 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-dependent Exploration for Online Reinforcement Learning from Human Feedback
May 06, 2026Online reinforcement learning from human feedback (RLHF) has emerged as a promising paradigm for aligning large language models (LLMs) by continuously collecting new preference feedback during training. A foundational challenge in this setting is exploration, which requires algorithms that enable the LLMs to generate informative comparisons that improve sample-efficiency in online RLHF. Existing exploration strategies often derive bonuses via on-policy expectations, which are difficult to estimate reliably from the limited historical preference data available during training; as a result, the policy can prematurely down-weight under-explored regions that may contain high-value behaviors. In this paper, we propose data-dependent exploration for preference optimization (DEPO), a simple and scalable method that leverages historical data to construct an extra uncertainty bonus for high-uncertainty regions, encouraging exploration toward potentially high-value data. Theoretically, we provide a data-dependent regret bound for the proposed algorithm, showing that it adapts to the hardness of the learning task itself and can be tighter than worst-case bounds in practice. Empirically, the proposed method consistently outperforms strong baselines across benchmarks, demonstrating improved sample efficiency.
TreeLoRA: Efficient Continual Learning via Layer-Wise LoRAs Guided by a Hierarchical Gradient-Similarity Tree
Jun 12, 2025Many real-world applications collect data in a streaming environment, where learning tasks are encountered sequentially. This necessitates continual learning (CL) to update models online, enabling adaptation to new tasks while preserving past knowledge to prevent catastrophic forgetting. Nowadays, with the flourish of large pre-trained models (LPMs), efficiency has become increasingly critical for CL, due to their substantial computational demands and growing parameter sizes. In this paper, we introduce TreeLoRA (K-D Tree of Low-Rank Adapters), a novel approach that constructs layer-wise adapters by leveraging hierarchical gradient similarity to enable efficient CL, particularly for LPMs. To reduce the computational burden of task similarity estimation, we employ bandit techniques to develop an algorithm based on lower confidence bounds to efficiently explore the task structure. Furthermore, we use sparse gradient updates to facilitate parameter optimization, making the approach better suited for LPMs. Theoretical analysis is provided to justify the rationale behind our approach, and experiments on both vision transformers (ViTs) and large language models (LLMs) demonstrate the effectiveness and efficiency of our approach across various domains, including vision and natural language processing tasks.
On Unsupervised Prompt Learning for Classification with Black-box Language Models
Oct 04, 2024



Large language models (LLMs) have achieved impressive success in text-formatted learning problems, and most popular LLMs have been deployed in a black-box fashion. Meanwhile, fine-tuning is usually necessary for a specific downstream task to obtain better performance, and this functionality is provided by the owners of the black-box LLMs. To fine-tune a black-box LLM, labeled data are always required to adjust the model parameters. However, in many real-world applications, LLMs can label textual datasets with even better quality than skilled human annotators, motivating us to explore the possibility of fine-tuning black-box LLMs with unlabeled data. In this paper, we propose unsupervised prompt learning for classification with black-box LLMs, where the learning parameters are the prompt itself and the pseudo labels of unlabeled data. Specifically, the prompt is modeled as a sequence of discrete tokens, and every token has its own to-be-learned categorical distribution. On the other hand, for learning the pseudo labels, we are the first to consider the in-context learning (ICL) capabilities of LLMs: we first identify reliable pseudo-labeled data using the LLM, and then assign pseudo labels to other unlabeled data based on the prompt, allowing the pseudo-labeled data to serve as in-context demonstrations alongside the prompt. Those in-context demonstrations matter: previously, they are involved when the prompt is used for prediction while they are not involved when the prompt is trained; thus, taking them into account during training makes the prompt-learning and prompt-using stages more consistent. Experiments on benchmark datasets show the effectiveness of our proposed algorithm. After unsupervised prompt learning, we can use the pseudo-labeled dataset for further fine-tuning by the owners of the black-box LLMs.
Generating Chain-of-Thoughts with a Direct Pairwise-Comparison Approach to Searching for the Most Promising Intermediate Thought
Feb 10, 2024To improve the ability of the large language model (LLMs) to handle complex reasoning problems, chain-of-thoughts (CoT) methods were proposed to guide LLMs to reason step-by-step, facilitating problem solving from simple to complex tasks. State-of-the-art approaches for generating such a chain involve interactive collaboration, where the learner generates candidate intermediate thoughts, evaluated by the LLM, guiding the generation of subsequent thoughts. However, a widespread yet understudied problem is that the evaluation from the LLM is typically noisy and unreliable, potentially misleading the generation process in selecting promising intermediate thoughts. In this paper, motivated by Vapnik's principle, we propose a novel comparison-based CoT generation algorithm that directly identifies the most promising thoughts with the noisy feedback from the LLM. In each round, we randomly pair intermediate thoughts and directly prompt the LLM to select the more promising one from each pair, allowing us to identify the most promising thoughts through an iterative process. To further model the noise in the comparison, we resort to the techniques of ensemble and dueling bandits and propose two variants of the proposed algorithm. Experiments on three real-world mathematical and reasoning tasks demonstrate the effectiveness of our proposed algorithm and verify the rationale of the direct pairwise comparison.
