 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Rearrangement Using Learned Implicit Collision Functions
Nov 21, 2020
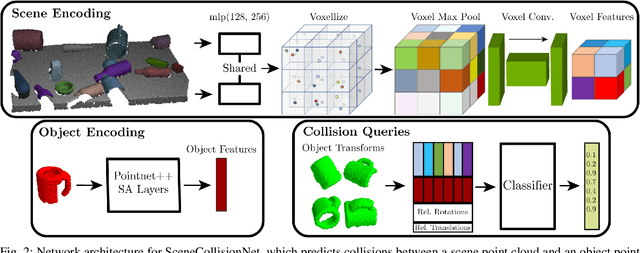
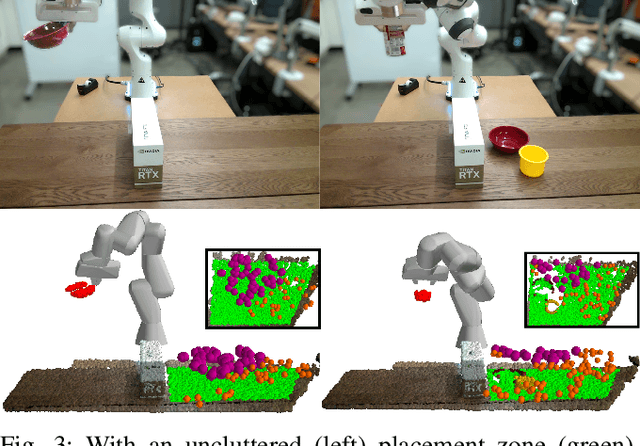
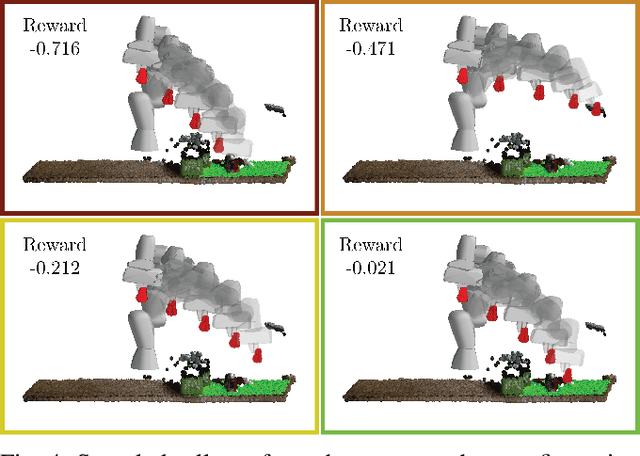
Robotic object rearrangement combines the skills of picking and placing objects. When object models are unavailable, typical collision-checking models may be unable to predict collisions in partial point clouds with occlusions, making generation of collision-free grasping or placement trajectories challenging. We propose a learned collision model that accepts scene and query object point clouds and predicts collisions for 6DOF object poses within the scene. We train the model on a synthetic set of 1 million scene/object point cloud pairs and 2 billion collision queries. We leverage the learned collision model as part of a model predictive path integral (MPPI) policy in a tabletop rearrangement task and show that the policy can plan collision-free grasps and placements for objects unseen in training in both simulated and physical cluttered scenes with a Franka Panda robot. The learned model outperforms both traditional pipelines and learned ablations by 9.8% in accuracy on a dataset of simulated collision queries and is 75x faster than the best-performing baseline. Videos and supplementary material are available at https://sites.google.com/nvidia.com/scenecollisionnet.
