 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCoNet+: A Stronger Group Collaborative Co-Salient Object Detector
Jun 01, 2022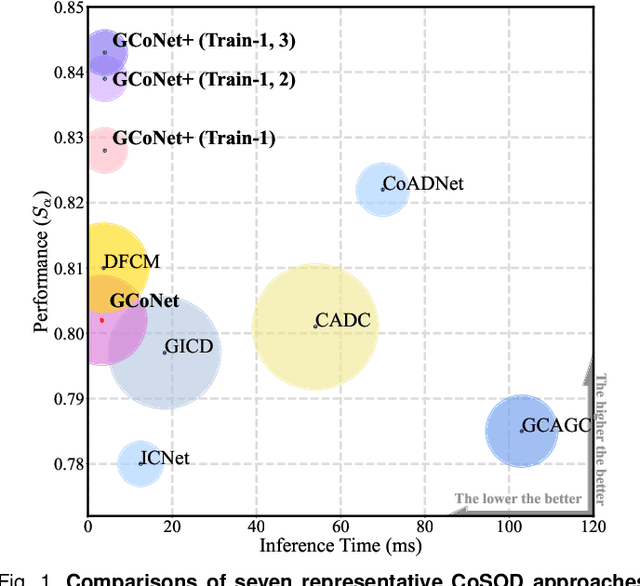



In this paper, we present a novel end-to-end group collaborative learning network, termed GCoNet+, which can effectively and efficiently (250 fps) identify co-salient objects in natural scenes. The proposed GCoNet+ achieves the new state-of-the-art performance for co-salient object detection (CoSOD) through mining consensus representations based on the following two essential criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module (GAM); 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module (GCM) conditioning on the inconsistent consensus. To further improve the accuracy, we design a series of simple yet effective components as follows: i) a recurrent auxiliary classification module (RACM) promoting the model learning at the semantic level; ii) a confidence enhancement module (CEM) helping the model to improve the quality of the final predictions; and iii) a group-based symmetric triplet (GST) loss guiding the model to learn more discriminative features. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and CoSal2015, demonstrate that our GCoNet+ outperforms the existing 12 cutting-edge models. Code has been released at https://github.com/ZhengPeng7/GCoNet_plus.
Deep Gradient Learning for Efficient Camouflaged Object Detection
May 25, 2022
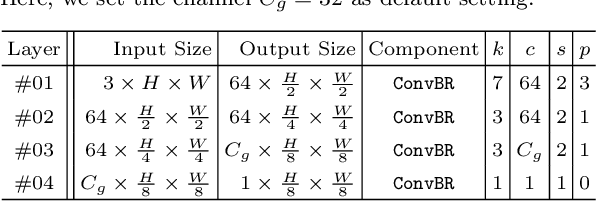

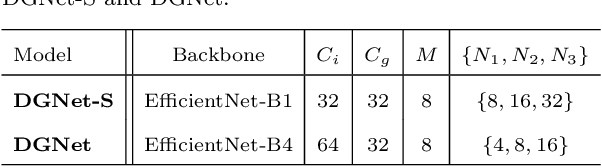
This paper introduces DGNet, a novel deep framework that exploits object gradient supervision for camouflaged object detection (COD). It decouples the task into two connected branches, i.e., a context and a texture encoder. The essential connection is the gradient-induced transition, representing a soft grouping between context and texture features. Benefiting from the simple but efficient framework, DGNet outperforms existing state-of-the-art COD models by a large margin. Notably, our efficient version, DGNet-S, runs in real-time (80 fps) and achieves comparable results to the cutting-edge model JCSOD-CVPR$_{21}$ with only 6.82% parameters. Application results also show that the proposed DGNet performs well in polyp segmentation, defect detection, and transparent object segmentation tasks. Codes will be made available at https://github.com/GewelsJI/DGNet.
