 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Sensor Intentions for Exploration
May 15, 2020
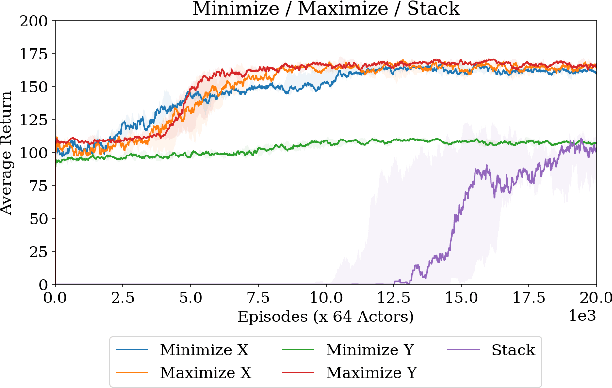
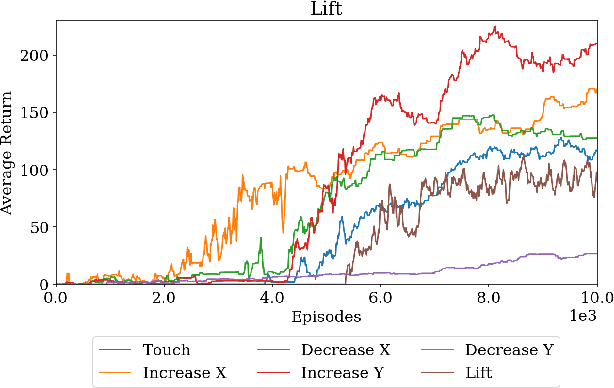
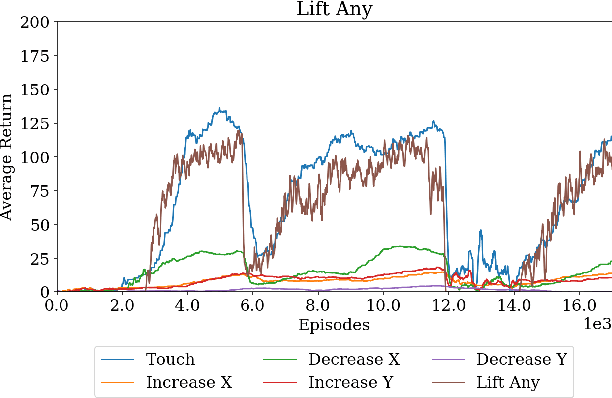
Modern reinforcement learning algorithms can learn solutions to increasingly difficult control problems while at the same time reduce the amount of prior knowledge needed for their application. One of the remaining challenges is the definition of reward schemes that appropriately facilitate exploration without biasing the solution in undesirable ways, and that can be implemented on real robotic systems without expensive instrumentation. In this paper we focus on a setting in which goal tasks are defined via simple sparse rewards, and exploration is facilitated via agent-internal auxiliary tasks. We introduce the idea of simple sensor intentions (SSIs) as a generic way to define auxiliary tasks. SSIs reduce the amount of prior knowledge that is required to define suitable rewards. They can further be computed directly from raw sensor streams and thus do not require expensive and possibly brittle state estimation on real systems. We demonstrate that a learning system based on these rewards can solve complex robotic tasks in simulation and in real world settings. In particular, we show that a real robotic arm can learn to grasp and lift and solve a Ball-in-a-Cup task from scratch, when only raw sensor streams are used for both controller input and in the auxiliary reward definition.
