 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-free 3D Single Stage Detector with Mask-Guided Attention for Point Cloud
Aug 08, 2021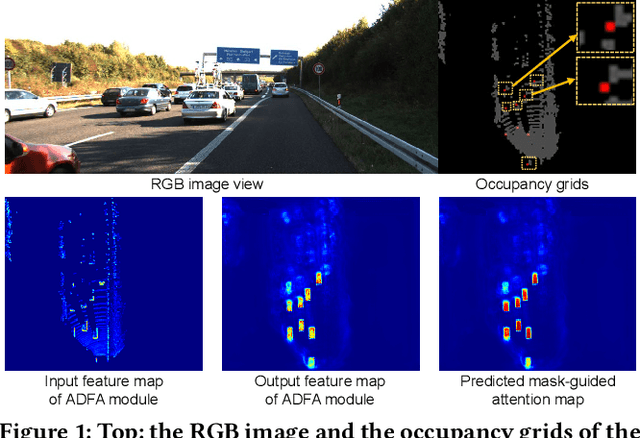
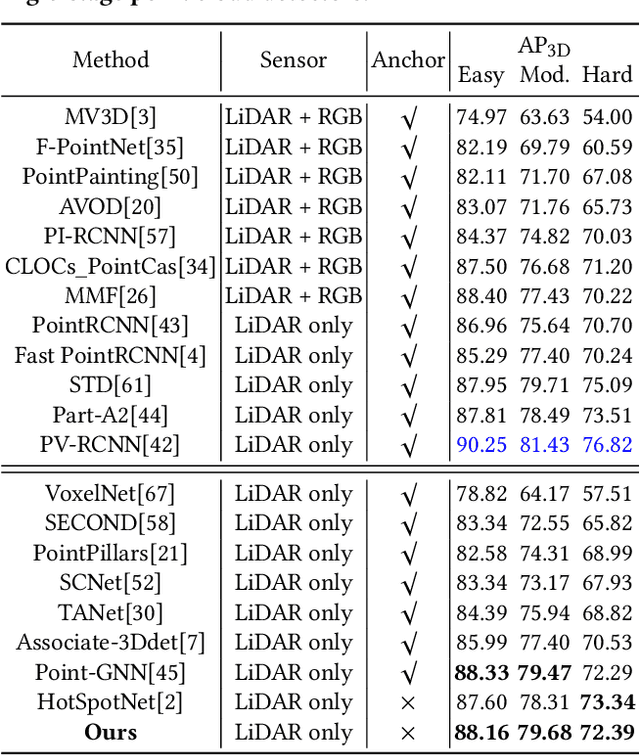
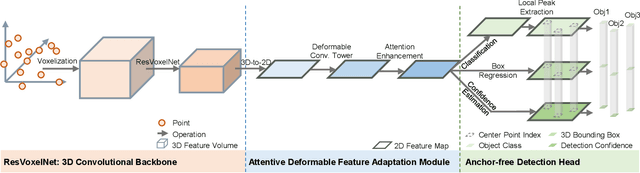
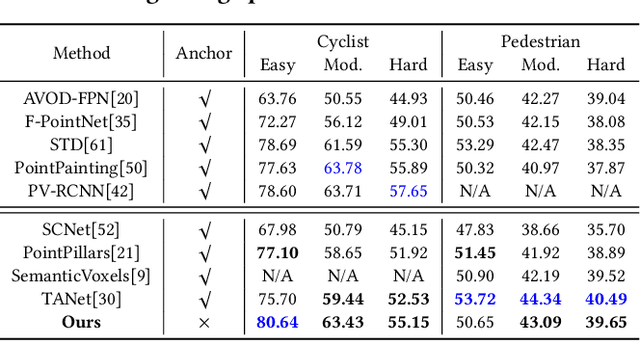
Most of the existing single-stage and two-stage 3D object detectors are anchor-based methods, while the efficient but challenging anchor-free single-stage 3D object detection is not well investigated. Recent studies on 2D object detection show that the anchor-free methods also are of great potential. However, the unordered and sparse properties of point clouds prevent us from directly leveraging the advanced 2D methods on 3D point clouds. We overcome this by converting the voxel-based sparse 3D feature volumes into the sparse 2D feature maps. We propose an attentive module to fit the sparse feature maps to dense mostly on the object regions through the deformable convolution tower and the supervised mask-guided attention. By directly regressing the 3D bounding box from the enhanced and dense feature maps, we construct a novel single-stage 3D detector for point clouds in an anchor-free manner. We propose an IoU-based detection confidence re-calibration scheme to improve the correlation between the detection confidence score and the accuracy of the bounding box regression. Our code is publicly available at \url{https://github.com/jialeli1/MGAF-3DSSD}.