Unsupervised Flow-Aligned Sequence-to-Sequence Learning for Video Restoration
May 20, 2022
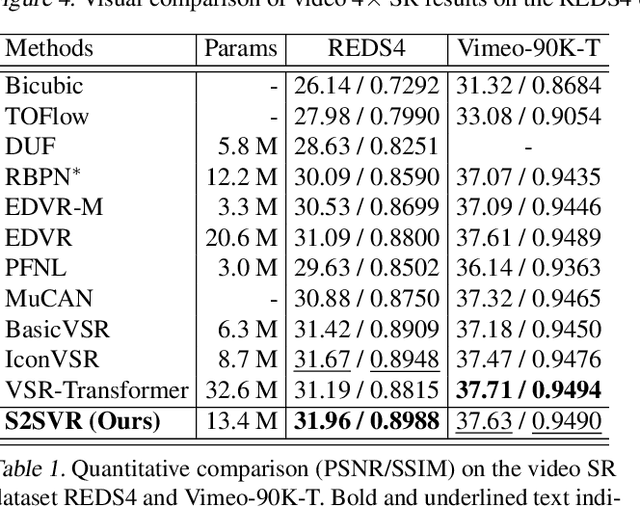
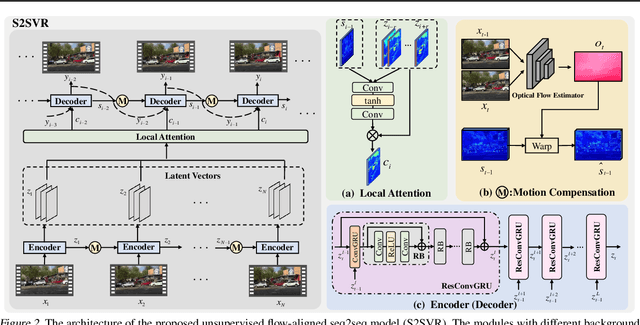
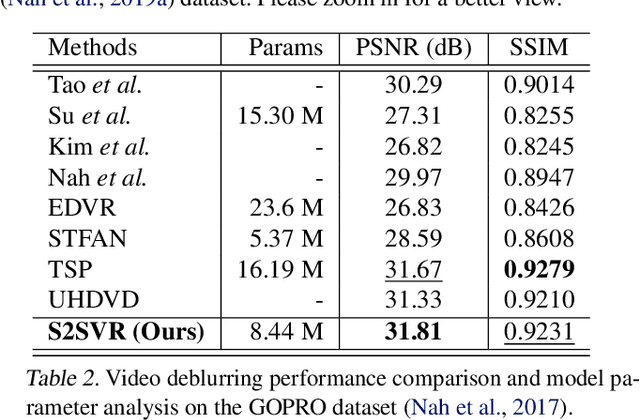
How to properly model the inter-frame relation within the video sequence is an important but unsolved challenge for video restoration (VR). In this work, we propose an unsupervised flow-aligned sequence-to-sequence model (S2SVR) to address this problem. On the one hand, the sequence-to-sequence model, which has proven capable of sequence modeling in the field of natural language processing, is explored for the first time in VR. Optimized serialization modeling shows potential in capturing long-range dependencies among frames. On the other hand, we equip the sequence-to-sequence model with an unsupervised optical flow estimator to maximize its potential. The flow estimator is trained with our proposed unsupervised distillation loss, which can alleviate the data discrepancy and inaccurate degraded optical flow issues of previous flow-based methods. With reliable optical flow, we can establish accurate correspondence among multiple frames, narrowing the domain difference between 1D language and 2D misaligned frames and improving the potential of the sequence-to-sequence model. S2SVR shows superior performance in multiple VR tasks, including video deblurring, video super-resolution, and compressed video quality enhancement. Code and models are publicly available at https://github.com/linjing7/VR-Baseline
Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging
May 20, 2022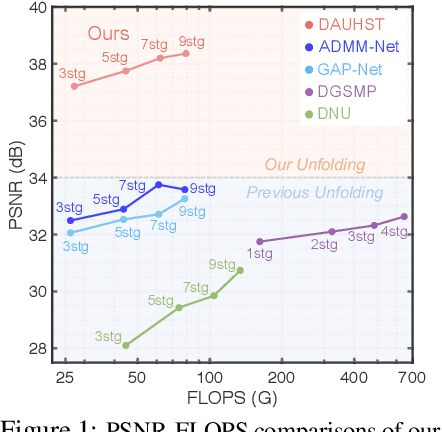
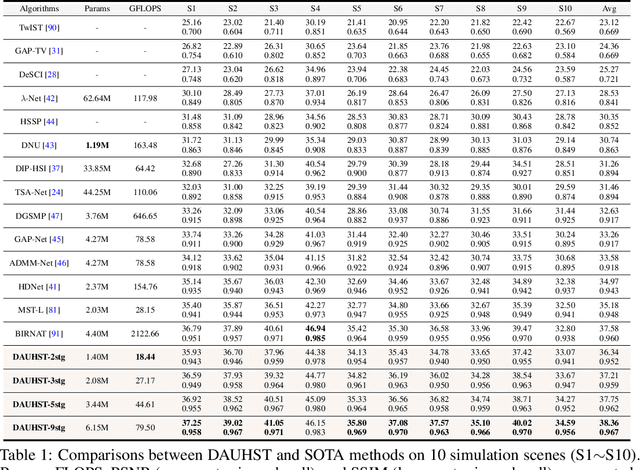
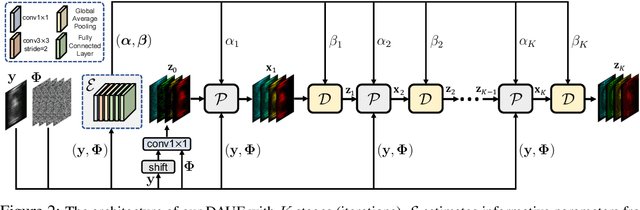