Comparing View-Based and Map-Based Semantic Labelling in Real-Time SLAM
Feb 24, 2020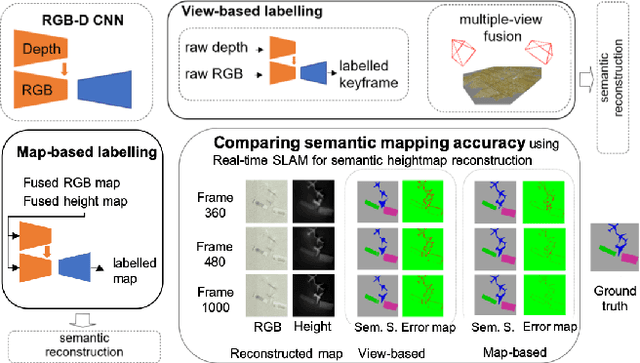
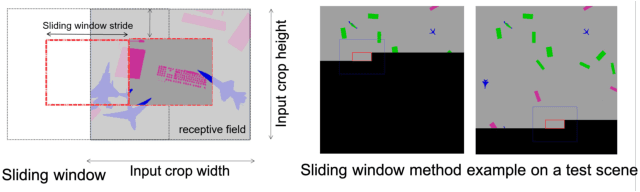
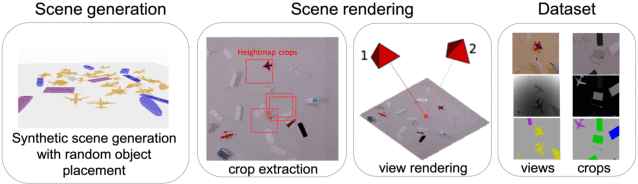
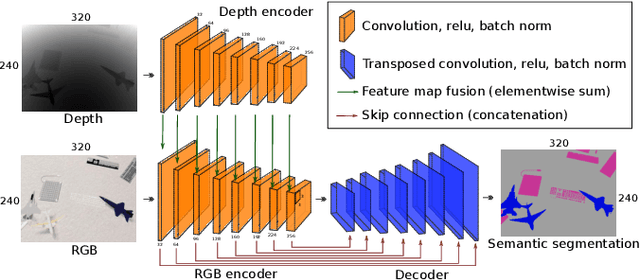
Generally capable Spatial AI systems must build persistent scene representations where geometric models are combined with meaningful semantic labels. The many approaches to labelling scenes can be divided into two clear groups: view-based which estimate labels from the input view-wise data and then incrementally fuse them into the scene model as it is built; and map-based which label the generated scene model. However, there has so far been no attempt to quantitatively compare view-based and map-based labelling. Here, we present an experimental framework and comparison which uses real-time height map fusion as an accessible platform for a fair comparison, opening up the route to further systematic research in this area.
MID-Fusion: Octree-based Object-Level Multi-Instance Dynamic SLAM
Mar 21, 2019
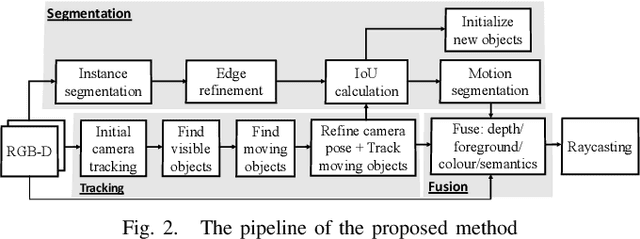
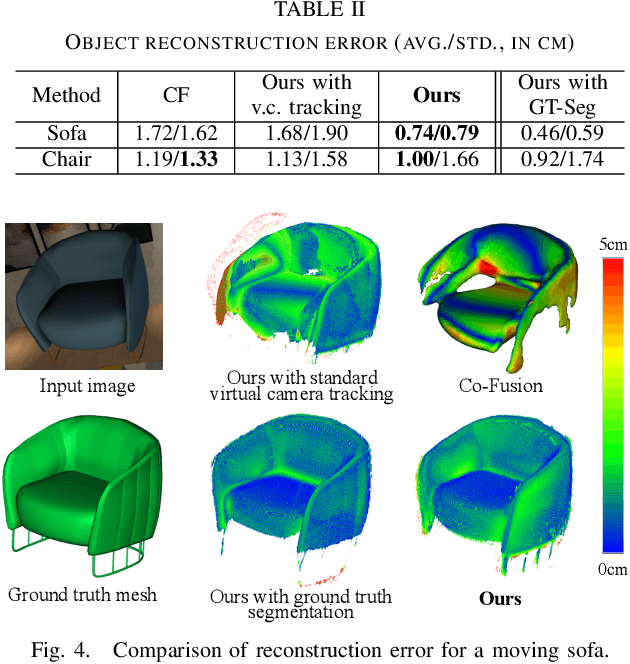

We propose a new multi-instance dynamic RGB-D SLAM system using an object-level octree-based volumetric representation. It can provide robust camera tracking in dynamic environments and at the same time, continuously estimate geometric, semantic, and motion properties for arbitrary objects in the scene. For each incoming frame, we perform instance segmentation to detect objects and refine mask boundaries using geometric and motion information. Meanwhile, we estimate the pose of each existing moving object using an object-oriented tracking method and robustly track the camera pose against the static scene. Based on the estimated camera pose and object poses, we associate segmented masks with existing models and incrementally fuse corresponding colour, depth, semantic, and foreground object probabilities into each object model. In contrast to existing approaches, our system is the first system to generate an object-level dynamic volumetric map from a single RGB-D camera, which can be used directly for robotic tasks. Our method can run at 2-3 Hz on a CPU, excluding the instance segmentation part. We demonstrate its effectiveness by quantitatively and qualitatively testing it on both synthetic and real-world sequences.
