 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Text Generation
Mar 17, 2023



Users interact with text, image, code, or other editors on a daily basis. However, machine learning models are rarely trained in the settings that reflect the interactivity between users and their editor. This is understandable as training AI models with real users is not only slow and costly, but what these models learn may be specific to user interface design choices. Unfortunately, this means most of the research on text, code, and image generation has focused on non-interactive settings, whereby the model is expected to get everything right without accounting for any input from a user who may be willing to help. We introduce a new Interactive Text Generation task that allows training generation models interactively without the costs of involving real users, by using user simulators that provide edits that guide the model towards a given target text. We train our interactive models using Imitation Learning, and our experiments against competitive non-interactive generation models show that models trained interactively are superior to their non-interactive counterparts, even when all models are given the same budget of user inputs or edits.
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
Mar 08, 2023



Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
Guiding Large Language Models via Directional Stimulus Prompting
Feb 22, 2023We introduce a new framework, Directional Stimulus Prompting, that uses a tuneable language model (LM) to provide guidance for the black-box frozen large language model (LLM) on downstream tasks. Unlike prior work that manually or automatically finds the optimal prompt for each task, we train a policy LM to generate discrete tokens as ``directional stimulus'' of each input, which is a hint/cue such as keywords of an article for summarization. The directional stimulus is then combined with the original input and fed into the LLM to guide its generation toward the desired target. The policy LM can be trained through 1) supervised learning from annotated data and 2) reinforcement learning from offline and online rewards to explore directional stimulus that better aligns LLMs with human preferences. This framework is flexibly applicable to various LMs and tasks. To verify its effectiveness, we apply our framework to summarization and dialogue response generation tasks. Experimental results demonstrate that it can significantly improve LLMs' performance with a small collection of training data: a T5 (780M) trained with 2,000 samples from the CNN/Daily Mail dataset improves Codex (175B)'s performance by 7.2% in ROUGE-Avg scores; 500 dialogues boost the combined score by 52.5%, achieving comparable or even better performance than fully trained models on the MultiWOZ dataset.
Enhancing Task Bot Engagement with Synthesized Open-Domain Dialog
Dec 20, 2022



Many efforts have been made to construct dialog systems for different types of conversations, such as task-oriented dialog (TOD) and open-domain dialog (ODD). To better mimic human-level conversations that usually fuse various dialog modes, it is essential to build a system that can effectively handle both TOD and ODD and access different knowledge sources. To address the lack of available data for the fused task, we propose a framework for automatically generating dialogues that combine knowledge-grounded ODDs and TODs in various settings. Additionally, we introduce a unified model PivotBot that is capable of appropriately adopting TOD and ODD modes and accessing different knowledge sources in order to effectively tackle the fused task. Evaluation results demonstrate the superior ability of the proposed model to switch seamlessly between TOD and ODD tasks.
DIONYSUS: A Pre-trained Model for Low-Resource Dialogue Summarization
Dec 20, 2022



Dialogue summarization has recently garnered significant attention due to its wide range of applications. However, existing methods for summarizing dialogues are suboptimal because they do not take into account the inherent structure of dialogue and rely heavily on labeled data, which can lead to poor performance in new domains. In this work, we propose DIONYSUS (dynamic input optimization in pre-training for dialogue summarization), a pre-trained encoder-decoder model for summarizing dialogues in any new domain. To pre-train DIONYSUS, we create two pseudo summaries for each dialogue example: one is produced by a fine-tuned summarization model, and the other is a collection of dialogue turns that convey important information. We then choose one of these pseudo summaries based on the difference in information distribution across different types of dialogues. This selected pseudo summary serves as the objective for pre-training DIONYSUS using a self-supervised approach on a large dialogue corpus. Our experiments show that DIONYSUS outperforms existing methods on six datasets, as demonstrated by its ROUGE scores in zero-shot and few-shot settings.
Grounded Keys-to-Text Generation: Towards Factual Open-Ended Generation
Dec 04, 2022



