 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Assembly Sequence with Graph Transformer
Oct 12, 2022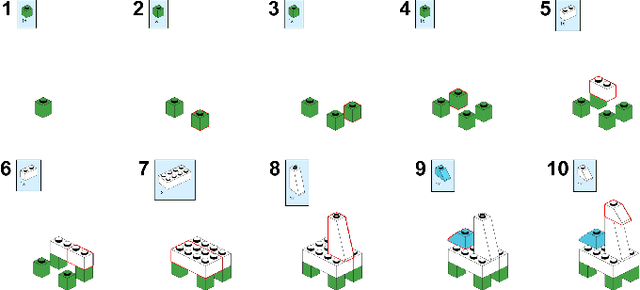
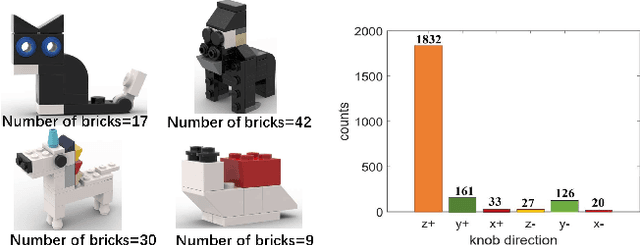

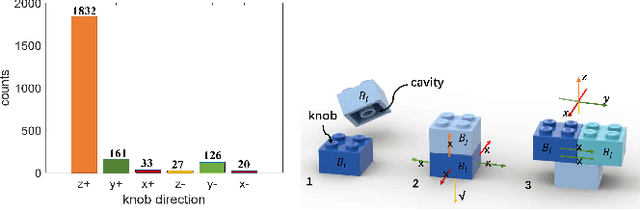
Assembly sequence planning (ASP) is the essential process for modern manufacturing, proven to be NP-complete thus its effective and efficient solution has been a challenge for researchers in the field. In this paper, we present a graph-transformer based framework for the ASP problem which is trained and demonstrated on a self-collected ASP database. The ASP database contains a self-collected set of LEGO models. The LEGO model is abstracted to a heterogeneous graph structure after a thorough analysis of the original structure and feature extraction. The ground truth assembly sequence is first generated by brute-force search and then adjusted manually to in line with human rational habits. Based on this self-collected ASP dataset, we propose a heterogeneous graph-transformer framework to learn the latent rules for assembly planning. We evaluated the proposed framework in a series of experiment. The results show that the similarity of the predicted and ground truth sequences can reach 0.44, a medium correlation measured by Kendall's $\tau$. Meanwhile, we compared the different effects of node features and edge features and generated a feasible and reasonable assembly sequence as a benchmark for further research. Our data set and code is available on https://github.com/AIR-DISCOVER/ICRA\_ASP.
Contrastive Video-Language Learning with Fine-grained Frame Sampling
Oct 10, 2022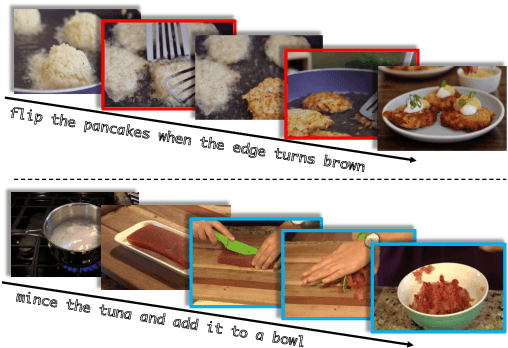
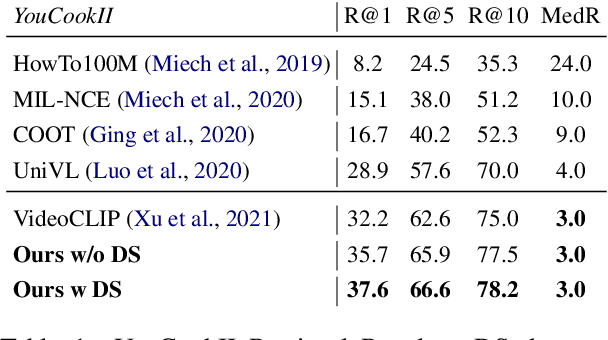
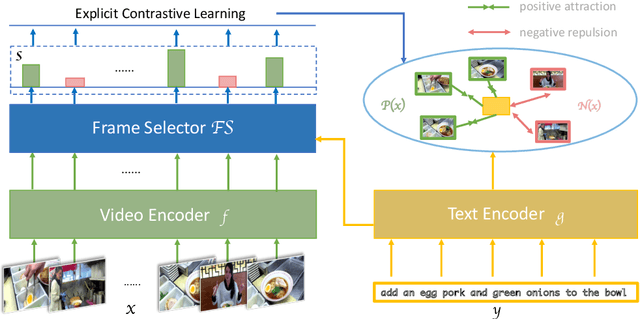
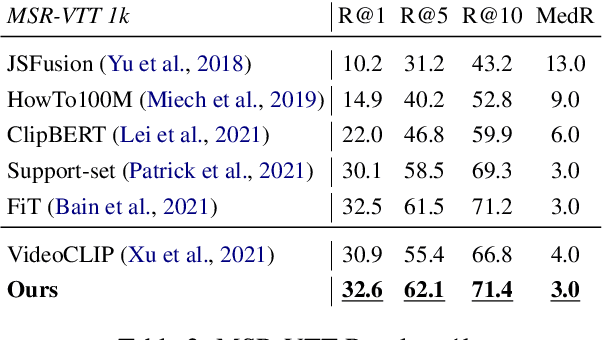