SceneCode: Monocular Dense Semantic Reconstruction using Learned Encoded Scene Representations
Mar 18, 2019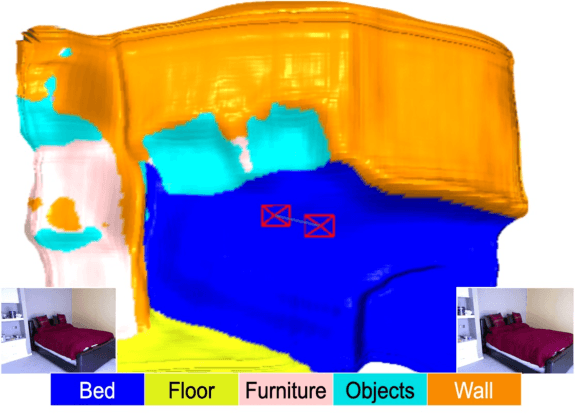
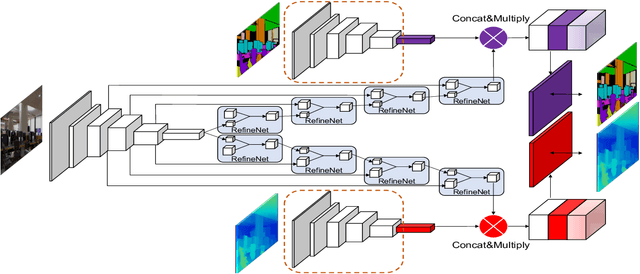
Systems which incrementally create 3D semantic maps from image sequences must store and update representations of both geometry and semantic entities. However, while there has been much work on the correct formulation for geometrical estimation, state-of-the-art systems usually rely on simple semantic representations which store and update independent label estimates for each surface element (depth pixels, surfels, or voxels). Spatial correlation is discarded, and fused label maps are incoherent and noisy. We introduce a new compact and optimisable semantic representation by training a variational auto-encoder that is conditioned on a colour image. Using this learned latent space, we can tackle semantic label fusion by jointly optimising the low-dimenional codes associated with each of a set of overlapping images, producing consistent fused label maps which preserve spatial correlation. We also show how this approach can be used within a monocular keyframe based semantic mapping system where a similar code approach is used for geometry. The probabilistic formulation allows a flexible formulation where we can jointly estimate motion, geometry and semantics in a unified optimisation.
