 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSAP: Rethinking Inversion Fidelity, Perception and Editability in GAN Latent Space
Sep 26, 2022
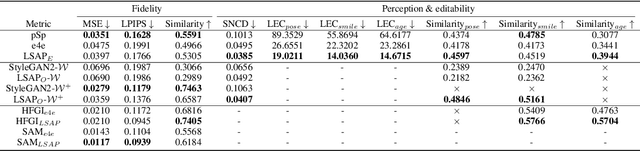
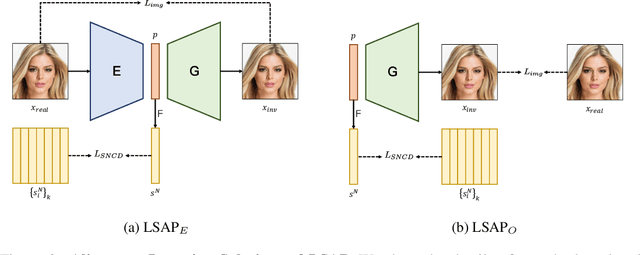
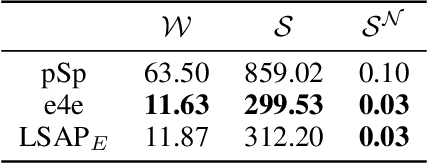
As the methods evolve, inversion is mainly divided into two steps. The first step is Image Embedding, in which an encoder or optimization process embeds images to get the corresponding latent codes. Afterward, the second step aims to refine the inversion and editing results, which we named Result Refinement. Although the second step significantly improves fidelity, perception and editability are almost unchanged, deeply dependent on inverse latent codes attained in the first step. Therefore, a crucial problem is gaining the latent codes with better perception and editability while retaining the reconstruction fidelity. In this work, we first point out that these two characteristics are related to the degree of alignment (or disalignment) of the inverse codes with the synthetic distribution. Then, we propose Latent Space Alignment Inversion Paradigm (LSAP), which consists of evaluation metric and solution for this problem. Specifically, we introduce Normalized Style Space ($\mathcal{S^N}$ space) and $\mathcal{S^N}$ Cosine Distance (SNCD) to measure disalignment of inversion methods. Since our proposed SNCD is differentiable, it can be optimized in both encoder-based and optimization-based embedding methods to conduct a uniform solution. Extensive experiments in various domains demonstrate that SNCD effectively reflects perception and editability, and our alignment paradigm archives the state-of-the-art in both two steps. Code is available on https://github.com/caopulan/GANInverter.
SQ-SLAM: Monocular Semantic SLAM Based on Superquadric Object Representation
Sep 22, 2022
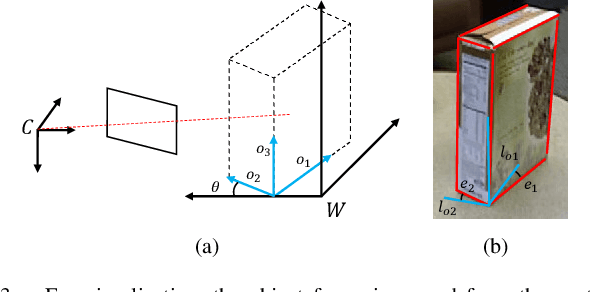
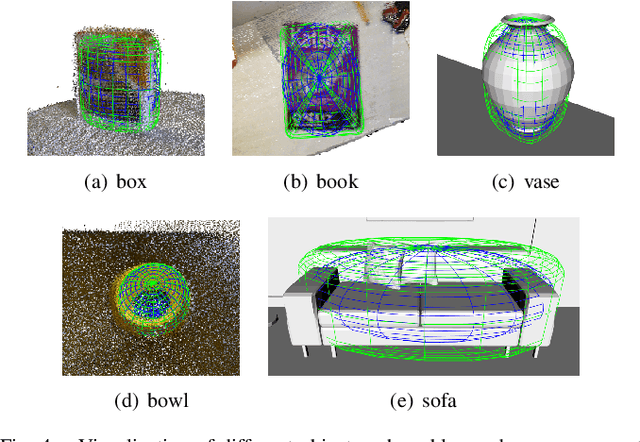
Object SLAM uses additional semantic information to detect and map objects in the scene, in order to improve the system's perception and map representation capabilities. Quadrics and cubes are often used to represent objects, but their single shape limits the accuracy of object map and thus affects the application of downstream tasks. In this paper, we introduce superquadrics (SQ) with shape parameters into SLAM for representing objects, and propose a separate parameter estimation method that can accurately estimate object pose and adapt to different shapes. Furthermore, we present a lightweight data association strategy for correctly associating semantic observations in multiple views with object landmarks. We implement a monocular semantic SLAM system with real-time performance and conduct comprehensive experiments on public datasets. The results show that our method is able to build accurate object map and has advantages in object representation. Code will be released upon acceptance.
