 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesRec: A Dataset for Aesthetics-Aligned Clothing Outfit Recommendation
Feb 03, 2026Clothing recommendation extends beyond merely generating personalized outfits; it serves as a crucial medium for aesthetic guidance. However, existing methods predominantly rely on user-item-outfit interaction behaviors while overlooking explicit representations of clothing aesthetics. To bridge this gap, we present the AesRec benchmark dataset featuring systematic quantitative aesthetic annotations, thereby enabling the development of aesthetics-aligned recommendation systems. Grounded in professional apparel quality standards and fashion aesthetic principles, we define a multidimensional set of indicators. At the item level, six dimensions are independently assessed: silhouette, chromaticity, materiality, craftsmanship, wearability, and item-level impression. Transitioning to the outfit level, the evaluation retains the first five core attributes while introducing stylistic synergy, visual harmony, and outfit-level impression as distinct metrics to capture the collective aesthetic impact. Given the increasing human-like proficiency of Vision-Language Models in multimodal understanding and interaction, we leverage them for large-scale aesthetic scoring. We conduct rigorous human-machine consistency validation on a fashion dataset, confirming the reliability of the generated ratings. Experimental results based on AesRec further demonstrate that integrating quantified aesthetic information into clothing recommendation models can provide aesthetic guidance for users while fulfilling their personalized requirements.
Conflict-Aware Client Selection for Multi-Server Federated Learning
Feb 02, 2026Federated learning (FL) has emerged as a promising distributed machine learning (ML) that enables collaborative model training across clients without exposing raw data, thereby preserving user privacy and reducing communication costs. Despite these benefits, traditional single-server FL suffers from high communication latency due to the aggregation of models from a large number of clients. While multi-server FL distributes workloads across edge servers, overlapping client coverage and uncoordinated selection often lead to resource contention, causing bandwidth conflicts and training failures. To address these limitations, we propose a decentralized reinforcement learning with conflict risk prediction, named RL CRP, to optimize client selection in multi-server FL systems. Specifically, each server estimates the likelihood of client selection conflicts using a categorical hidden Markov model based on its sparse historical client selection sequence. Then, a fairness-aware reward mechanism is incorporated to promote long-term client participation for minimizing training latency and resource contention. Extensive experiments demonstrate that the proposed RL-CRP framework effectively reduces inter-server conflicts and significantly improves training efficiency in terms of convergence speed and communication cost.
Causal World Modeling for Robot Control
Jan 29, 2026This work highlights that video world modeling, alongside vision-language pre-training, establishes a fresh and independent foundation for robot learning. Intuitively, video world models provide the ability to imagine the near future by understanding the causality between actions and visual dynamics. Inspired by this, we introduce LingBot-VA, an autoregressive diffusion framework that learns frame prediction and policy execution simultaneously. Our model features three carefully crafted designs: (1) a shared latent space, integrating vision and action tokens, driven by a Mixture-of-Transformers (MoT) architecture, (2) a closed-loop rollout mechanism, allowing for ongoing acquisition of environmental feedback with ground-truth observations, (3) an asynchronous inference pipeline, parallelizing action prediction and motor execution to support efficient control. We evaluate our model on both simulation benchmarks and real-world scenarios, where it shows significant promise in long-horizon manipulation, data efficiency in post-training, and strong generalizability to novel configurations. The code and model are made publicly available to facilitate the community.
Constrained Language Model Policy Optimization via Risk-aware Stepwise Alignment
Dec 30, 2025When fine-tuning pre-trained Language Models (LMs) to exhibit desired behaviors, maintaining control over risk is critical for ensuring both safety and trustworthiness. Most existing safety alignment methods, such as Safe RLHF and SACPO, typically operate under a risk-neutral paradigm that is insufficient to address the risks arising from deviations from the reference policy and offers limited robustness against rare but potentially catastrophic harmful behaviors. To address this limitation, we propose Risk-aware Stepwise Alignment (RSA), a novel alignment method that explicitly incorporates risk awareness into the policy optimization process by leveraging a class of nested risk measures. Specifically, RSA formulates safety alignment as a token-level risk-aware constrained policy optimization problem and solves it through a stepwise alignment procedure that yields token-level policy updates derived from the nested risk measures. This design offers two key benefits: (1) it mitigates risks induced by excessive model shift away from a reference policy, and (2) it explicitly suppresses low-probability yet high-impact harmful behaviors. Moreover, we provide theoretical analysis on policy optimality under mild assumptions. Experimental results demonstrate that our method achieves high levels of helpfulness while ensuring strong safety and significantly suppresses tail risks, namely low-probability yet high-impact unsafe responses.