Large pre-trained language models have recently enabled open-ended generation frameworks (e.g., prompt-to-text NLG) to tackle a variety of tasks going beyond the traditional data-to-text generation. While this framework is more general, it is under-specified and often leads to a lack of controllability restricting their real-world usage. We propose a new grounded keys-to-text generation task: the task is to generate a factual description about an entity given a set of guiding keys, and grounding passages. To address this task, we introduce a new dataset, called EntDeGen. Inspired by recent QA-based evaluation measures, we propose an automatic metric, MAFE, for factual correctness of generated descriptions. Our EntDescriptor model is equipped with strong rankers to fetch helpful passages and generate entity descriptions. Experimental result shows a good correlation (60.14) between our proposed metric and human judgments of factuality. Our rankers significantly improved the factual correctness of generated descriptions (15.95% and 34.51% relative gains in recall and precision). Finally, our ablation study highlights the benefit of combining keys and groundings.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022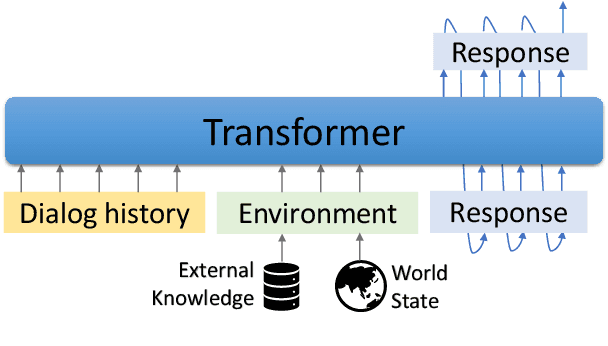
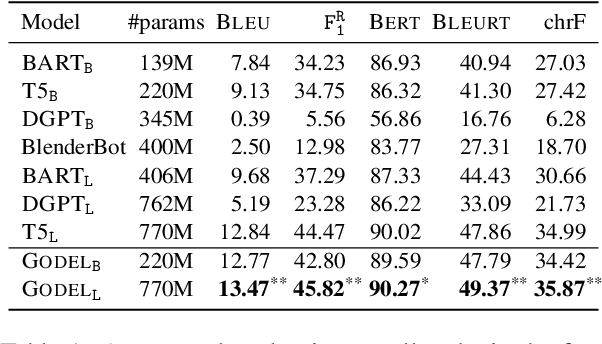

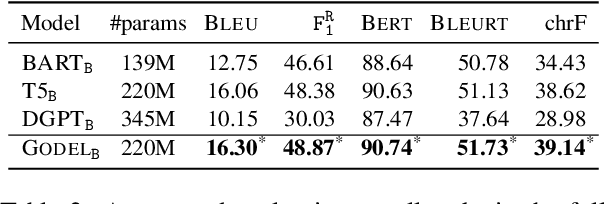
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Probing Factually Grounded Content Transfer with Factual Ablation
Mar 29, 2022
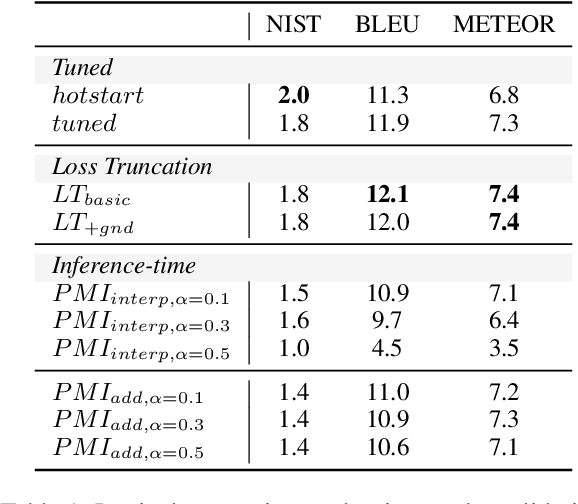
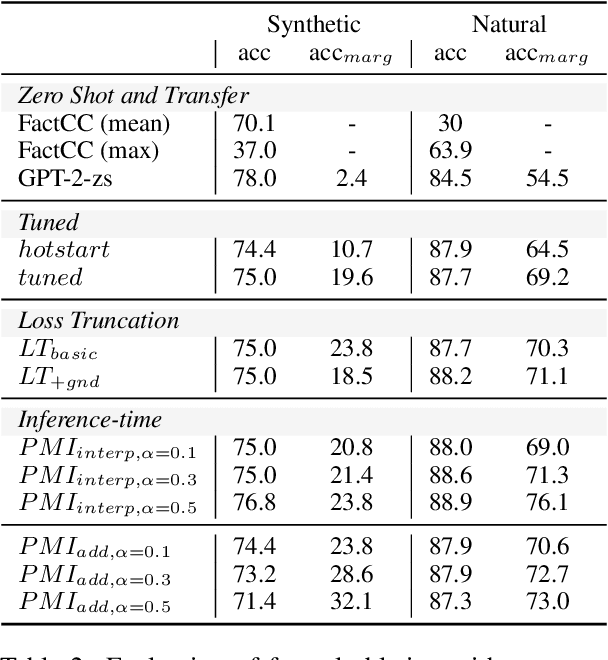

