 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020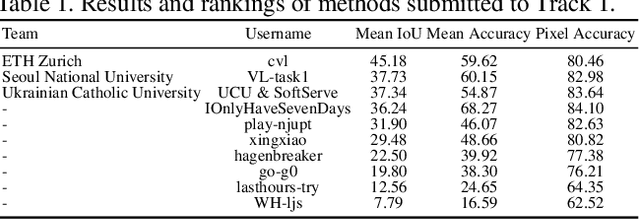
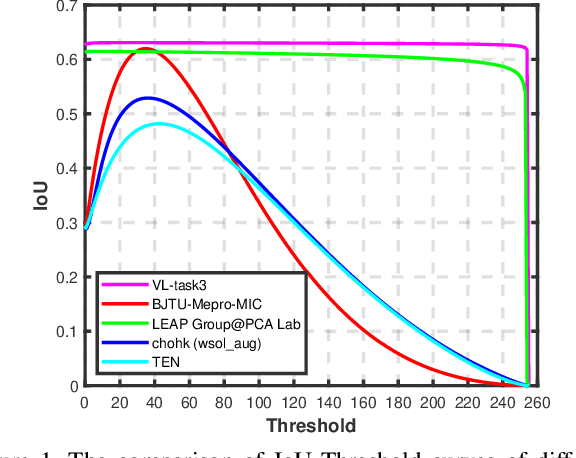

Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
Self-Supervised Ranking for Representation Learning
Oct 14, 2020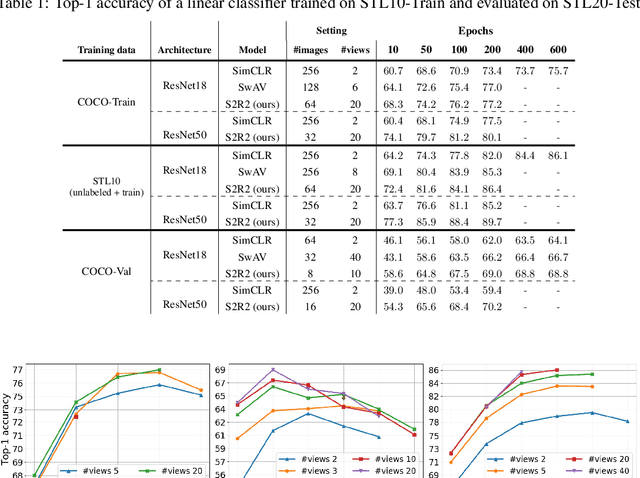
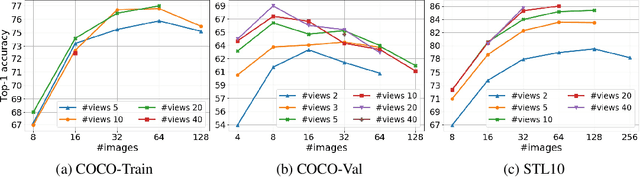
We present a new framework for self-supervised representation learning by positing it as a ranking problem in an image retrieval context on a large number of random views from random sets of images. Our work is based on two intuitive observations: first, a good representation of images must yield a high-quality image ranking in a retrieval task; second, we would expect random views of an image to be ranked closer to a reference view of that image than random views of other images. Hence, we model representation learning as a learning-to-rank problem in an image retrieval context, and train it by maximizing average precision (AP) for ranking. Specifically, given a mini-batch of images, we generate a large number of positive/negative samples and calculate a ranking loss term by separately treating each image view as a retrieval query. The new framework, dubbed S2R2, enables computing a global objective compared to the local objective in the popular contrastive learning framework calculated on pairs of views. A global objective leads S2R2 to faster convergence in terms of the number of epochs. In principle, by using a ranking criterion, we eliminate reliance on object-centered curated datasets (e.g., ImageNet). When trained on STL10 and MS-COCO, S2R2 outperforms SimCLR and performs on par with the state-of-the-art clustering-based contrastive learning model, SwAV, while being much simpler both conceptually and implementation-wise. Furthermore, when trained on a small subset of MS-COCO with fewer similar scenes, S2R2 significantly outperforms both SwAV and SimCLR. This indicates that S2R2 is potentially more effective on diverse scenes and decreases the need for a large training dataset for self-supervised learning.
