 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
Creating generalizable downstream graph models with random projections
Feb 17, 2023



We investigate graph representation learning approaches that enable models to generalize across graphs: given a model trained using the representations from one graph, our goal is to apply inference using those same model parameters when given representations computed over a new graph, unseen during model training, with minimal degradation in inference accuracy. This is in contrast to the more common task of doing inference on the unseen nodes of the same graph. We show that using random projections to estimate multiple powers of the transition matrix allows us to build a set of isomorphism-invariant features that can be used by a variety of tasks. The resulting features can be used to recover enough information about the local neighborhood of a node to enable inference with relevance competitive to other approaches while maintaining computational efficiency.
Probing Factually Grounded Content Transfer with Factual Ablation
Mar 29, 2022
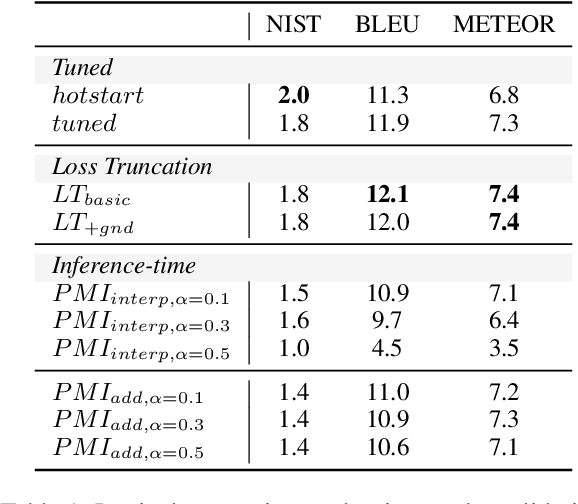
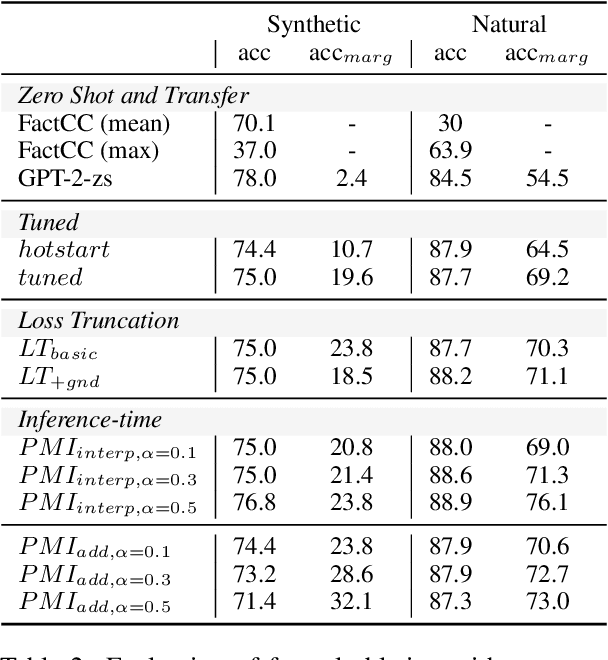

Despite recent success, large neural models often generate factually incorrect text. Compounding this is the lack of a standard automatic evaluation for factuality--it cannot be meaningfully improved if it cannot be measured. Grounded generation promises a path to solving both of these problems: models draw on a reliable external document (grounding) for factual information, simplifying the challenge of factuality. Measuring factuality is also simplified--to factual consistency, testing whether the generation agrees with the grounding, rather than all facts. Yet, without a standard automatic metric for factual consistency, factually grounded generation remains an open problem. We study this problem for content transfer, in which generations extend a prompt, using information from factual grounding. Particularly, this domain allows us to introduce the notion of factual ablation for automatically measuring factual consistency: this captures the intuition that the model should be less likely to produce an output given a less relevant grounding document. In practice, we measure this by presenting a model with two grounding documents, and the model should prefer to use the more factually relevant one. We contribute two evaluation sets to measure this. Applying our new evaluation, we propose multiple novel methods improving over strong baselines.