Adapting to Continuous Covariate Shift via Online Density Ratio Estimation
Feb 06, 2023



Dealing with distribution shifts is one of the central challenges for modern machine learning. One fundamental situation is the \emph{covariate shift}, where the input distributions of data change from training to testing stages while the input-conditional output distribution remains unchanged. In this paper, we initiate the study of a more challenging scenario -- \emph{continuous} covariate shift -- in which the test data appear sequentially, and their distributions can shift continuously. Our goal is to adaptively train the predictor such that its prediction risk accumulated over time can be minimized. Starting with the importance-weighted learning, we show the method works effectively if the time-varying density ratios of test and train inputs can be accurately estimated. However, existing density ratio estimation methods would fail due to data scarcity at each time step. To this end, we propose an online method that can appropriately reuse historical information. Our density ratio estimation method is proven to perform well by enjoying a dynamic regret bound, which finally leads to an excess risk guarantee for the predictor. Empirical results also validate the effectiveness.
Early Abnormal Detection of Sewage Pipe Network: Bagging of Various Abnormal Detection Algorithms
Jun 06, 2022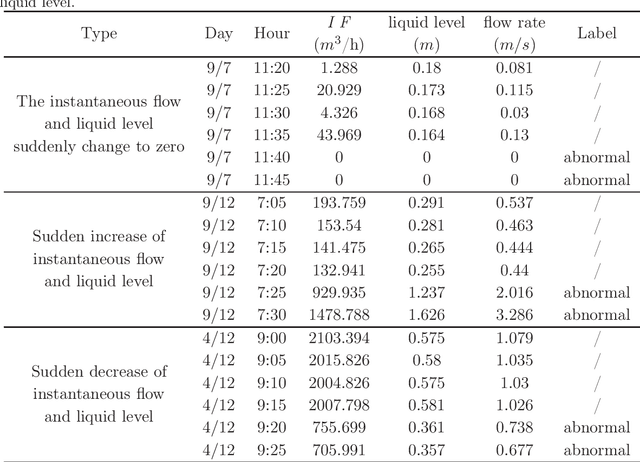
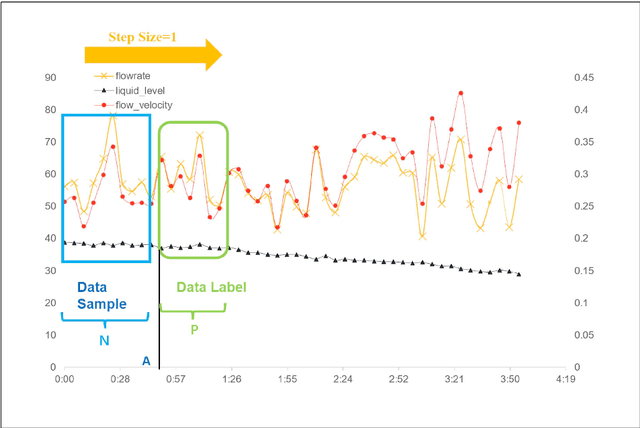
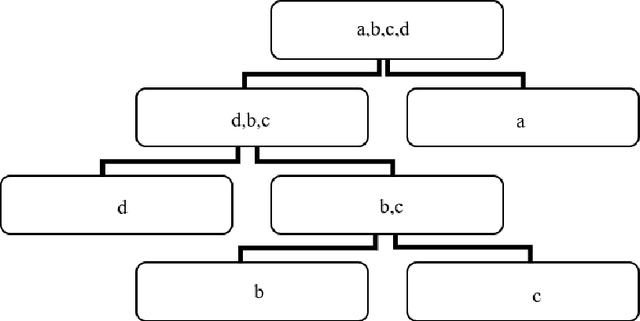
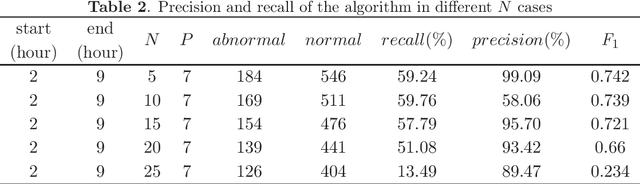
Abnormalities of the sewage pipe network will affect the normal operation of the whole city. Therefore, it is important to detect the abnormalities early. This paper propose an early abnormal-detection method. The abnormalities are detected by using the conventional algorithms, such as isolation forest algorithm, two innovations are given: (1) The current and historical data measured by the sensors placed in the sewage pipe network (such as ultrasonic Doppler flowmeter) are taken as the overall dataset, and then the general dataset is detected by using the conventional anomaly detection method to diagnose the anomaly of the data. The anomaly refers to the sample different from the others samples in the whole dataset. Because the definition of anomaly is not through the algorithm, but the whole dataset, the construction of the whole dataset is the key to propose the early abnormal-detection algorithms. (2) A bagging strategy for a variety of conventional anomaly detection algorithms is proposed to achieve the early detection of anomalies with the high precision and recall. The results show that this method can achieve the early anomaly detection with the highest precision of 98.21%, the recall rate 63.58% and F1-score of 0.774.