SMILE: Semantically-guided Multi-attribute Image and Layout Editing
Oct 05, 2020
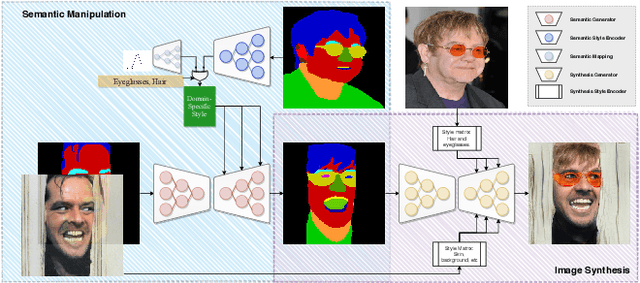

Attribute image manipulation has been a very active topic since the introduction of Generative Adversarial Networks (GANs). Exploring the disentangled attribute space within a transformation is a very challenging task due to the multiple and mutually-inclusive nature of the facial images, where different labels (eyeglasses, hats, hair, identity, etc.) can co-exist at the same time. Several works address this issue either by exploiting the modality of each domain/attribute using a conditional random vector noise, or extracting the modality from an exemplary image. However, existing methods cannot handle both random and reference transformations for multiple attributes, which limits the generality of the solutions. In this paper, we successfully exploit a multimodal representation that handles all attributes, be it guided by random noise or exemplar images, while only using the underlying domain information of the target domain. We present extensive qualitative and quantitative results for facial datasets and several different attributes that show the superiority of our method. Additionally, our method is capable of adding, removing or changing either fine-grained or coarse attributes by using an image as a reference or by exploring the style distribution space, and it can be easily extended to head-swapping and face-reenactment applications without being trained on videos.
Few-Shot Classification By Few-Iteration Meta-Learning
Oct 01, 2020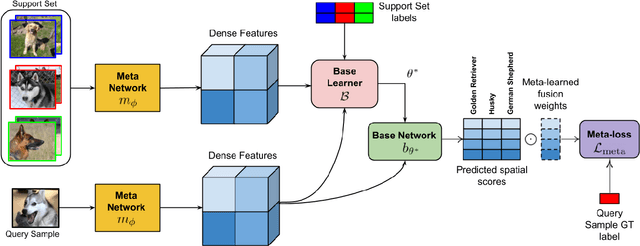
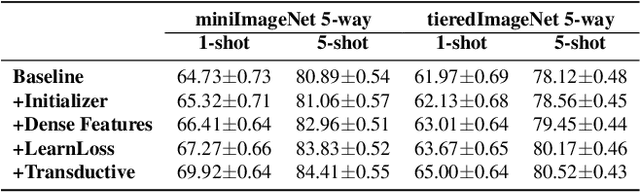

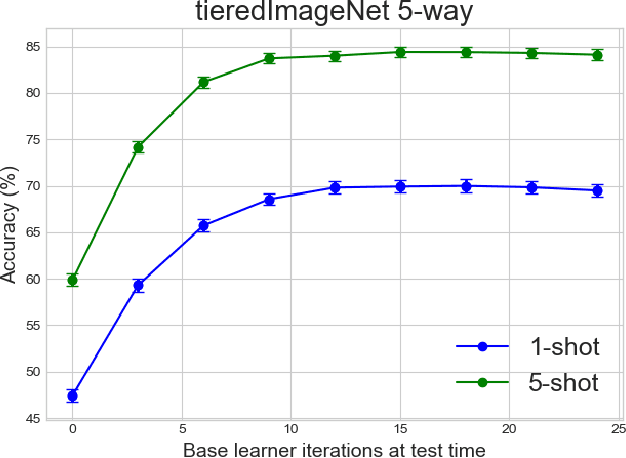
Learning in a low-data regime from only a few labeled examples is an important, but challenging problem. Recent advancements within meta-learning have demonstrated encouraging performance, in particular, for the task of few-shot classification. We propose a novel optimization-based meta-learning approach for few-shot classification. It consists of an embedding network, providing a general representation of the image, and a base learner module. The latter learns a linear classifier during the inference through an unrolled optimization procedure. We design an inner learning objective composed of (i) a robust classification loss on the support set and (ii) an entropy loss, allowing transductive learning from unlabeled query samples. By employing an efficient initialization module and a Steepest Descent based optimization algorithm, our base learner predicts a powerful classifier within only a few iterations. Further, our strategy enables important aspects of the base learner objective to be learned during meta-training. To the best of our knowledge, this work is the first to integrate both induction and transduction into the base learner in an optimization-based meta-learning framework. We perform a comprehensive experimental analysis, demonstrating the effectiveness of our approach on four few-shot classification datasets.
