 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Self-Supervised Learning for Medical Image Segmentation Based on Multi-Domain Data Aggregation
Jul 10, 2021
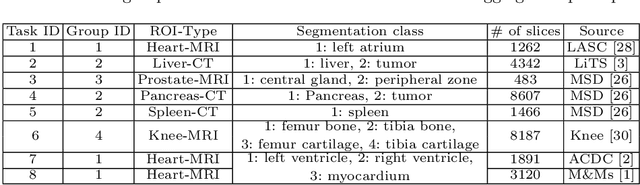
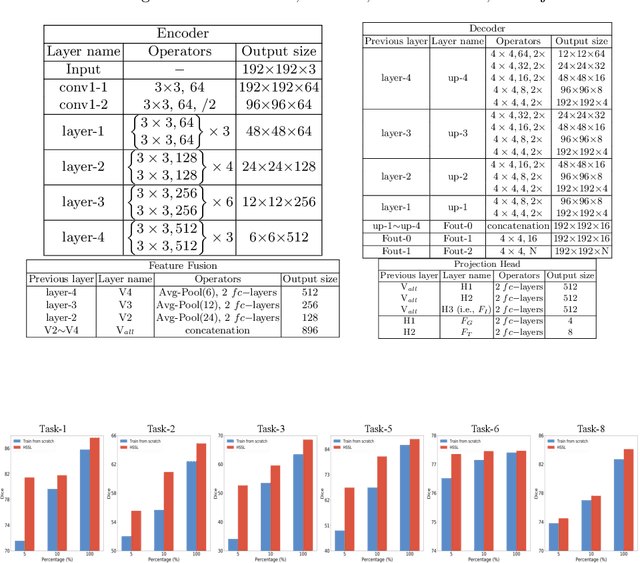
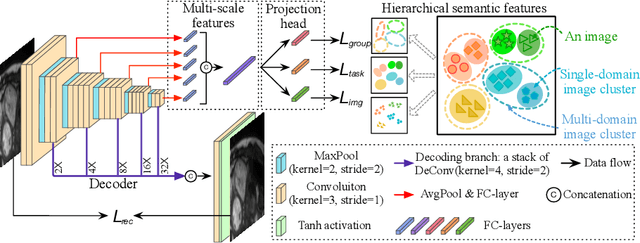
A large labeled dataset is a key to the success of supervised deep learning, but for medical image segmentation, it is highly challenging to obtain sufficient annotated images for model training. In many scenarios, unannotated images are abundant and easy to acquire. Self-supervised learning (SSL) has shown great potentials in exploiting raw data information and representation learning. In this paper, we propose Hierarchical Self-Supervised Learning (HSSL), a new self-supervised framework that boosts medical image segmentation by making good use of unannotated data. Unlike the current literature on task-specific self-supervised pretraining followed by supervised fine-tuning, we utilize SSL to learn task-agnostic knowledge from heterogeneous data for various medical image segmentation tasks. Specifically, we first aggregate a dataset from several medical challenges, then pre-train the network in a self-supervised manner, and finally fine-tune on labeled data. We develop a new loss function by combining contrastive loss and classification loss and pretrain an encoder-decoder architecture for segmentation tasks. Our extensive experiments show that multi-domain joint pre-training benefits downstream segmentation tasks and outperforms single-domain pre-training significantly. Compared to learning from scratch, our new method yields better performance on various tasks (e.g., +0.69% to +18.60% in Dice scores with 5% of annotated data). With limited amounts of training data, our method can substantially bridge the performance gap w.r.t. denser annotations (e.g., 10% vs.~100% of annotated data).