TOSE: A Fast Capacity Estimation Algorithm Based on Spike Approximations
Sep 02, 2022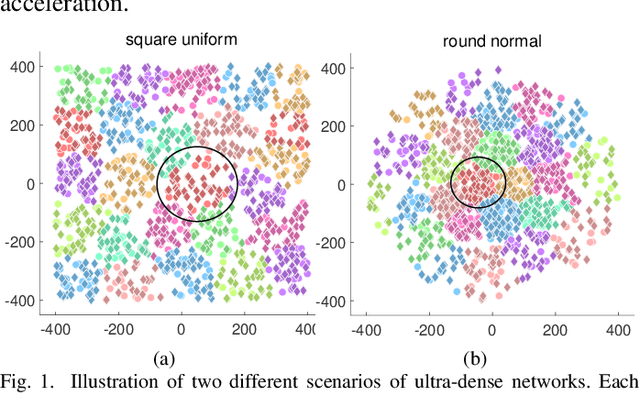
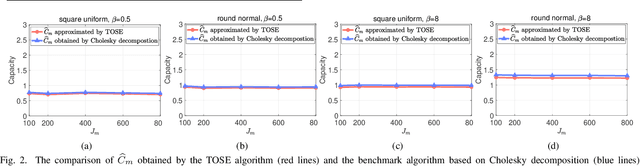
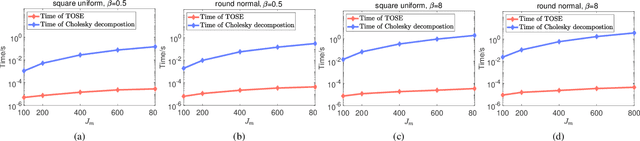
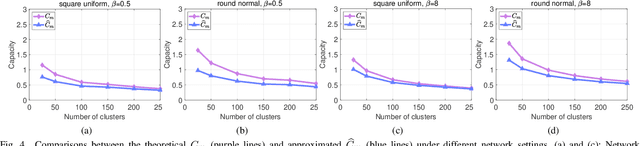
Capacity is one of the most important performance metrics for wireless communication networks. It describes the maximum rate at which the information can be transmitted of a wireless communication system. To support the growing demand for wireless traffic, wireless networks are becoming more dense and complicated, leading to a higher difficulty to derive the capacity. Unfortunately, most existing methods for the capacity calculation take a polynomial time complexity. This will become unaffordable for future ultra-dense networks, where both the number of base stations (BSs) and the number of users are extremely large. In this paper, we propose a fast algorithm TOSE to estimate the capacity for ultra-dense wireless networks. Based on the spiked model of random matrix theory (RMT), our algorithm can avoid the exact eigenvalue derivations of large dimensional matrices, which are complicated and inevitable in conventional capacity calculation methods. Instead, fast eigenvalue estimations can be realized based on the spike approximations in our TOSE algorithm. Our simulation results show that TOSE is an accurate and fast capacity approximation algorithm. Its estimation error is below 5%, and it runs in linear time, which is much lower than the polynomial time complexity of existing methods. In addition, TOSE has superior generality, since it is independent of the distributions of BSs and users, and the shape of network areas.