Depth Estimation from Monocular Images and Sparse Radar Data
Sep 30, 2020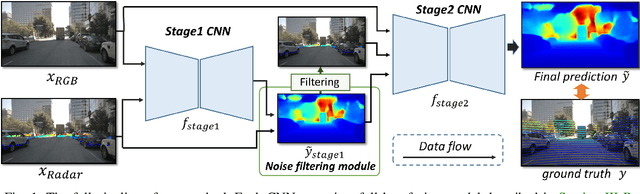
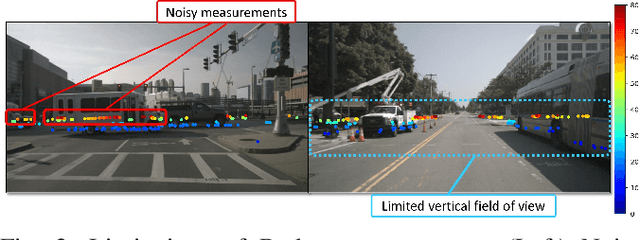
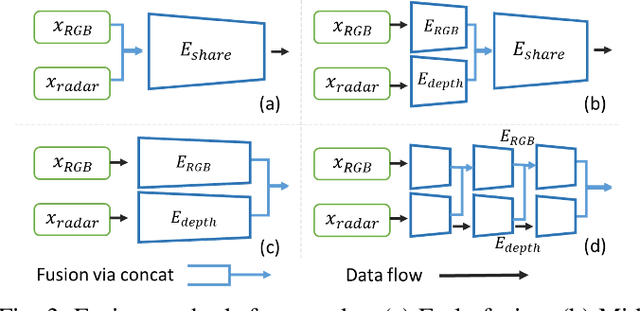

In this paper, we explore the possibility of achieving a more accurate depth estimation by fusing monocular images and Radar points using a deep neural network. We give a comprehensive study of the fusion between RGB images and Radar measurements from different aspects and proposed a working solution based on the observations. We find that the noise existing in Radar measurements is one of the main key reasons that prevents one from applying the existing fusion methods developed for LiDAR data and images to the new fusion problem between Radar data and images. The experiments are conducted on the nuScenes dataset, which is one of the first datasets which features Camera, Radar, and LiDAR recordings in diverse scenes and weather conditions. Extensive experiments demonstrate that our method outperforms existing fusion methods. We also provide detailed ablation studies to show the effectiveness of each component in our method.
Improving Point Cloud Semantic Segmentation by Learning 3D Object Proposal Generation
Sep 23, 2020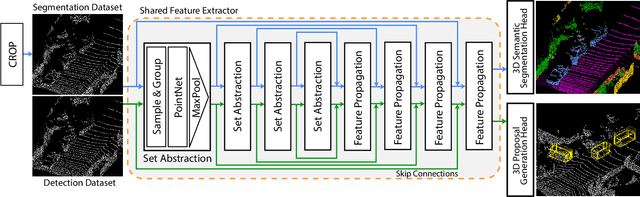
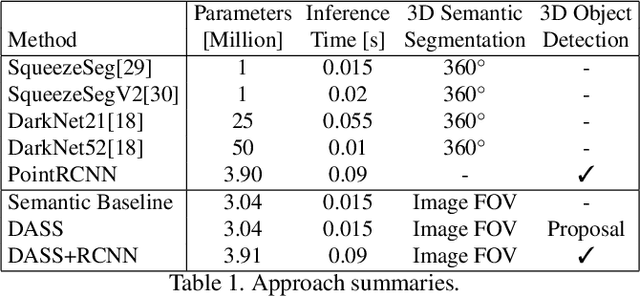
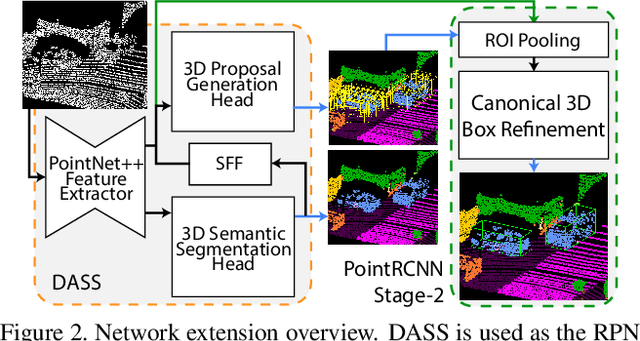
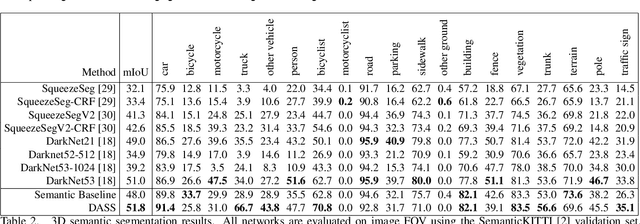
Point cloud semantic segmentation plays an essential role in autonomous driving, providing vital information about drivable surfaces and nearby objects that can aid higher level tasks such as path planning and collision avoidance. While current 3D semantic segmentation networks focus on convolutional architectures that perform great for well represented classes, they show a significant drop in performance for underrepresented classes that share similar geometric features. We propose a novel Detection Aware 3D Semantic Segmentation (DASS) framework that explicitly leverages localization features from an auxiliary 3D object detection task. By utilizing multitask training, the shared feature representation of the network is guided to be aware of per class detection features that aid