FREE: Feature Refinement for Generalized Zero-Shot Learning
Jul 29, 2021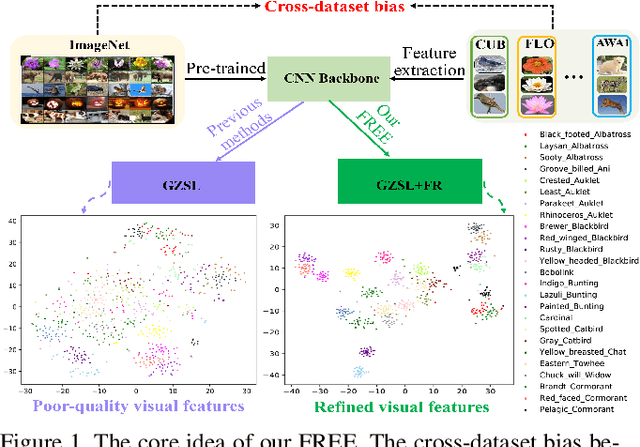
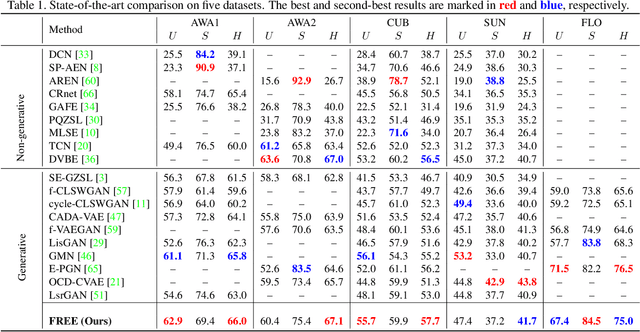
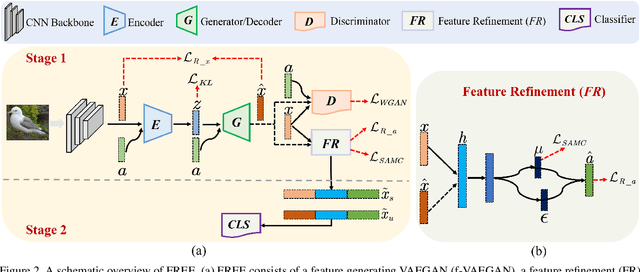
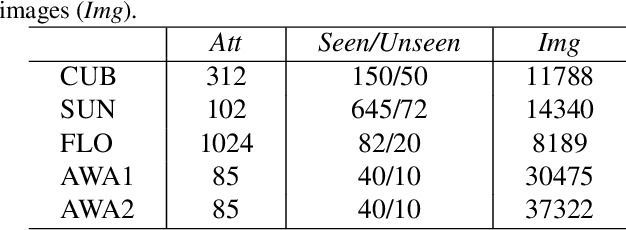
Generalized zero-shot learning (GZSL) has achieved significant progress, with many efforts dedicated to overcoming the problems of visual-semantic domain gap and seen-unseen bias. However, most existing methods directly use feature extraction models trained on ImageNet alone, ignoring the cross-dataset bias between ImageNet and GZSL benchmarks. Such a bias inevitably results in poor-quality visual features for GZSL tasks, which potentially limits the recognition performance on both seen and unseen classes. In this paper, we propose a simple yet effective GZSL method, termed feature refinement for generalized zero-shot learning (FREE), to tackle the above problem. FREE employs a feature refinement (FR) module that incorporates \textit{semantic$\rightarrow$visual} mapping into a unified generative model to refine the visual features of seen and unseen class samples. Furthermore, we propose a self-adaptive margin center loss (SAMC-loss) that cooperates with a semantic cycle-consistency loss to guide FR to learn class- and semantically-relevant representations, and concatenate the features in FR to extract the fully refined features. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of FREE over its baseline and current state-of-the-art methods. Our codes are available at https://github.com/shiming-chen/FREE .