Despite recent progress in video and language representation learning, the weak or sparse correspondence between the two modalities remains a bottleneck in the area. Most video-language models are trained via pair-level loss to predict whether a pair of video and text is aligned. However, even in paired video-text segments, only a subset of the frames are semantically relevant to the corresponding text, with the remainder representing noise; where the ratio of noisy frames is higher for longer videos. We propose FineCo (Fine-grained Contrastive Loss for Frame Sampling), an approach to better learn video and language representations with a fine-grained contrastive objective operating on video frames. It helps distil a video by selecting the frames that are semantically equivalent to the text, improving cross-modal correspondence. Building on the well established VideoCLIP model as a starting point, FineCo achieves state-of-the-art performance on YouCookII, a text-video retrieval benchmark with long videos. FineCo also achieves competitive results on text-video retrieval (MSR-VTT), and video question answering datasets (MSR-VTT QA and MSR-VTT MC) with shorter videos.
Contextual Modeling for 3D Dense Captioning on Point Clouds
Oct 08, 2022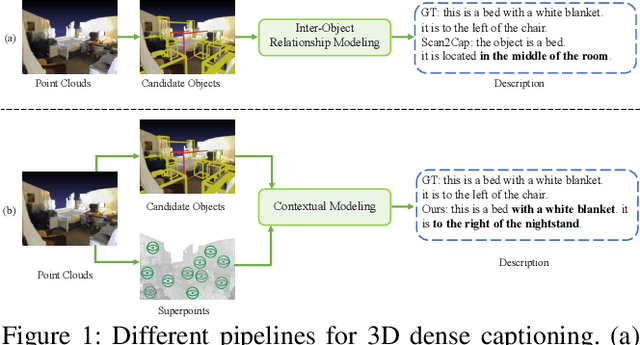
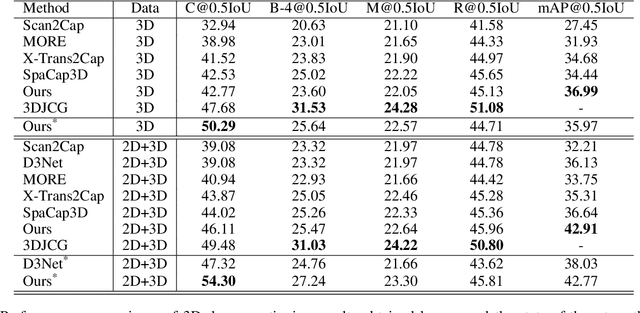
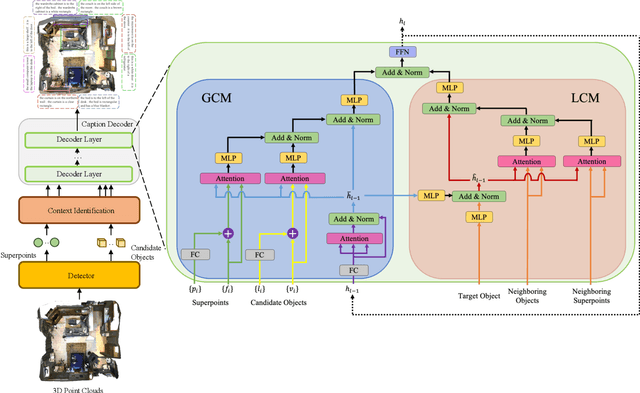
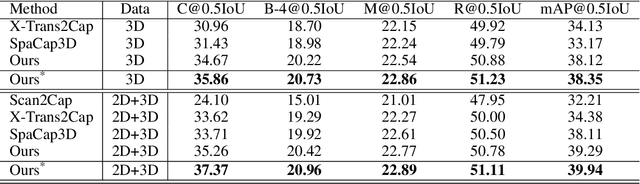
3D dense captioning, as an emerging vision-language task, aims to identify and locate each object from a set of point clouds and generate a distinctive natural language sentence for describing each located object. However, the existing methods mainly focus on mining inter-object relationship, while ignoring contextual information, especially the non-object details and background environment within the point clouds, thus leading to low-quality descriptions, such as inaccurate relative position information. In this paper, we make the first attempt to utilize the point clouds clustering features as the contextual information to supply the non-object details and background environment of the point clouds and incorporate them into the 3D dense captioning task. We propose two separate modules, namely