 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Black-Box Optimization
Oct 16, 2024



Black-box optimization algorithms have been widely used in various machine learning problems, including reinforcement learning and prompt fine-tuning. However, directly optimizing the training loss value, as commonly done in existing black-box optimization methods, could lead to suboptimal model quality and generalization performance. To address those problems in black-box optimization, we propose a novel Sharpness-Aware Black-box Optimization (SABO) algorithm, which applies a sharpness-aware minimization strategy to improve the model generalization. Specifically, the proposed SABO method first reparameterizes the objective function by its expectation over a Gaussian distribution. Then it iteratively updates the parameterized distribution by approximated stochastic gradients of the maximum objective value within a small neighborhood around the current solution in the Gaussian distribution space. Theoretically, we prove the convergence rate and generalization bound of the proposed SABO algorithm. Empirically, extensive experiments on the black-box prompt fine-tuning tasks demonstrate the effectiveness of the proposed SABO method in improving model generalization performance.
On Unsupervised Prompt Learning for Classification with Black-box Language Models
Oct 04, 2024



Large language models (LLMs) have achieved impressive success in text-formatted learning problems, and most popular LLMs have been deployed in a black-box fashion. Meanwhile, fine-tuning is usually necessary for a specific downstream task to obtain better performance, and this functionality is provided by the owners of the black-box LLMs. To fine-tune a black-box LLM, labeled data are always required to adjust the model parameters. However, in many real-world applications, LLMs can label textual datasets with even better quality than skilled human annotators, motivating us to explore the possibility of fine-tuning black-box LLMs with unlabeled data. In this paper, we propose unsupervised prompt learning for classification with black-box LLMs, where the learning parameters are the prompt itself and the pseudo labels of unlabeled data. Specifically, the prompt is modeled as a sequence of discrete tokens, and every token has its own to-be-learned categorical distribution. On the other hand, for learning the pseudo labels, we are the first to consider the in-context learning (ICL) capabilities of LLMs: we first identify reliable pseudo-labeled data using the LLM, and then assign pseudo labels to other unlabeled data based on the prompt, allowing the pseudo-labeled data to serve as in-context demonstrations alongside the prompt. Those in-context demonstrations matter: previously, they are involved when the prompt is used for prediction while they are not involved when the prompt is trained; thus, taking them into account during training makes the prompt-learning and prompt-using stages more consistent. Experiments on benchmark datasets show the effectiveness of our proposed algorithm. After unsupervised prompt learning, we can use the pseudo-labeled dataset for further fine-tuning by the owners of the black-box LLMs.
Vision-Language Model Fine-Tuning via Simple Parameter-Efficient Modification
Sep 25, 2024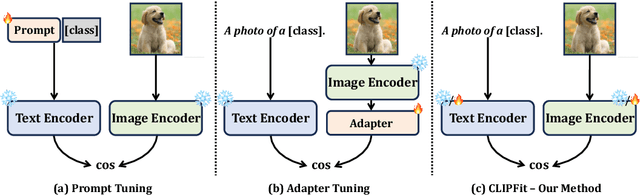



Recent advances in fine-tuning Vision-Language Models (VLMs) have witnessed the success of prompt tuning and adapter tuning, while the classic model fine-tuning on inherent parameters seems to be overlooked. It is believed that fine-tuning the parameters of VLMs with few-shot samples corrupts the pre-trained knowledge since fine-tuning the CLIP model even degrades performance. In this paper, we revisit this viewpoint, and propose a new perspective: fine-tuning the specific parameters instead of all will uncover the power of classic model fine-tuning on VLMs. Through our meticulous study, we propose ClipFit, a simple yet effective method to fine-tune CLIP without introducing any overhead of extra parameters. We demonstrate that by only fine-tuning the specific bias terms and normalization layers, ClipFit can improve the performance of zero-shot CLIP by 7.27\% average harmonic mean accuracy. Lastly, to understand how fine-tuning in CLIPFit affects the pre-trained models, we conducted extensive experimental analyses w.r.t. changes in internal parameters and representations. We found that low-level text bias layers and the first layer normalization layer change much more than other layers. The code is available at \url{https://github.com/minglllli/CLIPFit}.
Dual-Decoupling Learning and Metric-Adaptive Thresholding for Semi-Supervised Multi-Label Learning
Jul 26, 2024



Semi-supervised multi-label learning (SSMLL) is a powerful framework for leveraging unlabeled data to reduce the expensive cost of collecting precise multi-label annotations. Unlike semi-supervised learning, one cannot select the most probable label as the pseudo-label in SSMLL due to multiple semantics contained in an instance. To solve this problem, the mainstream method developed an effective thresholding strategy to generate accurate pseudo-labels. Unfortunately, the method neglected the quality of model predictions and its potential impact on pseudo-labeling performance. In this paper, we propose a dual-perspective method to generate high-quality pseudo-labels. To improve the quality of model predictions, we perform dual-decoupling to boost the learning of correlative and discriminative features, while refining the generation and utilization of pseudo-labels. To obtain proper class-wise thresholds, we propose the metric-adaptive thresholding strategy to estimate the thresholds, which maximize the pseudo-label performance for a given metric on labeled data. Experiments on multiple benchmark datasets show the proposed method can achieve the state-of-the-art performance and outperform the comparative methods with a significant margin.
Unlearning with Control: Assessing Real-world Utility for Large Language Model Unlearning
Jun 13, 2024