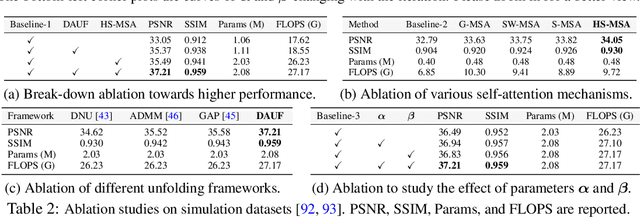
In coded aperture snapshot spectral compressive imaging (CASSI) systems, hyperspectral image (HSI) reconstruction methods are employed to recover the spatial-spectral signal from a compressed measurement. Among these algorithms, deep unfolding methods demonstrate promising performance but suffer from two issues. Firstly, they do not estimate the degradation patterns and ill-posedness degree from the highly related CASSI to guide the iterative learning. Secondly, they are mainly CNN-based, showing limitations in capturing long-range dependencies. In this paper, we propose a principled Degradation-Aware Unfolding Framework (DAUF) that estimates parameters from the compressed image and physical mask, and then uses these parameters to control each iteration. Moreover, we customize a novel Half-Shuffle Transformer (HST) that simultaneously captures local contents and non-local dependencies. By plugging HST into DAUF, we establish the first Transformer-based deep unfolding method, Degradation-Aware Unfolding Half-Shuffle Transformer (DAUHST), for HSI reconstruction. Experiments show that DAUHST significantly surpasses state-of-the-art methods while requiring cheaper computational and memory costs. Code and models will be released to the public.
A Continual Deepfake Detection Benchmark: Dataset, Methods, and Essentials
May 14, 2022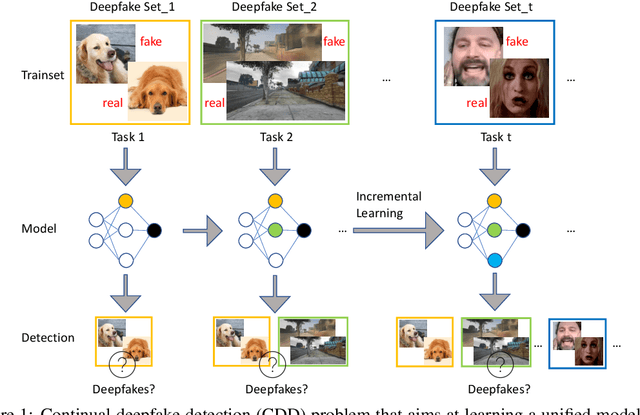

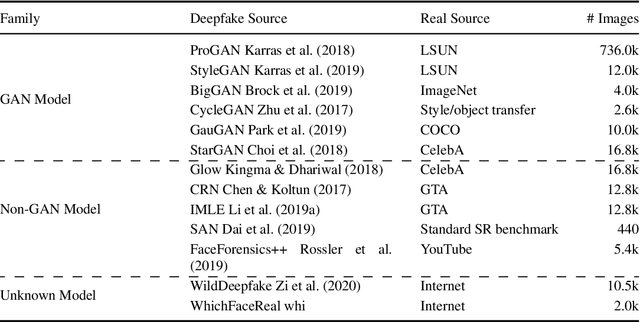
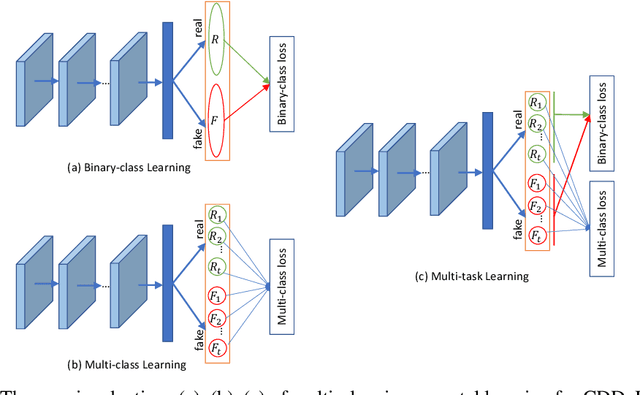