Text Editing by Command
Oct 24, 2020
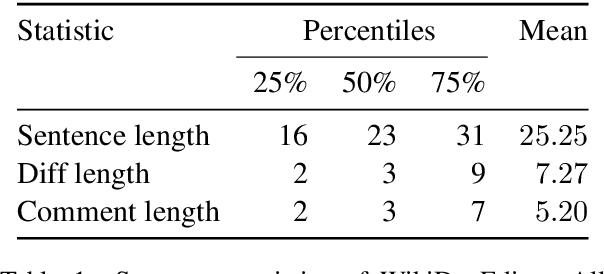
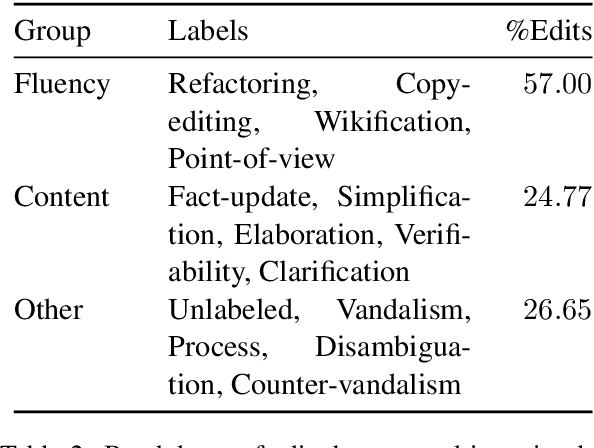
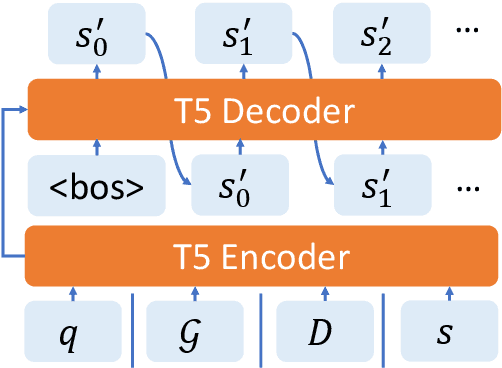
A prevailing paradigm in neural text generation is one-shot generation, where text is produced in a single step. The one-shot setting is inadequate, however, when the constraints the user wishes to impose on the generated text are dynamic, especially when authoring longer documents. We address this limitation with an interactive text generation setting in which the user interacts with the system by issuing commands to edit existing text. To this end, we propose a novel text editing task, and introduce WikiDocEdits, a dataset of single-sentence edits crawled from Wikipedia. We show that our Interactive Editor, a transformer-based model trained on this dataset, outperforms baselines and obtains positive results in both automatic and human evaluations. We present empirical and qualitative analyses of this model's performance.
Examination and Extension of Strategies for Improving Personalized Language Modeling via Interpolation
Jun 09, 2020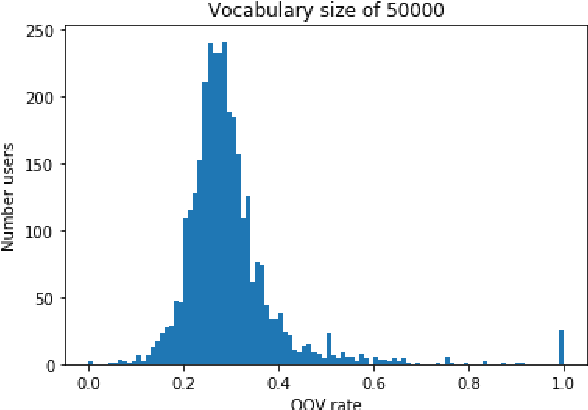
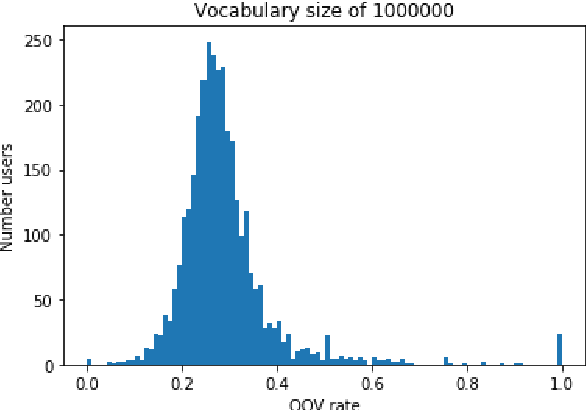
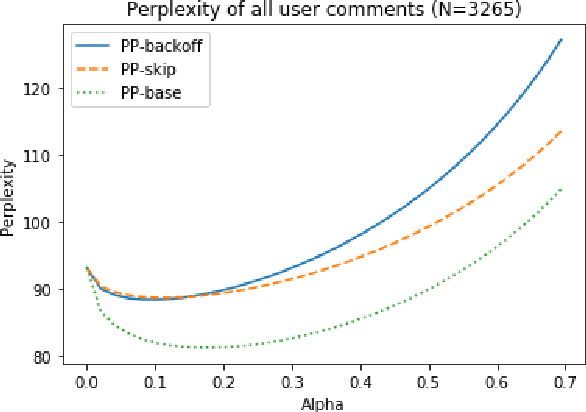
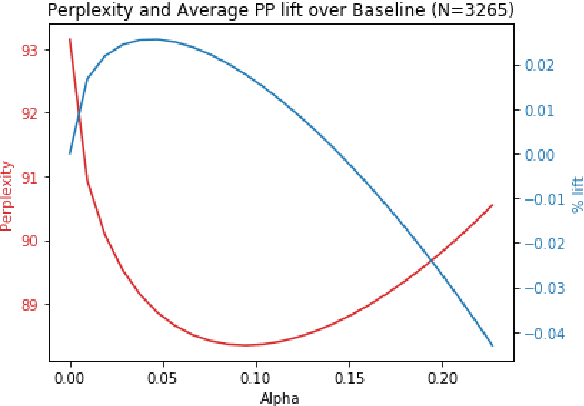