Exploratory Grasping: Asymptotically Optimal Algorithms for Grasping Challenging Polyhedral Objects
Nov 12, 2020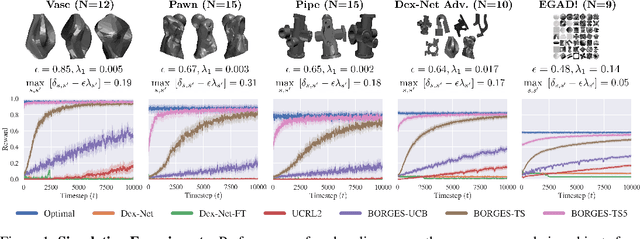
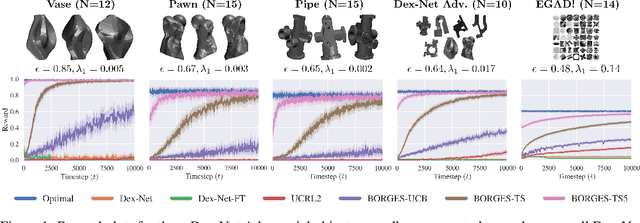
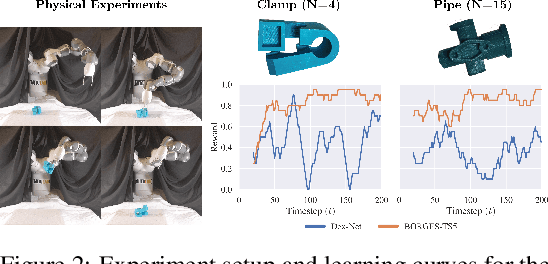
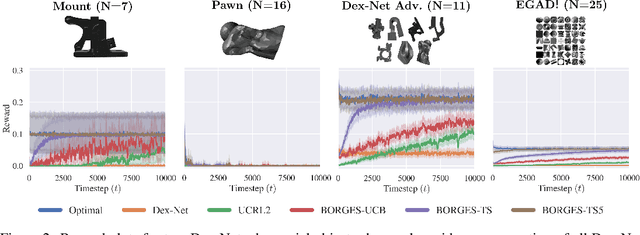
There has been significant recent work on data-driven algorithms for learning general-purpose grasping policies. However, these policies can consistently fail to grasp challenging objects which are significantly out of the distribution of objects in the training data or which have very few high quality grasps. Motivated by such objects, we propose a novel problem setting, Exploratory Grasping, for efficiently discovering reliable grasps on an unknown polyhedral object via sequential grasping, releasing, and toppling. We formalize Exploratory Grasping as a Markov Decision Process, study the theoretical complexity of Exploratory Grasping in the context of reinforcement learning and present an efficient bandit-style algorithm, Bandits for Online Rapid Grasp Exploration Strategy (BORGES), which leverages the structure of the problem to efficiently discover high performing grasps for each object stable pose. BORGES can be used to complement any general-purpose grasping algorithm with any grasp modality (parallel-jaw, suction, multi-fingered, etc) to learn policies for objects in which they exhibit persistent failures. Simulation experiments suggest that BORGES can significantly outperform both general-purpose grasping pipelines and two other online learning algorithms and achieves performance within 5% of the optimal policy within 1000 and 8000 timesteps on average across 46 challenging objects from the Dex-Net adversarial and EGAD! object datasets, respectively. Initial physical experiments suggest that BORGES can improve grasp success rate by 45% over a Dex-Net baseline with just 200 grasp attempts in the real world. See https://tinyurl.com/exp-grasping for supplementary material and videos.
Accelerating Grasp Exploration by Leveraging Learned Priors
Nov 11, 2020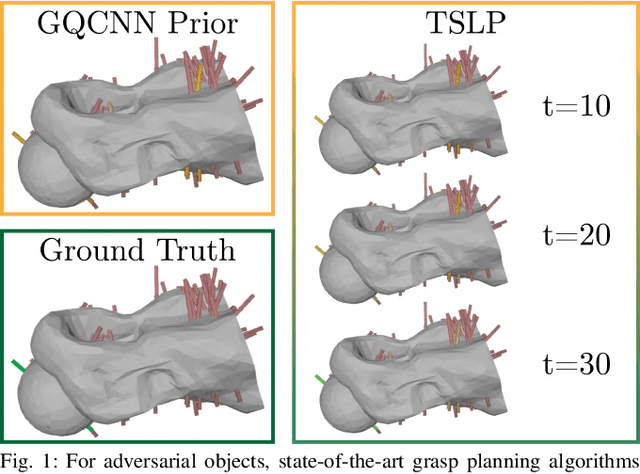
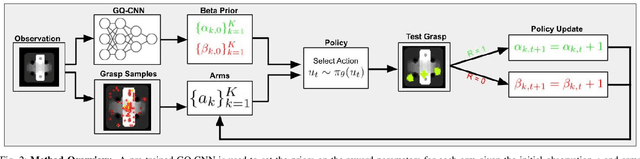
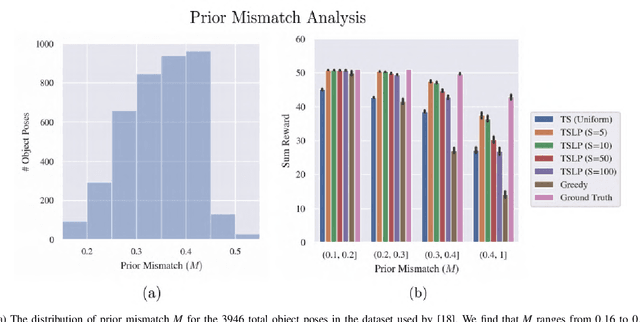
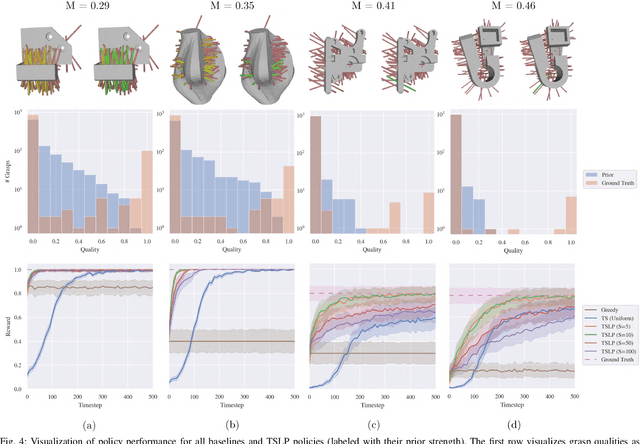