the Global Context Modeling (GCM) and Local Context Modeling (LCM), in a coarse-to-fine manner to perform the contextual modeling of the point clouds. Specifically, the GCM module captures the inter-object relationship among all objects with global contextual information to obtain more complete scene information of the whole point clouds. The LCM module exploits the influence of the neighboring objects of the target object and local contextual information to enrich the object representations. With such global and local contextual modeling strategies, our proposed model can effectively characterize the object representations and contextual information and thereby generate comprehensive and detailed descriptions of the located objects. Extensive experiments on the ScanRefer and Nr3D datasets demonstrate that our proposed method sets a new record on the 3D dense captioning task, and verify the effectiveness of our raised contextual modeling of point clouds.
SoccerNet 2022 Challenges Results
Oct 05, 2022
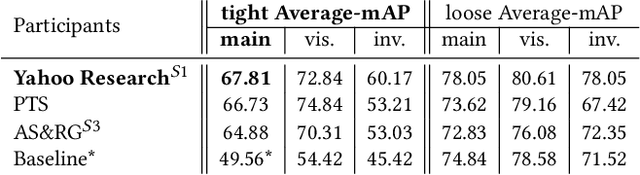
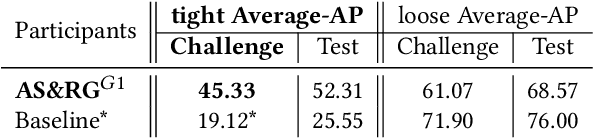
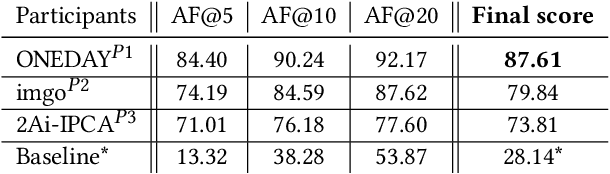
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Expansion and Shrinkage of Localization for Weakly-Supervised Semantic Segmentation
Sep 20, 2022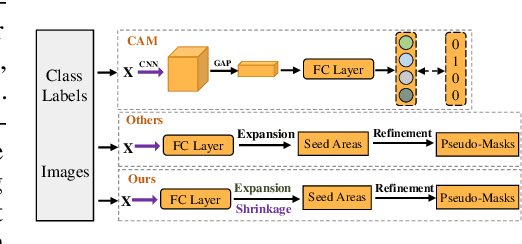
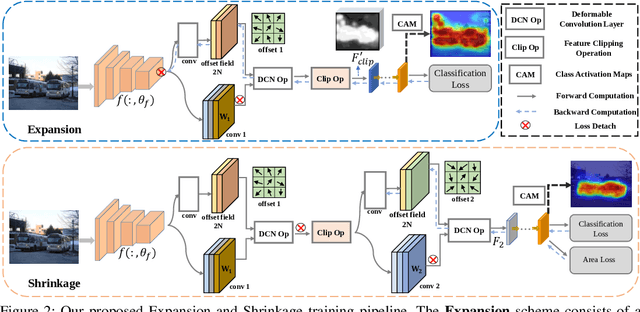

Generating precise class-aware pseudo ground-truths, a.k.a, class activation maps (CAMs), is essential for weakly-supervised semantic segmentation. The original CAM method usually produces incomplete and inaccurate localization maps. To tackle with this issue, this paper proposes an Expansion and Shrinkage scheme based on the offset learning in the deformable convolution, to sequentially improve the recall and precision of the located object in the two respective stages. In the Expansion stage, an offset learning branch in a deformable convolution layer, referred as "expansion sampler" seeks for sampling increasingly