 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLourdes Agapito
S3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Oct 13, 2020


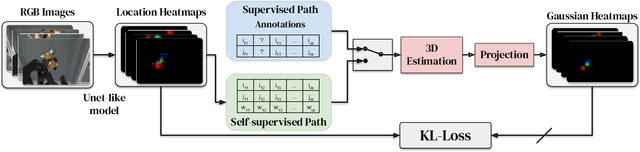
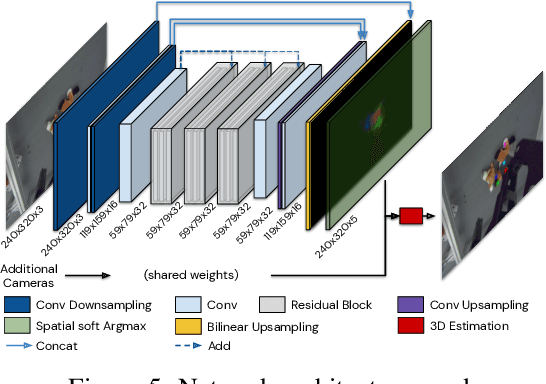
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
DiverseNet: When One Right Answer is not Enough
Aug 24, 2020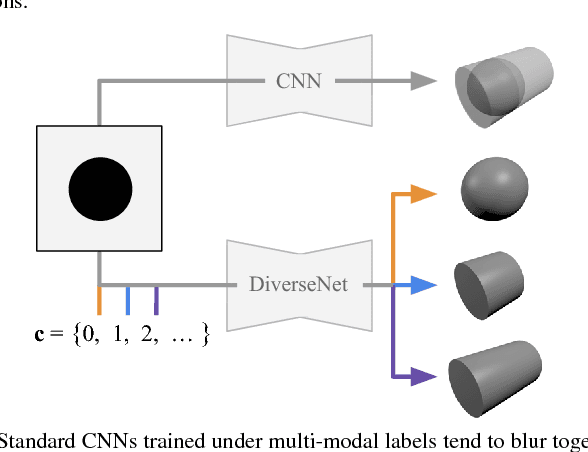
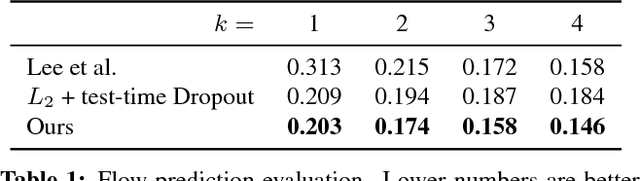
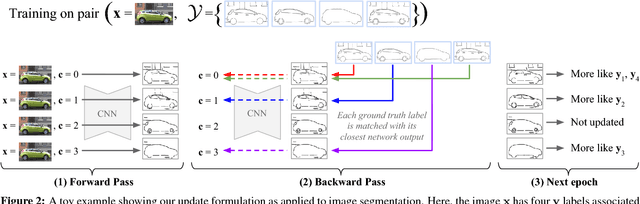
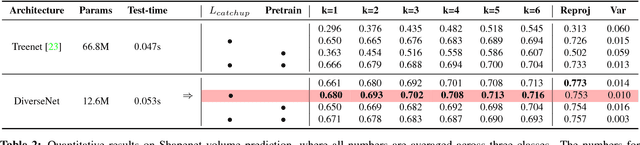
Many structured prediction tasks in machine vision have a collection of acceptable answers, instead of one definitive ground truth answer. Segmentation of images, for example, is subject to human labeling bias. Similarly, there are multiple possible pixel values that could plausibly complete occluded image regions. State-of-the art supervised learning methods are typically optimized to make a single test-time prediction for each query, failing to find other modes in the output space. Existing methods that allow for sampling often sacrifice speed or accuracy. We introduce a simple method for training a neural network, which enables diverse structured predictions to be made for each test-time query. For a single input, we learn to predict a range of possible answers. We compare favorably to methods that seek diversity through an ensemble of networks. Such stochastic multiple choice learning faces mode collapse, where one or more ensemble members fail to receive any training signal. Our best performing solution can be deployed for various tasks, and just involves small modifications to the existing single-mode architecture, loss function, and training regime. We demonstrate that our method results in quantitative improvements across three challenging tasks: 2D image completion, 3D volume estimation, and flow prediction.