Generalizing Nucleus Recognition Model in Multi-source Images via Pruning
Jul 06, 2021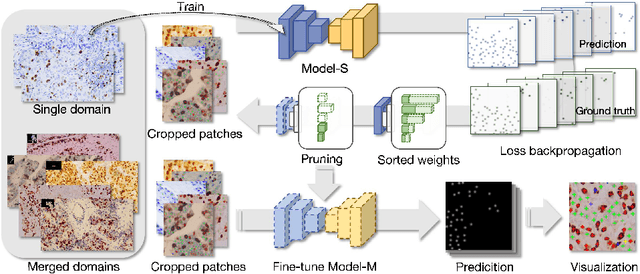
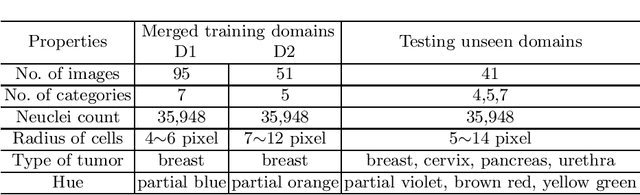
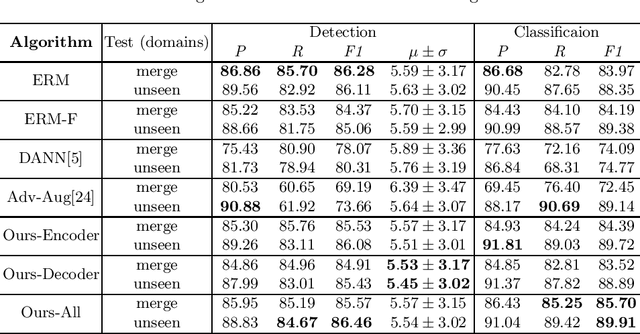
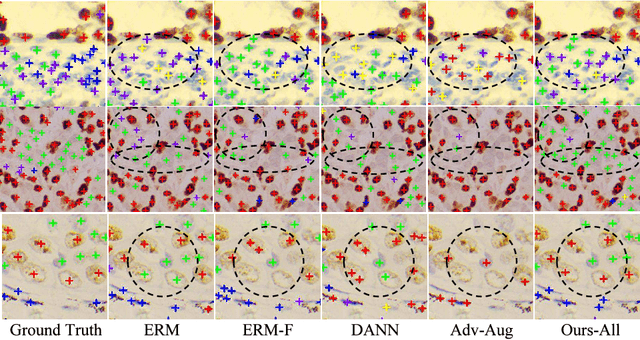
Ki67 is a significant biomarker in the diagnosis and prognosis of cancer, whose index can be evaluated by quantifying its expression in Ki67 immunohistochemistry (IHC) stained images. However, quantitative analysis on multi-source Ki67 images is yet a challenging task in practice due to cross-domain distribution differences, which result from imaging variation, staining styles, and lesion types. Many recent studies have made some efforts on domain generalization (DG), whereas there are still some noteworthy limitations. Specifically in the case of Ki67 images, learning invariant representation is at the mercy of the insufficient number of domains and the cell categories mismatching in different domains. In this paper, we propose a novel method to improve DG by searching the domain-agnostic subnetwork in a domain merging scenario. Partial model parameters are iteratively pruned according to the domain gap, which is caused by the data converting from a single domain into merged domains during training. In addition, the model is optimized by fine-tuning on merged domains to eliminate the interference of class mismatching among various domains. Furthermore, an appropriate implementation is attained by applying the pruning method to different parts of the framework. Compared with known DG methods, our method yields excellent performance in multiclass nucleus recognition of Ki67 IHC images, especially in the lost category cases. Moreover, our competitive results are also evaluated on the public dataset over the state-of-the-art DG methods.
Sparsely Overlapped Speech Training in the Time Domain: Joint Learning of Target Speech Separation and Personal VAD Benefits
Jun 28, 2021
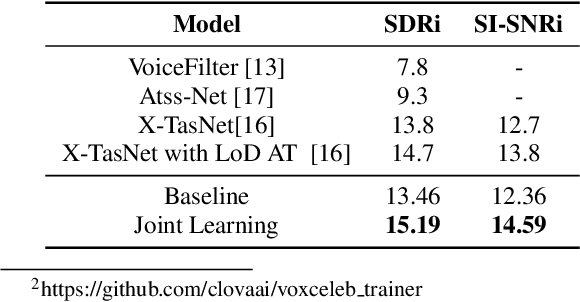
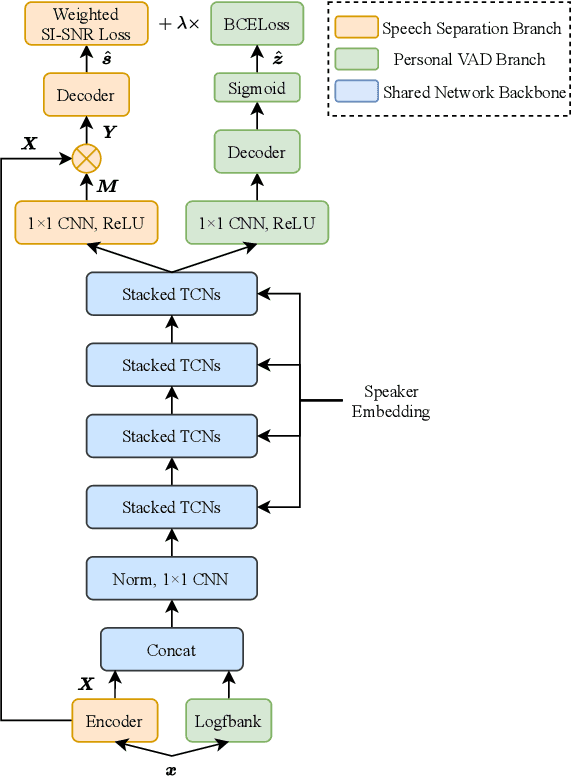
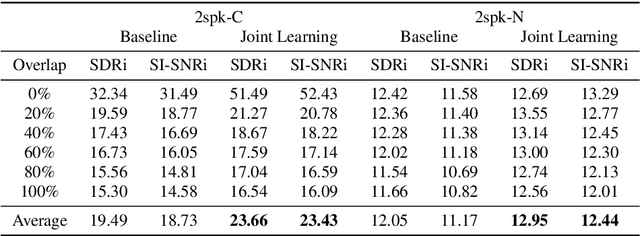