less discriminative object regions, driven by an inverse supervision signal that maximizes image-level classification loss. The located more complete object in the Expansion stage is then gradually narrowed down to the final object region during the Shrinkage stage. In the Shrinkage stage, the offset learning branch of another deformable convolution layer, referred as "shrinkage sampler", is introduced to exclude the false positive background regions attended in the Expansion stage to improve the precision of the localization maps. We conduct various experiments on PASCAL VOC 2012 and MS COCO 2014 to well demonstrate the superiority of our method over other state-of-the-art methods for weakly-supervised semantic segmentation. Code will be made publicly available here https://github.com/TyroneLi/ESOL_WSSS.
Reweighting Clicks with Dwell Time in Recommendation
Sep 19, 2022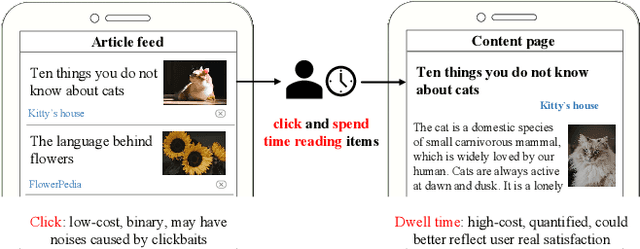

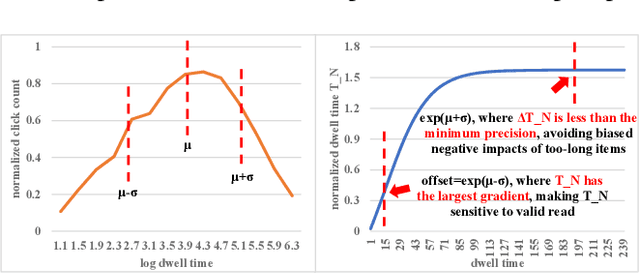
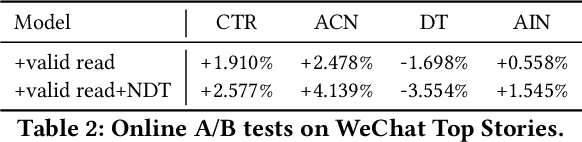
The click behavior is the most widely-used user positive feedback in recommendation. However, simply considering each click equally in training may suffer from clickbaits and title-content mismatching, and thus fail to precisely capture users' real satisfaction on items. Dwell time could be viewed as a high-quality quantitative indicator of user preferences on each click, while existing recommendation models do not fully explore the modeling of dwell time. In this work, we focus on reweighting clicks with dwell time in recommendation. Precisely, we first define a new behavior named valid read, which helps to select high-quality click instances for different users and items via dwell time. Next, we propose a normalized dwell time function to reweight click signals in training, which could better guide our model to provide a high-quality and efficient reading. The Click reweighting model achieves significant improvements on both offline and online evaluations in a real-world system.
