 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Semantically Aligned Vision-Language Pre-Training
Aug 04, 2022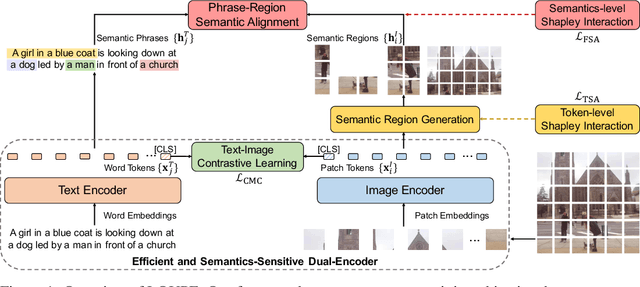
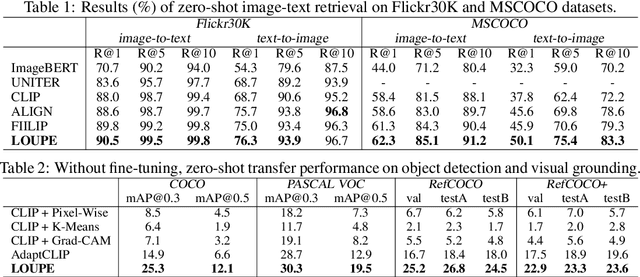
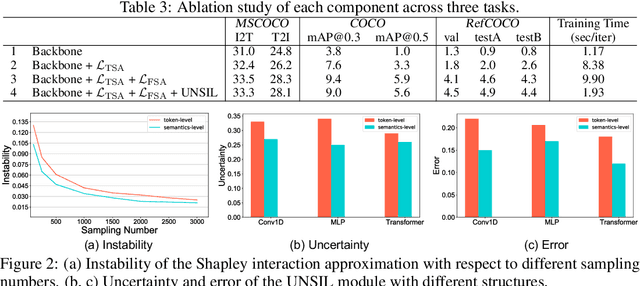

Large-scale vision-language pre-training has shown impressive advances in a wide range of downstream tasks. Existing methods mainly model the cross-modal alignment by the similarity of the global representations of images and texts, or advanced cross-modal attention upon image and text features. However, they fail to explicitly learn the fine-grained semantic alignment between visual regions and textual phrases, as only global image-text alignment information is available. In this paper, we introduce LOUPE, a fine-grained semantically aLigned visiOn-langUage PrE-training framework, which learns fine-grained semantic alignment from the novel perspective of game-theoretic interactions. To efficiently compute the game-theoretic interactions, we further propose an uncertainty-aware neural Shapley interaction learning module. Experiments show that LOUPE achieves state-of-the-art on image-text retrieval benchmarks. Without any object-level human annotations and fine-tuning, LOUPE achieves competitive performance on object detection and visual grounding. More importantly, LOUPE opens a new promising direction of learning fine-grained semantics from large-scale raw image-text pairs.
