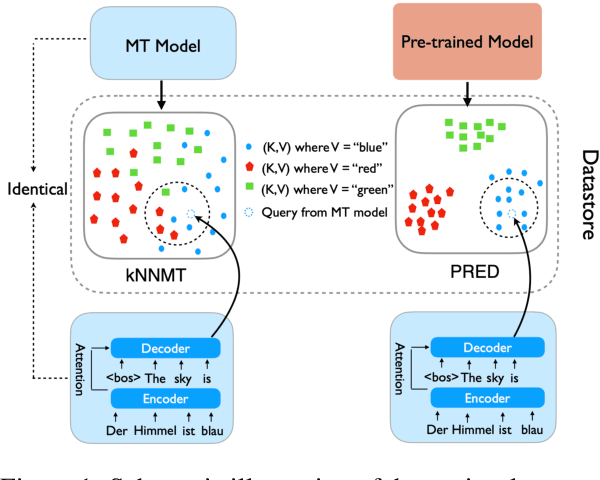
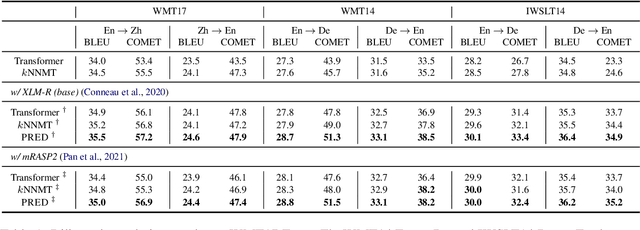
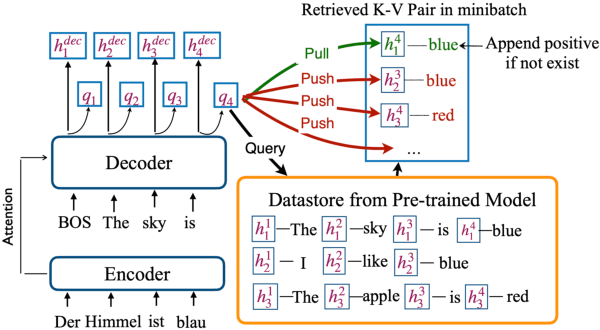
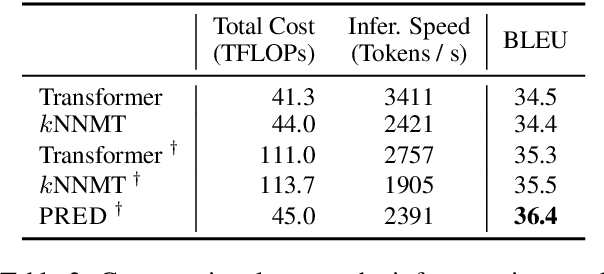
Nearest Neighbor Machine Translation (kNNMT) is a simple and effective method of augmenting neural machine translation (NMT) with a token-level nearest neighbor retrieval mechanism. The effectiveness of kNNMT directly depends on the quality of retrieved neighbors. However, original kNNMT builds datastores based on representations from NMT models, which would result in poor retrieval accuracy when NMT models are not good enough, leading to sub-optimal translation performance. In this paper, we propose PRED, a framework that leverages Pre-trained models for Datastores in kNN-MT. Better representations from pre-trained models allow us to build datastores of better quality. We also design a novel contrastive alignment objective to mitigate the representation gap between the NMT model and pre-trained models, enabling the NMT model to retrieve from better datastores. We conduct extensive experiments on both bilingual and multilingual translation benchmarks, including WMT17 English $\leftrightarrow$ Chinese, WMT14 English $\leftrightarrow$ German, IWSLT14 German $\leftrightarrow$ English, and IWSLT14 multilingual datasets. Empirical results demonstrate the effectiveness of PRED.