A Novel Framework based on Unknown Estimation via Principal Sub-space for Universal Domain Adaption
Sep 19, 2022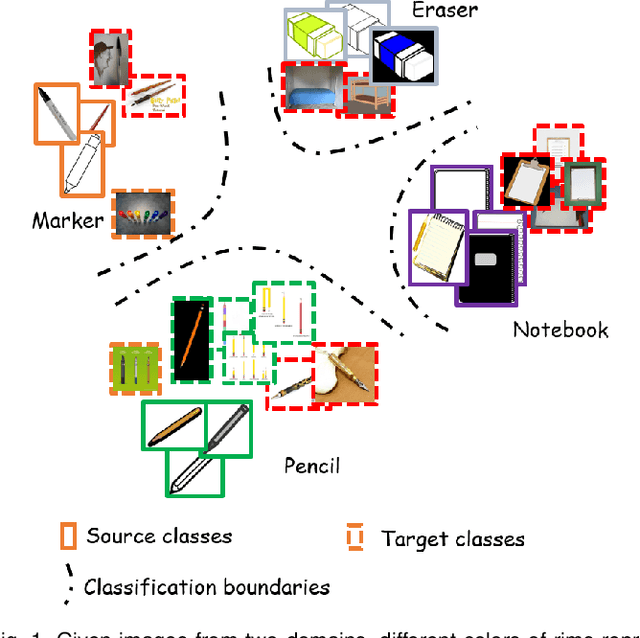
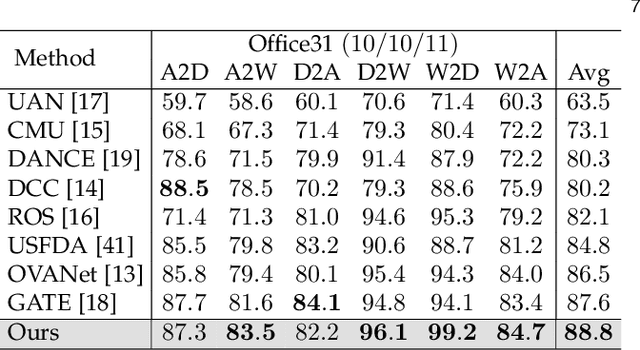
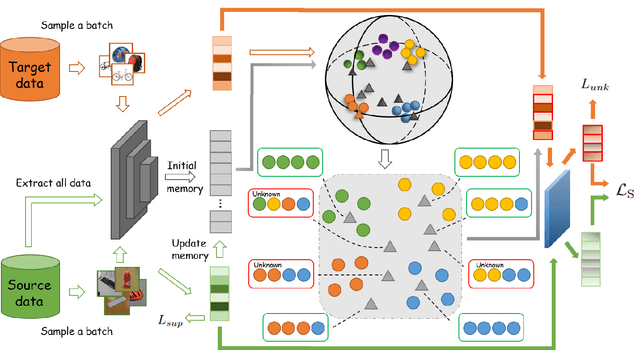
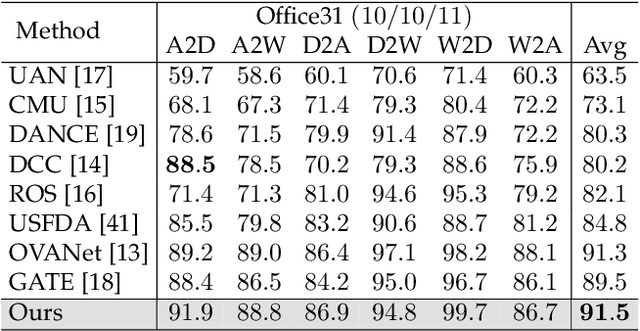
Universal domain adaptation (UniDA) aims to transfer the knowledge of common classes from source domain to target domain without any prior knowledge on the label set, which requires to distinguish the unknown samples from the known ones in the target domain. Like the traditional unsupervised domain adaptation problem, the misalignment between two domains exists due to the biased and less-discriminative embedding. Recent methods proposed to complete the domain misalignment by clustering target samples with the nearest neighbors or the prototypes. However, it is dangerous to do so since we do not have any prior knowledge about the distributions of unknown samples which can magnify the misalignment especially when the unknown set is big. Meanwhile, other existing classifier-based methods could easily produce overconfident predictions of unknown samples because of the supervised objective in source domain leading the whole model to be biased towards the common classes in the target domain. Therefore, we propose a novel non-parameter unknown samples detection method based on mapping the samples in the original feature space into a reliable linear sub-space which makes data points more sparse to reduce the misalignment between unknown samples and source samples. Moreover, unlike the recent methods applying extra parameters to improve the classification of unknown samples, this paper well balances the confidence values of both known and unknown samples through an unknown-adaptive margin loss which can control the gradient updating of the classifier learning on supervised source samples depending on the confidence level of detected unknown samples at current step. Finally, experiments on four public datasets demonstrate that our method significantly outperforms existing state-of-the-art methods.