In this paper, we detail novel strategies for interpolating personalized language models and methods to handle out-of-vocabulary (OOV) tokens to improve personalized language models. Using publicly available data from Reddit, we demonstrate improvements in offline metrics at the user level by interpolating a global LSTM-based authoring model with a user-personalized n-gram model. By optimizing this approach with a back-off to uniform OOV penalty and the interpolation coefficient, we observe that over 80% of users receive a lift in perplexity, with an average of 5.2% in perplexity lift per user. In doing this research we extend previous work in building NLIs and improve the robustness of metrics for downstream tasks.
A Controllable Model of Grounded Response Generation
May 01, 2020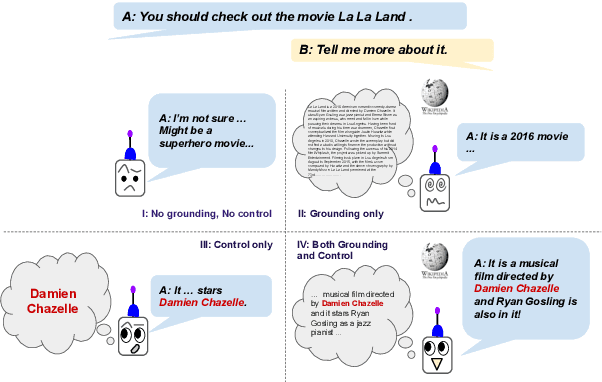
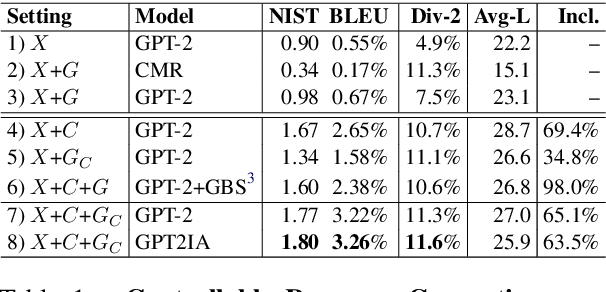
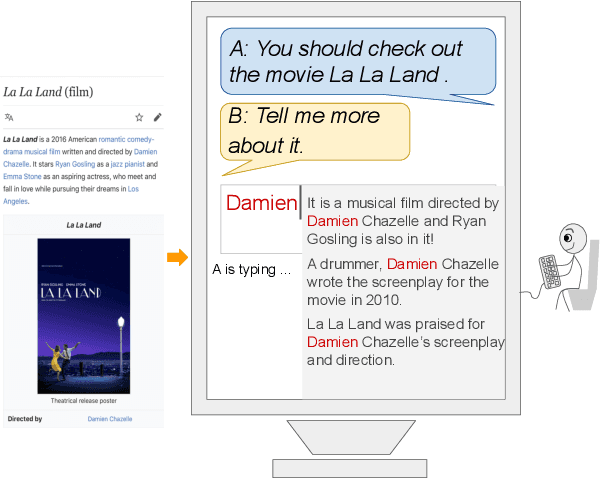
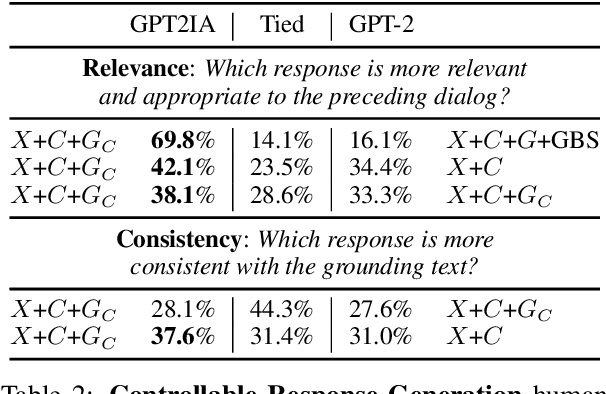
Current end-to-end neural conversation models inherently lack the flexibility to impose semantic control in the response generation process. This control is essential to ensure that users' semantic intents are satisfied and to impose a degree of specificity on generated outputs. Attempts to boost informativeness alone come at the expense of factual accuracy, as attested by GPT-2's propensity to "hallucinate" facts. While this may be mitigated by access to background knowledge, there is scant guarantee of relevance