$\text{H}^2$em: Learning Hierarchical Hyperbolic Embeddings for Compositional Zero-Shot Learning
Dec 23, 2025Compositional zero-shot learning (CZSL) aims to recognize unseen state-object compositions by generalizing from a training set of their primitives (state and object). Current methods often overlook the rich hierarchical structures, such as the semantic hierarchy of primitives (e.g., apple fruit) and the conceptual hierarchy between primitives and compositions (e.g, sliced apple apple). A few recent efforts have shown effectiveness in modeling these hierarchies through loss regularization within Euclidean space. In this paper, we argue that they fail to scale to the large-scale taxonomies required for real-world CZSL: the space's polynomial volume growth in flat geometry cannot match the exponential structure, impairing generalization capacity. To this end, we propose H2em, a new framework that learns Hierarchical Hyperbolic EMbeddings for CZSL. H2em leverages the unique properties of hyperbolic geometry, a space naturally suited for embedding tree-like structures with low distortion. However, a naive hyperbolic mapping may suffer from hierarchical collapse and poor fine-grained discrimination. We further design two learning objectives to structure this space: a Dual-Hierarchical Entailment Loss that uses hyperbolic entailment cones to enforce the predefined hierarchies, and a Discriminative Alignment Loss with hard negative mining to establish a large geodesic distance between semantically similar compositions. Furthermore, we devise Hyperbolic Cross-Modal Attention to realize instance-aware cross-modal infusion within hyperbolic geometry. Extensive ablations on three benchmarks demonstrate that H2em establishes a new state-of-the-art in both closed-world and open-world scenarios. Our codes will be released.
COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
Dec 10, 2025End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.
Towards Robust Protective Perturbation against DeepFake Face Swapping
Dec 08, 2025DeepFake face swapping enables highly realistic identity forgeries, posing serious privacy and security risks. A common defence embeds invisible perturbations into images, but these are fragile and often destroyed by basic transformations such as compression or resizing. In this paper, we first conduct a systematic analysis of 30 transformations across six categories and show that protection robustness is highly sensitive to the choice of training transformations, making the standard Expectation over Transformation (EOT) with uniform sampling fundamentally suboptimal. Motivated by this, we propose Expectation Over Learned distribution of Transformation (EOLT), the framework to treat transformation distribution as a learnable component rather than a fixed design choice. Specifically, EOLT employs a policy network that learns to automatically prioritize critical transformations and adaptively generate instance-specific perturbations via reinforcement learning, enabling explicit modeling of defensive bottlenecks while maintaining broad transferability. Extensive experiments demonstrate that our method achieves substantial improvements over state-of-the-art approaches, with 26% higher average robustness and up to 30% gains on challenging transformation categories.
Certified Signed Graph Unlearning
Nov 18, 2025Signed graphs model complex relationships through positive and negative edges, with widespread real-world applications. Given the sensitive nature of such data, selective removal mechanisms have become essential for privacy protection. While graph unlearning enables the removal of specific data influences from Graph Neural Networks (GNNs), existing methods are designed for conventional GNNs and overlook the unique heterogeneous properties of signed graphs. When applied to Signed Graph Neural Networks (SGNNs), these methods lose critical sign information, degrading both model utility and unlearning effectiveness. To address these challenges, we propose Certified Signed Graph Unlearning (CSGU), which provides provable privacy guarantees while preserving the sociological principles underlying SGNNs. CSGU employs a three-stage method: (1) efficiently identifying minimal influenced neighborhoods via triangular structures, (2) applying sociological theories to quantify node importance for optimal privacy budget allocation, and (3) performing importance-weighted parameter updates to achieve certified modifications with minimal utility degradation. Extensive experiments demonstrate that CSGU outperforms existing methods, achieving superior performance in both utility preservation and unlearning effectiveness on SGNNs.
