 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Sep 27, 2023



We present Any-Modality Augmented Language Model (AnyMAL), a unified model that reasons over diverse input modality signals (i.e. text, image, video, audio, IMU motion sensor), and generates textual responses. AnyMAL inherits the powerful text-based reasoning abilities of the state-of-the-art LLMs including LLaMA-2 (70B), and converts modality-specific signals to the joint textual space through a pre-trained aligner module. To further strengthen the multimodal LLM's capabilities, we fine-tune the model with a multimodal instruction set manually collected to cover diverse topics and tasks beyond simple QAs. We conduct comprehensive empirical analysis comprising both human and automatic evaluations, and demonstrate state-of-the-art performance on various multimodal tasks.
A Data Source for Reasoning Embodied Agents
Sep 14, 2023



Recent progress in using machine learning models for reasoning tasks has been driven by novel model architectures, large-scale pre-training protocols, and dedicated reasoning datasets for fine-tuning. In this work, to further pursue these advances, we introduce a new data generator for machine reasoning that integrates with an embodied agent. The generated data consists of templated text queries and answers, matched with world-states encoded into a database. The world-states are a result of both world dynamics and the actions of the agent. We show the results of several baseline models on instantiations of train sets. These include pre-trained language models fine-tuned on a text-formatted representation of the database, and graph-structured Transformers operating on a knowledge-graph representation of the database. We find that these models can answer some questions about the world-state, but struggle with others. These results hint at new research directions in designing neural reasoning models and database representations. Code to generate the data will be released at github.com/facebookresearch/neuralmemory
Transforming Human-Centered AI Collaboration: Redefining Embodied Agents Capabilities through Interactive Grounded Language Instructions
May 18, 2023



Human intelligence's adaptability is remarkable, allowing us to adjust to new tasks and multi-modal environments swiftly. This skill is evident from a young age as we acquire new abilities and solve problems by imitating others or following natural language instructions. The research community is actively pursuing the development of interactive "embodied agents" that can engage in natural conversations with humans and assist them with real-world tasks. These agents must possess the ability to promptly request feedback in case communication breaks down or instructions are unclear. Additionally, they must demonstrate proficiency in learning new vocabulary specific to a given domain. In this paper, we made the following contributions: (1) a crowd-sourcing tool for collecting grounded language instructions; (2) the largest dataset of grounded language instructions; and (3) several state-of-the-art baselines. These contributions are suitable as a foundation for further research.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022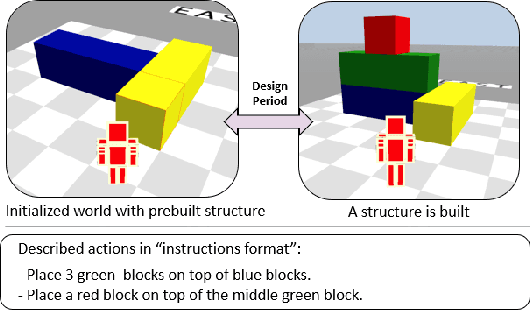

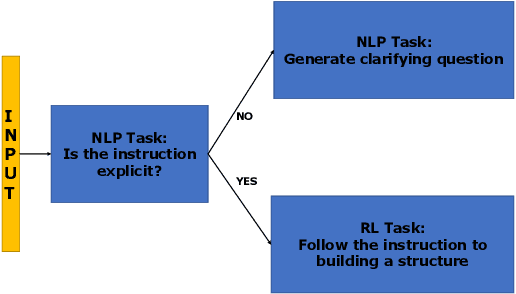
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
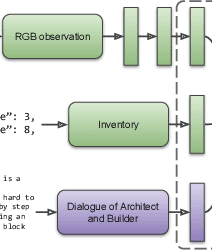
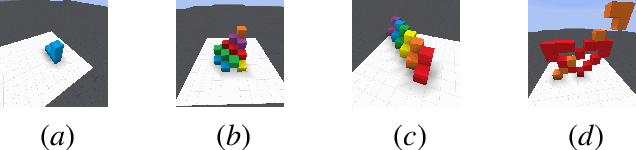
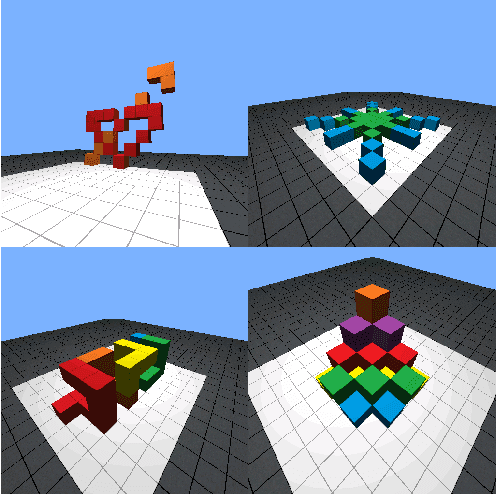
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
Many Episode Learning in a Modular Embodied Agent via End-to-End Interaction
Apr 19, 2022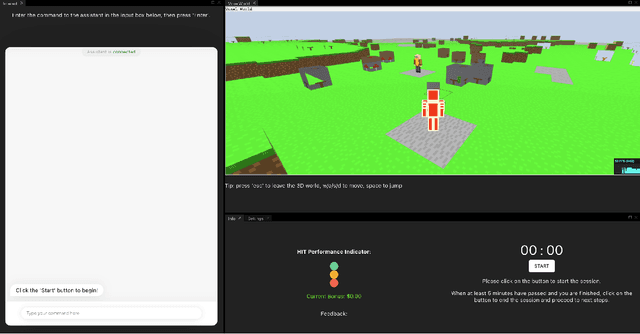