Target speech separation is the process of filtering a certain speaker's voice out of speech mixtures according to the additional speaker identity information provided. Recent works have made considerable improvement by processing signals in the time domain directly. The majority of them take fully overlapped speech mixtures for training. However, since most real-life conversations occur randomly and are sparsely overlapped, we argue that training with different overlap ratio data benefits. To do so, an unavoidable problem is that the popularly used SI-SNR loss has no definition for silent sources. This paper proposes the weighted SI-SNR loss, together with the joint learning of target speech separation and personal VAD. The weighted SI-SNR loss imposes a weight factor that is proportional to the target speaker's duration and returns zero when the target speaker is absent. Meanwhile, the personal VAD generates masks and sets non-target speech to silence. Experiments show that our proposed method outperforms the baseline by 1.73 dB in terms of SDR on fully overlapped speech, as well as by 4.17 dB and 0.9 dB on sparsely overlapped speech of clean and noisy conditions. Besides, with slight degradation in performance, our model could reduce the time costs in inference.
High-Dimensional Bayesian Optimisation with Variational Autoencoders and Deep Metric Learning
Jun 16, 2021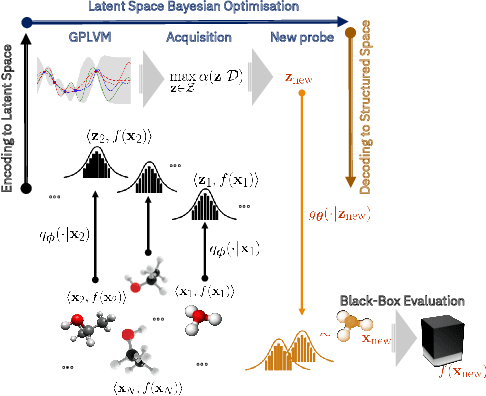

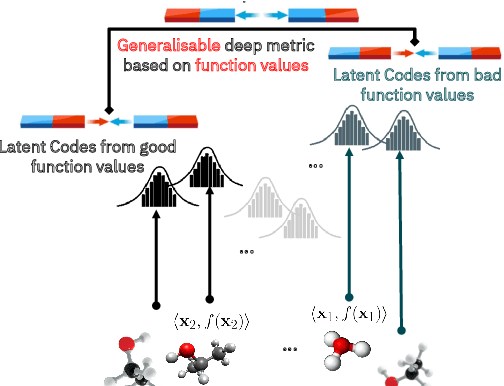

We introduce a method based on deep metric learning to perform Bayesian optimisation over high-dimensional, structured input spaces using variational autoencoders (VAEs). By extending ideas from supervised deep metric learning, we address a longstanding problem in high-dimensional VAE Bayesian optimisation, namely how to enforce a discriminative latent space as an inductive bias. Importantly, we achieve such an inductive bias using just 1% of the available labelled data relative to previous work, highlighting the sample efficiency of our approach. As a theoretical contribution, we present a proof of vanishing regret for our method. As an empirical contribution, we present state-of-the-art results on real-world high-dimensional black-box optimisation problems including property-guided molecule generation. It is the hope that the results presented in this paper can act as a guiding principle for realising effective high-dimensional Bayesian optimisation.