The compelling goal of eradicating undesirable data behaviors, while preserving usual model functioning, underscores the significance of machine unlearning within the domain of large language models (LLMs). Recent research has begun to approach LLM unlearning via gradient ascent (GA) -- increasing the prediction risk for those training strings targeted to be unlearned, thereby erasing their parameterized responses. Despite their simplicity and efficiency, we suggest that GA-based methods face the propensity towards excessive unlearning, resulting in various undesirable model behaviors, such as catastrophic forgetting, that diminish their practical utility. In this paper, we suggest a set of metrics that can capture multiple facets of real-world utility and propose several controlling methods that can regulate the extent of excessive unlearning. Accordingly, we suggest a general framework to better reflect the practical efficacy of various unlearning methods -- we begin by controlling the unlearning procedures/unlearned models such that no excessive unlearning occurs and follow by the evaluation for unlearning efficacy. Our experimental analysis on established benchmarks revealed that GA-based methods are far from perfect in practice, as strong unlearning is at the high cost of hindering the model utility. We conclude that there is still a long way towards practical and effective LLM unlearning, and more efforts are required in this field.
Decoupling the Class Label and the Target Concept in Machine Unlearning
Jun 12, 2024



Machine unlearning as an emerging research topic for data regulations, aims to adjust a trained model to approximate a retrained one that excludes a portion of training data. Previous studies showed that class-wise unlearning is successful in forgetting the knowledge of a target class, through gradient ascent on the forgetting data or fine-tuning with the remaining data. However, while these methods are useful, they are insufficient as the class label and the target concept are often considered to coincide. In this work, we decouple them by considering the label domain mismatch and investigate three problems beyond the conventional all matched forgetting, e.g., target mismatch, model mismatch, and data mismatch forgetting. We systematically analyze the new challenges in restrictively forgetting the target concept and also reveal crucial forgetting dynamics in the representation level to realize these tasks. Based on that, we propose a general framework, namely, TARget-aware Forgetting (TARF). It enables the additional tasks to actively forget the target concept while maintaining the rest part, by simultaneously conducting annealed gradient ascent on the forgetting data and selected gradient descent on the hard-to-affect remaining data. Empirically, various experiments under the newly introduced settings are conducted to demonstrate the effectiveness of our TARF.
Slight Corruption in Pre-training Data Makes Better Diffusion Models
May 30, 2024



Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
Locally Estimated Global Perturbations are Better than Local Perturbations for Federated Sharpness-aware Minimization
May 29, 2024



In federated learning (FL), the multi-step update and data heterogeneity among clients often lead to a loss landscape with sharper minima, degenerating the performance of the resulted global model. Prevalent federated approaches incorporate sharpness-aware minimization (SAM) into local training to mitigate this problem. However, the local loss landscapes may not accurately reflect the flatness of global loss landscape in heterogeneous environments; as a result, minimizing local sharpness and calculating perturbations on client data might not align the efficacy of SAM in FL with centralized training. To overcome this challenge, we propose FedLESAM, a novel algorithm that locally estimates the direction of global perturbation on client side as the difference between global models received in the previous active and current rounds. Besides the improved quality, FedLESAM also speed up federated SAM-based approaches since it only performs once backpropagation in each iteration. Theoretically, we prove a slightly tighter bound than its original FedSAM by ensuring consistent perturbation. Empirically, we conduct comprehensive experiments on four federated benchmark datasets under three partition strategies to demonstrate the superior performance and efficiency of FedLESAM.
Multi-Player Approaches for Dueling Bandits
May 25, 2024



Various approaches have emerged for multi-armed bandits in distributed systems. The multiplayer dueling bandit problem, common in scenarios with only preference-based information like human feedback, introduces challenges related to controlling collaborative exploration of non-informative arm pairs, but has received little attention. To fill this gap, we demonstrate that the direct use of a Follow Your Leader black-box approach matches the lower bound for this setting when utilizing known dueling bandit algorithms as a foundation. Additionally, we analyze a message-passing fully distributed approach with a novel Condorcet-winner recommendation protocol, resulting in expedited exploration in many cases. Our experimental comparisons reveal that our multiplayer algorithms surpass single-player benchmark algorithms, underscoring their efficacy in addressing the nuanced challenges of the multiplayer dueling bandit setting.
Offline Reinforcement Learning from Datasets with Structured Non-Stationarity
May 23, 2024



Current Reinforcement Learning (RL) is often limited by the large amount of data needed to learn a successful policy. Offline RL aims to solve this issue by using transitions collected by a different behavior policy. We address a novel Offline RL problem setting in which, while collecting the dataset, the transition and reward functions gradually change between episodes but stay constant within each episode. We propose a method based on Contrastive Predictive Coding that identifies this non-stationarity in the offline dataset, accounts for it when training a policy, and predicts it during evaluation. We analyze our proposed method and show that it performs well in simple continuous control tasks and challenging, high-dimensional locomotion tasks. We show that our method often achieves the oracle performance and performs better than baselines.