* 6 pages, 4 figures. arXiv admin note: text overlap with arXiv:2204.03393
POPDx: An Automated Framework for Patient Phenotyping across 392,246 Individuals in the UK Biobank Study
Aug 23, 2022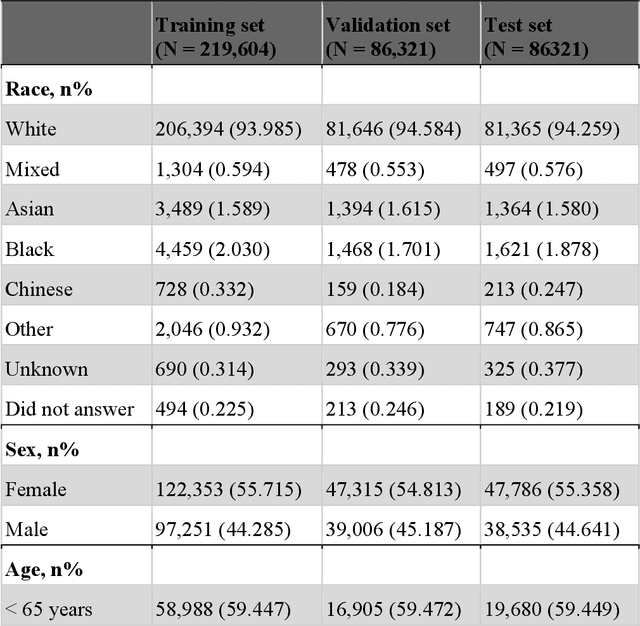
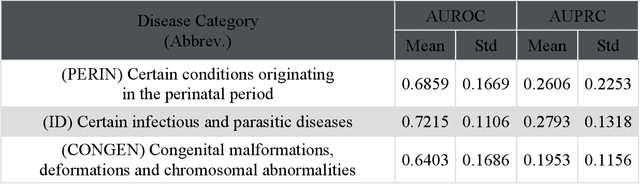
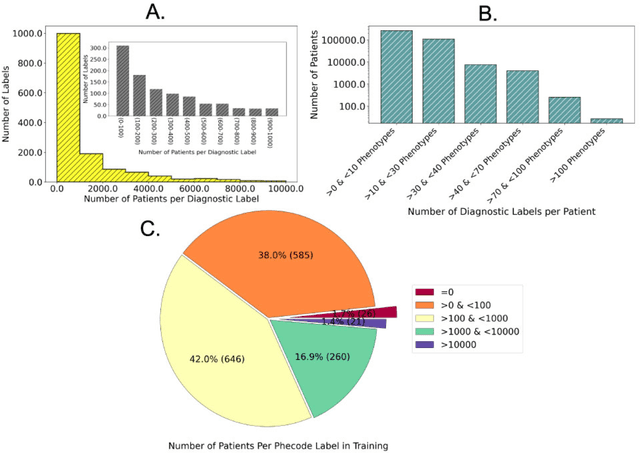
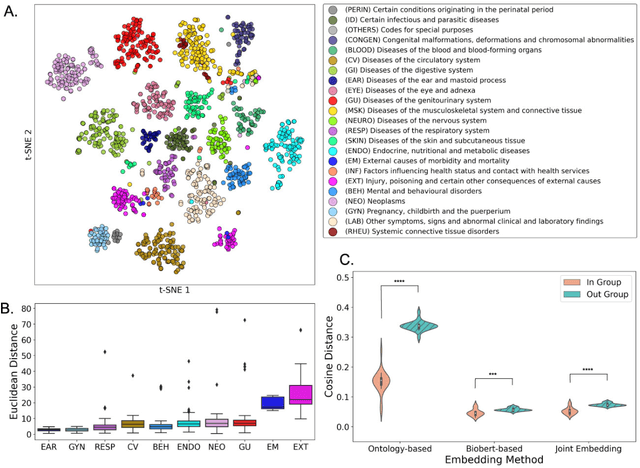
Objective For the UK Biobank standardized phenotype codes are associated with patients who have been hospitalized but are missing for many patients who have been treated exclusively in an outpatient setting. We describe a method for phenotype recognition that imputes phenotype codes for all UK Biobank participants. Materials and Methods POPDx (Population-based Objective Phenotyping by Deep Extrapolation) is a bilinear machine learning framework for simultaneously estimating the probabilities of 1,538 phenotype codes. We extracted phenotypic and health-related information of 392,246 individuals from the UK Biobank for POPDx development and evaluation. A total of 12,803 ICD-10 diagnosis codes of the patients were converted to 1,538 Phecodes as gold standard labels. The POPDx framework was evaluated and compared to other available methods on automated multi-phenotype recognition. Results POPDx can predict phenotypes that are rare or even unobserved in training. We demonstrate substantial improvement of automated multi-phenotype recognition across 22 disease categories, and its application in identifying key epidemiological features associated with each phenotype. Conclusions POPDx helps provide well-defined cohorts for downstream studies. It is a general purpose method that can be applied to other biobanks with diverse but incomplete data.