Skeleton-Parted Graph Scattering Networks for 3D Human Motion Prediction
Jul 31, 2022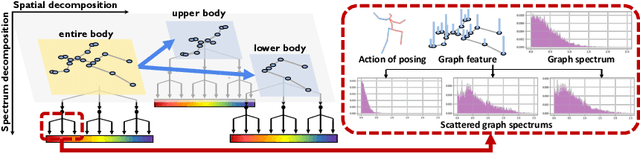
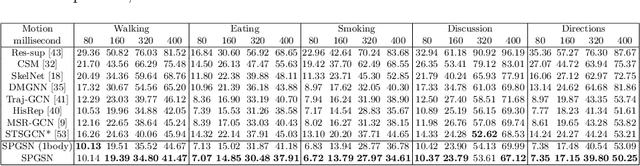
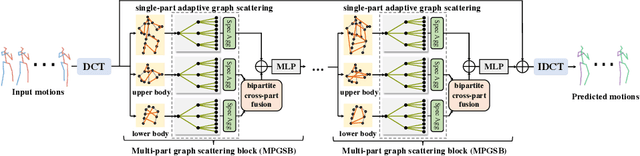
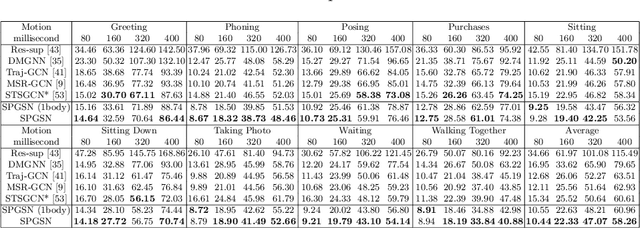
Graph convolutional network based methods that model the body-joints' relations, have recently shown great promise in 3D skeleton-based human motion prediction. However, these methods have two critical issues: first, deep graph convolutions filter features within only limited graph spectrums, losing sufficient information in the full band; second, using a single graph to model the whole body underestimates the diverse patterns on various body-parts. To address the first issue, we propose adaptive graph scattering, which leverages multiple trainable band-pass graph filters to decompose pose features into richer graph spectrum bands. To address the second issue, body-parts are modeled separately to learn diverse dynamics, which enables finer feature extraction along the spatial dimensions. Integrating the above two designs, we propose a novel skeleton-parted graph scattering network (SPGSN). The cores of the model are cascaded multi-part graph scattering blocks (MPGSBs), building adaptive graph scattering on diverse body-parts, as well as fusing the decomposed features based on the inferred spectrum importance and body-part interactions. Extensive experiments have shown that SPGSN outperforms state-of-the-art methods by remarkable margins of 13.8%, 9.3% and 2.7% in terms of 3D mean per joint position error (MPJPE) on Human3.6M, CMU Mocap and 3DPW datasets, respectively.
Visual Recognition by Request
Jul 28, 2022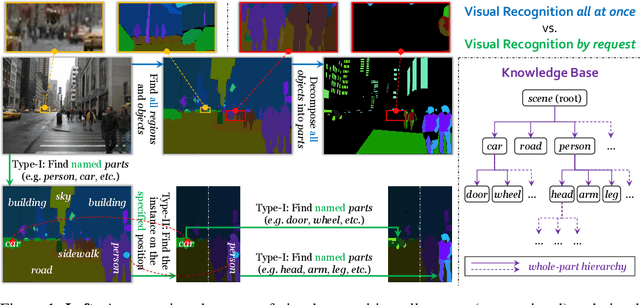
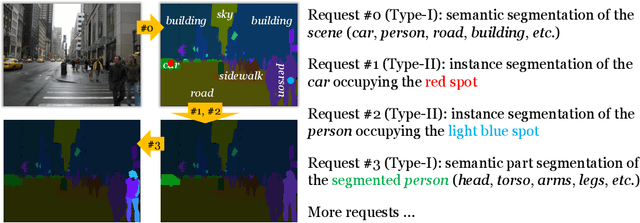

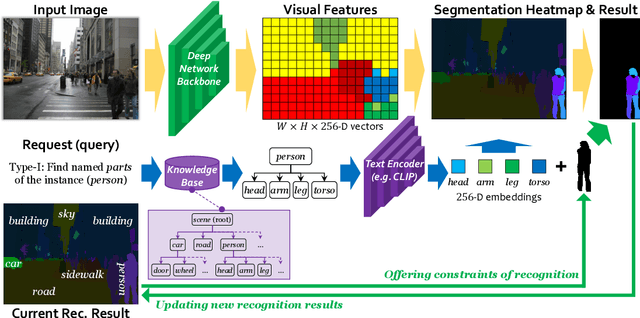
In this paper, we present a novel protocol of annotation and evaluation for visual recognition. Different from traditional settings, the protocol does not require the labeler/algorithm to annotate/recognize all targets (objects, parts, etc.) at once, but instead raises a number of recognition instructions and the algorithm recognizes targets by request. This mechanism brings two beneficial properties to reduce the burden of annotation, namely, (i) variable granularity: different scenarios can have different levels of annotation, in particular, object parts can be labeled only in large and clear instances, (ii) being open-domain: new concepts can be added to the database in minimal costs. To deal with the proposed setting, we maintain a knowledge base and design a query-based visual recognition framework that constructs queries on-the-fly based on the requests. We evaluate the recognition system on two mixed-annotated datasets, CPP and ADE20K, and demonstrate its promising ability of learning from partially labeled data as well as adapting to new concepts with only text labels.
