 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering
Aug 15, 2022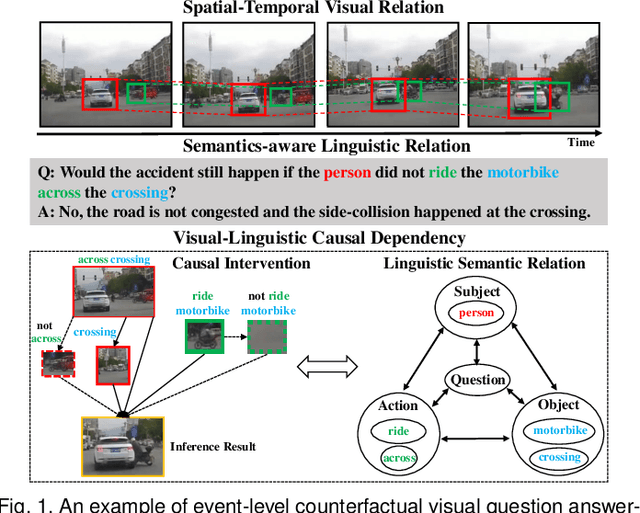
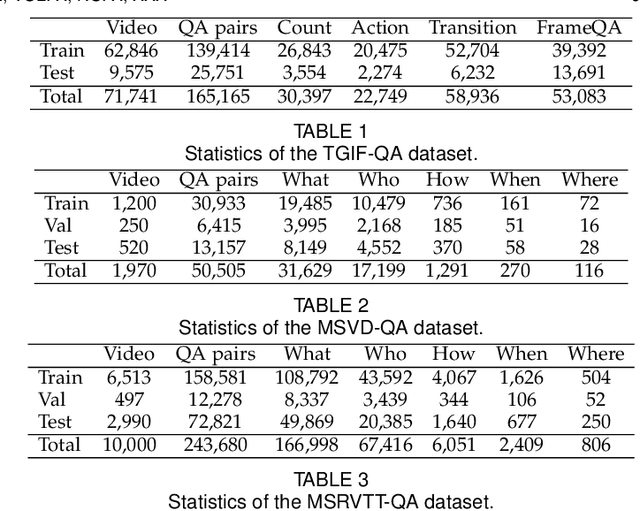
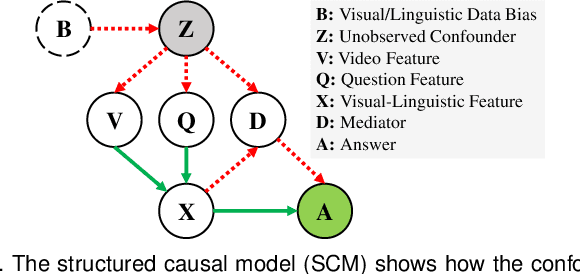
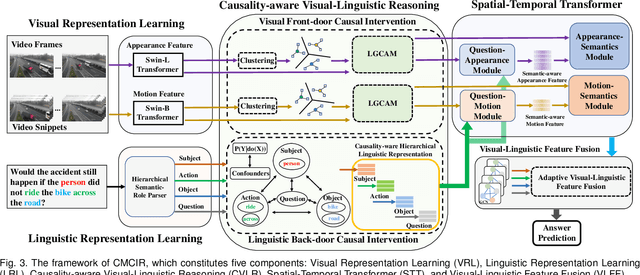
Existing visual question answering methods tend to capture the spurious correlations from visual and linguistic modalities, and fail to discover the true casual mechanism that facilitates reasoning truthfully based on the dominant visual evidence and the correct question intention. Additionally, the existing methods usually ignore the complex event-level understanding in multi-modal settings that requires a strong cognitive capability of causal inference to jointly model cross-modal event temporality, causality, and dynamics. In this work, we focus on event-level visual question answering from a new perspective, i.e., cross-modal causal relational reasoning, by introducing causal intervention methods to mitigate the spurious correlations and discover the true causal structures for the integration of visual and linguistic modalities. Specifically, we propose a novel event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to achieve robust casuality-aware visual-linguistic question answering. To uncover the causal structures for visual and linguistic modalities, the novel Causality-aware Visual-Linguistic Reasoning (CVLR) module is proposed