Matching Features without Descriptors: Implicitly Matched Interest Points (IMIPs)
Nov 26, 2018
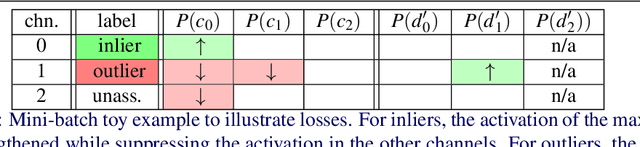
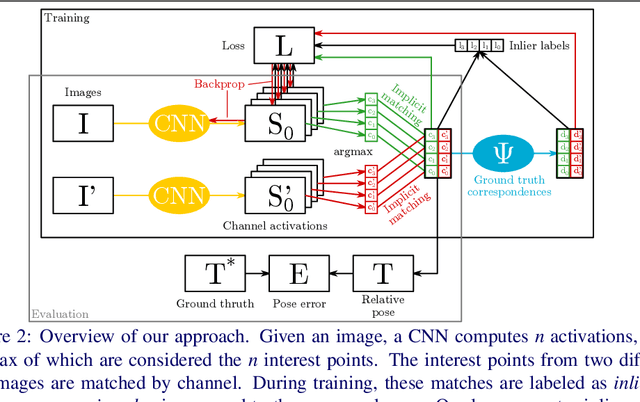
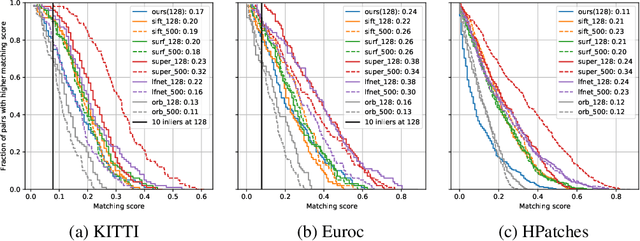
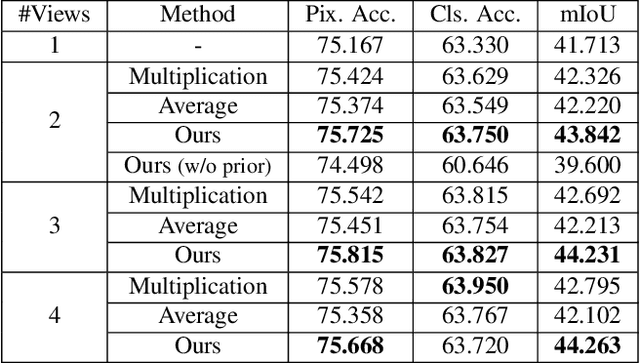
The extraction and matching of interest points is a prerequisite for visual pose estimation and related problems. Traditionally, matching has been achieved by assigning descriptors to interest points and matching points that have similar descriptors. In this paper, we propose a method by which interest points are instead already implicitly matched at detection time. Thanks to this, descriptors do not need to be calculated, stored, communicated, or matched any more. This is achieved by a convolutional neural network with multiple output channels. The i-th interest point is the location of the maximum of the i-th channel, and the i-th interest point in one image is implicitly matched with the i-th interest point in another image. This paper describes how to design and train such a network in a way that results in successful relative pose estimation performance with as little as 128 output channels. While the overall matching score is slightly lower than with traditional methods, the network also outputs the confidence for a specific interest point resulting in a valid match. Most importantly, the approach completely gets rid of descriptors and thus enables localization systems with a significantly smaller memory footprint and multi-agent localization systems that require significantly less bandwidth. We evaluate performance relative to state-of-the-art alternatives.
Task-Embedded Control Networks for Few-Shot Imitation Learning
Oct 08, 2018

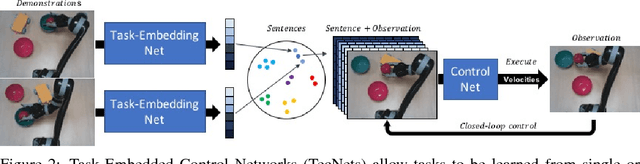
Much like humans, robots should have the ability to leverage knowledge from previously learned tasks in order to learn new tasks quickly in new and unfamiliar environments. Despite this, most robot learning approaches have focused on learning a single task, from scratch, with a limited notion of generalisation, and no way of leveraging the knowledge to learn other tasks more efficiently. One possible solution is meta-learning, but many of the related approaches are limited in their ability to scale to a large number of tasks and to learn further tasks without forgetting previously learned ones. With this in mind, we introduce Task-Embedded Control Networks, which employ ideas from metric learning in order to create a task embedding that can be used by a robot to learn new tasks from one or more demonstrations. In the area of visually-guided manipulation, we present simulation results in which we surpass the performance of a state-of-the-art method when using only visual information from each demonstration. Additionally, we demonstrate that our approach can also be used in conjunction with domain randomisation to train our few-shot learning ability in simulation and then deploy in the real world without any additional training. Once deployed, the robot can learn new tasks from a single real-world demonstration.