There have been emerging a number of benchmarks and techniques for the detection of deepfakes. However, very few works study the detection of incrementally appearing deepfakes in the real-world scenarios. To simulate the wild scenes, this paper suggests a continual deepfake detection benchmark (CDDB) over a new collection of deepfakes from both known and unknown generative models. The suggested CDDB designs multiple evaluations on the detection over easy, hard, and long sequence of deepfake tasks, with a set of appropriate measures. In addition, we exploit multiple approaches to adapt multiclass incremental learning methods, commonly used in the continual visual recognition, to the continual deepfake detection problem. We evaluate several methods, including the adapted ones, on the proposed CDDB. Within the proposed benchmark, we explore some commonly known essentials of standard continual learning. Our study provides new insights on these essentials in the context of continual deepfake detection. The suggested CDDB is clearly more challenging than the existing benchmarks, which thus offers a suitable evaluation avenue to the future research. Our benchmark dataset and the source code will be made publicly available.
Revisiting Random Channel Pruning for Neural Network Compression
May 11, 2022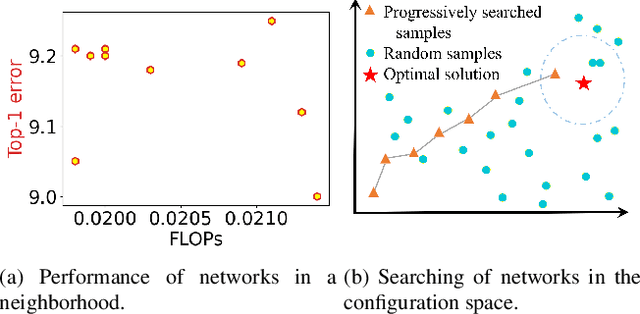
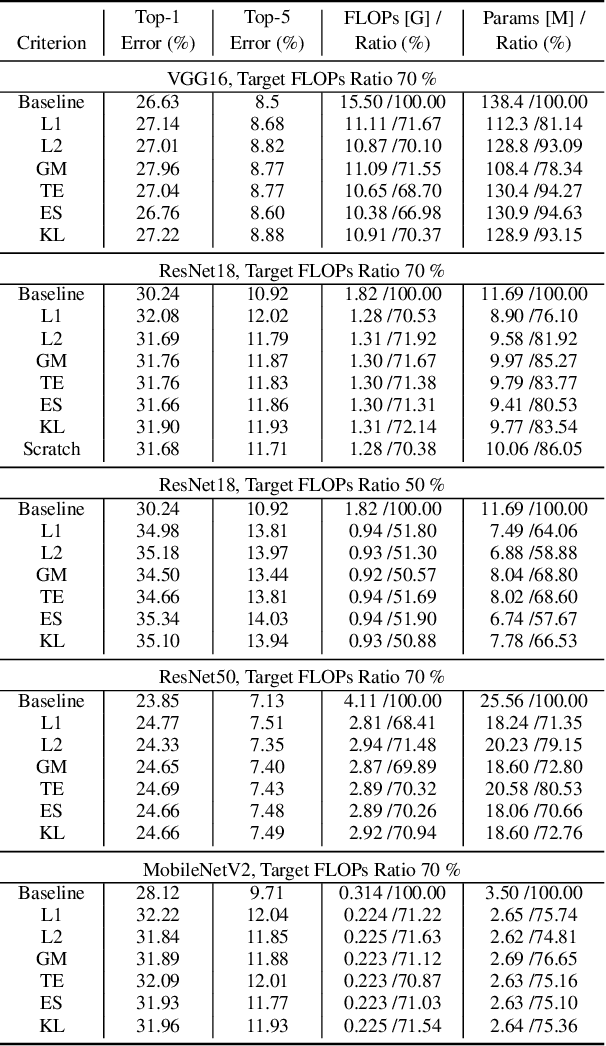
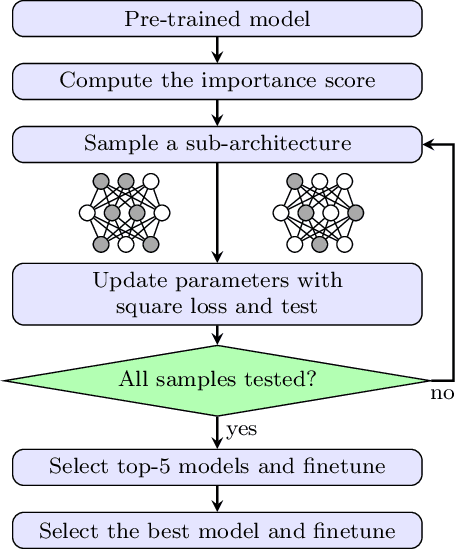
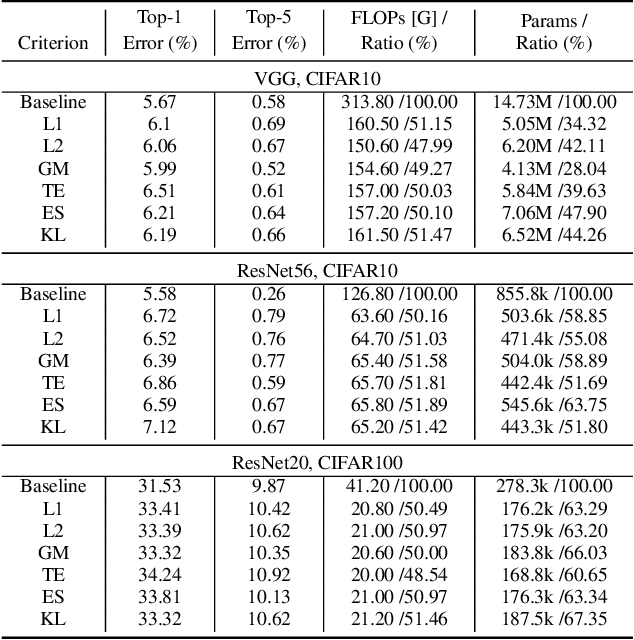
Channel (or 3D filter) pruning serves as an effective way to accelerate the inference of neural networks. There has been a flurry of algorithms that try to solve this practical problem, each being claimed effective in some ways. Yet, a benchmark to compare those algorithms directly is lacking, mainly due to the complexity of the algorithms and some custom settings such as the particular network configuration or training procedure. A fair benchmark is important for the further development of channel