ASOD60K: Audio-Induced Salient Object Detection in Panoramic Videos
Jul 24, 2021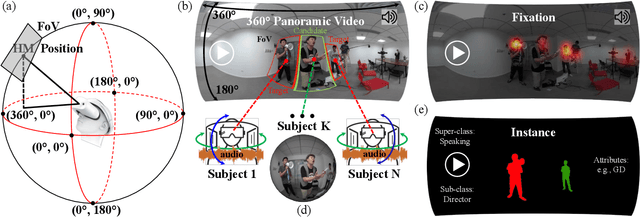

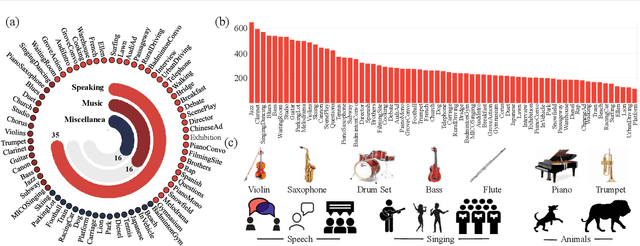
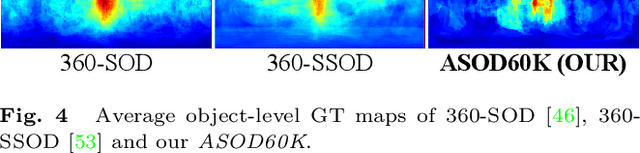
Exploring to what humans pay attention in dynamic panoramic scenes is useful for many fundamental applications, including augmented reality (AR) in retail, AR-powered recruitment, and visual language navigation. With this goal in mind, we propose PV-SOD, a new task that aims to segment salient objects from panoramic videos. In contrast to existing fixation-level or object-level saliency detection tasks, we focus on multi-modal salient object detection (SOD), which mimics human attention mechanism by segmenting salient objects with the guidance of audio-visual cues. To support this task, we collect the first large-scale dataset, named ASOD60K, which contains 4K-resolution video frames annotated with a six-level hierarchy, thus distinguishing itself with richness, diversity and quality. Specifically, each sequence is marked with both its super-/sub-class, with objects of each sub-class being further annotated with human eye fixations, bounding boxes, object-/instance-level masks, and associated attributes (e.g., geometrical