 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBernini: Latent Semantic Planning for Video Diffusion
May 21, 2026Multimodal large language models (MLLMs) and diffusion models have each reached remarkable maturity: MLLMs excel at reasoning over heterogeneous multimodal inputs with strong semantic grounding, while diffusion models synthesize images and videos with photorealistic fidelity. We argue that these two families can be unified through a simple division of labor: MLLMs perform semantic planning, while diffusion models render pixels from high-level semantic guidance and low-level visual features. Building on this idea, we propose Bernini, a unified framework for video generation and editing. An MLLM-based planner predicts the target semantic representation directly in the ViT embedding space, and a DiT-based renderer synthesizes pixels conditioned on this plan, augmented by text features and, for editing, source VAE features for detail preservation. Because semantics serve as the interface, the planner and renderer can be trained separately and only lightly co-trained, preserving the pretrained strengths of both components while keeping training efficient. To better handle multiple visual inputs, we introduce Segment-Aware 3D Rotary Positional Embedding (SA-3D RoPE), and further incorporate chain-of-thought reasoning in the planner to better transfer understanding into generation. Bernini achieves state-of-the-art performance across a wide range of video generation and editing benchmarks, with the MLLM's pretrained understanding translating into strong generalization on challenging editing tasks.
HLLM-Creator: Hierarchical LLM-based Personalized Creative Generation
Aug 25, 2025AI-generated content technologies are widely used in content creation. However, current AIGC systems rely heavily on creators' inspiration, rarely generating truly user-personalized content. In real-world applications such as online advertising, a single product may have multiple selling points, with different users focusing on different features. This underscores the significant value of personalized, user-centric creative generation. Effective personalized content generation faces two main challenges: (1) accurately modeling user interests and integrating them into the content generation process while adhering to factual constraints, and (2) ensuring high efficiency and scalability to handle the massive user base in industrial scenarios. Additionally, the scarcity of personalized creative data in practice complicates model training, making data construction another key hurdle. We propose HLLM-Creator, a hierarchical LLM framework for efficient user interest modeling and personalized content generation. During inference, a combination of user clustering and a user-ad-matching-prediction based pruning strategy is employed to significantly enhance generation efficiency and reduce computational overhead, making the approach suitable for large-scale deployment. Moreover, we design a data construction pipeline based on chain-of-thought reasoning, which generates high-quality, user-specific creative titles and ensures factual consistency despite limited personalized data. This pipeline serves as a critical foundation for the effectiveness of our model. Extensive experiments on personalized title generation for Douyin Search Ads show the effectiveness of HLLM-Creator. Online A/B test shows a 0.476% increase on Adss, paving the way for more effective and efficient personalized generation in industrial scenarios. Codes for academic dataset are available at https://github.com/bytedance/HLLM.
Center Prediction Loss for Re-identification
Apr 30, 2021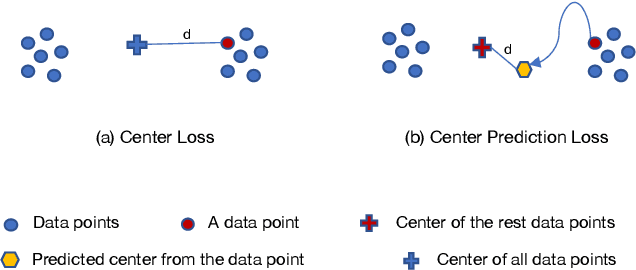
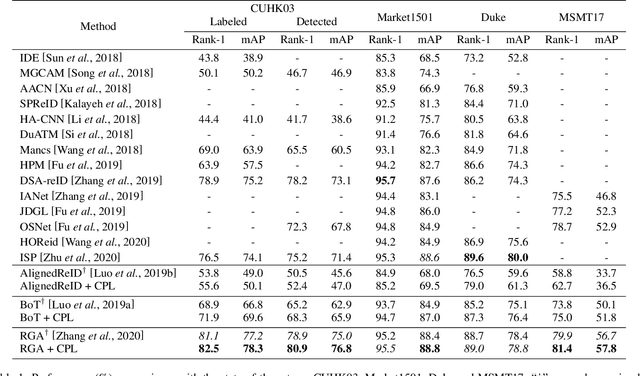
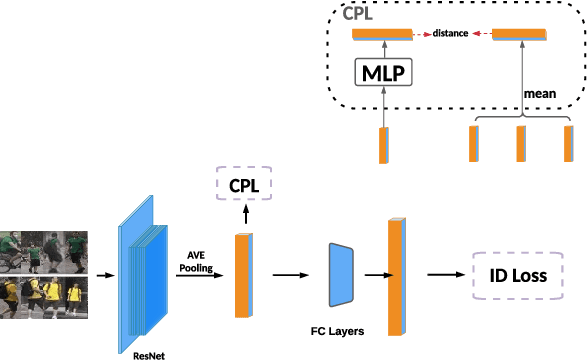
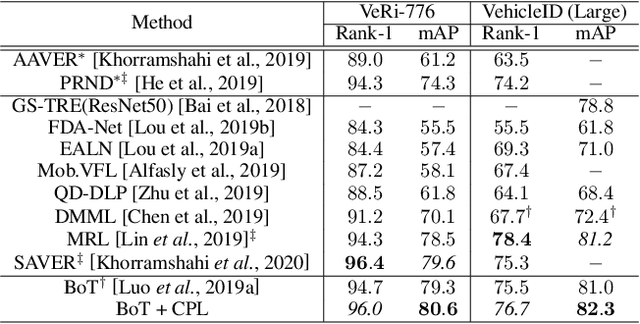
The training loss function that enforces certain training sample distribution patterns plays a critical role in building a re-identification (ReID) system. Besides the basic requirement of discrimination, i.e., the features corresponding to different identities should not be mixed, additional intra-class distribution constraints, such as features from the same identities should be close to their centers, have been adopted to construct losses. Despite the advances of various new loss functions, it is still challenging to strike the balance between the need of reducing the intra-class variation and allowing certain distribution freedom. In this paper, we propose a new loss based on center predictivity, that is, a sample must be positioned in a location of the feature space such that from it we can roughly predict the location of the center of same-class samples. The prediction error is then regarded as a loss called Center Prediction Loss (CPL). We show that, without introducing additional hyper-parameters, this new loss leads to a more flexible intra-class distribution constraint while ensuring the between-class samples are well-separated. Extensive experiments on various real-world ReID datasets show that the proposed loss can achieve superior performance and can also be complementary to existing losses.