pruning. Meanwhile, recent investigations reveal that the channel configurations discovered by pruning algorithms are at least as important as the pre-trained weights. This gives channel pruning a new role, namely searching the optimal channel configuration. In this paper, we try to determine the channel configuration of the pruned models by random search. The proposed approach provides a new way to compare different methods, namely how well they behave compared with random pruning. We show that this simple strategy works quite well compared with other channel pruning methods. We also show that under this setting, there are surprisingly no clear winners among different channel importance evaluation methods, which then may tilt the research efforts into advanced channel configuration searching methods.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
Apr 27, 2022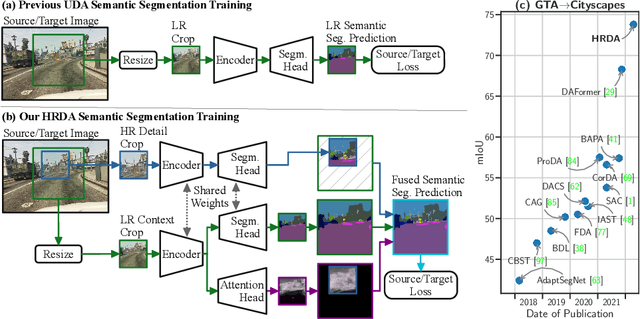
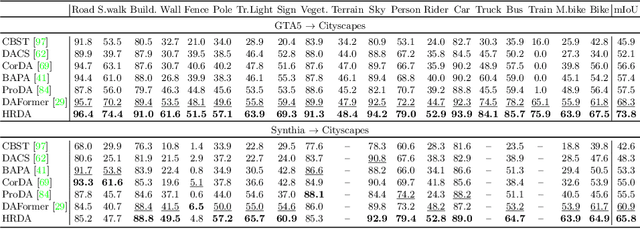
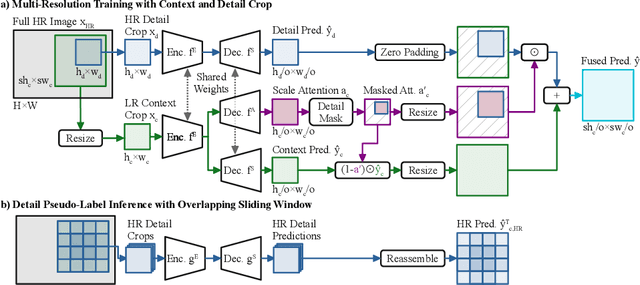
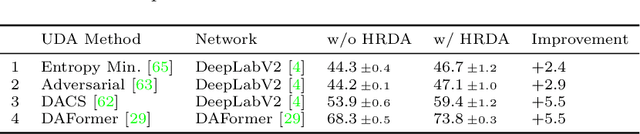
Unsupervised domain adaptation (UDA) aims to adapt a model trained on the source domain (e.g. synthetic data) to the target domain (e.g. real-world data) without requiring further annotations on the target domain. This work focuses on UDA for semantic segmentation as real-world pixel-wise annotations are particularly expensive to acquire. As UDA methods for semantic segmentation are usually GPU memory intensive, most previous methods operate only on downscaled images. We question this design as low-resolution predictions often fail to preserve fine details. The alternative of training with random crops of high-resolution images alleviates this problem but falls short in capturing long-range, domain-robust