and informativeness in generated responses. We propose a framework that we call controllable grounded response generation (CGRG), in which lexical control phrases are either provided by an user or automatically extracted by a content planner from dialogue context and grounding knowledge. Quantitative and qualitative results show that, using this framework, a GPT-2 based model trained on a conversation-like Reddit dataset outperforms strong generation baselines.
Towards Content Transfer through Grounded Text Generation
May 13, 2019

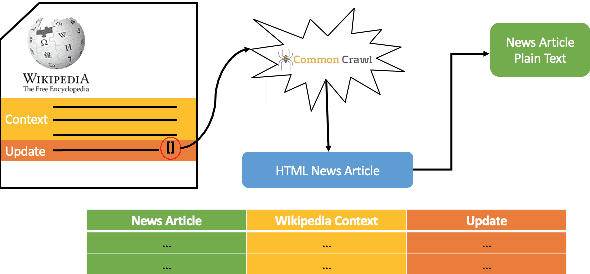
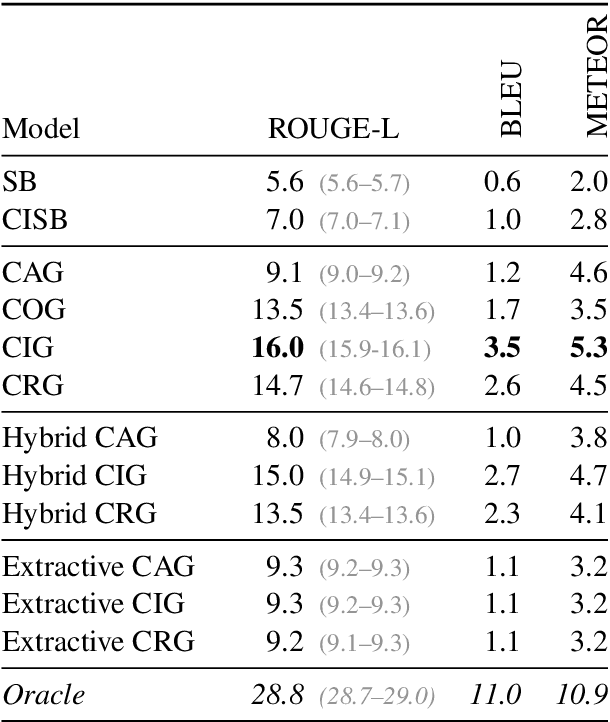
Recent work in neural generation has attracted significant interest in controlling the form of text, such as style, persona, and politeness. However, there has been less work on controlling neural text generation for content. This paper introduces the notion of Content Transfer for long-form text generation, where the task is to generate a next sentence in a document that both fits its context and is grounded in a content-rich external textual source such as a news story. Our experiments on Wikipedia data show significant improvements against competitive baselines. As another contribution of this paper, we release a benchmark dataset of 640k Wikipedia referenced sentences paired with the source articles to encourage exploration of this new task.