A comparative study of neural network techniques for automatic software vulnerability detection
Apr 29, 2021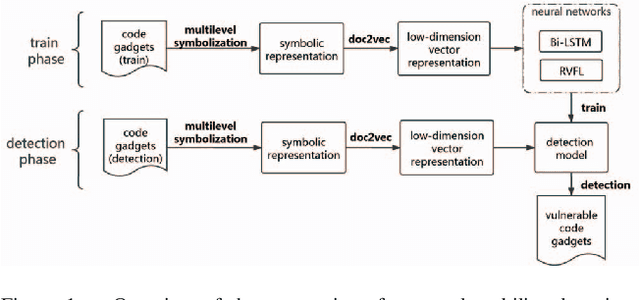
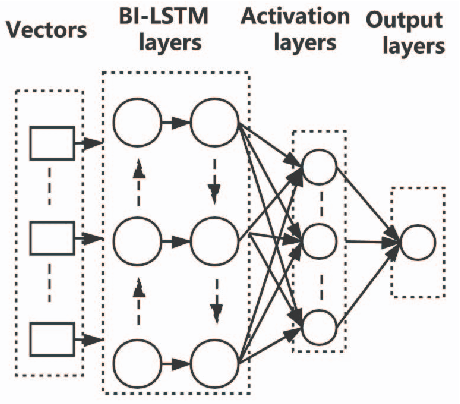
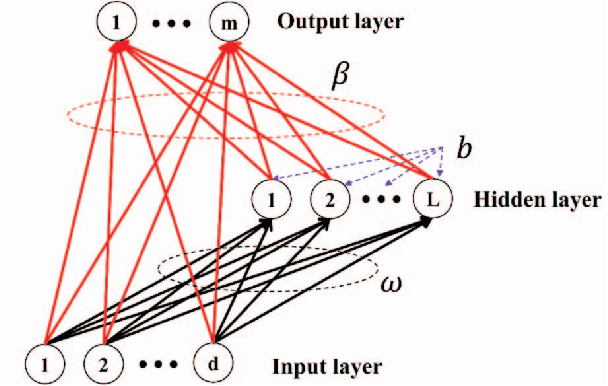
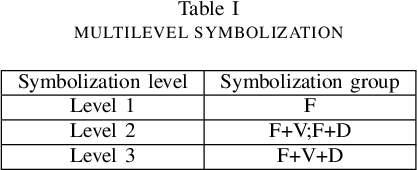
Software vulnerabilities are usually caused by design flaws or implementation errors, which could be exploited to cause damage to the security of the system. At present, the most commonly used method for detecting software vulnerabilities is static analysis. Most of the related technologies work based on rules or code similarity (source code level) and rely on manually defined vulnerability features. However, these rules and vulnerability features are difficult to be defined and designed accurately, which makes static analysis face many challenges in practical applications. To alleviate this problem, some researchers have proposed to use neural networks that have the ability of automatic feature extraction to improve the intelligence of detection. However, there are many types of neural networks, and different data preprocessing methods will have a significant impact on model performance. It is a great challenge for engineers and researchers to choose a proper neural network and data preprocessing method for a given problem. To solve this problem, we have conducted extensive experiments to test the performance of the two most typical neural networks (i.e., Bi-LSTM and RVFL) with the two most classical data preprocessing methods (i.e., the vector representation and the program symbolization methods) on software vulnerability detection problems and obtained a series of interesting research conclusions, which can provide valuable guidelines for researchers and engineers. Specifically, we found that 1) the training speed of RVFL is always faster than BiLSTM, but the prediction accuracy of Bi-LSTM model is higher than RVFL; 2) using doc2vec for vector representation can make the model have faster training speed and generalization ability than using word2vec; and 3) multi-level symbolization is helpful to improve the precision of neural network models.