context information. Therefore, we propose HRDA, a multi-resolution training approach for UDA, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention, while maintaining a manageable GPU memory footprint. HRDA enables adapting small objects and preserving fine segmentation details. It significantly improves the state-of-the-art performance by 5.5 mIoU for GTA-to-Cityscapes and 4.9 mIoU for Synthia-to-Cityscapes, resulting in unprecedented 73.8 and 65.8 mIoU, respectively. The implementation is available at https://github.com/lhoyer/HRDA.
MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction
Apr 17, 2022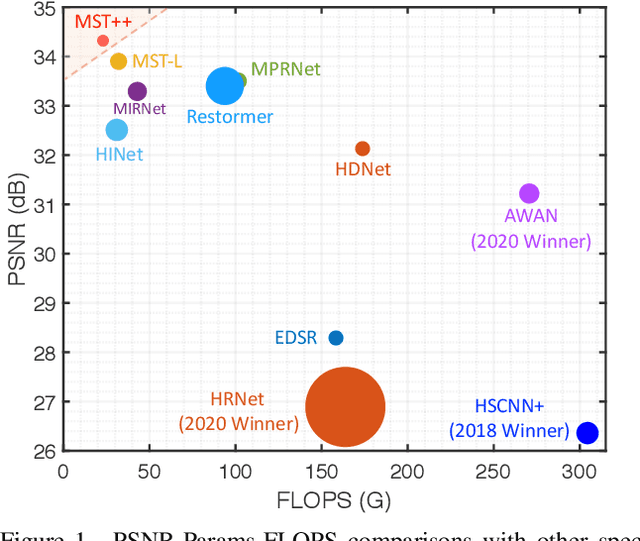
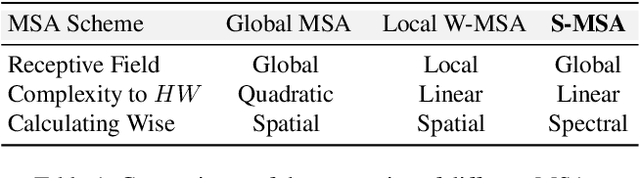
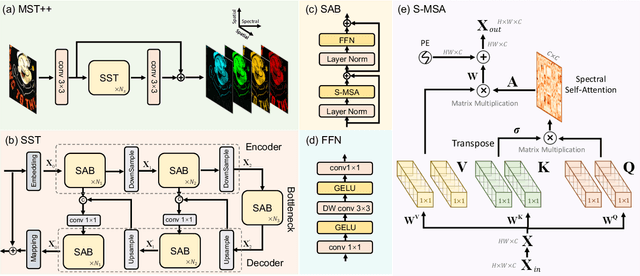
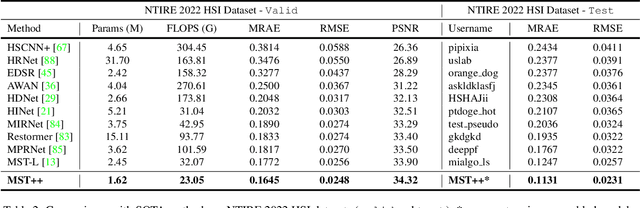
Existing leading methods for spectral reconstruction (SR) focus on designing deeper or wider convolutional neural networks (CNNs) to learn the end-to-end mapping from the RGB image to its hyperspectral image (HSI). These CNN-based methods achieve impressive restoration performance while showing limitations in capturing the long-range dependencies and self-similarity prior. To cope with this problem, we propose a novel Transformer-based method, Multi-stage Spectral-wise Transformer (MST++), for efficient spectral reconstruction. In particular, we employ Spectral-wise Multi-head Self-attention (S-MSA) that is based on the HSI spatially sparse while spectrally self-similar nature to compose the basic unit, Spectral-wise Attention Block (SAB). Then SABs build up Single-stage Spectral-wise Transformer (SST) that exploits a U-shaped structure to extract multi-resolution contextual information. Finally, our MST++, cascaded by several