Confidence Modeling for Neural Semantic Parsing
May 11, 2018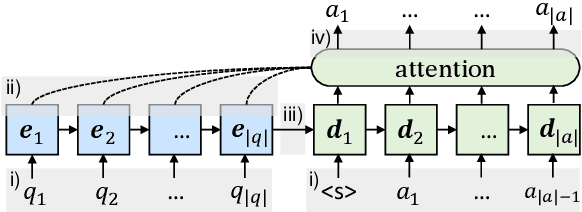



In this work we focus on confidence modeling for neural semantic parsers which are built upon sequence-to-sequence models. We outline three major causes of uncertainty, and design various metrics to quantify these factors. These metrics are then used to estimate confidence scores that indicate whether model predictions are likely to be correct. Beyond confidence estimation, we identify which parts of the input contribute to uncertain predictions allowing users to interpret their model, and verify or refine its input. Experimental results show that our confidence model significantly outperforms a widely used method that relies on posterior probability, and improves the quality of interpretation compared to simply relying on attention scores.
Abstractions for AI-Based User Interfaces and Systems
Sep 14, 2017Novel user interfaces based on artificial intelligence, such as natural-language agents, present new categories of engineering challenges. These systems need to cope with uncertainty and ambiguity, interface with machine learning algorithms, and compose information from multiple users to make decisions. We propose to treat these challenges as language-design problems. We describe three programming language abstractions for three core problems in intelligent system design. First, hypothetical worlds support nondeterministic search over spaces of alternative actions. Second, a feature type system abstracts the interaction between applications and learning algorithms. Finally, constructs for collaborative execution extend hypothetical worlds across multiple machines while controlling access to private data. We envision these features as first steps toward a complete language for implementing AI-based interfaces and applications.
Distant Supervision for Relation Extraction beyond the Sentence Boundary
Aug 14, 2017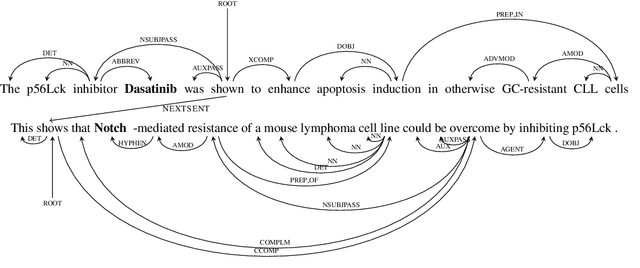

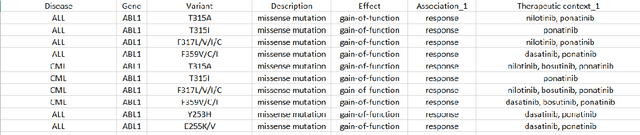

The growing demand for structured knowledge has led to great interest in relation extraction, especially in cases with limited supervision. However, existing distance supervision approaches only extract relations expressed in single sentences. In general, cross-sentence relation extraction is under-explored, even in the supervised-learning setting. In this paper, we propose the first approach for applying distant supervision to cross- sentence relation extraction. At the core of our approach is a graph representation that can incorporate both standard dependencies and discourse relations, thus providing a unifying way to model relations within and across sentences. We extract features from multiple paths in this graph, increasing accuracy and robustness when confronted with linguistic variation and analysis error. Experiments on an important extraction task for precision medicine show that our approach can learn an accurate cross-sentence extractor, using only a small existing knowledge base and unlabeled text from biomedical research articles. Compared to the existing distant supervision paradigm, our approach extracted twice as many relations at similar precision, thus demonstrating the prevalence of cross-sentence relations and the promise of our approach.