Despite recent success, large neural models often generate factually incorrect text. Compounding this is the lack of a standard automatic evaluation for factuality--it cannot be meaningfully improved if it cannot be measured. Grounded generation promises a path to solving both of these problems: models draw on a reliable external document (grounding) for factual information, simplifying the challenge of factuality. Measuring factuality is also simplified--to factual consistency, testing whether the generation agrees with the grounding, rather than all facts. Yet, without a standard automatic metric for factual consistency, factually grounded generation remains an open problem. We study this problem for content transfer, in which generations extend a prompt, using information from factual grounding. Particularly, this domain allows us to introduce the notion of factual ablation for automatically measuring factual consistency: this captures the intuition that the model should be less likely to produce an output given a less relevant grounding document. In practice, we measure this by presenting a model with two grounding documents, and the model should prefer to use the more factually relevant one. We contribute two evaluation sets to measure this. Applying our new evaluation, we propose multiple novel methods improving over strong baselines.
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021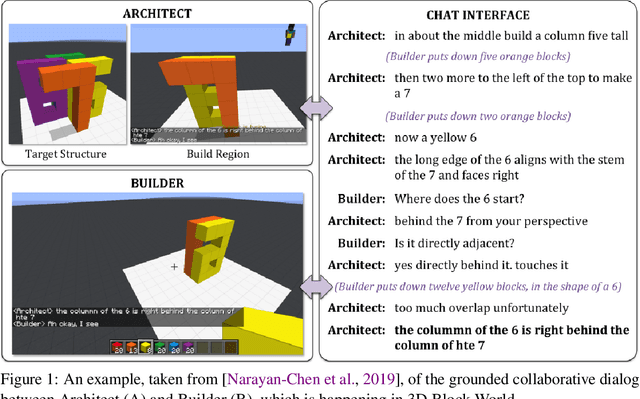

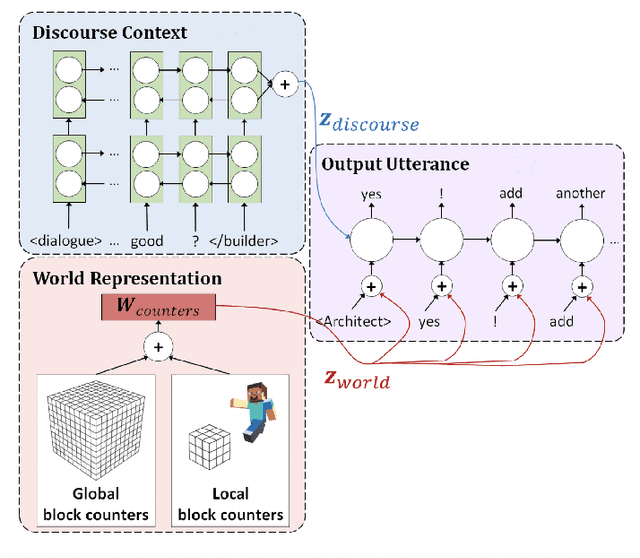
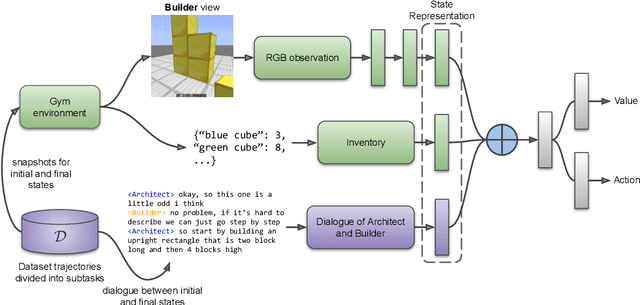
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Automatic Document Sketching: Generating Drafts from Analogous Texts
Jun 14, 2021
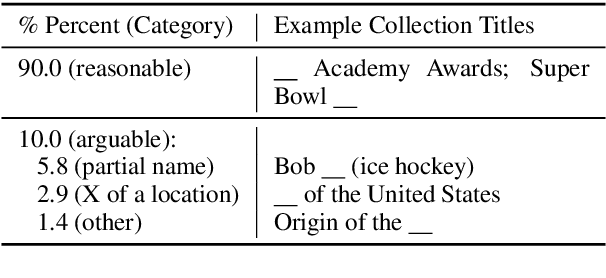
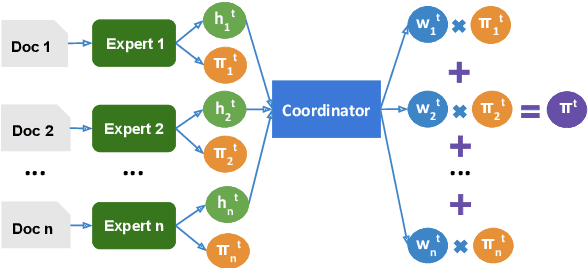
The advent of large pre-trained language models has made it possible to make high-quality predictions on how to add or change a sentence in a document. However, the high branching factor inherent to text generation impedes the ability of even the strongest language models to offer useful editing suggestions at a more global or document level. We introduce a new task, document sketching, which involves generating entire draft documents for the writer to review and revise. These drafts are built from sets of documents that overlap in form - sharing large segments of potentially reusable text - while diverging in content. To support this task, we introduce a Wikipedia-based dataset of analogous documents and investigate the application of weakly supervised methods, including use of a transformer-based mixture of experts, together with reinforcement learning. We report experiments using automated and human evaluation methods and discuss relative merits of these models.