Learning to Fast Unrank in Collaborative Filtering Recommendation
Nov 10, 2025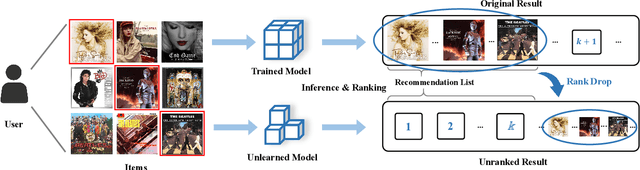
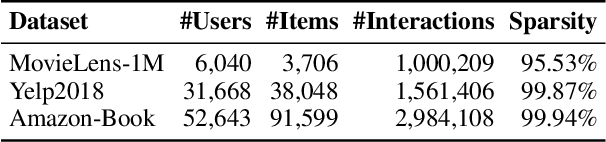
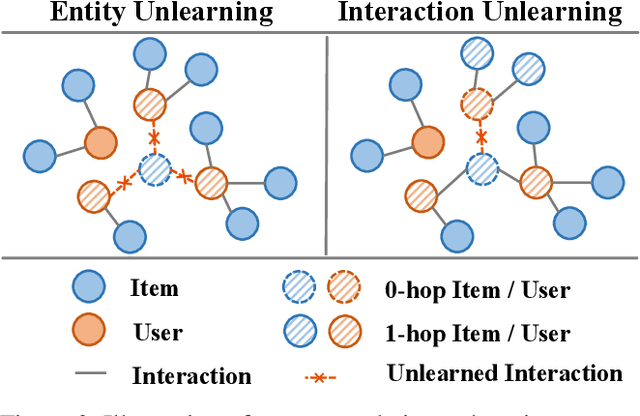
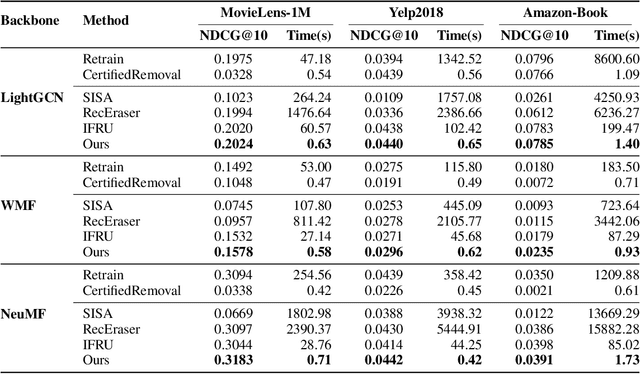
Modern data-driven recommendation systems risk memorizing sensitive user behavioral patterns, raising privacy concerns. Existing recommendation unlearning methods, while capable of removing target data influence, suffer from inefficient unlearning speed and degraded performance, failing to meet real-time unlearning demands. Considering the ranking-oriented nature of recommendation systems, we present unranking, the process of reducing the ranking positions of target items while ensuring the formal guarantees of recommendation unlearning. To achieve efficient unranking, we propose Learning to Fast Unrank in Collaborative Filtering Recommendation (L2UnRank), which operates through three key stages: (a) identifying the influenced scope via interaction-based p-hop propagation, (b) computing structural and semantic influences for entities within this scope, and (c) performing efficient, ranking-aware parameter updates guided by influence information. Extensive experiments across multiple datasets and backbone models demonstrate L2UnRank's model-agnostic nature, achieving state-of-the-art unranking effectiveness and maintaining recommendation quality comparable to retraining, while also delivering a 50x speedup over existing methods. Codes are available at https://github.com/Juniper42/L2UnRank.
Interaction-Centric Knowledge Infusion and Transfer for Open-Vocabulary Scene Graph Generation
Nov 08, 2025



Open-vocabulary scene graph generation (OVSGG) extends traditional SGG by recognizing novel objects and relationships beyond predefined categories, leveraging the knowledge from pre-trained large-scale models. Existing OVSGG methods always adopt a two-stage pipeline: 1) \textit{Infusing knowledge} into large-scale models via pre-training on large datasets; 2) \textit{Transferring knowledge} from pre-trained models with fully annotated scene graphs during supervised fine-tuning. However, due to a lack of explicit interaction modeling, these methods struggle to distinguish between interacting and non-interacting instances of the same object category. This limitation induces critical issues in both stages of OVSGG: it generates noisy pseudo-supervision from mismatched objects during knowledge infusion, and causes ambiguous query matching during knowledge transfer. To this end, in this paper, we propose an inter\textbf{AC}tion-\textbf{C}entric end-to-end OVSGG framework (\textbf{ACC}) in an interaction-driven paradigm to minimize these mismatches. For \textit{interaction-centric knowledge infusion}, ACC employs a bidirectional interaction prompt for robust pseudo-supervision generation to enhance the model's interaction knowledge. For \textit{interaction-centric knowledge transfer}, ACC first adopts interaction-guided query selection that prioritizes pairing interacting objects to reduce interference from non-interacting ones. Then, it integrates interaction-consistent knowledge distillation to bolster robustness by pushing relational foreground away from the background while retaining general knowledge. Extensive experimental results on three benchmarks show that ACC achieves state-of-the-art performance, demonstrating the potential of interaction-centric paradigms for real-world applications.