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021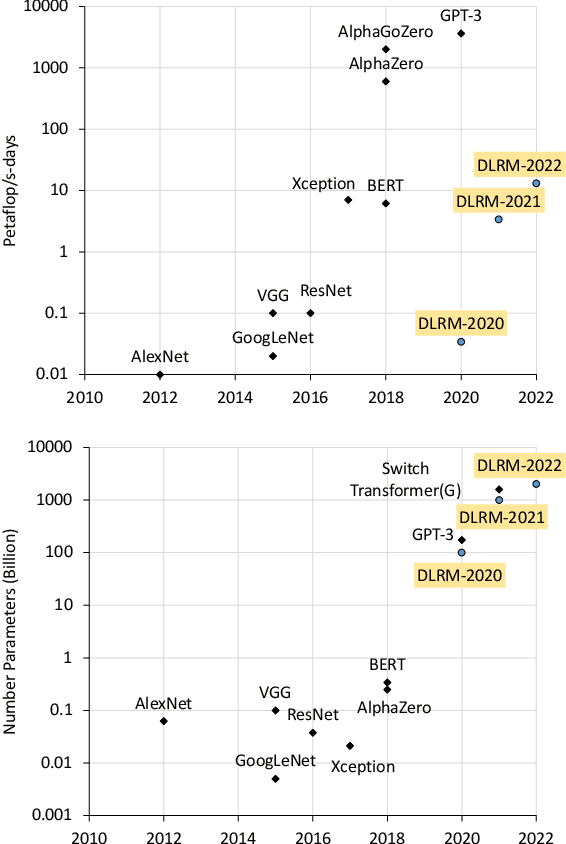

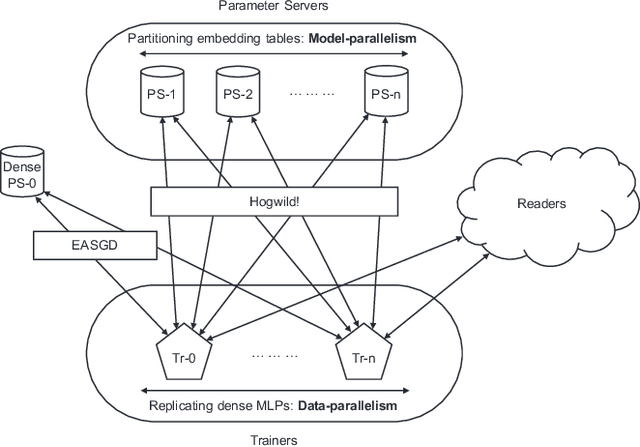
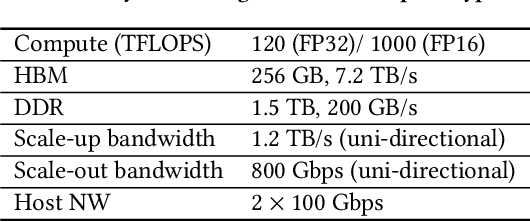
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
TransfoRNN: Capturing the Sequential Information in Self-Attention Representations for Language Modeling
Apr 04, 2021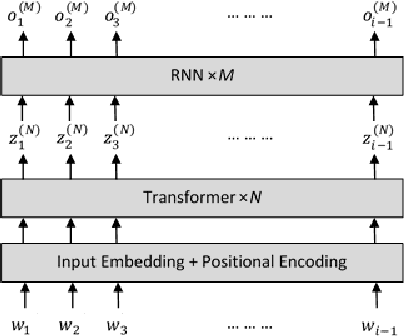
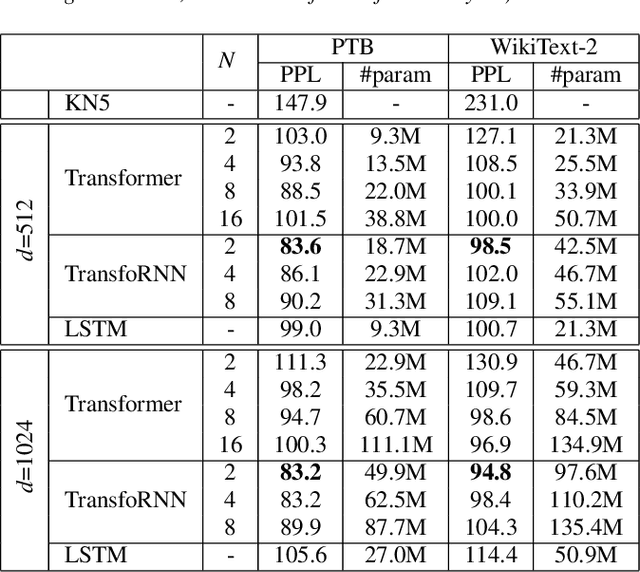
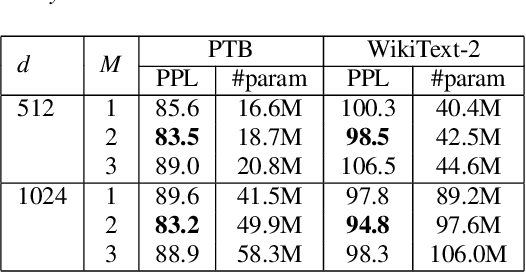
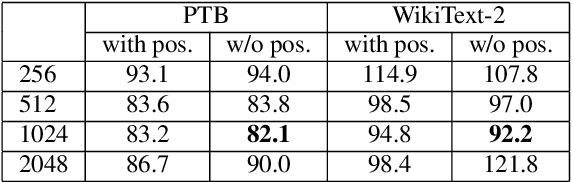
In this paper, we describe the use of recurrent neural networks to capture sequential information from the self-attention representations to improve the Transformers. Although self-attention mechanism provides a means to exploit long context, the sequential information, i.e. the arrangement of tokens, is not explicitly captured. We propose to cascade the recurrent neural networks to the Transformers, which referred to as the TransfoRNN model, to capture the sequential information. We found that the TransfoRNN models which consists of only shallow Transformers stack is suffice to give comparable, if not better, performance than a deeper Transformer model. Evaluated on the Penn Treebank and WikiText-2 corpora, the proposed TransfoRNN model has shown lower model perplexities with fewer number of model parameters. On the Penn Treebank corpus, the model perplexities were reduced up to 5.5% with the model size reduced up to 10.5%. On the WikiText-2 corpus, the model perplexity was reduced up to 2.2% with a 27.7% smaller model. Also, the TransfoRNN model was applied on the LibriSpeech speech recognition task and has shown comparable results with the Transformer models.