Weakly Supervised Semantic Segmentation via Progressive Patch Learning
Sep 16, 2022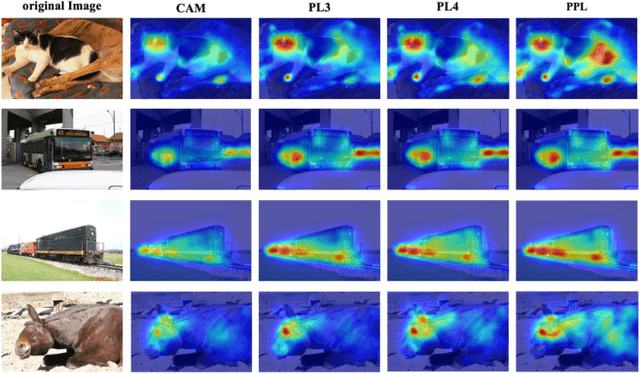
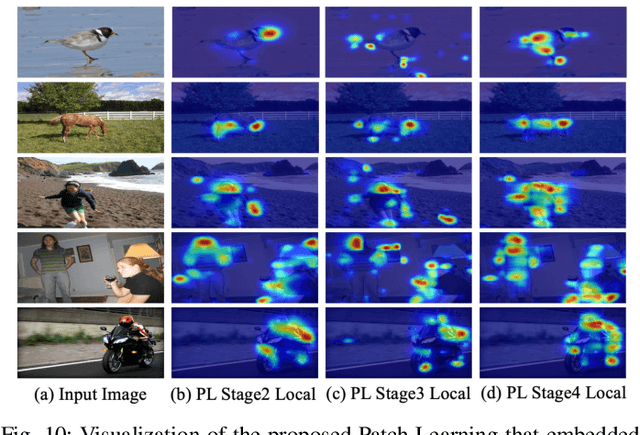
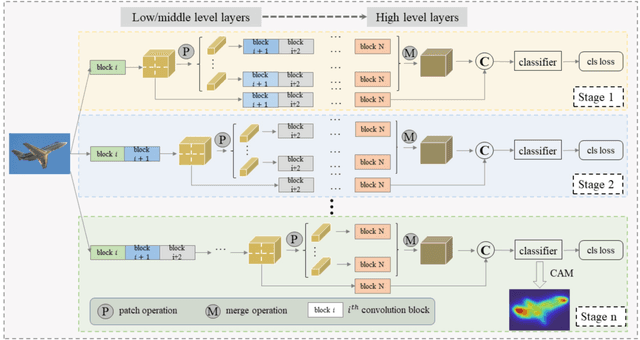
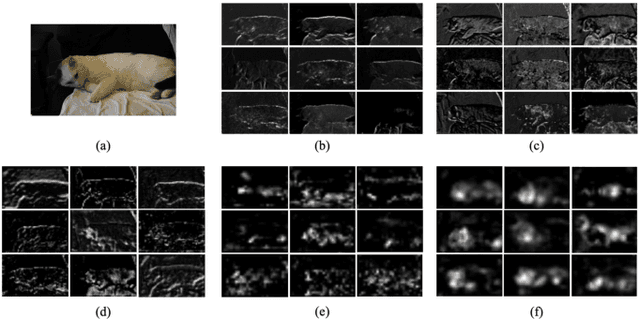
Most of the existing semantic segmentation approaches with image-level class labels as supervision, highly rely on the initial class activation map (CAM) generated from the standard classification network. In this paper, a novel "Progressive Patch Learning" approach is proposed to improve the local details extraction of the classification, producing the CAM better covering the whole object rather than only the most discriminative regions as in CAMs obtained in conventional classification models. "Patch Learning" destructs the feature maps into patches and independently processes each local patch in parallel before the final aggregation. Such a mechanism enforces the network to find weak information from the scattered discriminative local parts, achieving enhanced local details sensitivity. "Progressive Patch Learning" further extends the feature destruction and patch learning to multi-level granularities in a progressive manner. Cooperating with a multi-stage optimization strategy, such a "Progressive Patch Learning" mechanism implicitly provides the model with the feature extraction ability across different locality-granularities. As an alternative to the implicit multi-granularity progressive fusion approach, we additionally propose an explicit method to simultaneously fuse features from different granularities in a single model, further enhancing the CAM quality on the full object coverage. Our