Active Pointly-Supervised Instance Segmentation
Jul 23, 2022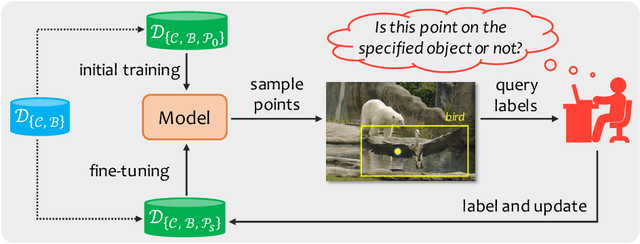
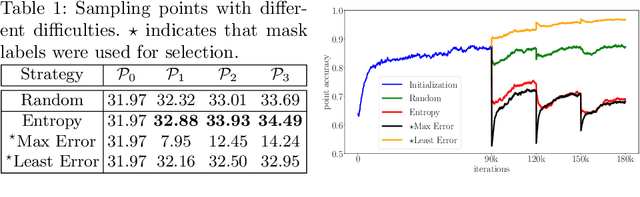
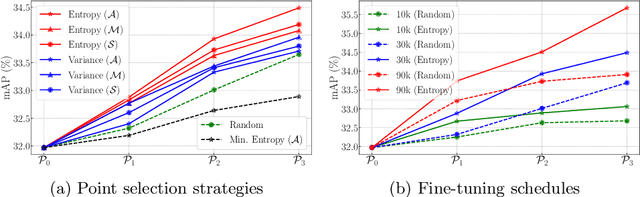

The requirement of expensive annotations is a major burden for training a well-performed instance segmentation model. In this paper, we present an economic active learning setting, named active pointly-supervised instance segmentation (APIS), which starts with box-level annotations and iteratively samples a point within the box and asks if it falls on the object. The key of APIS is to find the most desirable points to maximize the segmentation accuracy with limited annotation budgets. We formulate this setting and propose several uncertainty-based sampling strategies. The model developed with these strategies yields consistent performance gain on the challenging MS-COCO dataset, compared against other learning strategies. The results suggest that APIS, integrating the advantages of active learning and point-based supervision, is an effective learning paradigm for label-efficient instance segmentation.
A Survey on Label-efficient Deep Segmentation: Bridging the Gap between Weak Supervision and Dense Prediction
Jul 04, 2022
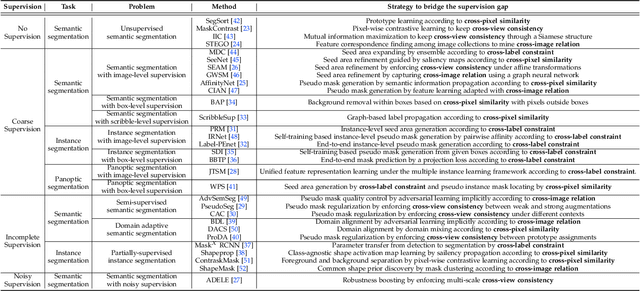

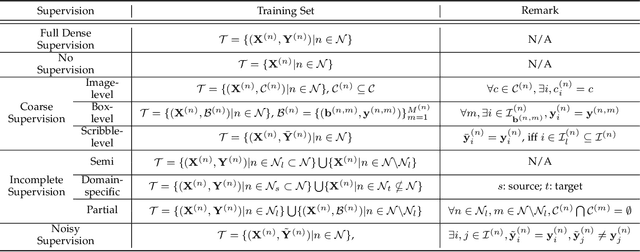
The rapid development of deep learning has made a great progress in segmentation, one of the fundamental tasks of computer vision. However, the current segmentation algorithms mostly rely on the availability of pixel-level annotations, which are often expensive, tedious, and laborious. To alleviate this burden, the past years have witnessed an increasing attention in building label-efficient, deep-learning-based segmentation algorithms. This paper offers a comprehensive review on label-efficient segmentation methods. To this end, we first develop a taxonomy to organize these methods according to the supervision provided by different types of weak labels (including no supervision, coarse supervision, incomplete supervision and noisy supervision) and supplemented by the types of segmentation problems (including semantic segmentation, instance segmentation and panoptic segmentation). Next, we summarize the existing label-efficient segmentation methods from a unified perspective that discusses an important question: how to bridge the gap between weak supervision and dense prediction -- the current methods are mostly based on heuristic priors, such as cross-pixel similarity, cross-label constraint, cross-view consistency, cross-image relation, etc. Finally, we share our opinions about the future research directions for label-efficient deep segmentation.