LS-Net: Learning to Solve Nonlinear Least Squares for Monocular Stereo
Sep 09, 2018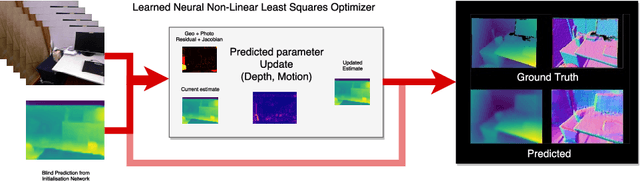
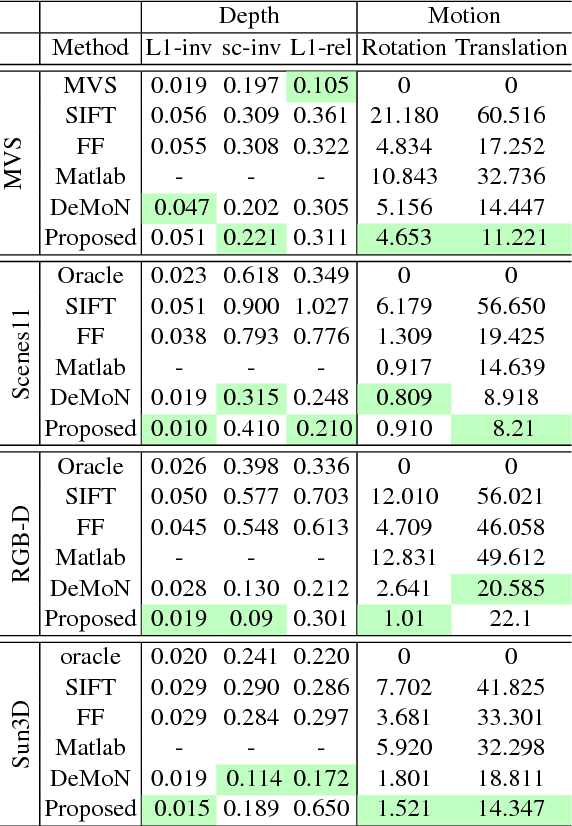
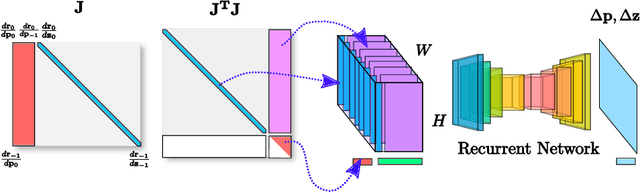
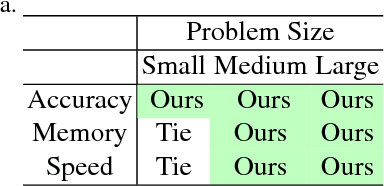
Sum-of-squares objective functions are very popular in computer vision algorithms. However, these objective functions are not always easy to optimize. The underlying assumptions made by solvers are often not satisfied and many problems are inherently ill-posed. In this paper, we propose LS-Net, a neural nonlinear least squares optimization algorithm which learns to effectively optimize these cost functions even in the presence of adversities. Unlike traditional approaches, the proposed solver requires no hand-crafted regularizers or priors as these are implicitly learned from the data. We apply our method to the problem of motion stereo ie. jointly estimating the motion and scene geometry from pairs of images of a monocular sequence. We show that our learned optimizer is able to efficiently and effectively solve this challenging optimization problem.
