 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompBench: Benchmarking Complex Instruction-guided Image Editing
May 18, 2025While real-world applications increasingly demand intricate scene manipulation, existing instruction-guided image editing benchmarks often oversimplify task complexity and lack comprehensive, fine-grained instructions. To bridge this gap, we introduce, a large-scale benchmark specifically designed for complex instruction-guided image editing. CompBench features challenging editing scenarios that incorporate fine-grained instruction following, spatial and contextual reasoning, thereby enabling comprehensive evaluation of image editing models' precise manipulation capabilities. To construct CompBench, We propose an MLLM-human collaborative framework with tailored task pipelines. Furthermore, we propose an instruction decoupling strategy that disentangles editing intents into four key dimensions: location, appearance, dynamics, and objects, ensuring closer alignment between instructions and complex editing requirements. Extensive evaluations reveal that CompBench exposes fundamental limitations of current image editing models and provides critical insights for the development of next-generation instruction-guided image editing systems.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
GauS-SLAM: Dense RGB-D SLAM with Gaussian Surfels
May 03, 2025



We propose GauS-SLAM, a dense RGB-D SLAM system that leverages 2D Gaussian surfels to achieve robust tracking and high-fidelity mapping. Our investigations reveal that Gaussian-based scene representations exhibit geometry distortion under novel viewpoints, which significantly degrades the accuracy of Gaussian-based tracking methods. These geometry inconsistencies arise primarily from the depth modeling of Gaussian primitives and the mutual interference between surfaces during the depth blending. To address these, we propose a 2D Gaussian-based incremental reconstruction strategy coupled with a Surface-aware Depth Rendering mechanism, which significantly enhances geometry accuracy and multi-view consistency. Additionally, the proposed local map design dynamically isolates visible surfaces during tracking, mitigating misalignment caused by occluded regions in global maps while maintaining computational efficiency with increasing Gaussian density. Extensive experiments across multiple datasets demonstrate that GauS-SLAM outperforms comparable methods, delivering superior tracking precision and rendering fidelity. The project page will be made available at https://gaus-slam.github.io.
Scaling On-Device GPU Inference for Large Generative Models
May 01, 2025Driven by the advancements in generative AI, large machine learning models have revolutionized domains such as image processing, audio synthesis, and speech recognition. While server-based deployments remain the locus of peak performance, the imperative for on-device inference, necessitated by privacy and efficiency considerations, persists. Recognizing GPUs as the on-device ML accelerator with the widest reach, we present ML Drift--an optimized framework that extends the capabilities of state-of-the-art GPU-accelerated inference engines. ML Drift enables on-device execution of generative AI workloads which contain 10 to 100x more parameters than existing on-device generative AI models. ML Drift addresses intricate engineering challenges associated with cross-GPU API development, and ensures broad compatibility across mobile and desktop/laptop platforms, thereby facilitating the deployment of significantly more complex models on resource-constrained devices. Our GPU-accelerated ML/AI inference engine achieves an order-of-magnitude performance improvement relative to existing open-source GPU inference engines.
Bipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
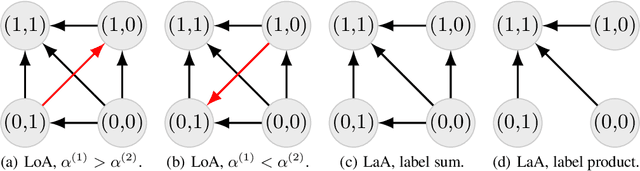

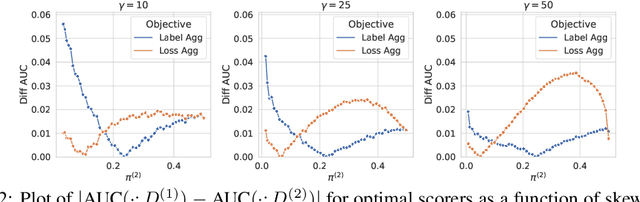
Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
VCR-Bench: A Comprehensive Evaluation Framework for Video Chain-of-Thought Reasoning
Apr 10, 2025The advancement of Chain-of-Thought (CoT) reasoning has significantly enhanced the capabilities of large language models (LLMs) and large vision-language models (LVLMs). However, a rigorous evaluation framework for video CoT reasoning remains absent. Current video benchmarks fail to adequately assess the reasoning process and expose whether failures stem from deficiencies in perception or reasoning capabilities. Therefore, we introduce VCR-Bench, a novel benchmark designed to comprehensively evaluate LVLMs' Video Chain-of-Thought Reasoning capabilities. VCR-Bench comprises 859 videos spanning a variety of video content and durations, along with 1,034 high-quality question-answer pairs. Each pair is manually annotated with a stepwise CoT rationale, where every step is tagged to indicate its association with the perception or reasoning capabilities. Furthermore, we design seven distinct task dimensions and propose the CoT score to assess the entire CoT process based on the stepwise tagged CoT rationals. Extensive experiments on VCR-Bench highlight substantial limitations in current LVLMs. Even the top-performing model, o1, only achieves a 62.8% CoT score and an 56.7% accuracy, while most models score below 40%. Experiments show most models score lower on perception than reasoning steps, revealing LVLMs' key bottleneck in temporal-spatial information processing for complex video reasoning. A robust positive correlation between the CoT score and accuracy confirms the validity of our evaluation framework and underscores the critical role of CoT reasoning in solving complex video reasoning tasks. We hope VCR-Bench to serve as a standardized evaluation framework and expose the actual drawbacks in complex video reasoning task.