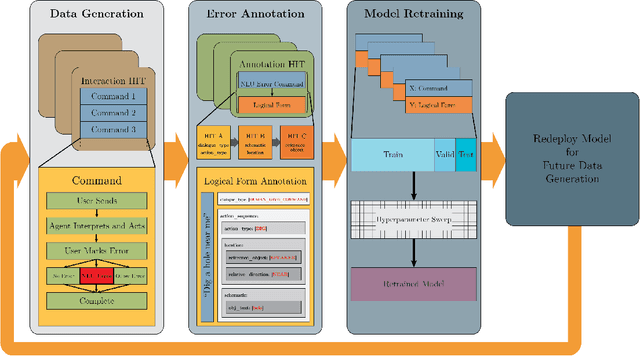
In this work we give a case study of an embodied machine-learning (ML) powered agent that improves itself via interactions with crowd-workers. The agent consists of a set of modules, some of which are learned, and others heuristic. While the agent is not "end-to-end" in the ML sense, end-to-end interaction is a vital part of the agent's learning mechanism. We describe how the design of the agent works together with the design of multiple annotation interfaces to allow crowd-workers to assign credit to module errors from end-to-end interactions, and to label data for individual modules. Over multiple automated human-agent interaction, credit assignment, data annotation, and model re-training and re-deployment, rounds we demonstrate agent improvement.
NeurIPS 2021 Competition IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Oct 15, 2021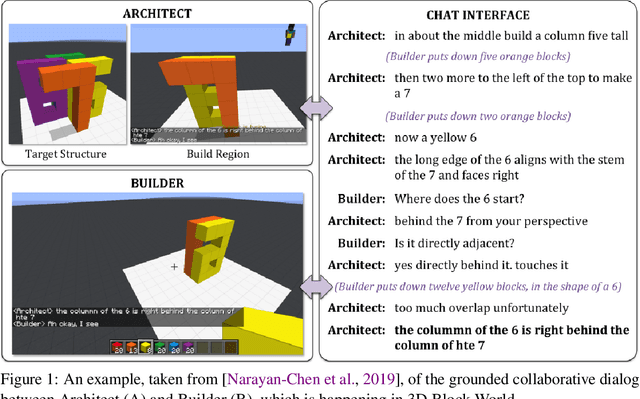