tackling the differentiation of geometrically similar classes. We additionally provide a pipeline that uses DASS to generate high recall proposals for existing 2-stage detectors and demonstrate that the added supervisory signal can be used to improve 3D orientation estimation capabilities. Extensive experiments on both the SemanticKITTI and KITTI object datasets show that DASS can improve 3D semantic segmentation results of geometrically similar classes up to 37.8% IoU in image FOV while maintaining high precision BEV detection results.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
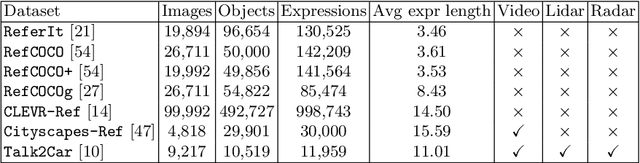

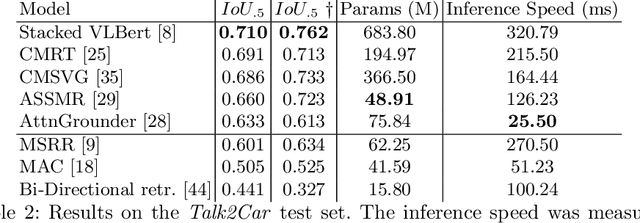
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.
GOCor: Bringing Globally Optimized Correspondence Volumes into Your Neural Network
Sep 16, 2020
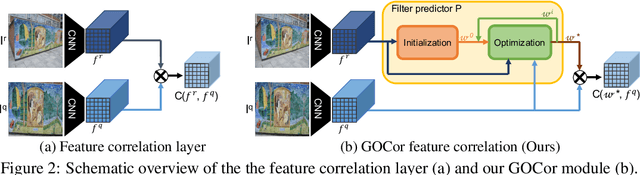
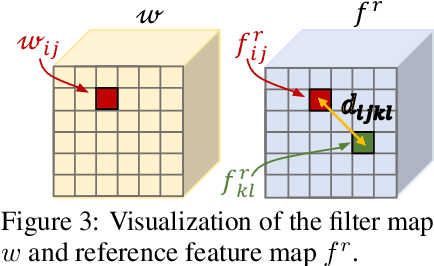
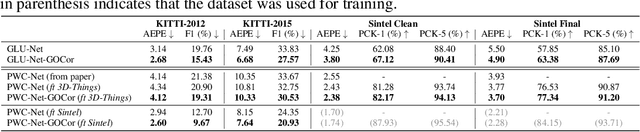
The feature correlation layer serves as a key neural network module in numerous computer vision problems that involve dense correspondences between image pairs. It predicts a correspondence volume by evaluating dense scalar products between feature vectors extracted from pairs of locations in two images. However, this point-to-point feature comparison is insufficient when disambiguating multiple similar regions in an image, severely affecting the performance of the end task. We propose GOCor, a fully differentiable dense matching module, acting as a direct replacement to the feature correlation layer. The correspondence volume generated by our module is the result of an internal optimization procedure that explicitly accounts for similar regions in the scene. Moreover, our approach is capable of effectively learning spatial matching priors to resolve further matching ambiguities. We analyze our GOCor module in extensive ablative experiments. When integrated into state-of-the-art networks, our approach significantly outperforms the feature correlation layer for the tasks of geometric matching, optical flow, and dense semantic matching. The code and trained models will be made available at github.com/PruneTruong/GOCor.