distortion). These coarse-to-fine annotations enable detailed analysis for PV-SOD modeling, e.g., determining the major challenges for existing SOD models, and predicting scanpaths to study the long-term eye fixation behaviors of humans. We systematically benchmark 11 representative approaches on ASOD60K and derive several interesting findings. We hope this study could serve as a good starting point for advancing SOD research towards panoramic videos.
PVTv2: Improved Baselines with Pyramid Vision Transformer
Jul 17, 2021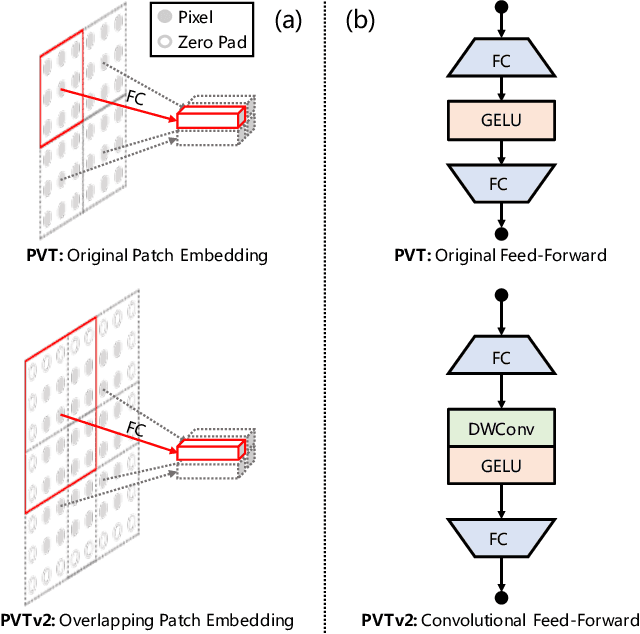
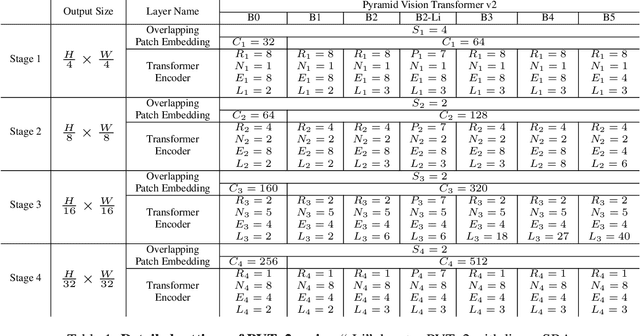
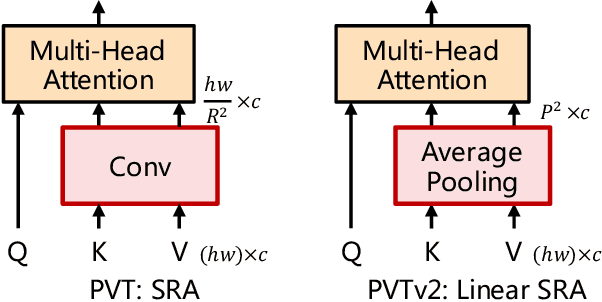
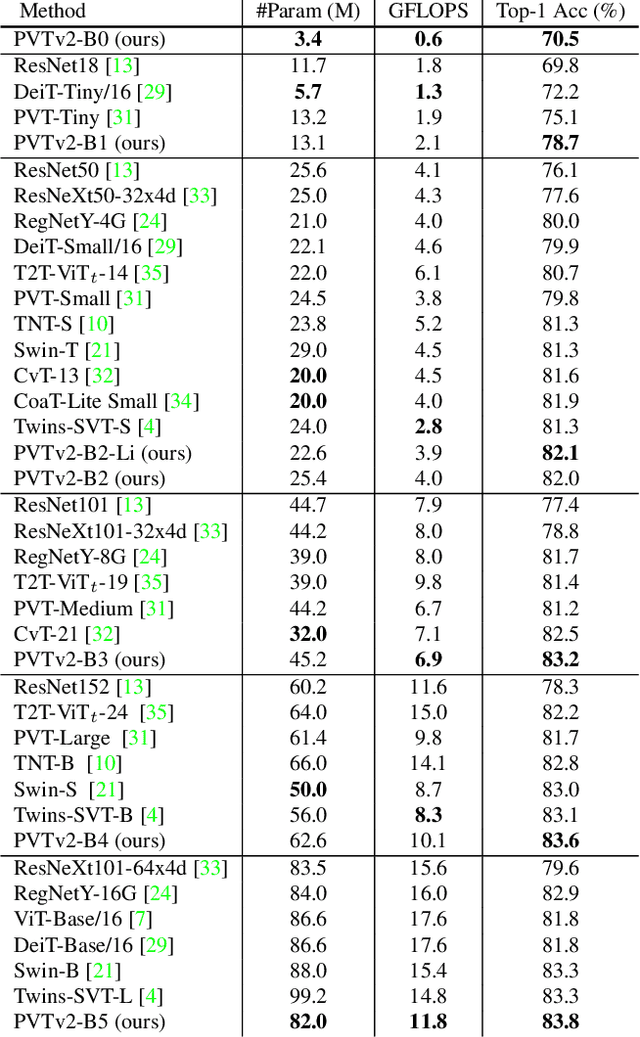
Transformer recently has shown encouraging progresses in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (abbreviated as PVTv1) by adding three designs, including (1) overlapping patch embedding, (2) convolutional feed-forward networks, and (3) linear complexity attention layers. With these modifications, our PVTv2 significantly improves PVTv1 on three tasks e.g., classification, detection, and segmentation. Moreover, PVTv2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision. Code is available at https://github.com/whai362/PVT .
