 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
Jun 17, 2025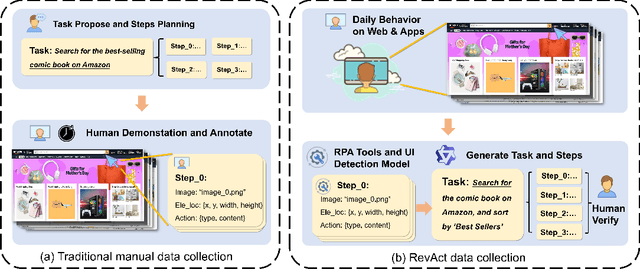
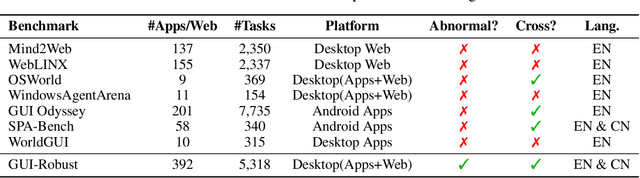

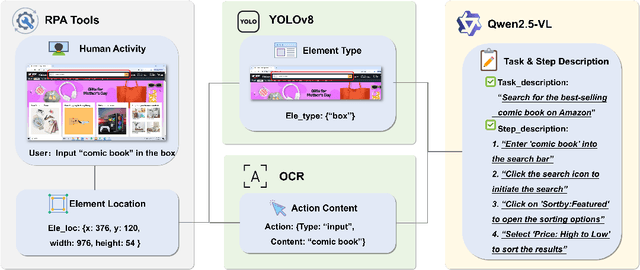
The development of high-quality datasets is crucial for benchmarking and advancing research in Graphical User Interface (GUI) agents. Despite their importance, existing datasets are often constructed under idealized conditions, overlooking the diverse anomalies frequently encountered in real-world deployments. To address this limitation, we introduce GUI-Robust, a novel dataset designed for comprehensive GUI agent evaluation, explicitly incorporating seven common types of anomalies observed in everyday GUI interactions. Furthermore, we propose a semi-automated dataset construction paradigm that collects user action sequences from natural interactions via RPA tools and then generate corresponding step and task descriptions for these actions with the assistance of MLLMs. This paradigm significantly reduces annotation time cost by a factor of over 19 times. Finally, we assess state-of-the-art GUI agents using the GUI-Robust dataset, revealing their substantial performance degradation in abnormal scenarios. We anticipate that our work will highlight the importance of robustness in GUI agents and inspires more future research in this direction. The dataset and code are available at https://github.com/chessbean1/GUI-Robust..
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
Adaptive Location Hierarchy Learning for Long-Tailed Mobility Prediction
May 26, 2025Human mobility prediction is crucial for applications ranging from location-based recommendations to urban planning, which aims to forecast users' next location visits based on historical trajectories. Despite the severe long-tailed distribution of locations, the problem of long-tailed mobility prediction remains largely underexplored. Existing long-tailed learning methods primarily focus on rebalancing the skewed distribution at the data, model, or class level, neglecting to exploit the spatiotemporal semantics of locations. To address this gap, we propose the first plug-and-play framework for long-tailed mobility prediction in an exploitation and exploration manner, named \textbf{A}daptive \textbf{LO}cation \textbf{H}ier\textbf{A}rchy learning (ALOHA). First, we construct city-tailored location hierarchy based on Large Language Models (LLMs) by exploiting Maslow's theory of human motivation to design Chain-of-Thought (CoT) prompts that captures spatiotemporal semantics. Second, we optimize the location hierarchy predictions by Gumbel disturbance and node-wise adaptive weights within the hierarchical tree structure. Experiments on state-of-the-art models across six datasets demonstrate the framework's consistent effectiveness and generalizability, which strikes a well balance between head and tail locations. Weight analysis and ablation studies reveal the optimization differences of each component for head and tail locations. Furthermore, in-depth analyses of hierarchical distance and case study demonstrate the effective semantic guidance from the location hierarchy. Our code will be made publicly available.
SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data
May 25, 2025



Recent advances have demonstrated the effectiveness of Reinforcement Learning (RL) in improving the reasoning capabilities of Large Language Models (LLMs). However, existing works inevitably rely on high-quality instructions and verifiable rewards for effective training, both of which are often difficult to obtain in specialized domains. In this paper, we propose Self-play Reinforcement Learning(SeRL) to bootstrap LLM training with limited initial data. Specifically, SeRL comprises two complementary modules: self-instruction and self-rewarding. The former module generates additional instructions based on the available data at each training step, employing robust online filtering strategies to ensure instruction quality, diversity, and difficulty. The latter module introduces a simple yet effective majority-voting mechanism to estimate response rewards for additional instructions, eliminating the need for external annotations. Finally, SeRL performs conventional RL based on the generated data, facilitating iterative self-play learning. Extensive experiments on various reasoning benchmarks and across different LLM backbones demonstrate that the proposed SeRL yields results superior to its counterparts and achieves performance on par with those obtained by high-quality data with verifiable rewards. Our code is available at https://github.com/wantbook-book/SeRL.
Bi-level Mean Field: Dynamic Grouping for Large-Scale MARL
May 10, 2025Large-scale Multi-Agent Reinforcement Learning (MARL) often suffers from the curse of dimensionality, as the exponential growth in agent interactions significantly increases computational complexity and impedes learning efficiency. To mitigate this, existing efforts that rely on Mean Field (MF) simplify the interaction landscape by approximating neighboring agents as a single mean agent, thus reducing overall complexity to pairwise interactions. However, these MF methods inevitably fail to account for individual differences, leading to aggregation noise caused by inaccurate iterative updates during MF learning. In this paper, we propose a Bi-level Mean Field (BMF) method to capture agent diversity with dynamic grouping in large-scale MARL, which can alleviate aggregation noise via bi-level interaction. Specifically, BMF introduces a dynamic group assignment module, which employs a Variational AutoEncoder (VAE) to learn the representations of agents, facilitating their dynamic grouping over time. Furthermore, we propose a bi-level interaction module to model both inter- and intra-group interactions for effective neighboring aggregation. Experiments across various tasks demonstrate that the proposed BMF yields results superior to the state-of-the-art methods. Our code will be made publicly available.
Diffusion Model Quantization: A Review
May 08, 2025Recent success of large text-to-image models has empirically underscored the exceptional performance of diffusion models in generative tasks. To facilitate their efficient deployment on resource-constrained edge devices, model quantization has emerged as a pivotal technique for both compression and acceleration. This survey offers a thorough review of the latest advancements in diffusion model quantization, encapsulating and analyzing the current state of the art in this rapidly advancing domain. First, we provide an overview of the key challenges encountered in the quantization of diffusion models, including those based on U-Net architectures and Diffusion Transformers (DiT). We then present a comprehensive taxonomy of prevalent quantization techniques, engaging in an in-depth discussion of their underlying principles. Subsequently, we perform a meticulous analysis of representative diffusion model quantization schemes from both qualitative and quantitative perspectives. From a quantitative standpoint, we rigorously benchmark a variety of methods using widely recognized datasets, delivering an extensive evaluation of the most recent and impactful research in the field. From a qualitative standpoint, we categorize and synthesize the effects of quantization errors, elucidating these impacts through both visual analysis and trajectory examination. In conclusion, we outline prospective avenues for future research, proposing novel directions for the quantization of generative models in practical applications. The list of related papers, corresponding codes, pre-trained models and comparison results are publicly available at the survey project homepage https://github.com/TaylorJocelyn/Diffusion-Model-Quantization.