Temporal-contextual Event Learning for Pedestrian Crossing Intent Prediction
Apr 04, 2025Ensuring the safety of vulnerable road users through accurate prediction of pedestrian crossing intention (PCI) plays a crucial role in the context of autonomous and assisted driving. Analyzing the set of observation video frames in ego-view has been widely used in most PCI prediction methods to forecast the cross intent. However, they struggle to capture the critical events related to pedestrian behaviour along the temporal dimension due to the high redundancy of the video frames, which results in the sub-optimal performance of PCI prediction. Our research addresses the challenge by introducing a novel approach called \underline{T}emporal-\underline{c}ontextual Event \underline{L}earning (TCL). The TCL is composed of the Temporal Merging Module (TMM), which aims to manage the redundancy by clustering the observed video frames into multiple key temporal events. Then, the Contextual Attention Block (CAB) is employed to adaptively aggregate multiple event features along with visual and non-visual data. By synthesizing the temporal feature extraction and contextual attention on the key information across the critical events, TCL can learn expressive representation for the PCI prediction. Extensive experiments are carried out on three widely adopted datasets, including PIE, JAAD-beh, and JAAD-all. The results show that TCL substantially surpasses the state-of-the-art methods. Our code can be accessed at https://github.com/dadaguailhb/TCL.
Semantic-guided Representation Learning for Multi-Label Recognition
Apr 04, 2025Multi-label Recognition (MLR) involves assigning multiple labels to each data instance in an image, offering advantages over single-label classification in complex scenarios. However, it faces the challenge of annotating all relevant categories, often leading to uncertain annotations, such as unseen or incomplete labels. Recent Vision and Language Pre-training (VLP) based methods have made significant progress in tackling zero-shot MLR tasks by leveraging rich vision-language correlations. However, the correlation between multi-label semantics has not been fully explored, and the learned visual features often lack essential semantic information. To overcome these limitations, we introduce a Semantic-guided Representation Learning approach (SigRL) that enables the model to learn effective visual and textual representations, thereby improving the downstream alignment of visual images and categories. Specifically, we first introduce a graph-based multi-label correlation module (GMC) to facilitate information exchange between labels, enriching the semantic representation across the multi-label texts. Next, we propose a Semantic Visual Feature Reconstruction module (SVFR) to enhance the semantic information in the visual representation by integrating the learned textual representation during reconstruction. Finally, we optimize the image-text matching capability of the VLP model using both local and global features to achieve zero-shot MLR. Comprehensive experiments are conducted on several MLR benchmarks, encompassing both zero-shot MLR (with unseen labels) and single positive multi-label learning (with limited labels), demonstrating the superior performance of our approach compared to state-of-the-art methods. The code is available at https://github.com/MVL-Lab/SigRL.
Temporal Gaussian Copula For Clinical Multivariate Time Series Data Imputation
Apr 03, 2025The imputation of the Multivariate time series (MTS) is particularly challenging since the MTS typically contains irregular patterns of missing values due to various factors such as instrument failures, interference from irrelevant data, and privacy regulations. Existing statistical methods and deep learning methods have shown promising results in time series imputation. In this paper, we propose a Temporal Gaussian Copula Model (TGC) for three-order MTS imputation. The key idea is to leverage the Gaussian Copula to explore the cross-variable and temporal relationships based on the latent Gaussian representation. Subsequently, we employ an Expectation-Maximization (EM) algorithm to improve robustness in managing data with varying missing rates. Comprehensive experiments were conducted on three real-world MTS datasets. The results demonstrate that our TGC substantially outperforms the state-of-the-art imputation methods. Additionally, the TGC model exhibits stronger robustness to the varying missing ratios in the test dataset. Our code is available at https://github.com/MVL-Lab/TGC-MTS.
A Method for Evaluating the Interpretability of Machine Learning Models in Predicting Bond Default Risk Based on LIME and SHAP
Feb 26, 2025Interpretability analysis methods for artificial intelligence models, such as LIME and SHAP, are widely used, though they primarily serve as post-model for analyzing model outputs. While it is commonly believed that the transparency and interpretability of AI models diminish as their complexity increases, currently there is no standardized method for assessing the inherent interpretability of the models themselves. This paper uses bond market default prediction as a case study, applying commonly used machine learning algorithms within AI models. First, the classification performance of these algorithms in default prediction is evaluated. Then, leveraging LIME and SHAP to assess the contribution of sample features to prediction outcomes, the paper proposes a novel method for evaluating the interpretability of the models themselves. The results of this analysis are consistent with the intuitive understanding and logical expectations regarding the interpretability of these models.