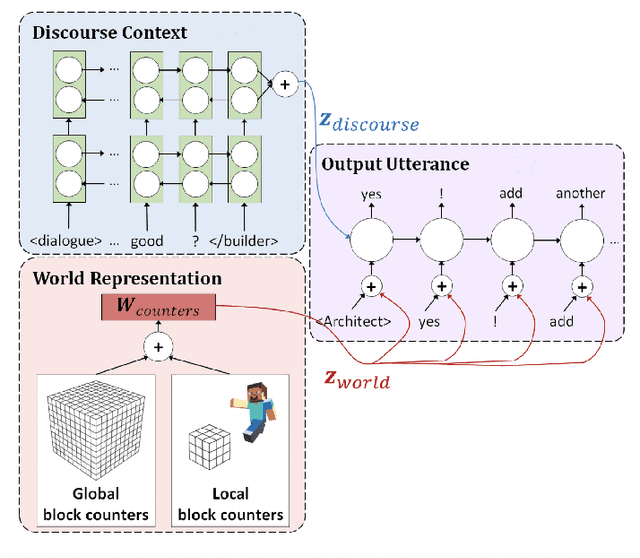
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
droidlet: modular, heterogenous, multi-modal agents
Jan 25, 2021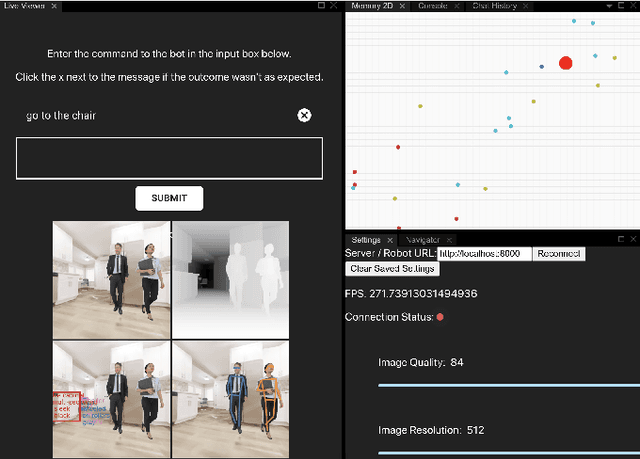
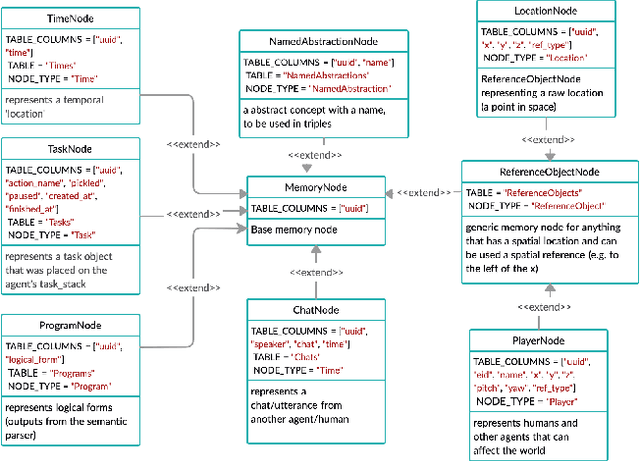
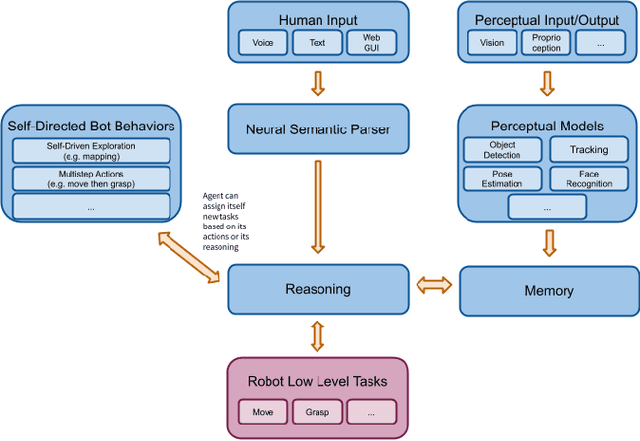
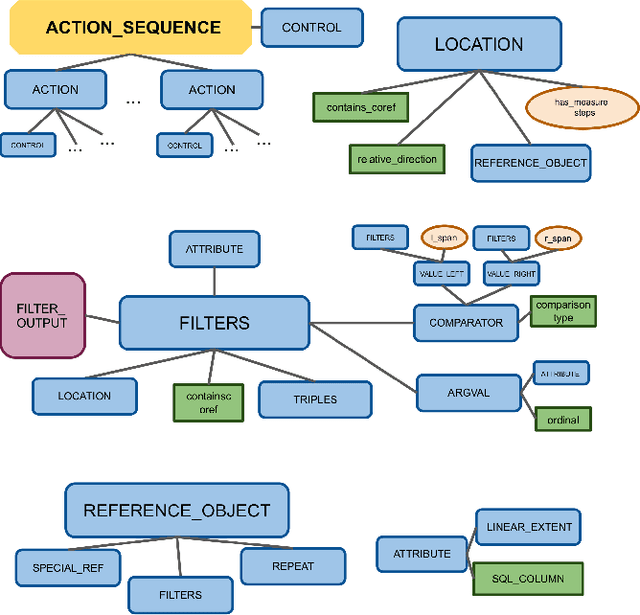
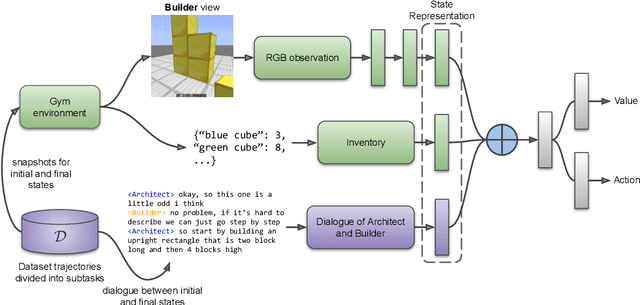
In recent years, there have been significant advances in building end-to-end Machine Learning (ML) systems that learn at scale. But most of these systems are: (a) isolated (perception, speech, or language only); (b) trained on static datasets. On the other hand, in the field of robotics, large-scale learning has always been difficult. Supervision is hard to gather and real world physical interactions are expensive. In this work we introduce and open-source droidlet, a modular, heterogeneous agent architecture and platform. It allows us to exploit both large-scale static datasets in perception and language and sophisticated heuristics often used in robotics; and provides tools for interactive annotation. Furthermore, it brings together perception, language and action onto one platform, providing a path towards agents that learn from the richness of real world interactions.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.