Plug-and-Play Image Restoration with Deep Denoiser Prior
Aug 31, 2020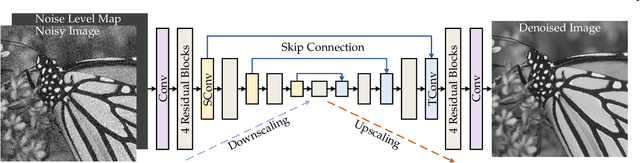


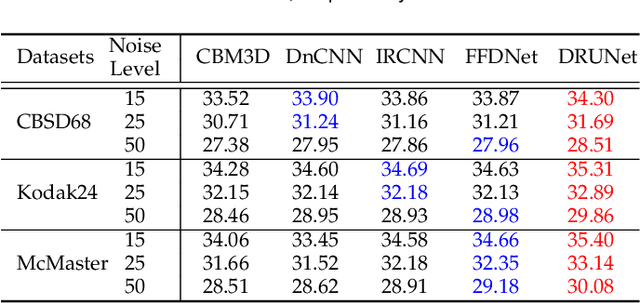
Recent works on plug-and-play image restoration have shown that a denoiser can implicitly serve as the image prior for model-based methods to solve many inverse problems. Such a property induces considerable advantages for plug-and-play image restoration (e.g., integrating the flexibility of model-based method and effectiveness of learning-based methods) when the denoiser is discriminatively learned via deep convolutional neural network (CNN) with large modeling capacity. However, while deeper and larger CNN models are rapidly gaining popularity, existing plug-and-play image restoration hinders its performance due to the lack of suitable denoiser prior. In order to push the limits of plug-and-play image restoration, we set up a benchmark deep denoiser prior by training a highly flexible and effective CNN denoiser. We then plug the deep denoiser prior as a modular part into a half quadratic splitting based iterative algorithm to solve various image restoration problems. We, meanwhile, provide a thorough analysis of parameter setting, intermediate results and empirical convergence to better understand the working mechanism. Experimental results on three representative image restoration tasks, including deblurring, super-resolution and demosaicing, demonstrate that the proposed plug-and-play image restoration with deep denoiser prior not only significantly outperforms other state-of-the-art model-based methods but also achieves competitive or even superior performance against state-of-the-art learning-based methods. The source code is available at https://github.com/cszn/DPIR.
Learning Condition Invariant Features for Retrieval-Based Localization from 1M Images
Aug 27, 2020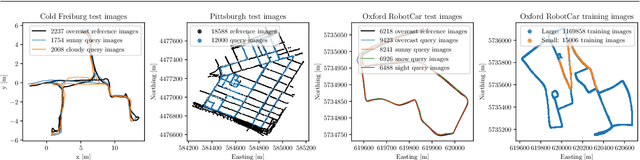

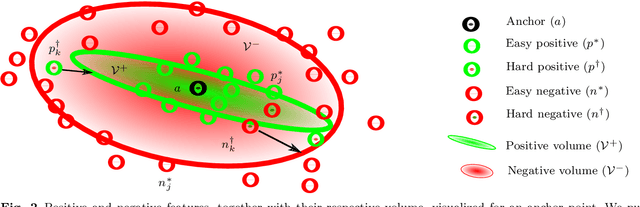
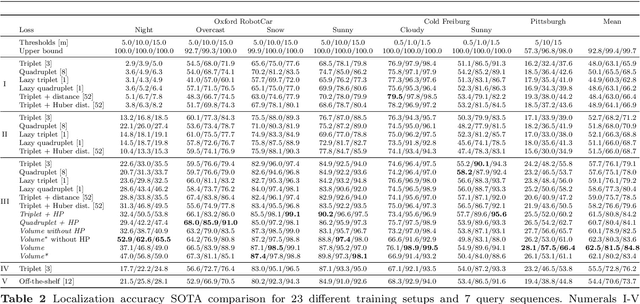
Image features for retrieval-based localization must be invariant to dynamic objects (e.g. cars) as well as seasonal and daytime changes. Such invariances are, up to some extent, learnable with existing methods using triplet-like losses, given a large number of diverse training images. However, due to the high algorithmic training complexity, there exists insufficient comparison between different loss functions on large datasets. In this paper, we train and evaluate several localization methods on three different benchmark datasets, including Oxford RobotCar with over one million images. This large scale evaluation yields valuable insights into the generalizability and performance of retrieval-based localization. Based on our findings, we develop a novel method for learning more accurate and better generalizing localization features. It consists of two main contributions: (i) a feature volume-based loss function, and (ii) hard positive and pairwise negative mining. On the challenging Oxford RobotCar night condition, our method outperforms the well-known triplet loss by 24.4% in localization accuracy within 5m.