The DKU-Duke-Lenovo System Description for the Third DIHARD Speech Diarization Challenge
Feb 06, 2021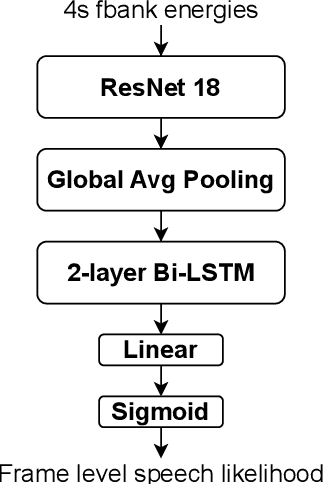
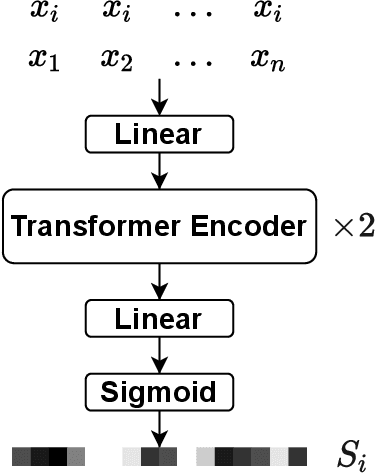
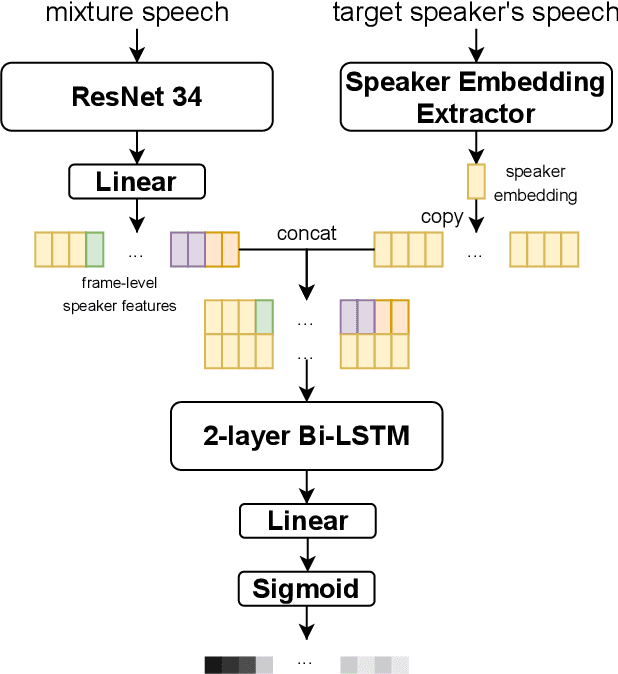

In this paper, we present the submitted system for the third DIHARD Speech Diarization Challenge from the DKU-Duke-Lenovo team. Our system consists of several modules: voice activity detection (VAD), segmentation, speaker embedding extraction, attentive similarity scoring, agglomerative hierarchical clustering. In addition, the target speaker VAD (TSVAD) is used for the phone call data to further improve the performance. Our final submitted system achieves a DER of 15.43% for the core evaluation set and 13.39% for the full evaluation set on task 1, and we also get a DER of 21.63% for core evaluation set and 18.90% for full evaluation set on task 2.
Denoising Single Voxel Magnetic Resonance Spectroscopy with Deep Learning on Repeatedly Sampled In Vivo Data
Jan 26, 2021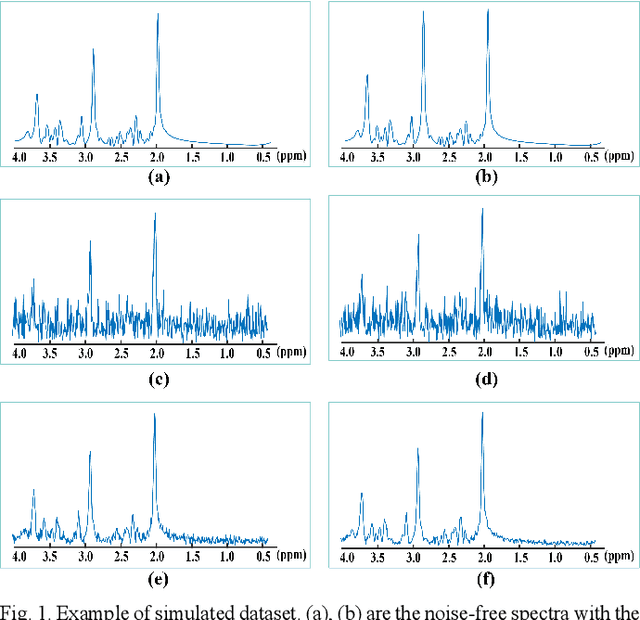
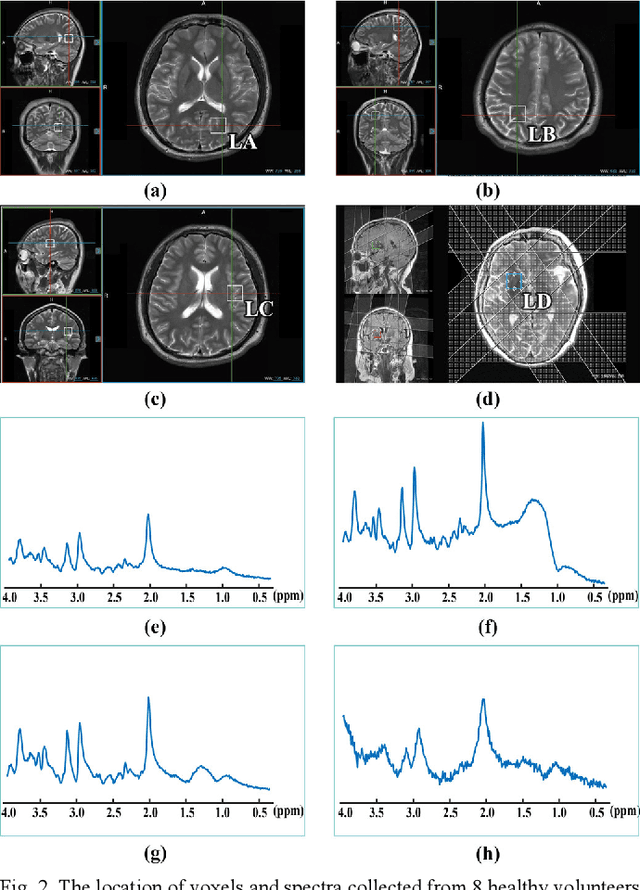
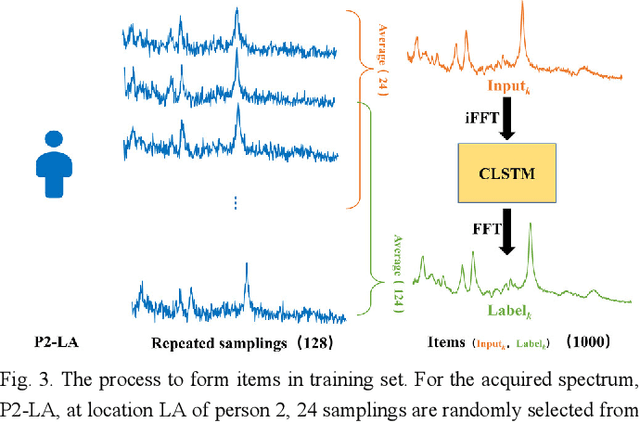