Variational Topic Inference for Chest X-Ray Report Generation
Jul 15, 2021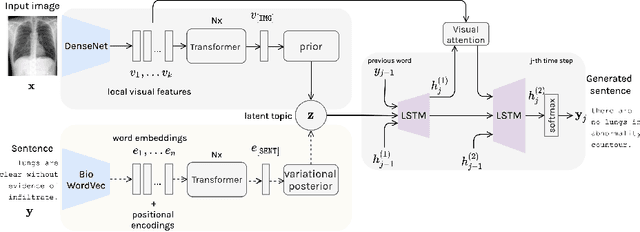
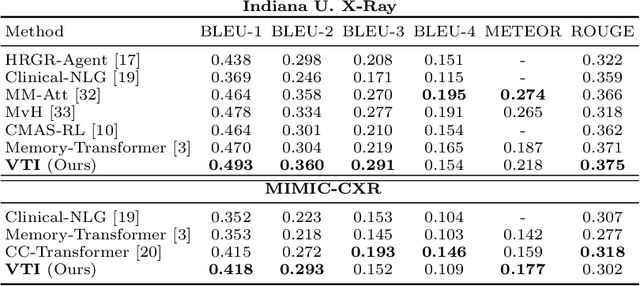
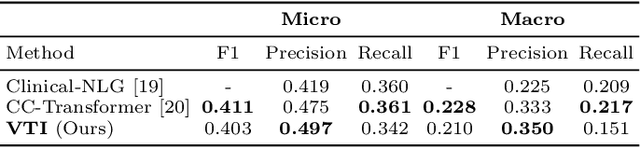
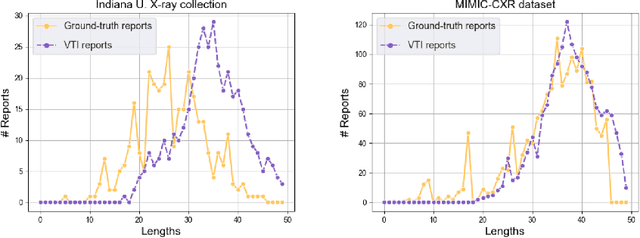
Automating report generation for medical imaging promises to reduce workload and assist diagnosis in clinical practice. Recent work has shown that deep learning models can successfully caption natural images. However, learning from medical data is challenging due to the diversity and uncertainty inherent in the reports written by different radiologists with discrepant expertise and experience. To tackle these challenges, we propose variational topic inference for automatic report generation. Specifically, we introduce a set of topics as latent variables to guide sentence generation by aligning image and language modalities in a latent space. The topics are inferred in a conditional variational inference framework, with each topic governing the generation of a sentence in the report. Further, we adopt a visual attention module that enables the model to attend to different locations in the image and generate more informative descriptions. We conduct extensive experiments on two benchmarks, namely Indiana U. Chest X-rays and MIMIC-CXR. The results demonstrate that our proposed variational topic inference method can generate novel reports rather than mere copies of reports used in training, while still achieving comparable performance to state-of-the-art methods in terms of standard language generation criteria.
Kernel Continual Learning
Jul 14, 2021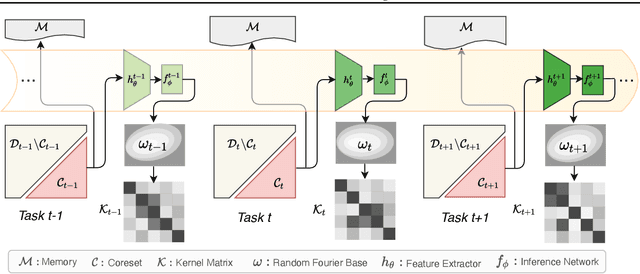
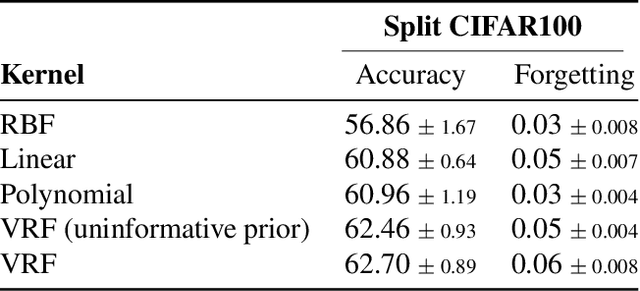
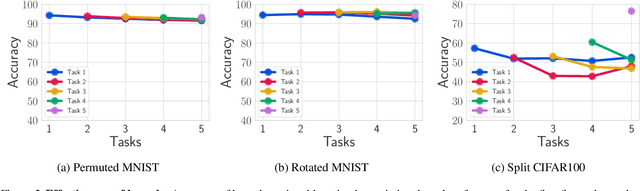

This paper introduces kernel continual learning, a simple but effective variant of continual learning that leverages the non-parametric nature of kernel methods to tackle catastrophic forgetting. We deploy an episodic memory unit that stores a subset of samples for each task to learn task-specific classifiers based on kernel ridge regression. This does not require memory replay and systematically avoids task interference in the classifiers. We further introduce variational random features to learn a data-driven kernel for each task. To do so, we formulate kernel continual learning as a variational inference problem, where a random Fourier basis is incorporated as the latent variable. The variational posterior distribution over the random Fourier basis is inferred from the coreset of each task. In this way, we are able to generate more informative kernels specific to each task, and, more importantly, the coreset size can be reduced to achieve more compact memory, resulting in more efficient continual learning based on episodic memory. Extensive evaluation on four benchmarks demonstrates the effectiveness and promise of kernels for continual learning.