Build Your Own Visual-Inertial Drone: A Cost-Effective and Open-Source Autonomous Drone
Sep 06, 2018


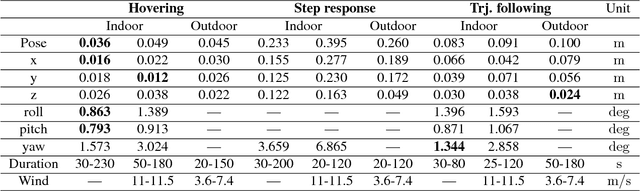
This paper describes an approach to building a cost-effective and research grade visual-inertial odometry aided vertical taking-off and landing (VTOL) platform. We utilize an off-the-shelf visual-inertial sensor, an onboard computer, and a quadrotor platform that are factory-calibrated and mass-produced, thereby sharing similar hardware and sensor specifications (e.g., mass, dimensions, intrinsic and extrinsic of camera-IMU systems, and signal-to-noise ratio). We then perform a system calibration and identification enabling the use of our visual-inertial odometry, multi-sensor fusion, and model predictive control frameworks with the off-the-shelf products. This implies that we can partially avoid tedious parameter tuning procedures for building a full system. The complete system is extensively evaluated both indoors using a motion capture system and outdoors using a laser tracker while performing hover and step responses, and trajectory following tasks in the presence of external wind disturbances. We achieve root-mean-square (RMS) pose errors between a reference and actual trajectories of 0.036m, while performing hover. We also conduct relatively long distance flight (~180m) experiments on a farm site and achieve 0.82% drift error of the total distance flight. This paper conveys the insights we acquired about the platform and sensor module and returns to the community as open-source code with tutorial documentation.
* 21 pages, 10 figures, accepted to IEEE Robotics & Automation Magazine
Fusion++: Volumetric Object-Level SLAM
Aug 28, 2018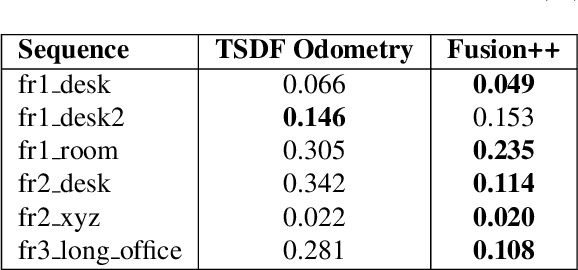
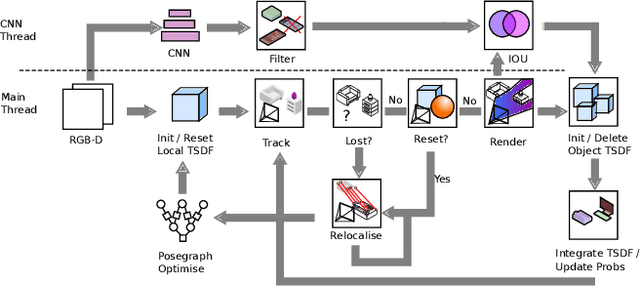
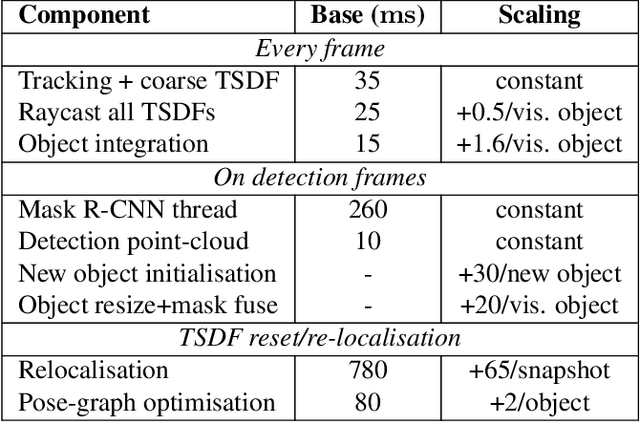
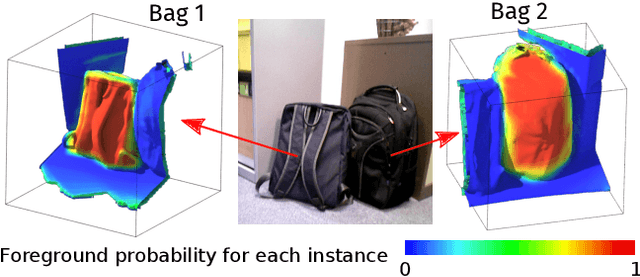
We propose an online object-level SLAM system which builds a persistent and accurate 3D graph map of arbitrary reconstructed objects. As an RGB-D camera browses a cluttered indoor scene, Mask-RCNN instance segmentations are used to initialise compact per-object Truncated Signed Distance Function (TSDF) reconstructions with object size-dependent resolutions and a novel 3D foreground mask. Reconstructed objects are stored in an optimisable 6DoF pose graph which is our only persistent map representation. Objects are incrementally refined via depth fusion, and are used for tracking, relocalisation and loop closure detection. Loop closures cause adjustments in the relative pose estimates of object instances, but no intra-object warping. Each object also carries semantic information which is refined over time and an existence probability to account for spurious instance predictions. We demonstrate our approach on a hand-held RGB-D sequence from a cluttered office scene with a large number and variety of object instances, highlighting how the system closes loops and makes good use of existing objects on repeated loops. We quantitatively evaluate the trajectory error of our system against a baseline approach on the RGB-D SLAM benchmark, and qualitatively compare reconstruction quality of discovered objects on the YCB video dataset. Performance evaluation shows our approach is highly memory efficient and runs online at 4-8Hz (excluding relocalisation) despite not being optimised at the software level.