Quantizing Diffusion Models from a Sampling-Aware Perspective
May 04, 2025Diffusion models have recently emerged as the dominant approach in visual generation tasks. However, the lengthy denoising chains and the computationally intensive noise estimation networks hinder their applicability in low-latency and resource-limited environments. Previous research has endeavored to address these limitations in a decoupled manner, utilizing either advanced samplers or efficient model quantization techniques. In this study, we uncover that quantization-induced noise disrupts directional estimation at each sampling step, further distorting the precise directional estimations of higher-order samplers when solving the sampling equations through discretized numerical methods, thereby altering the optimal sampling trajectory. To attain dual acceleration with high fidelity, we propose a sampling-aware quantization strategy, wherein a Mixed-Order Trajectory Alignment technique is devised to impose a more stringent constraint on the error bounds at each sampling step, facilitating a more linear probability flow. Extensive experiments on sparse-step fast sampling across multiple datasets demonstrate that our approach preserves the rapid convergence characteristics of high-speed samplers while maintaining superior generation quality. Code will be made publicly available soon.
From GNNs to Trees: Multi-Granular Interpretability for Graph Neural Networks
May 01, 2025Interpretable Graph Neural Networks (GNNs) aim to reveal the underlying reasoning behind model predictions, attributing their decisions to specific subgraphs that are informative. However, existing subgraph-based interpretable methods suffer from an overemphasis on local structure, potentially overlooking long-range dependencies within the entire graphs. Although recent efforts that rely on graph coarsening have proven beneficial for global interpretability, they inevitably reduce the graphs to a fixed granularity. Such an inflexible way can only capture graph connectivity at a specific level, whereas real-world graph tasks often exhibit relationships at varying granularities (e.g., relevant interactions in proteins span from functional groups, to amino acids, and up to protein domains). In this paper, we introduce a novel Tree-like Interpretable Framework (TIF) for graph classification, where plain GNNs are transformed into hierarchical trees, with each level featuring coarsened graphs of different granularity as tree nodes. Specifically, TIF iteratively adopts a graph coarsening module to compress original graphs (i.e., root nodes of trees) into increasingly coarser ones (i.e., child nodes of trees), while preserving diversity among tree nodes within different branches through a dedicated graph perturbation module. Finally, we propose an adaptive routing module to identify the most informative root-to-leaf paths, providing not only the final prediction but also the multi-granular interpretability for the decision-making process. Extensive experiments on the graph classification benchmarks with both synthetic and real-world datasets demonstrate the superiority of TIF in interpretability, while also delivering a competitive prediction performance akin to the state-of-the-art counterparts.
Sample-level Adaptive Knowledge Distillation for Action Recognition
Apr 01, 2025Knowledge Distillation (KD) compresses neural networks by learning a small network (student) via transferring knowledge from a pre-trained large network (teacher). Many endeavours have been devoted to the image domain, while few works focus on video analysis which desires training much larger model making it be hardly deployed in resource-limited devices. However, traditional methods neglect two important problems, i.e., 1) Since the capacity gap between the teacher and the student exists, some knowledge w.r.t. difficult-to-transfer samples cannot be correctly transferred, or even badly affects the final performance of student, and 2) As training progresses, difficult-to-transfer samples may become easier to learn, and vice versa. To alleviate the two problems, we propose a Sample-level Adaptive Knowledge Distillation (SAKD) framework for action recognition. In particular, it mainly consists of the sample distillation difficulty evaluation module and the sample adaptive distillation module. The former applies the temporal interruption to frames, i.e., randomly dropout or shuffle the frames during training, which increases the learning difficulty of samples during distillation, so as to better discriminate their distillation difficulty. The latter module adaptively adjusts distillation ratio at sample level, such that KD loss dominates the training with easy-to-transfer samples while vanilla loss dominates that with difficult-to-transfer samples. More importantly, we only select those samples with both low distillation difficulty and high diversity to train the student model for reducing computational cost. Experimental results on two video benchmarks and one image benchmark demonstrate the superiority of the proposed method by striking a good balance between performance and efficiency.
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Mar 31, 2025MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM's GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.