proposed method achieves outstanding performance on the PASCAL VOC 2012 dataset e.g., with 69.6$% mIoU on the test set), which surpasses most existing weakly supervised semantic segmentation methods. Code will be made publicly available here https://github.com/TyroneLi/PPL_WSSS.
MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
Sep 07, 2022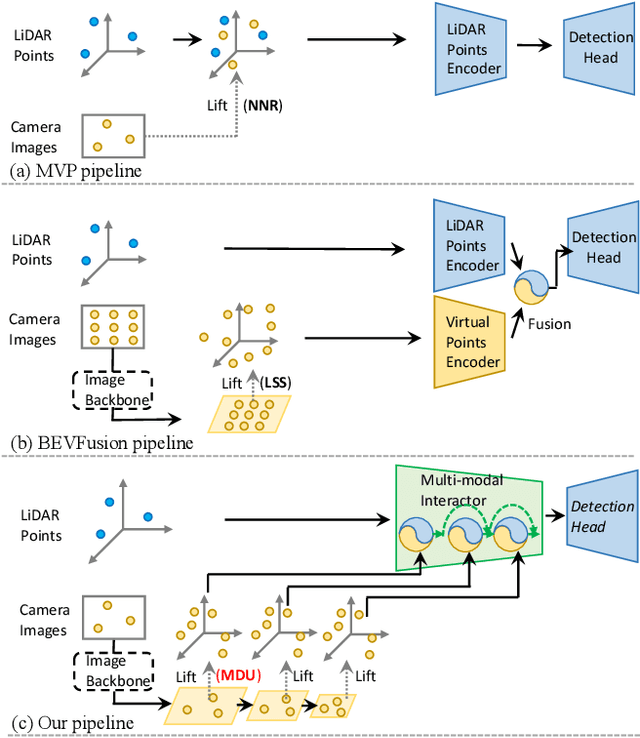
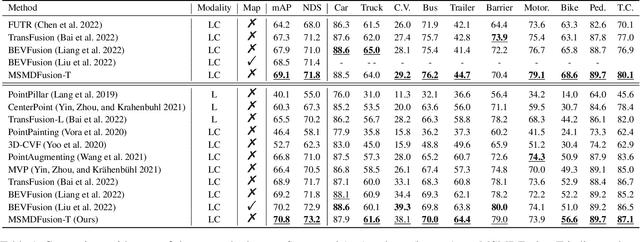
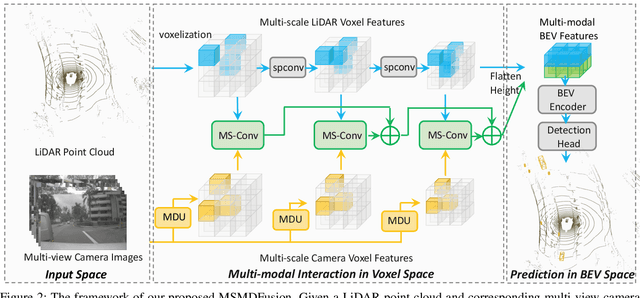
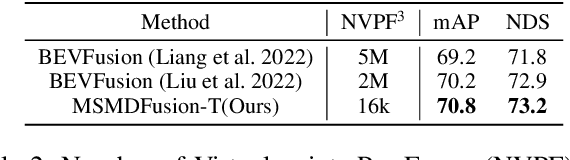
Fusing LiDAR and camera information is essential for achieving accurate and reliable 3D object detection in autonomous driving systems. However, this is challenging due to the difficulty of combining multi-granularity geometric and semantic features from two drastically different modalities. Recent approaches aim at exploring the semantic densities of camera features through lifting points in 2D camera images (referred to as seeds) into 3D space for fusion, and they can be roughly divided into 1) early fusion of raw points that aims at augmenting the 3D point cloud at the early input stage, and 2) late fusion of BEV (bird-eye view) maps that merges LiDAR and camera BEV features before the detection head. While both have their merits in enhancing the representation power of the combined features, this single-level fusion strategy is a suboptimal solution to the aforementioned challenge. Their major drawbacks are the inability to interact the multi-granularity semantic features from two distinct modalities sufficiently. To this end, we propose a novel framework that focuses on the multi-scale progressive interaction of the multi-granularity LiDAR