The ability of robots to grasp novel objects has industry applications in e-commerce order fulfillment and home service. Data-driven grasping policies have achieved success in learning general strategies for grasping arbitrary objects. However, these approaches can fail to grasp objects which have complex geometry or are significantly outside of the training distribution. We present a Thompson sampling algorithm that learns to grasp a given object with unknown geometry using online experience. The algorithm leverages learned priors from the Dexterity Network robot grasp planner to guide grasp exploration and provide probabilistic estimates of grasp success for each stable pose of the novel object. We find that seeding the policy with the Dex-Net prior allows it to more efficiently find robust grasps on these objects. Experiments suggest that the best learned policy attains an average total reward 64.5% higher than a greedy baseline and achieves within 5.7% of an oracle baseline when evaluated over 300,000 training runs across a set of 3000 object poses.
Non-Markov Policies to Reduce Sequential Failures in Robot Bin Picking
Jul 20, 2020



A new generation of automated bin picking systems using deep learning is evolving to support increasing demand for e-commerce. To accommodate a wide variety of products, many automated systems include multiple gripper types and/or tool changers. However, for some objects, sequential grasp failures are common: when a computed grasp fails to lift and remove the object, the bin is often left unchanged; as the sensor input is consistent, the system retries the same grasp over and over, resulting in a significant reduction in mean successful picks per hour (MPPH). Based on an empirical study of sequential failures, we characterize a class of "sequential failure objects" (SFOs) -- objects prone to sequential failures based on a novel taxonomy. We then propose three non-Markov picking policies that incorporate memory of past failures to modify subsequent actions. Simulation experiments on SFO models and the EGAD dataset suggest that the non-Markov policies significantly outperform the Markov policy in terms of the sequential failure rate and MPPH. In physical experiments on 50 heaps of 12 SFOs the most effective Non-Markov policy increased MPPH over the Dex-Net Markov policy by 107%.
X-Ray: Mechanical Search for an Occluded Object by Minimizing Support of Learned Occupancy Distributions
Apr 20, 2020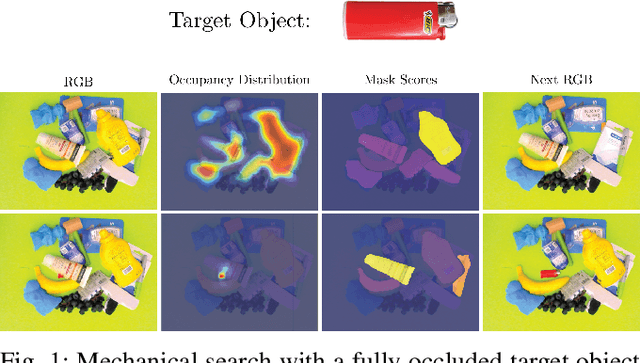
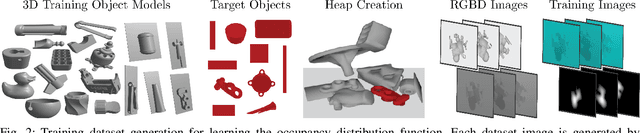
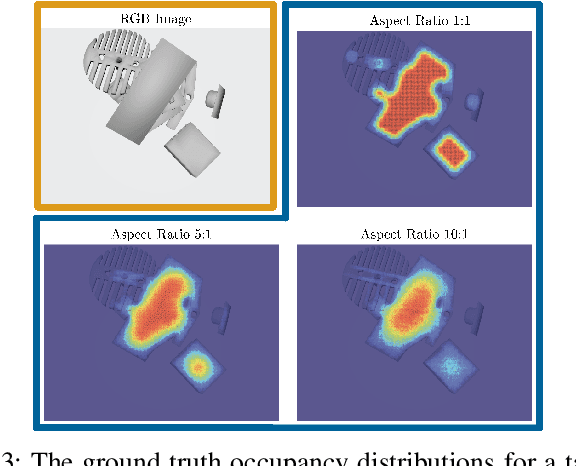
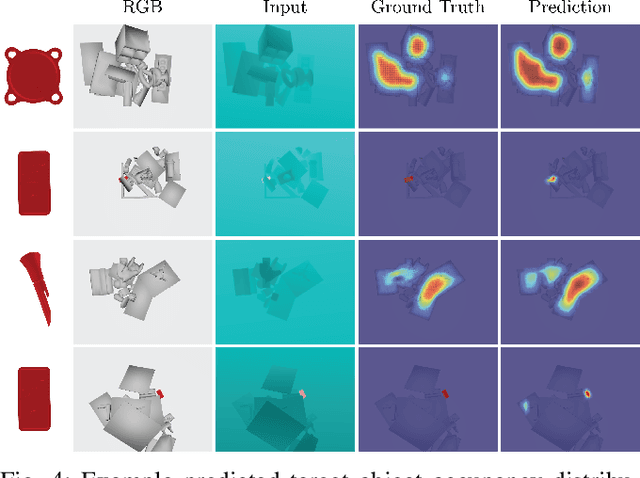