Fast Dynamic Radiance Fields with Time-Aware Neural Voxels
May 30, 2022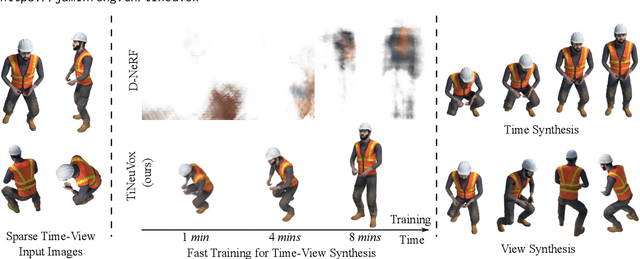

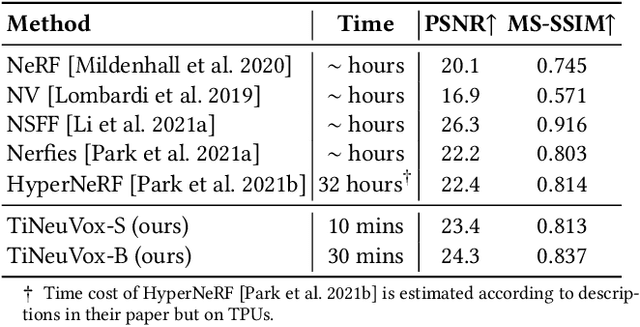
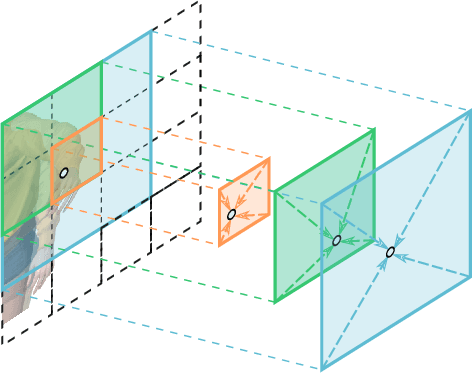
Neural radiance fields (NeRF) have shown great success in modeling 3D scenes and synthesizing novel-view images. However, most previous NeRF methods take much time to optimize one single scene. Explicit data structures, e.g. voxel features, show great potential to accelerate the training process. However, voxel features face two big challenges to be applied to dynamic scenes, i.e. modeling temporal information and capturing different scales of point motions. We propose a radiance field framework by representing scenes with time-aware voxel features, named as TiNeuVox. A tiny coordinate deformation network is introduced to model coarse motion trajectories and temporal information is further enhanced in the radiance network. A multi-distance interpolation method is proposed and applied on voxel features to model both small and large motions. Our framework significantly accelerates the optimization of dynamic radiance fields while maintaining high rendering quality. Empirical evaluation is performed on both synthetic and real scenes. Our TiNeuVox completes training with only 8 minutes and 8-MB storage cost while showing similar or even better rendering performance than previous dynamic NeRF methods.