FroDO: From Detections to 3D Objects
May 11, 2020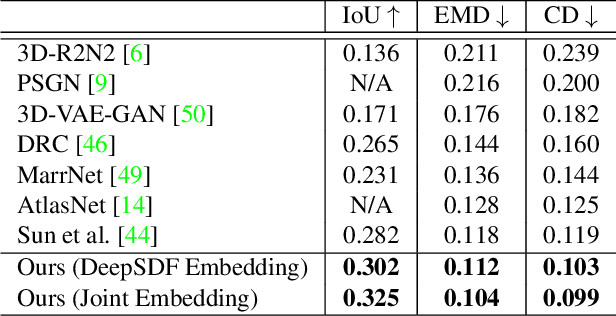


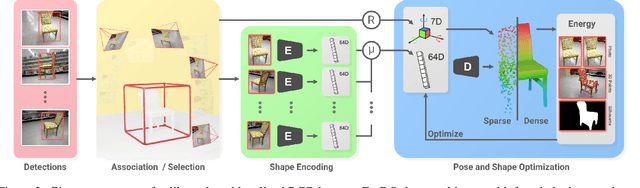
Object-oriented maps are important for scene understanding since they jointly capture geometry and semantics, allow individual instantiation and meaningful reasoning about objects. We introduce FroDO, a method for accurate 3D reconstruction of object instances from RGB video that infers object location, pose and shape in a coarse-to-fine manner. Key to FroDO is to embed object shapes in a novel learnt space that allows seamless switching between sparse point cloud and dense DeepSDF decoding. Given an input sequence of localized RGB frames, FroDO first aggregates 2D detections to instantiate a category-aware 3D bounding box per object. A shape code is regressed using an encoder network before optimizing shape and pose further under the learnt shape priors using sparse and dense shape representations. The optimization uses multi-view geometric, photometric and silhouette losses. We evaluate on real-world datasets, including Pix3D, Redwood-OS, and ScanNet, for single-view, multi-view, and multi-object reconstruction.
xR-EgoPose: Egocentric 3D Human Pose from an HMD Camera
Jul 23, 2019

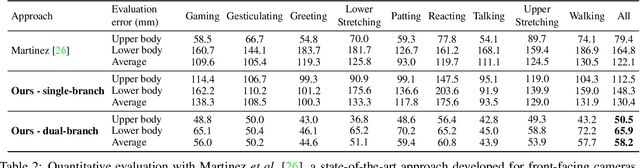

We present a new solution to egocentric 3D body pose estimation from monocular images captured from a downward looking fish-eye camera installed on the rim of a head mounted virtual reality device. This unusual viewpoint, just 2 cm. away from the user's face, leads to images with unique visual appearance, characterized by severe self-occlusions and strong perspective distortions that result in a drastic difference in resolution between lower and upper body. Our contribution is two-fold. Firstly, we propose a new encoder-decoder architecture with a novel dual branch decoder designed specifically to account for the varying uncertainty in the 2D joint locations. Our quantitative evaluation, both on synthetic and real-world datasets, shows that our strategy leads to substantial improvements in accuracy over state of the art egocentric pose estimation approaches. Our second contribution is a new large-scale photorealistic synthetic dataset - xR-EgoPose - offering 383K frames of high quality renderings of people with a diversity of skin tones, body shapes, clothing, in a variety of backgrounds and lighting conditions, performing a range of actions. Our experiments show that the high variability in our new synthetic training corpus leads to good generalization to real world footage and to state of the art results on real world datasets with ground truth. Moreover, an evaluation on the Human3.6M benchmark shows that the performance of our method is on par with top performing approaches on the more classic problem of 3D human pose from a third person viewpoint.
3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds
Nov 02, 2018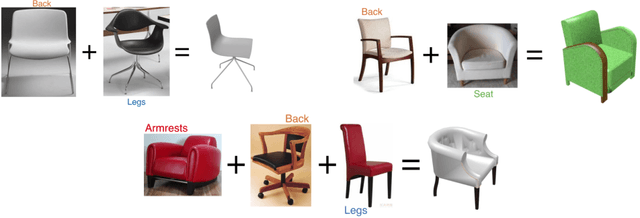
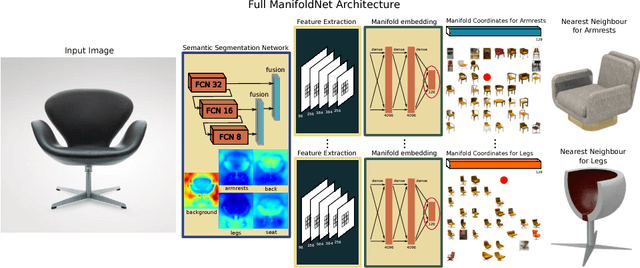

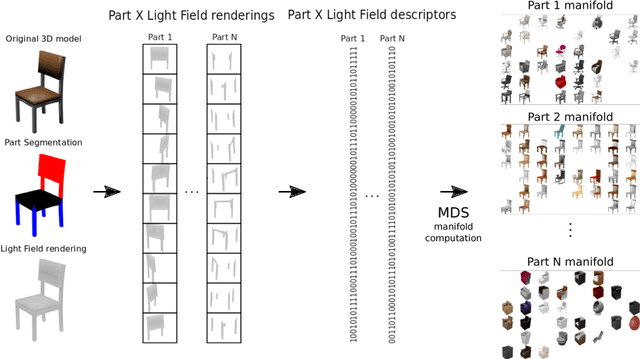
We present 3D Pick & Mix, a new 3D shape retrieval system that provides users with a new level of freedom to explore 3D shape and Internet image collections by introducing the ability to reason about objects at the level of their constituent parts. While classic retrieval systems can only formulate simple searches such as "find the 3D model that is most similar to the input image" our new approach can formulate advanced and semantically meaningful search queries such as: "find me the 3D model that best combines the design of the legs of the chair in image 1 but with no armrests, like the chair in image 2". Many applications could benefit from such rich queries, users could browse through catalogues of furniture and pick and mix parts, combining for example the legs of a chair from one shop and the armrests from another shop.
MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects
Oct 22, 2018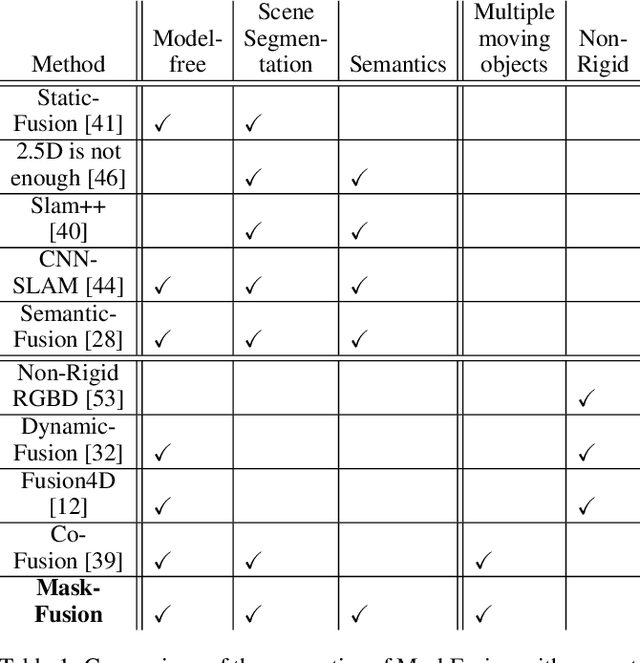
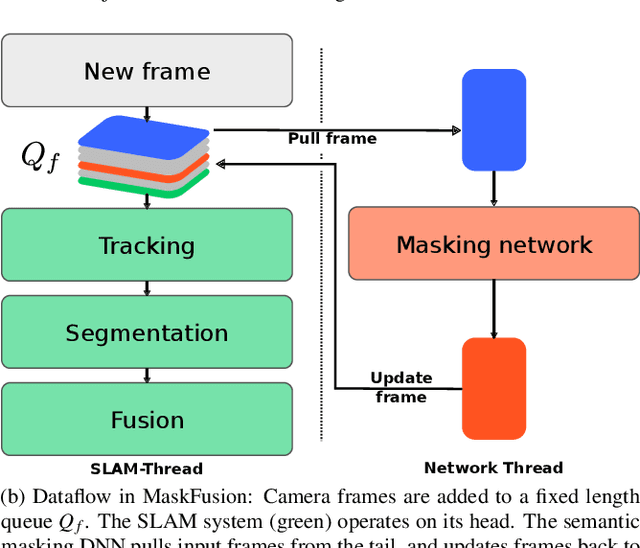
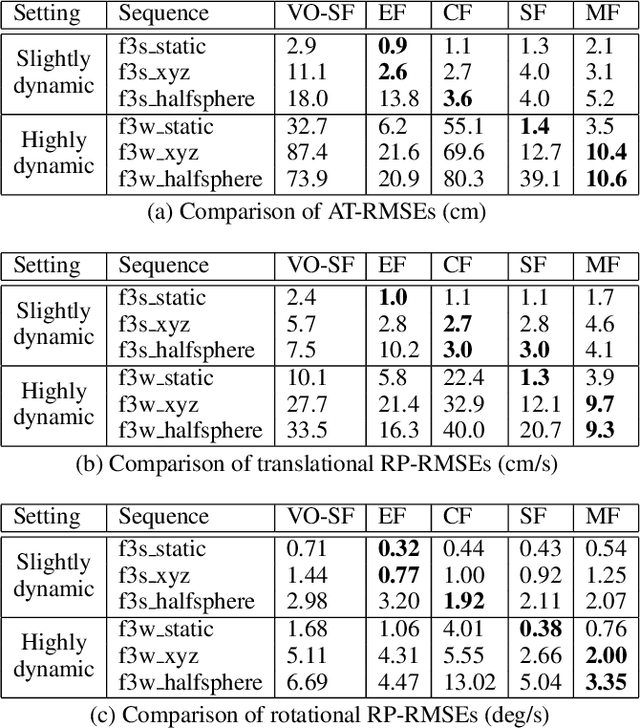
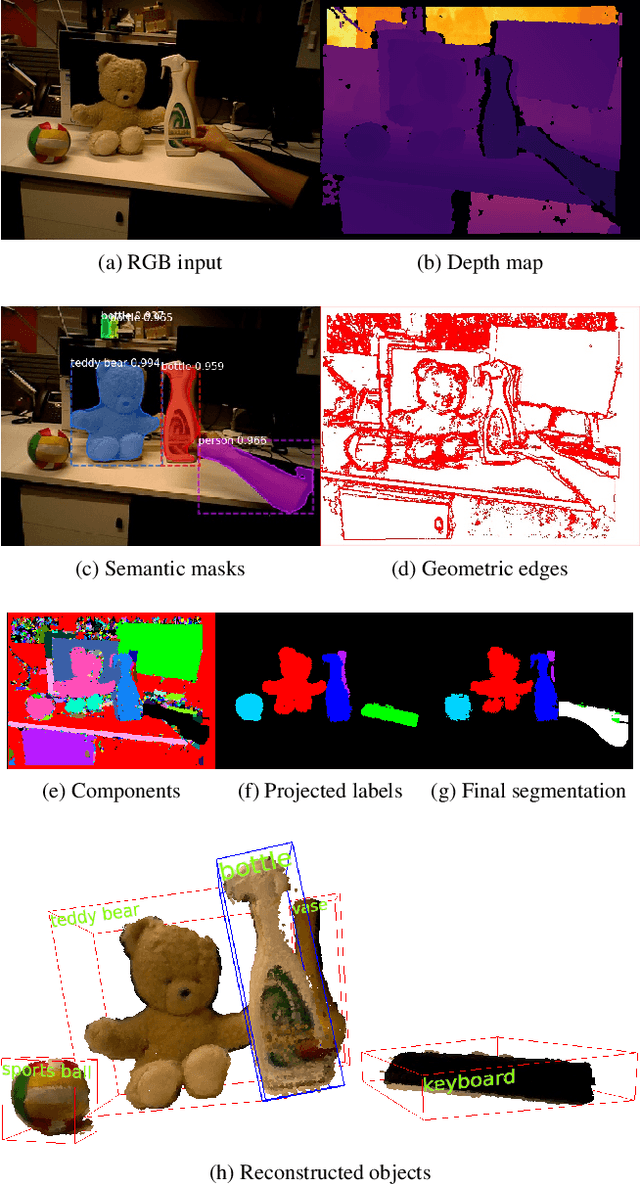
We present MaskFusion, a real-time, object-aware, semantic and dynamic RGB-D SLAM system that goes beyond traditional systems which output a purely geometric map of a static scene. MaskFusion recognizes, segments and assigns semantic class labels to different objects in the scene, while tracking and reconstructing them even when they move independently from the camera. As an RGB-D camera scans a cluttered scene, image-based instance-level semantic segmentation creates semantic object masks that enable real-time object recognition and the creation of an object-level representation for the world map. Unlike previous recognition-based SLAM systems, MaskFusion does not require known models of the objects it can recognize, and can deal with multiple independent motions. MaskFusion takes full advantage of using instance-level semantic segmentation to enable semantic labels to be fused into an object-aware map, unlike recent semantics enabled SLAM systems that perform voxel-level semantic segmentation. We show augmented-reality applications that demonstrate the unique features of the map output by MaskFusion: instance-aware, semantic and dynamic.