For applications in e-commerce, warehouses, healthcare, and home service, robots are often required to search through heaps of objects to grasp a specific target object. For mechanical search, we introduce X-Ray, an algorithm based on learned occupancy distributions. We train a neural network using a synthetic dataset of RGBD heap images labeled for a set of standard bounding box targets with varying aspect ratios. X-Ray minimizes support of the learned distribution as part of a mechanical search policy in both simulated and real environments. We benchmark these policies against two baseline policies on 1,000 heaps of 15 objects in simulation where the target object is partially or fully occluded. Results suggest that X-Ray is significantly more efficient, as it succeeds in extracting the target object 82% of the time, 15% more often than the best-performing baseline. Experiments on an ABB YuMi robot with 20 heaps of 25 household objects suggest that the learned policy transfers easily to a physical system, where it outperforms baseline policies by 15% in success rate with 17% fewer actions. Datasets, videos, and experiments are available at http://sites.google.com/berkeley.edu/x-ray .
GOMP: Grasp-Optimized Motion Planning for Bin Picking
Mar 05, 2020
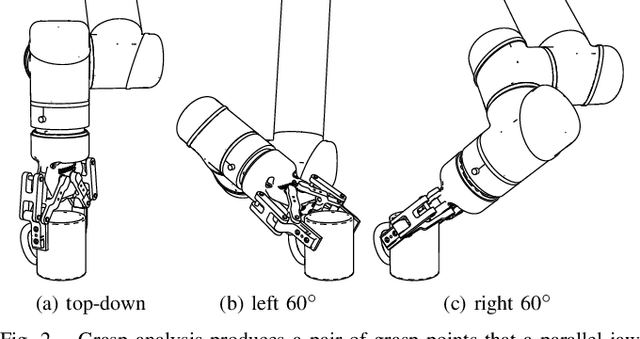


Rapid and reliable robot bin picking is a critical challenge in automating warehouses, often measured in picks-per-hour (PPH). We explore increasing PPH using faster motions based on optimizing over a set of candidate grasps. The source of this set of grasps is two-fold: (1) grasp-analysis tools such as Dex-Net generate multiple candidate grasps, and (2) each of these grasps has a degree of freedom about which a robot gripper can rotate. In this paper, we present Grasp-Optimized Motion Planning (GOMP), an algorithm that speeds up the execution of a bin-picking robot's operations by incorporating robot dynamics and a set of candidate grasps produced by a grasp planner into an optimizing motion planner. We compute motions by optimizing with sequential quadratic programming (SQP) and iteratively updating trust regions to account for the non-convex nature of the problem. In our formulation, we constrain the motion to remain within the mechanical limits of the robot while avoiding obstacles. We further convert the problem to a time-minimization by repeatedly shorting a time horizon of a trajectory until the SQP is infeasible. In experiments with a UR5, GOMP achieves a speedup of 9x over a baseline planner.