Clustered Cell-Free Networking: A Graph Partitioning Approach
Jul 24, 2022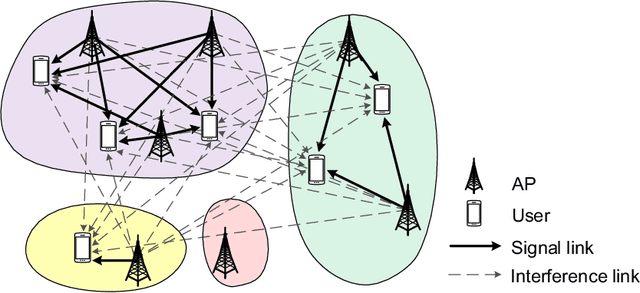
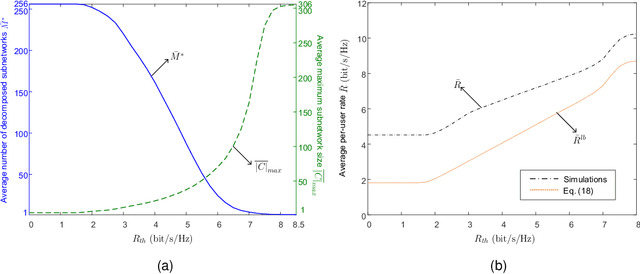

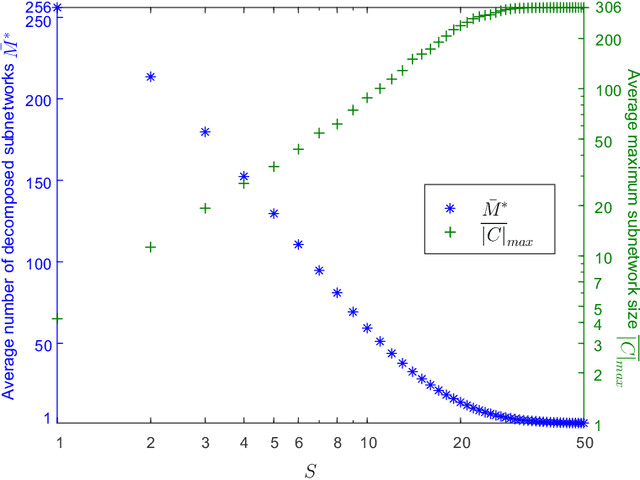
By moving to millimeter wave (mmWave) frequencies, base stations (BSs) will be densely deployed to provide seamless coverage in sixth generation (6G) mobile communication systems, which, unfortunately, leads to severe cell-edge problem. In addition, with massive multiple-input-multiple-output (MIMO) antenna arrays employed at BSs, the beamspace channel is sparse for each user, and thus there is no need to serve all the users in a cell by all the beams therein jointly. Therefore, it is of paramount importance to develop a flexible clustered cell-free networking scheme that can decompose the whole network into a number of weakly interfered small subnetworks operating independently and in parallel. Given a per-user rate constraint for service quality guarantee, this paper aims to maximize the number of decomposed subnetworks so as to reduce the signaling overhead and system complexity as much as possible. By formulating it as a bipartite graph partitioning problem, a rate-constrained network decomposition (RC-NetDecomp) algorithm is proposed, which can smoothly tune the network structure from the current cellular network with simple beam allocation to a fully cooperative network by increasing the required per-user rate. Simulation results demonstrate that the proposed RC-NetDecomp algorithm outperforms existing baselines in terms of average per-user rate, fairness among users and energy efficiency.