HiViT: Hierarchical Vision Transformer Meets Masked Image Modeling
May 30, 2022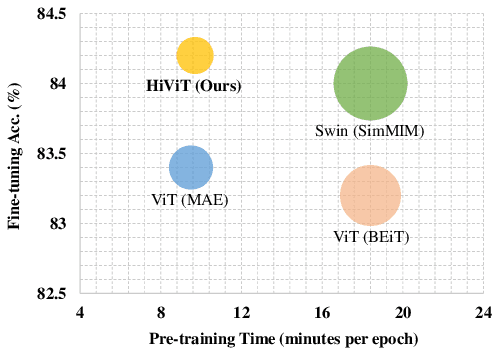

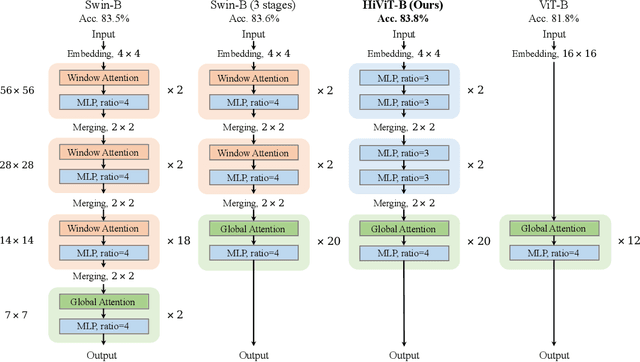
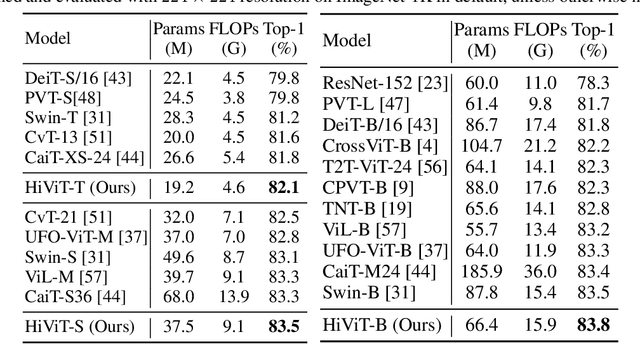
Recently, masked image modeling (MIM) has offered a new methodology of self-supervised pre-training of vision transformers. A key idea of efficient implementation is to discard the masked image patches (or tokens) throughout the target network (encoder), which requires the encoder to be a plain vision transformer (e.g., ViT), albeit hierarchical vision transformers (e.g., Swin Transformer) have potentially better properties in formulating vision inputs. In this paper, we offer a new design of hierarchical vision transformers named HiViT (short for Hierarchical ViT) that enjoys both high efficiency and good performance in MIM. The key is to remove the unnecessary "local inter-unit operations", deriving structurally simple hierarchical vision transformers in which mask-units can be serialized like plain vision transformers. For this purpose, we start with Swin Transformer and (i) set the masking unit size to be the token size in the main stage of Swin Transformer, (ii) switch off inter-unit self-attentions before the main stage, and (iii) eliminate all operations after the main stage. Empirical studies demonstrate the advantageous performance of HiViT in terms of fully-supervised, self-supervised, and transfer learning. In particular, in running MAE on ImageNet-1K, HiViT-B reports a +0.6% accuracy gain over ViT-B and a 1.9$\times$ speed-up over Swin-B, and the performance gain generalizes to downstream tasks of detection and segmentation. Code will be made publicly available.
Domain-Agnostic Prior for Transfer Semantic Segmentation
Apr 20, 2022
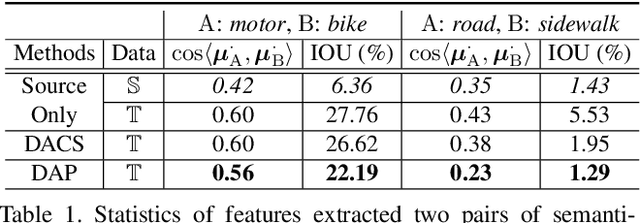
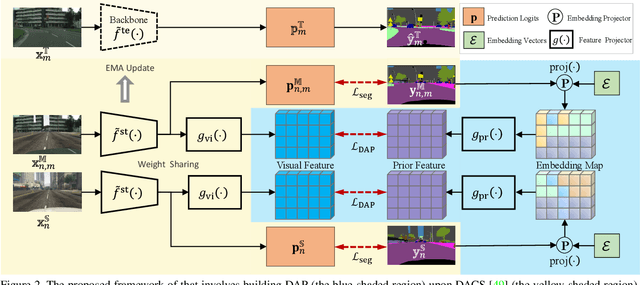
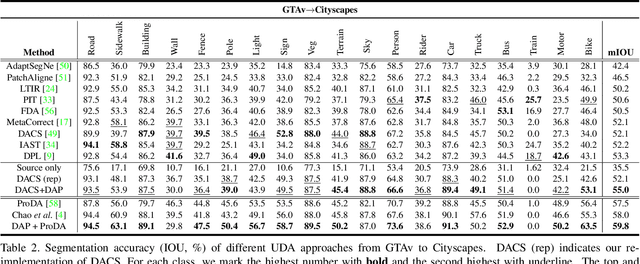
Unsupervised domain adaptation (UDA) is an important topic in the computer vision community. The key difficulty lies in defining a common property between the source and target domains so that the source-domain features can align with the target-domain semantics. In this paper, we present a simple and effective mechanism that regularizes cross-domain representation learning with a domain-agnostic prior (DAP) that constrains