SSTs, progressively improves the reconstruction quality from coarse to fine. Comprehensive experiments show that our MST++ significantly outperforms other state-of-the-art methods. In the NTIRE 2022 Spectral Reconstruction Challenge, our approach won the First place. Code and pre-trained models are publicly available at https://github.com/caiyuanhao1998/MST-plus-plus.
* Winner of NTIRE 2022 Challenge on Spectral Reconstruction from RGB; The First Transformer-based Method for Spectral Reconstruction
Neural Vector Fields for Surface Representation and Inference
Apr 13, 2022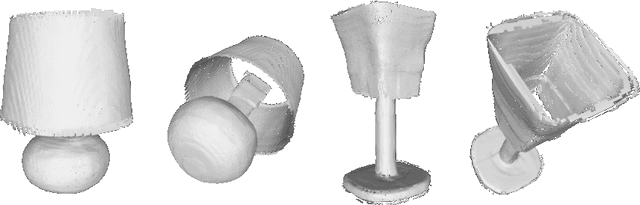
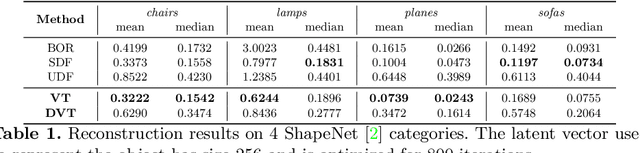
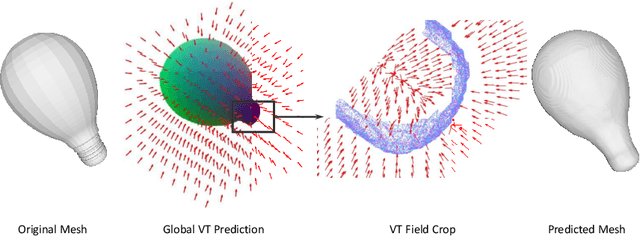
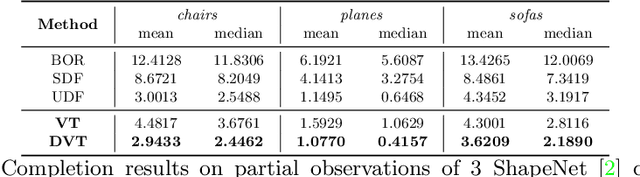
Neural implicit fields have recently been shown to represent 3D shapes accurately, opening up various applications in 3D shape analysis. Up to now, such implicit fields for 3D representation are scalar, encoding the signed distance or binary volume occupancy and more recently the unsigned distance. However, the first two can only represent closed shapes, while the unsigned distance has difficulties in accurate and fast shape inference. In this paper, we propose a Neural Vector Field for shape representation in order to overcome the two aforementioned problems. Mapping each point in space to the direction towards the closest surface, we can represent any type of shape. Similarly the shape mesh can be reconstructed by applying the marching cubes algorithm, with proposed small changes, on top of the inferred vector field. We compare the method on ShapeNet where the proposed new neural implicit field shows superior accuracy in representing both closed and open shapes outperforming previous methods.