A Survey on Long-Tailed Visual Recognition
May 27, 2022The heavy reliance on data is one of the major reasons that currently limit the development of deep learning. Data quality directly dominates the effect of deep learning models, and the long-tailed distribution is one of the factors affecting data quality. The long-tailed phenomenon is prevalent due to the prevalence of power law in nature. In this case, the performance of deep learning models is often dominated by the head classes while the learning of the tail classes is severely underdeveloped. In order to learn adequately for all classes, many researchers have studied and preliminarily addressed the long-tailed problem. In this survey, we focus on the problems caused by long-tailed data distribution, sort out the representative long-tailed visual recognition datasets and summarize some mainstream long-tailed studies. Specifically, we summarize these studies into ten categories from the perspective of representation learning, and outline the highlights and limitations of each category. Besides, we have studied four quantitative metrics for evaluating the imbalance, and suggest using the Gini coefficient to evaluate the long-tailedness of a dataset. Based on the Gini coefficient, we quantitatively study 20 widely-used and large-scale visual datasets proposed in the last decade, and find that the long-tailed phenomenon is widespread and has not been fully studied. Finally, we provide several future directions for the development of long-tailed learning to provide more ideas for readers.
Locality-Aware Inter-and Intra-Video Reconstruction for Self-Supervised Correspondence Learning
Mar 29, 2022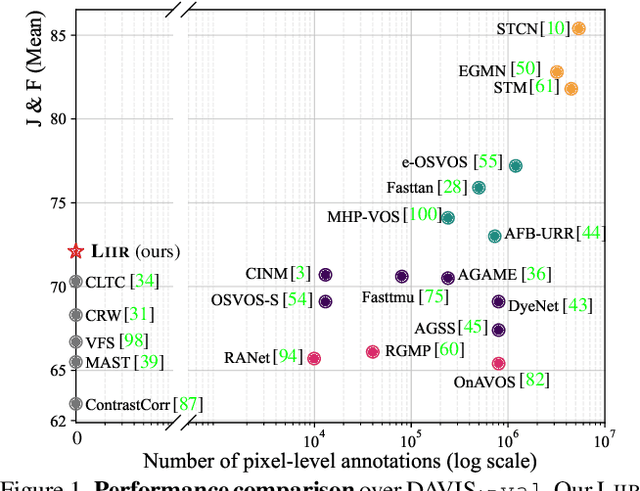
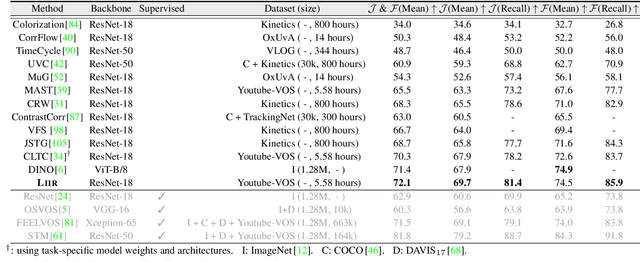
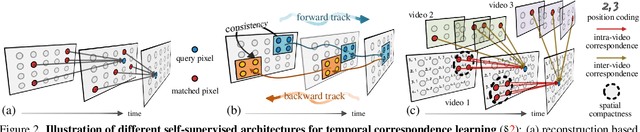
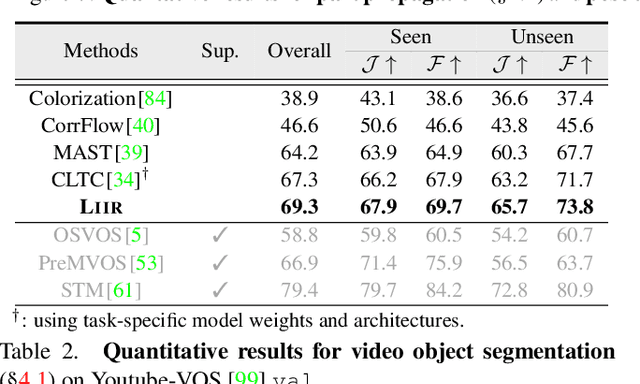
Our target is to learn visual correspondence from unlabeled videos. We develop LIIR, a locality-aware inter-and intra-video reconstruction framework that fills in three missing pieces, i.e., instance discrimination, location awareness, and spatial compactness, of self-supervised correspondence learning puzzle. First, instead of most existing efforts focusing on intra-video self-supervision only, we exploit cross video affinities as extra negative samples within a unified, inter-and intra-video reconstruction scheme. This enables instance discriminative representation learning by contrasting desired intra-video pixel association against negative inter-video correspondence. Second, we merge position information into correspondence matching, and design a position shifting strategy to remove the side-effect of position encoding during inter-video affinity computation, making our LIIR location-sensitive. Third, to make full use of the spatial continuity nature of video data, we impose a compactness-based constraint on correspondence matching, yielding more sparse and reliable solutions. The learned representation surpasses self-supervised state-of-the-arts on label propagation tasks including objects, semantic parts, and keypoints.