Structured Latent Embeddings for Recognizing Unseen Classes in Unseen Domains
Jul 12, 2021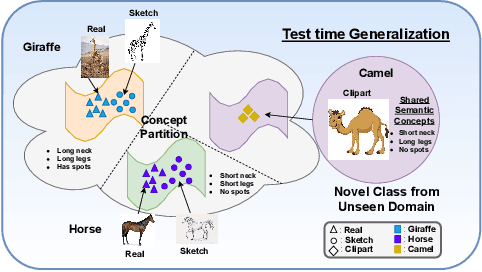
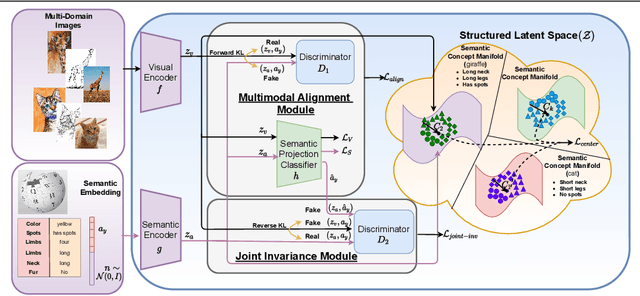
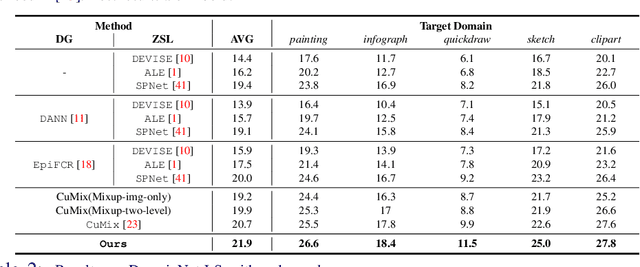
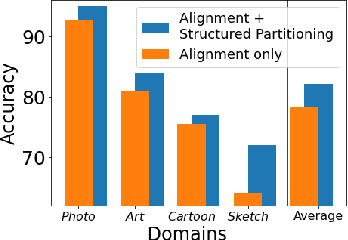
The need to address the scarcity of task-specific annotated data has resulted in concerted efforts in recent years for specific settings such as zero-shot learning (ZSL) and domain generalization (DG), to separately address the issues of semantic shift and domain shift, respectively. However, real-world applications often do not have constrained settings and necessitate handling unseen classes in unseen domains -- a setting called Zero-shot Domain Generalization, which presents the issues of domain and semantic shifts simultaneously. In this work, we propose a novel approach that learns domain-agnostic structured latent embeddings by projecting images from different domains as well as class-specific semantic text-based representations to a common latent space. In particular, our method jointly strives for the following objectives: (i) aligning the multimodal cues from visual and text-based semantic concepts; (ii) partitioning the common latent space according to the domain-agnostic class-level semantic concepts; and (iii) learning a domain invariance w.r.t the visual-semantic joint distribution for generalizing to unseen classes in unseen domains. Our experiments on the challenging DomainNet and DomainNet-LS benchmarks show the superiority of our approach over existing methods, with significant gains on difficult domains like quickdraw and sketch.