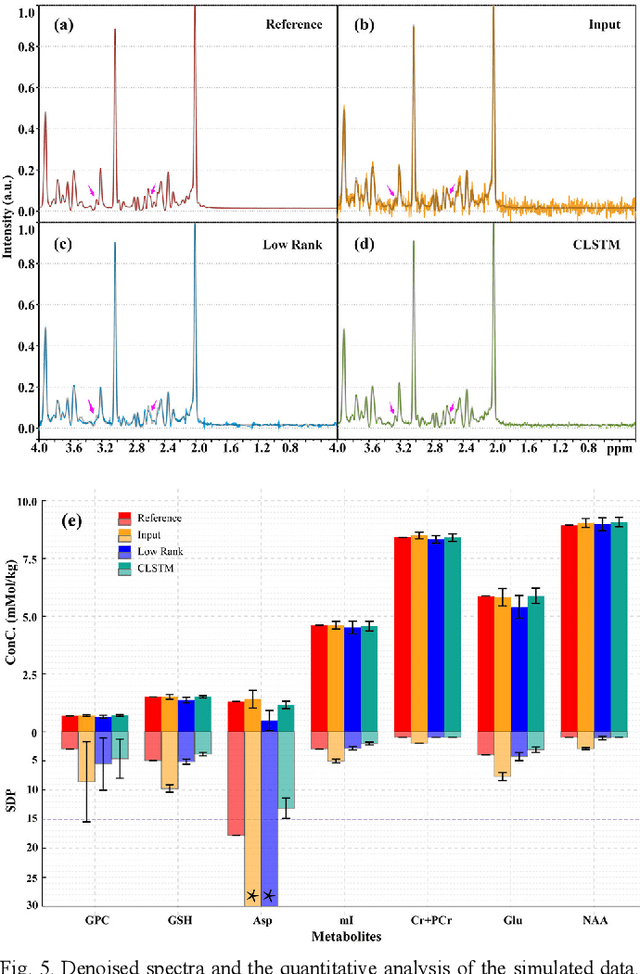
Objective: Magnetic Resonance Spectroscopy (MRS) is a noninvasive tool to reveal metabolic information. One challenge of MRS is the relatively low Signal-Noise Ratio (SNR) due to low concentrations of metabolites. To improve the SNR, the most common approach is to average signals that are acquired in multiple times. The data acquisition time, however, is increased by multiple times accordingly, resulting in the scanned objects uncomfortable or even unbearable. Methods: By exploring the multiple sampled data, a deep learning denoising approach is proposed to learn a mapping from the low SNR signal to the high SNR one. Results: Results on simulated and in vivo data show that the proposed method significantly reduces the data acquisition time with slightly compromised metabolic accuracy. Conclusion: A deep learning denoising method was proposed to significantly shorten the time of data acquisition, while maintaining signal accuracy and reliability. Significance: Provide a solution of the fundamental low SNR problem in MRS with artificial intelligence.