Minimal Work: A Grasp Quality Metric for Deformable Hollow Objects
Sep 24, 2019
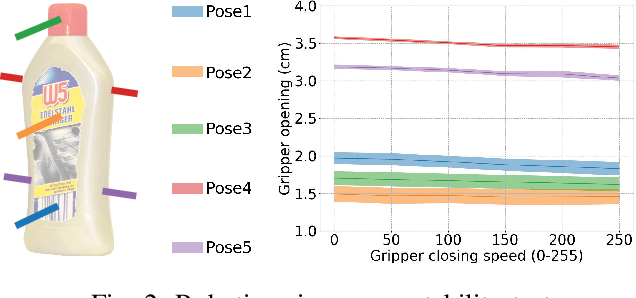
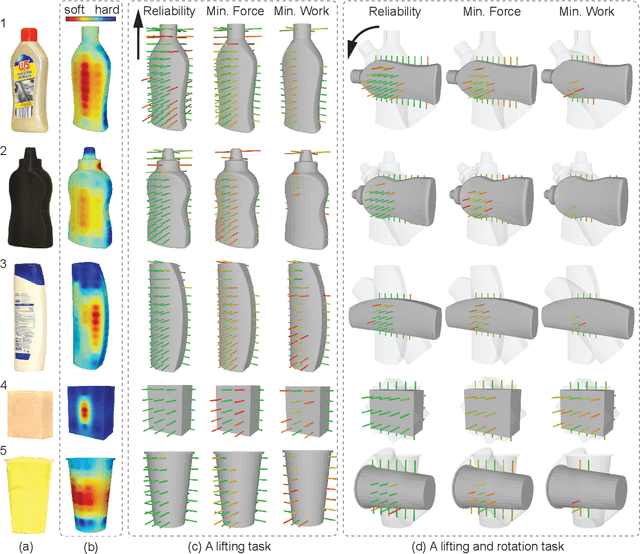
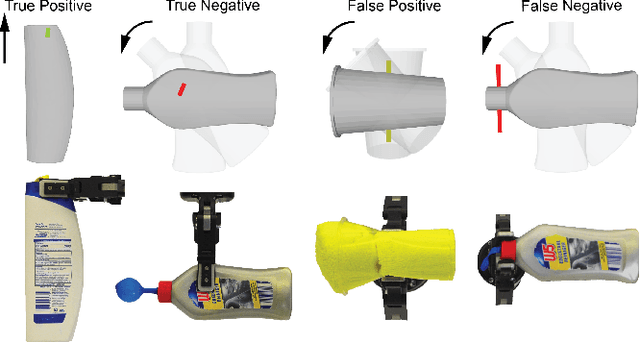
Robot grasping of deformable hollow objects such as plastic bottles and cups is challenging as the grasp should resist disturbances while minimally deforming the object so as not to damage it or dislodge liquids. We propose minimal work as a novel grasp quality metric that combines wrench resistance and the object deformation. We introduce an efficient algorithm to compute required work to resist an external wrench for a manipulation task by solving a linear program. The algorithm first computes the minimum required grasp force and an estimation of the gripper jaw displacements based on the object deformability at different locations measured with physical experiments. The work done by the jaws is the product of the grasp force and the displacements. The grasp quality metric is computed based on the required work under perturbations of grasp poses to address uncertainties in actuation. We collect 460 physical grasps with a UR5 robot and a Robotiq gripper. Physical experiments suggest the minimal work quality metric reaches 74.2% balanced accuracy and is up to 24.2% higher than classical wrench-based quality metrics, where the balanced accuracy is the raw accuracy normalized by the number of successful and failed real-world grasps.