Local-to-Global Self-Attention in Vision Transformers
Jul 10, 2021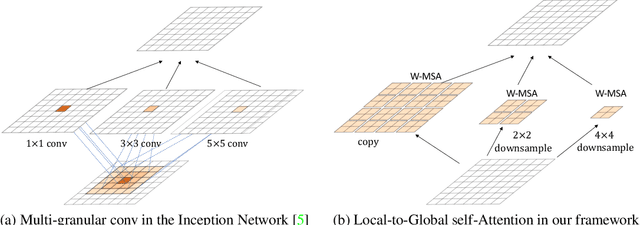
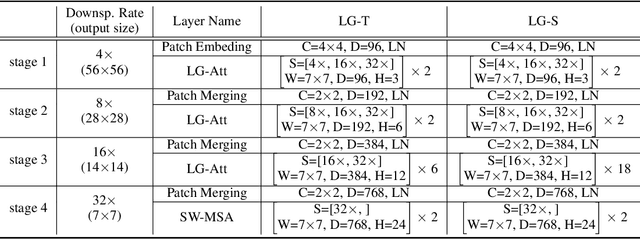
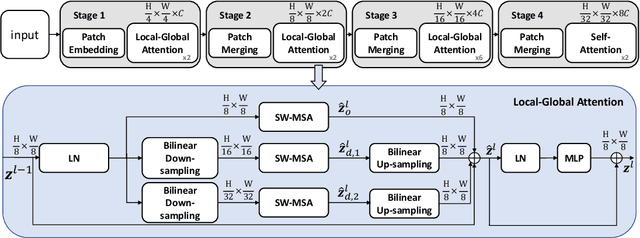
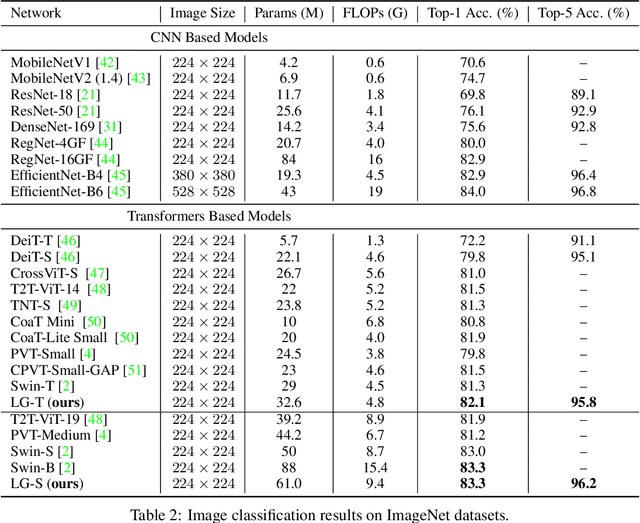
Transformers have demonstrated great potential in computer vision tasks. To avoid dense computations of self-attentions in high-resolution visual data, some recent Transformer models adopt a hierarchical design, where self-attentions are only computed within local windows. This design significantly improves the efficiency but lacks global feature reasoning in early stages. In this work, we design a multi-path structure of the Transformer, which enables local-to-global reasoning at multiple granularities in each stage. The proposed framework is computationally efficient and highly effective. With a marginal increasement in computational overhead, our model achieves notable improvements in both image classification and semantic segmentation. Code is available at https://github.com/ljpadam/LG-Transformer
Instance-Level Relative Saliency Ranking with Graph Reasoning
Jul 08, 2021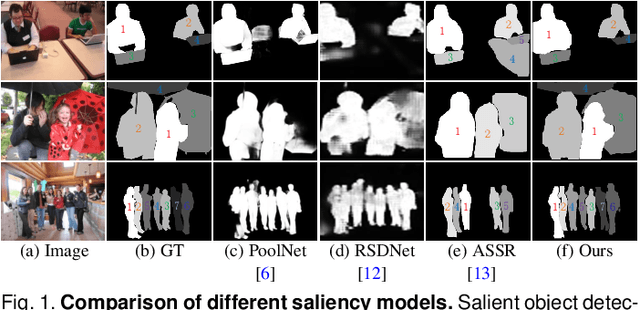



Conventional salient object detection models cannot differentiate the importance of different salient objects. Recently, two works have been proposed to detect saliency ranking by assigning different degrees of saliency to different objects. However, one of these models cannot differentiate object instances and the other focuses more on sequential attention shift order inference. In this paper, we investigate a practical problem setting that requires simultaneously segment salient instances and infer their relative saliency rank order. We present a novel unified model as the first end-to-end solution, where an improved Mask R-CNN is first used to segment salient instances and a saliency ranking branch is then added to infer the relative saliency. For relative saliency ranking, we build a new graph reasoning module by combining four graphs to incorporate the instance interaction relation, local contrast, global contrast, and a high-level semantic prior, respectively. A novel loss function is also proposed to effectively train the saliency ranking branch. Besides, a new dataset and an evaluation metric are proposed for this task, aiming at pushing forward this field of research. Finally, experimental results demonstrate that our proposed model is more effective than previous methods. We also show an example of its practical usage on adaptive image retargeting.