Multi-Domain Joint Training for Person Re-Identification
Jan 06, 2022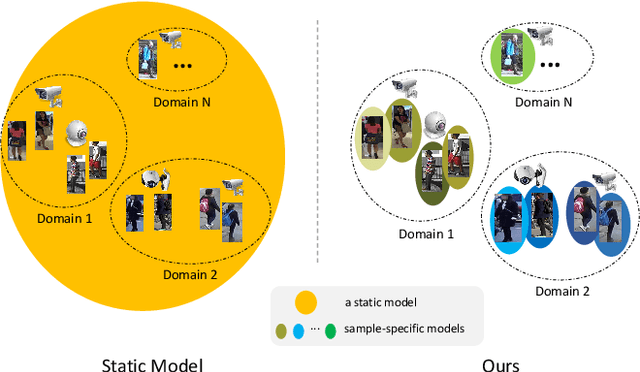

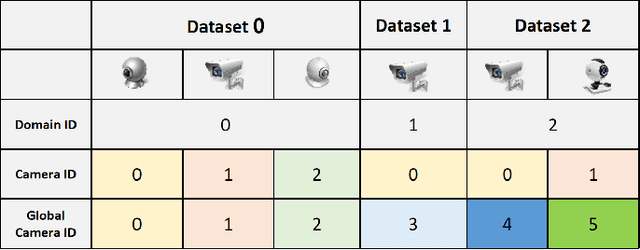
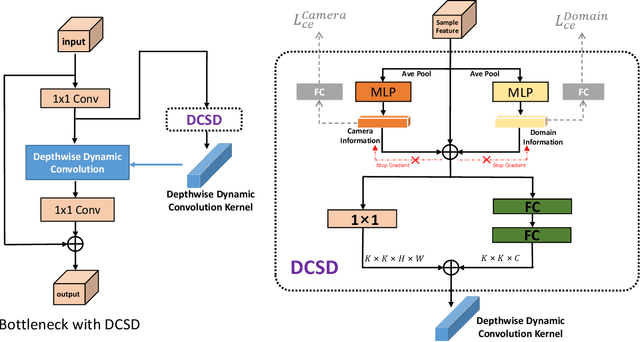
Deep learning-based person Re-IDentification (ReID) often requires a large amount of training data to achieve good performance. Thus it appears that collecting more training data from diverse environments tends to improve the ReID performance. This paper re-examines this common belief and makes a somehow surprising observation: using more samples, i.e., training with samples from multiple datasets, does not necessarily lead to better performance by using the popular ReID models. In some cases, training with more samples may even hurt the performance of the evaluation is carried out in one of those datasets. We postulate that this phenomenon is due to the incapability of the standard network in adapting to diverse environments. To overcome this issue, we propose an approach called Domain-Camera-Sample Dynamic network (DCSD) whose parameters can be adaptive to various factors. Specifically, we consider the internal domain-related factor that can be identified from the input features, and external domain-related factors, such as domain information or camera information. Our discovery is that training with such an adaptive model can better benefit from more training samples. Experimental results show that our DCSD can greatly boost the performance (up to 12.3%) while joint training in multiple datasets.