and camera features. Our proposed method, abbreviated as MDMSFusion, achieves state-of-the-art results in 3D object detection, with 69.1 mAP and 71.8 NDS on nuScenes validation set, and 70.8 mAP and 73.2 NDS on nuScenes test set, which rank 1st and 2nd respectively among single-model non-ensemble approaches by the time of submission.
A Circular Window-based Cascade Transformer for Online Action Detection
Aug 30, 2022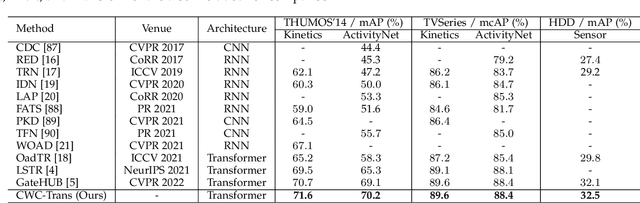
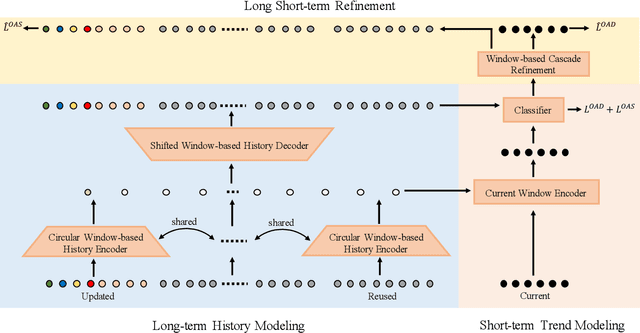
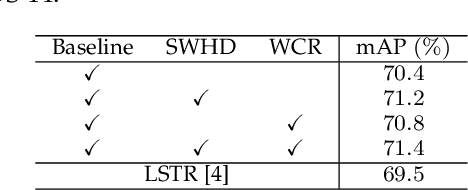
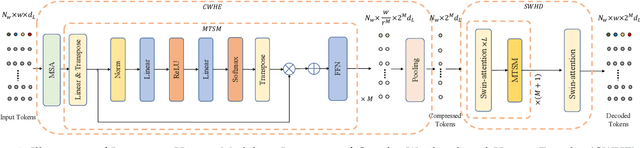
Online action detection aims at the accurate action prediction of the current frame based on long historical observations. Meanwhile, it demands real-time inference on online streaming videos. In this paper, we advocate a novel and efficient principle for online action detection. It merely updates the latest and oldest historical representations in one window but reuses the intermediate ones, which have been already computed. Based on this principle, we introduce a window-based cascade Transformer with a circular historical queue, where it conducts multi-stage attentions and cascade refinement on each window. We also explore the association between online action detection and its counterpart offline action segmentation as an auxiliary task. We find that such an extra supervision helps discriminative history clustering and acts as feature augmentation for better training the classifier and cascade refinement. Our proposed method achieves the state-of-the-art performances on three challenging datasets THUMOS'14, TVSeries, and HDD. Codes will be available after acceptance.