the features extracted from source and target domains to align with a domain-agnostic space. In practice, this is easily implemented as an extra loss term that requires a little extra costs. In the standard evaluation protocol of transferring synthesized data to real data, we validate the effectiveness of different types of DAP, especially that borrowed from a text embedding model that shows favorable performance beyond the state-of-the-art UDA approaches in terms of segmentation accuracy. Our research reveals that UDA benefits much from better proxies, possibly from other data modalities.
CenterNet++ for Object Detection
Apr 18, 2022

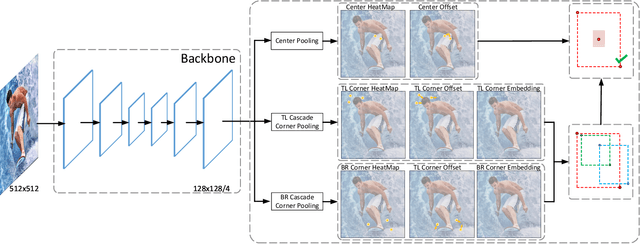
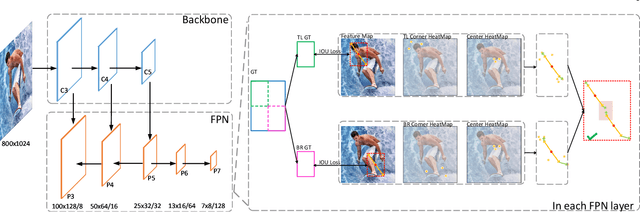
There are two mainstreams for object detection: top-down and bottom-up. The state-of-the-art approaches mostly belong to the first category. In this paper, we demonstrate that the bottom-up approaches are as competitive as the top-down and enjoy higher recall. Our approach, named CenterNet, detects each object as a triplet keypoints (top-left and bottom-right corners and the center keypoint). We firstly group the corners by some designed cues and further confirm the objects by the center keypoints. The corner keypoints equip the approach with the ability to detect objects of various scales and shapes and the center keypoint avoids the confusion brought by a large number of false-positive proposals. Our approach is a kind of anchor-free detector because it does not need to define explicit anchor boxes. We adapt our approach to the backbones with different structures, i.e., the 'hourglass' like networks and the the 'pyramid' like networks, which detect objects on a single-resolution feature map and multi-resolution feature maps, respectively. On the MS-COCO dataset, CenterNet with Res2Net-101 and Swin-Transformer achieves APs of 53.7% and 57.1%, respectively, outperforming all existing bottom-up detectors and achieving state-of-the-art. We also design a real-time CenterNet, which achieves a good trade-off between accuracy and speed with an AP of 43.6% at 30.5 FPS. https://github.com/Duankaiwen/PyCenterNet.
Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
Mar 27, 2022


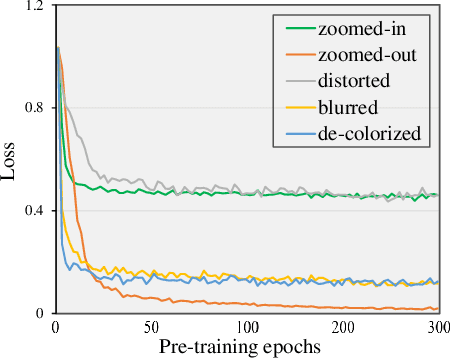
The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.