Bi-level Feature Alignment for Versatile Image Translation and Manipulation
Jul 07, 2021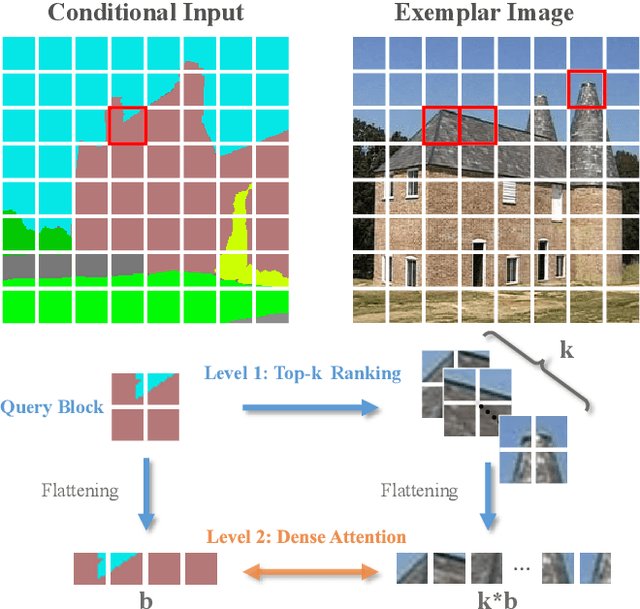
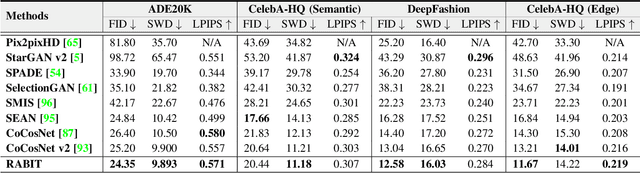
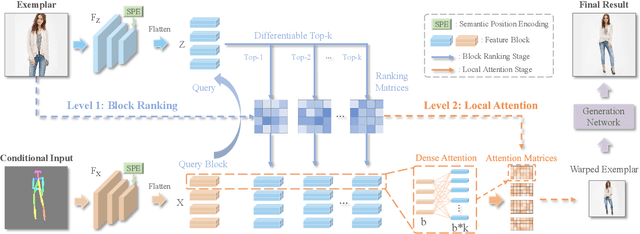
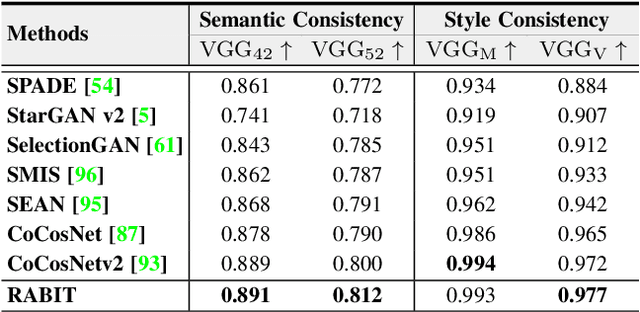
Generative adversarial networks (GANs) have achieved great success in image translation and manipulation. However, high-fidelity image generation with faithful style control remains a grand challenge in computer vision. This paper presents a versatile image translation and manipulation framework that achieves accurate semantic and style guidance in image generation by explicitly building a correspondence. To handle the quadratic complexity incurred by building the dense correspondences, we introduce a bi-level feature alignment strategy that adopts a top-$k$ operation to rank block-wise features followed by dense attention between block features which reduces memory cost substantially. As the top-$k$ operation involves index swapping which precludes the gradient propagation, we propose to approximate the non-differentiable top-$k$ operation with a regularized earth mover's problem so that its gradient can be effectively back-propagated. In addition, we design a novel semantic position encoding mechanism that builds up coordinate for each individual semantic region to preserve texture structures while building correspondences. Further, we design a novel confidence feature injection module which mitigates mismatch problem by fusing features adaptively according to the reliability of built correspondences. Extensive experiments show that our method achieves superior performance qualitatively and quantitatively as compared with the state-of-the-art. The code is available at \href{https://github.com/fnzhan/RABIT}{https://github.com/fnzhan/RABIT}.