Rethinking Pose in 3D: Multi-stage Refinement and Recovery for Markerless Motion Capture
Aug 04, 2018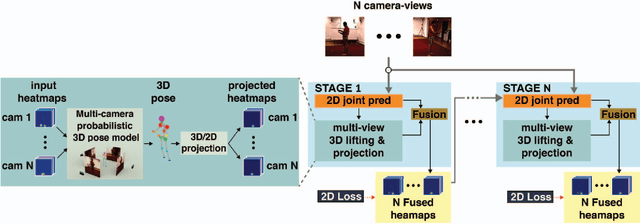
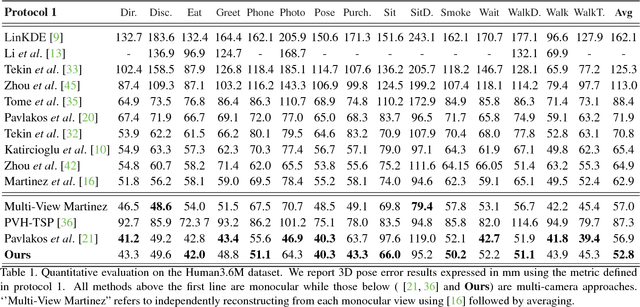
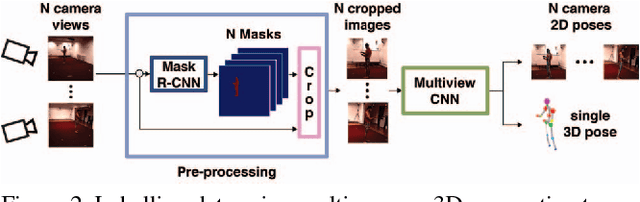

We propose a CNN-based approach for multi-camera markerless motion capture of the human body. Unlike existing methods that first perform pose estimation on individual cameras and generate 3D models as post-processing, our approach makes use of 3D reasoning throughout a multi-stage approach. This novelty allows us to use provisional 3D models of human pose to rethink where the joints should be located in the image and to recover from past mistakes. Our principled refinement of 3D human poses lets us make use of image cues, even from images where we previously misdetected joints, to refine our estimates as part of an end-to-end approach. Finally, we demonstrate how the high-quality output of our multi-camera setup can be used as an additional training source to improve the accuracy of existing single camera models.
Training VAEs Under Structured Residuals
Jul 31, 2018


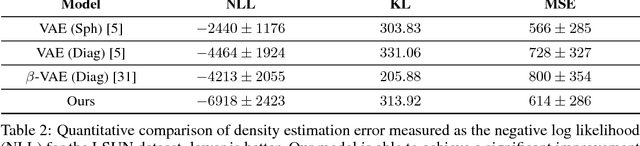
Variational auto-encoders (VAEs) are a popular and powerful deep generative model. Previous works on VAEs have assumed a factorized likelihood model, whereby the output uncertainty of each pixel is assumed to be independent. This approximation is clearly limited as demonstrated by observing a residual image from a VAE reconstruction, which often possess a high level of structure. This paper demonstrates a novel scheme to incorporate a structured Gaussian likelihood prediction network within the VAE that allows the residual correlations to be modeled. Our novel architecture, with minimal increase in complexity, incorporates the covariance matrix prediction within the VAE. We also propose a new mechanism for allowing structured uncertainty on color images. Furthermore, we provide a scheme for effectively training this model, and include some suggestions for improving performance in terms of efficiency or modeling longer range correlations.
Structured Uncertainty Prediction Networks
Mar 23, 2018
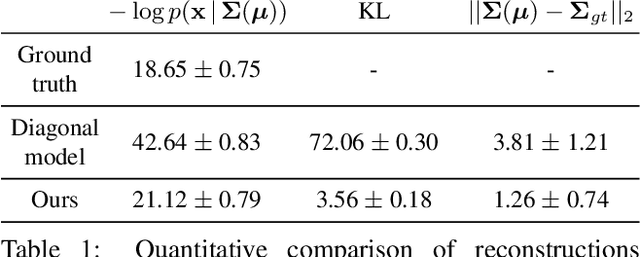
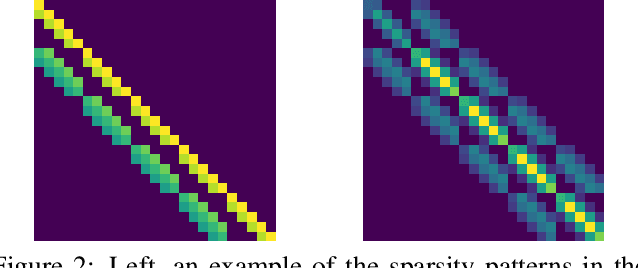

This paper is the first work to propose a network to predict a structured uncertainty distribution for a synthesized image. Previous approaches have been mostly limited to predicting diagonal covariance matrices. Our novel model learns to predict a full Gaussian covariance matrix for each reconstruction, which permits efficient sampling and likelihood evaluation. We demonstrate that our model can accurately reconstruct ground truth correlated residual distributions for synthetic datasets and generate plausible high frequency samples for real face images. We also illustrate the use of these predicted covariances for structure preserving image denoising.