Unlabeled Data Guided Semi-supervised Histopathology Image Segmentation
Dec 17, 2020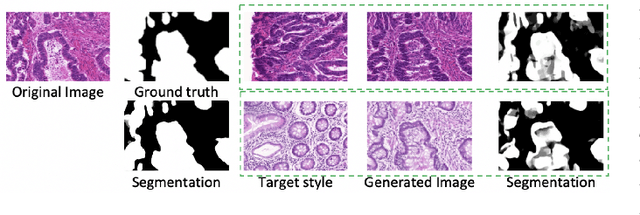
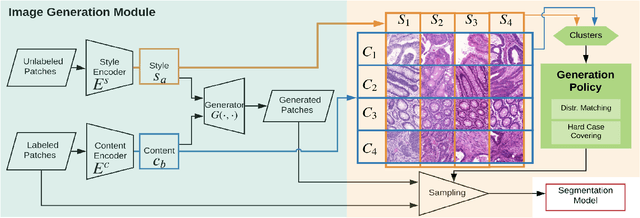
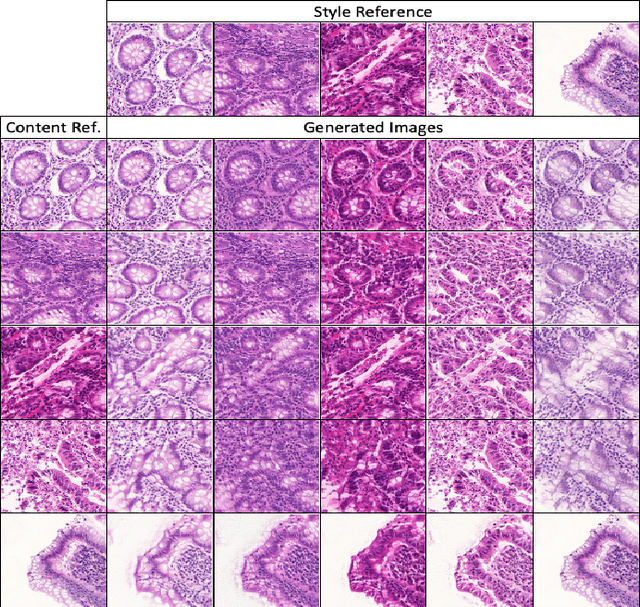
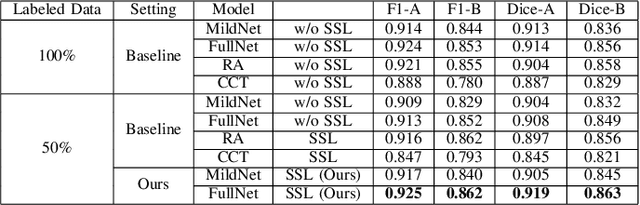
Automatic histopathology image segmentation is crucial to disease analysis. Limited available labeled data hinders the generalizability of trained models under the fully supervised setting. Semi-supervised learning (SSL) based on generative methods has been proven to be effective in utilizing diverse image characteristics. However, it has not been well explored what kinds of generated images would be more useful for model training and how to use such images. In this paper, we propose a new data guided generative method for histopathology image segmentation by leveraging the unlabeled data distributions. First, we design an image generation module. Image content and style are disentangled and embedded in a clustering-friendly space to utilize their distributions. New images are synthesized by sampling and cross-combining contents and styles. Second, we devise an effective data selection policy for judiciously sampling the generated images: (1) to make the generated training set better cover the dataset, the clusters that are underrepresented in the original training set are covered more; (2) to make the training process more effective, we identify and oversample the images of "hard cases" in the data for which annotated training data may be scarce. Our method is evaluated on glands and nuclei datasets. We show that under both the inductive and transductive settings, our SSL method consistently boosts the performance of common segmentation models and attains state-of-the-art results.