Mechanical Search: Multi-Step Retrieval of a Target Object Occluded by Clutter
Mar 04, 2019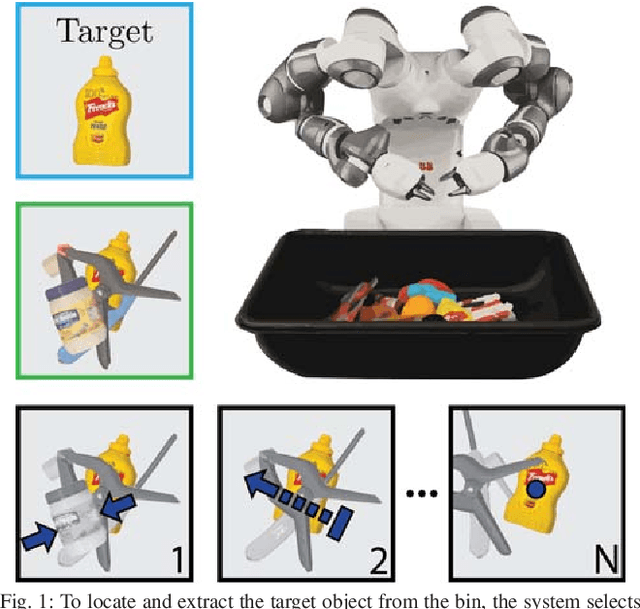
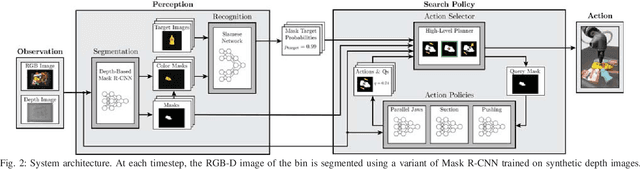
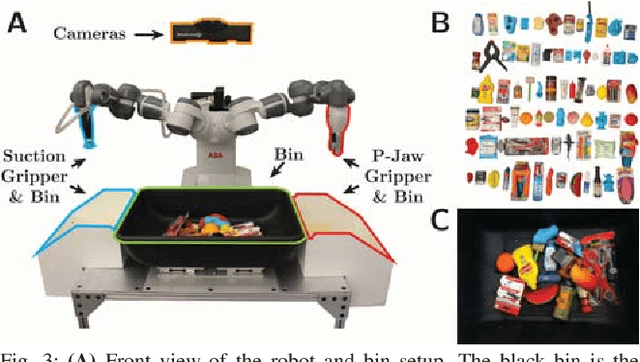
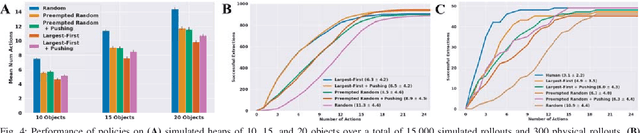
When operating in unstructured environments such as warehouses, homes, and retail centers, robots are frequently required to interactively search for and retrieve specific objects from cluttered bins, shelves, or tables. Mechanical Search describes the class of tasks where the goal is to locate and extract a known target object. In this paper, we formalize Mechanical Search and study a version where distractor objects are heaped over the target object in a bin. The robot uses an RGBD perception system and control policies to iteratively select, parameterize, and perform one of 3 actions -- push, suction, grasp -- until the target object is extracted, or either a time limit is exceeded, or no high confidence push or grasp is available. We present a study of 5 algorithmic policies for mechanical search, with 15,000 simulated trials and 300 physical trials for heaps ranging from 10 to 20 objects. Results suggest that success can be achieved in this long-horizon task with algorithmic policies in over 95% of instances and that the number of actions required scales approximately linearly with the size of the heap. Code and supplementary material can be found at http://ai.stanford.edu/mech-search .
Segmenting Unknown 3D Objects from Real Depth Images using Mask R-CNN Trained on Synthetic Data
Mar 03, 2019



The ability to segment unknown objects in depth images has potential to enhance robot skills in grasping and object tracking. Recent computer vision research has demonstrated that Mask R-CNN can be trained to segment specific categories of objects in RGB images when massive hand-labeled datasets are available. As generating these datasets is time consuming, we instead train with synthetic depth images. Many robots now use depth sensors, and recent results suggest training on synthetic depth data can transfer successfully to the real world. We present a method for automated dataset generation and rapidly generate a synthetic training dataset of 50,000 depth images and 320,000 object masks using simulated heaps of 3D CAD models. We train a variant of Mask R-CNN with domain randomization on the generated dataset to perform category-agnostic instance segmentation without any hand-labeled data and we evaluate the trained network, which we refer to as Synthetic Depth (SD) Mask R-CNN, on a set of real, high-resolution depth images of challenging, densely-cluttered bins containing objects with highly-varied geometry. SD Mask R-CNN outperforms point cloud clustering baselines by an absolute 15% in Average Precision and 20% in Average Recall on COCO benchmarks, and achieves performance levels similar to a Mask R-CNN trained on a massive, hand-labeled RGB dataset and fine-tuned on real images from the experimental setup. We deploy the model in an instance-specific grasping pipeline to demonstrate its usefulness in a robotics application. Code, the synthetic training dataset, and supplementary material are available at https://bit.ly/2letCuE.