Two-Stream Video Classification with Cross-Modality Attention
Aug 01, 2019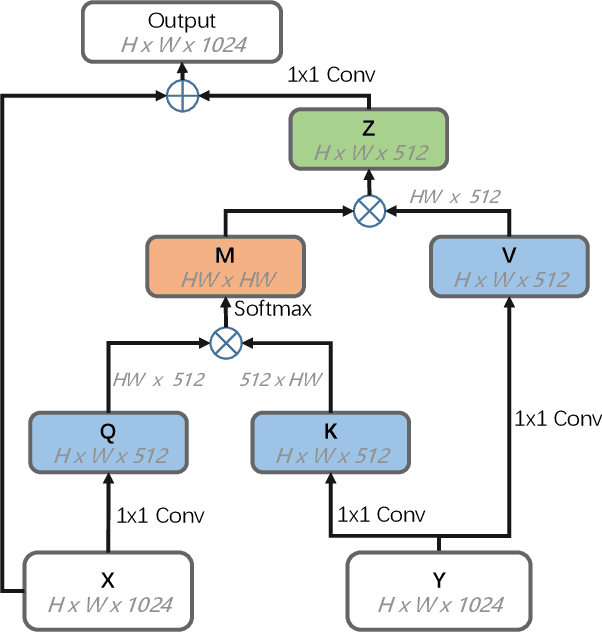
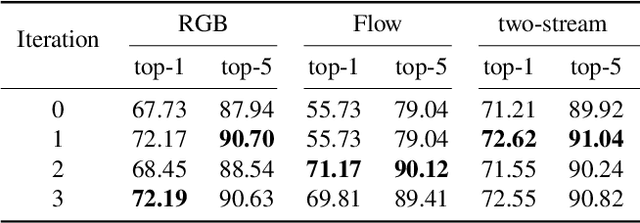
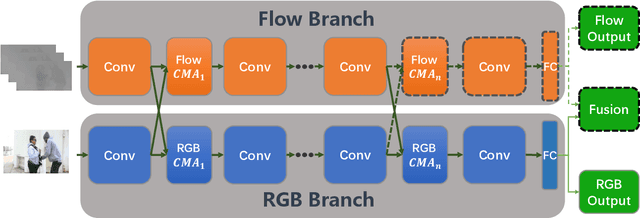

Fusing multi-modality information is known to be able to effectively bring significant improvement in video classification. However, the most popular method up to now is still simply fusing each stream's prediction scores at the last stage. A valid question is whether there exists a more effective method to fuse information cross modality. With the development of attention mechanism in natural language processing, there emerge many successful applications of attention in the field of computer vision. In this paper, we propose a cross-modality attention operation, which can obtain information from other modality in a more effective way than two-stream. Correspondingly we implement a compatible block named CMA block, which is a wrapper of our proposed attention operation. CMA can be plugged into many existing architectures. In the experiments, we comprehensively compare our method with two-stream and non-local models widely used in video classification. All experiments clearly demonstrate strong performance superiority by our proposed method. We also analyze the advantages of the CMA block by visualizing the attention map, which intuitively shows how the block helps the final prediction.
Deep Steering: Learning End-to-End Driving Model from Spatial and Temporal Visual Cues
Aug 12, 2017
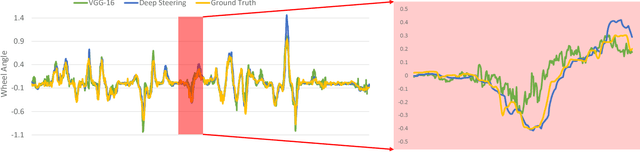


In recent years, autonomous driving algorithms using low-cost vehicle-mounted cameras have attracted increasing endeavors from both academia and industry. There are multiple fronts to these endeavors, including object detection on roads, 3-D reconstruction etc., but in this work we focus on a vision-based model that directly maps raw input images to steering angles using deep networks. This represents a nascent research topic in computer vision. The technical contributions of this work are three-fold. First, the model is learned and evaluated on real human driving videos that are time-synchronized with other vehicle sensors. This differs from many prior models trained from synthetic data in racing games. Second, state-of-the-art models, such as PilotNet, mostly predict the wheel angles independently on each video frame, which contradicts common understanding of driving as a stateful process. Instead, our proposed model strikes a combination of spatial and temporal cues, jointly investigating instantaneous monocular camera observations and vehicle's historical states. This is in practice accomplished by inserting carefully-designed recurrent units (e.g., LSTM and Conv-LSTM) at proper network layers. Third, to facilitate the interpretability of the learned model, we utilize a visual back-propagation scheme for discovering and visualizing image regions crucially influencing the final steering prediction. Our experimental study is based on about 6 hours of human driving data provided by Udacity. Comprehensive quantitative evaluations demonstrate the effectiveness and robustness of our model, even under scenarios like drastic lighting changes and abrupt turning. The comparison with other state-of-the-art models clearly reveals its superior performance in predicting the due wheel angle for a self-driving car.