M3ST: Mix at Three Levels for Speech Translation
Dec 07, 2022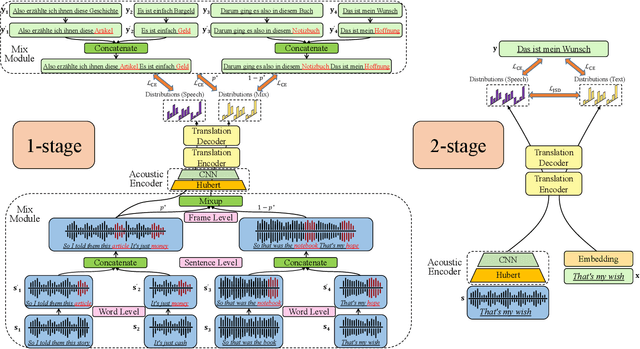
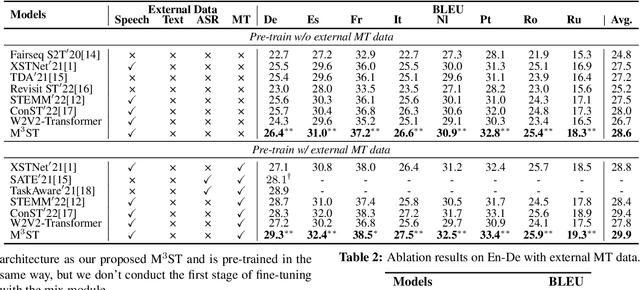

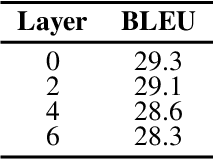
How to solve the data scarcity problem for end-to-end speech-to-text translation (ST)? It's well known that data augmentation is an efficient method to improve performance for many tasks by enlarging the dataset. In this paper, we propose Mix at three levels for Speech Translation (M^3ST) method to increase the diversity of the augmented training corpus. Specifically, we conduct two phases of fine-tuning based on a pre-trained model using external machine translation (MT) data. In the first stage of fine-tuning, we mix the training corpus at three levels, including word level, sentence level and frame level, and fine-tune the entire model with mixed data. At the second stage of fine-tuning, we take both original speech sequences and original text sequences in parallel into the model to fine-tune the network, and use Jensen-Shannon divergence to regularize their outputs. Experiments on MuST-C speech translation benchmark and analysis show that M^3ST outperforms current strong baselines and achieves state-of-the-art results on eight directions with an average BLEU of 29.9.
Leveraging per Image-Token Consistency for Vision-Language Pre-training
Nov 20, 2022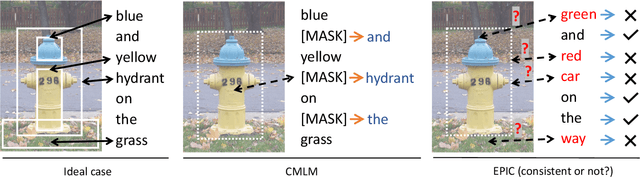
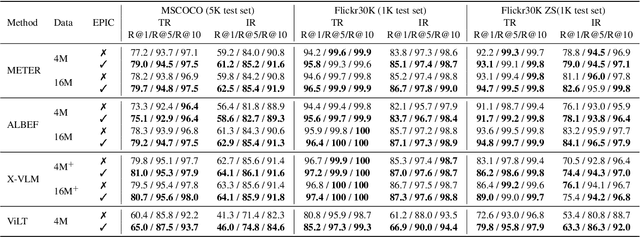
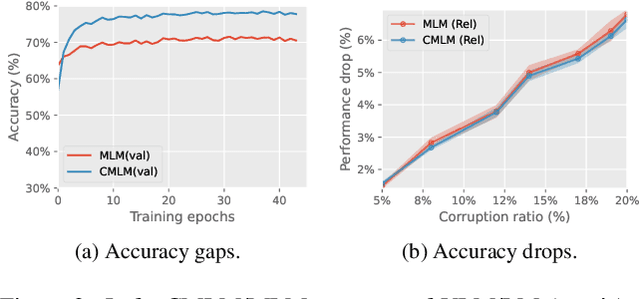
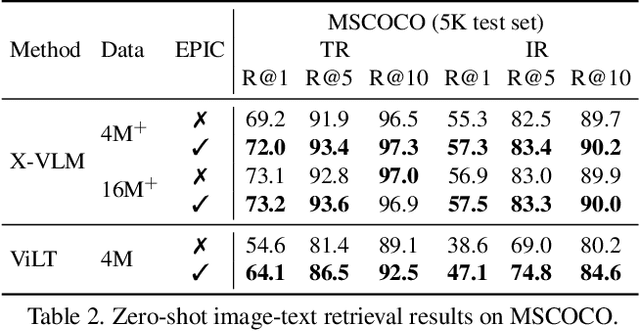
Most existing vision-language pre-training (VLP) approaches adopt cross-modal masked language modeling (CMLM) to learn vision-language associations. However, we find that CMLM is insufficient for this purpose according to our observations: (1) Modality bias: a considerable amount of masked tokens in CMLM can be recovered with only the language information, ignoring the visual inputs. (2) Under-utilization of the unmasked