Multi-initialization Optimization Network for Accurate 3D Human Pose and Shape Estimation
Dec 24, 2021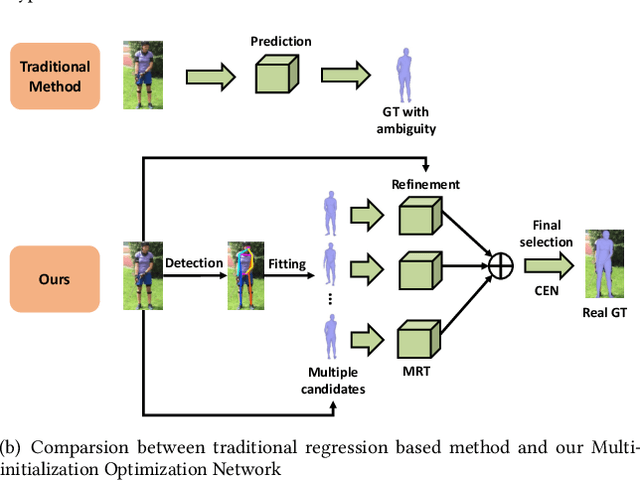
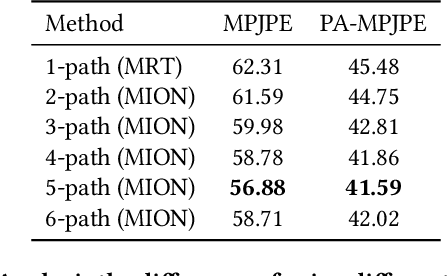

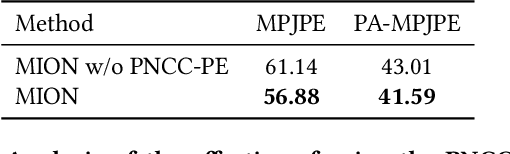
3D human pose and shape recovery from a monocular RGB image is a challenging task. Existing learning based methods highly depend on weak supervision signals, e.g. 2D and 3D joint location, due to the lack of in-the-wild paired 3D supervision. However, considering the 2D-to-3D ambiguities existed in these weak supervision labels, the network is easy to get stuck in local optima when trained with such labels. In this paper, we reduce the ambituity by optimizing multiple initializations. Specifically, we propose a three-stage framework named Multi-Initialization Optimization Network (MION). In the first stage, we strategically select different coarse 3D reconstruction candidates which are compatible with the 2D keypoints of input sample. Each coarse reconstruction can be regarded as an initialization leads to one optimization branch. In the second stage, we design a mesh refinement transformer (MRT) to respectively refine each coarse reconstruction result via a self-attention mechanism. Finally, a Consistency Estimation Network (CEN) is proposed to find the best result from mutiple candidates by evaluating if the visual evidence in RGB image matches a given 3D reconstruction. Experiments demonstrate that our Multi-Initialization Optimization Network outperforms existing 3D mesh based methods on multiple public benchmarks.
Quality-Aware Network for Face Parsing
Jun 14, 2021
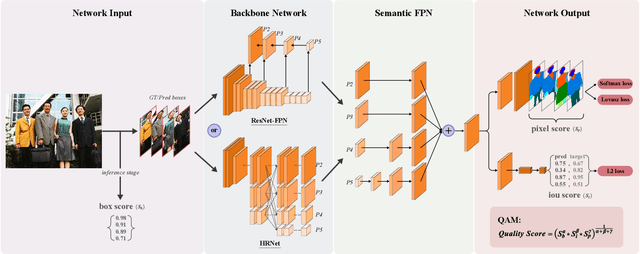
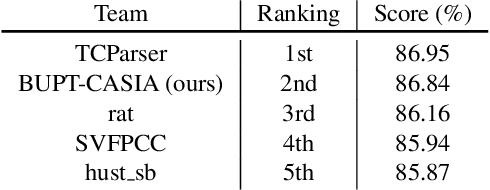

This is a very short technical report, which introduces the solution of the Team BUPT-CASIA for Short-video Face Parsing Track of The 3rd Person in Context (PIC) Workshop and Challenge at CVPR 2021. Face parsing has recently attracted increasing interest due to its numerous application potentials. Generally speaking, it has a lot in common with human parsing, such as task setting, data characteristics, number of categories and so on. Therefore, this work applies state-of-the-art human parsing method to face parsing task to explore the similarities and differences between them. Our submission achieves 86.84% score and wins the 2nd place in the challenge.