CodeSLAM - Learning a Compact, Optimisable Representation for Dense Visual SLAM
Apr 03, 2018
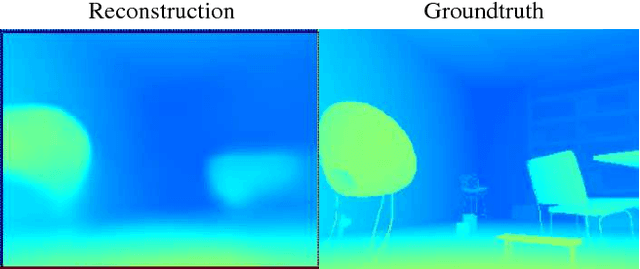
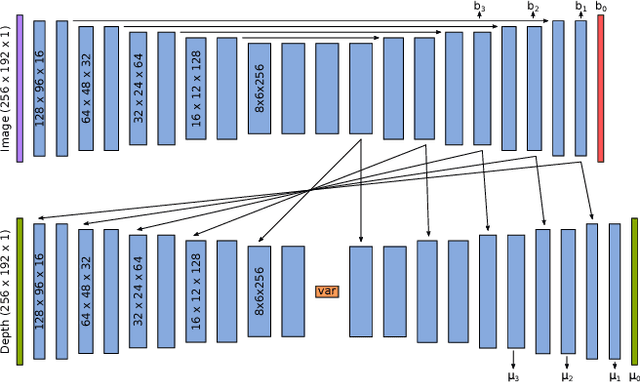
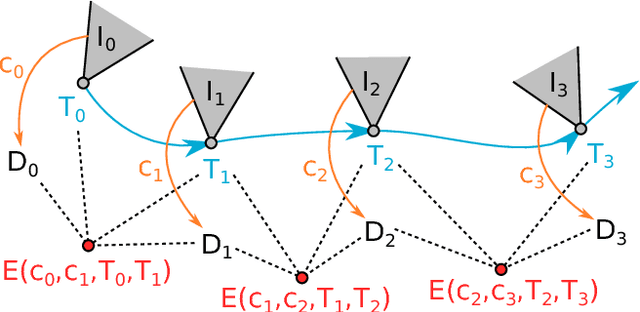
The representation of geometry in real-time 3D perception systems continues to be a critical research issue. Dense maps capture complete surface shape and can be augmented with semantic labels, but their high dimensionality makes them computationally costly to store and process, and unsuitable for rigorous probabilistic inference. Sparse feature-based representations avoid these problems, but capture only partial scene information and are mainly useful for localisation only. We present a new compact but dense representation of scene geometry which is conditioned on the intensity data from a single image and generated from a code consisting of a small number of parameters. We are inspired by work both on learned depth from images, and auto-encoders. Our approach is suitable for use in a keyframe-based monocular dense SLAM system: While each keyframe with a code can produce a depth map, the code can be optimised efficiently jointly with pose variables and together with the codes of overlapping keyframes to attain global consistency. Conditioning the depth map on the image allows the code to only represent aspects of the local geometry which cannot directly be predicted from the image. We explain how to learn our code representation, and demonstrate its advantageous properties in monocular SLAM.