tokens: CMLM primarily focuses on the masked token but it cannot simultaneously leverage other tokens to learn vision-language associations. To handle those limitations, we propose EPIC (lEveraging Per Image-Token Consistency for vision-language pre-training). In EPIC, for each image-sentence pair, we mask tokens that are salient to the image (i.e., Saliency-based Masking Strategy) and replace them with alternatives sampled from a language model (i.e., Inconsistent Token Generation Procedure), and then the model is required to determine for each token in the sentence whether they are consistent with the image (i.e., Image-Text Consistent Task). The proposed EPIC method is easily combined with pre-training methods. Extensive experiments show that the combination of the EPIC method and state-of-the-art pre-training approaches, including ViLT, ALBEF, METER, and X-VLM, leads to significant improvements on downstream tasks.
CoBERT: Self-Supervised Speech Representation Learning Through Code Representation Learning
Oct 08, 2022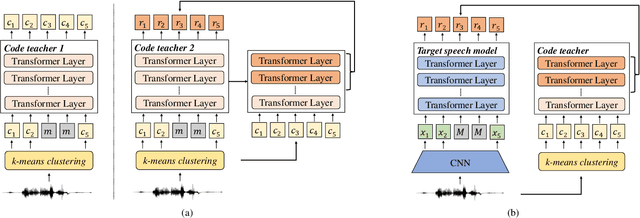
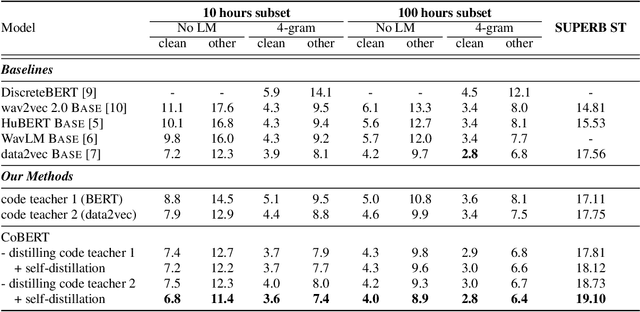
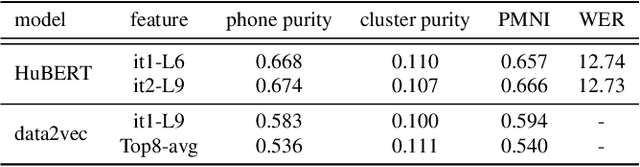
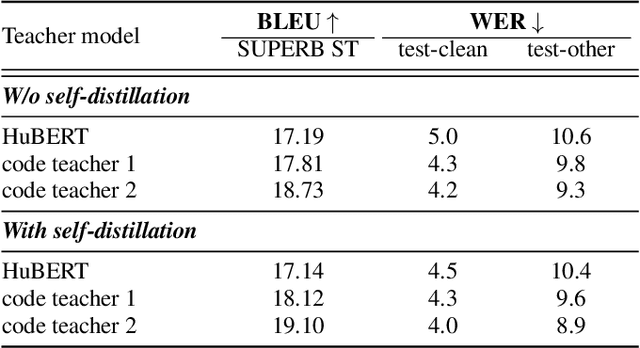
Speech is the surface form of a finite set of phonetic units, which can be represented by discrete codes. We propose the Code BERT (CoBERT) approach for self-supervised speech representation learning. The idea is to convert an utterance to a sequence of discrete codes, and perform code representation learning, where we predict the code representations based on a masked view of the original speech input. Unlike the prior self-distillation approaches of which the teacher and the student are of the same modality, our target model predicts representations from a different modality. CoBERT outperforms the most recent state-of-the-art performance on the ASR task and brings significant improvements on the SUPERB speech translation (ST) task.