to collaboratively disentangle the visual and linguistic spurious correlations via elaborately designed front-door and back-door causal intervention modules. To discover the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build a novel Spatial-Temporal Transformer (STT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on large-scale event-level urban dataset SUTD-TrafficQA and three benchmark real-world datasets TGIF-QA, MSVD-QA, and MSRVTT-QA demonstrate the effectiveness of our CMCIR for discovering visual-linguistic causal structures.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022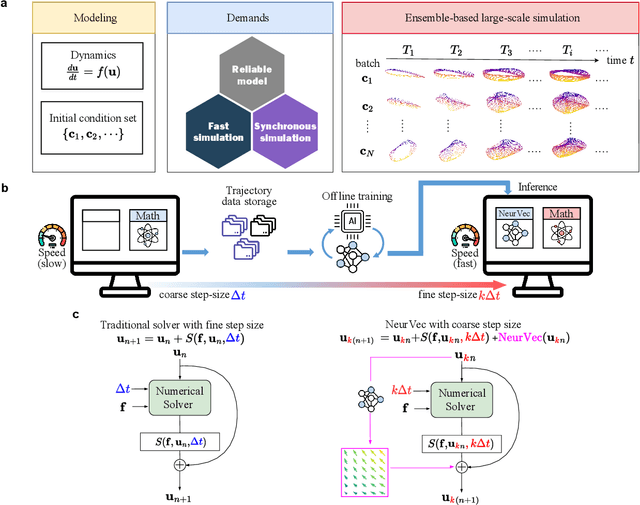

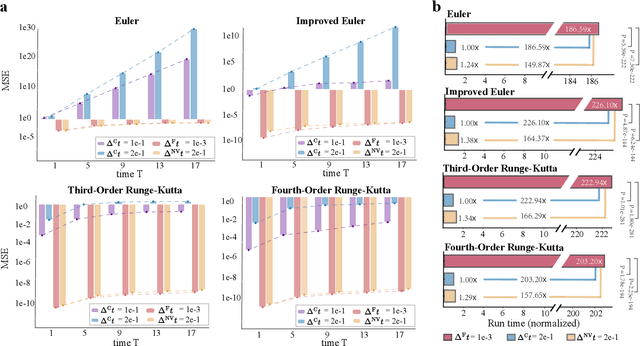
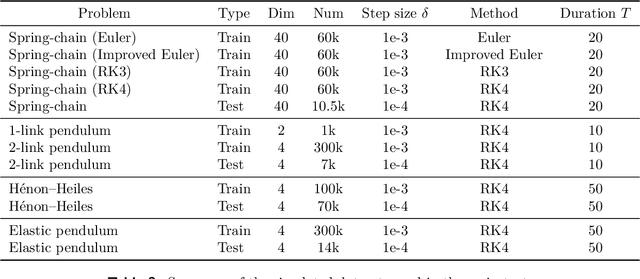
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.
Robust Real-World Image Super-Resolution against Adversarial Attacks
Jul 31, 2022
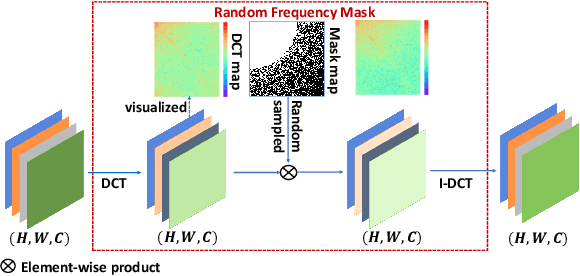
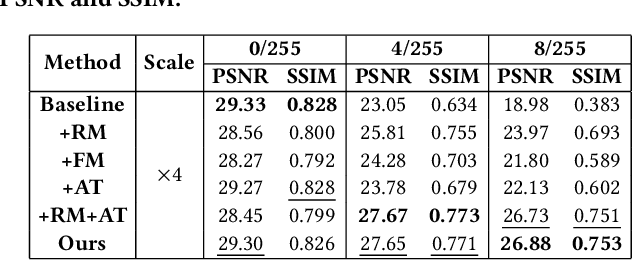
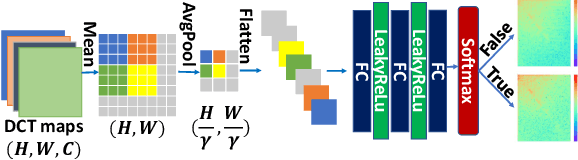
Recently deep neural networks (DNNs) have achieved significant success in real-world image super-resolution (SR). However, adversarial image samples with quasi-imperceptible noises could threaten deep learning SR models. In this paper, we propose a robust deep learning framework for real-world SR that randomly erases potential adversarial noises in the frequency domain of input images or features. The rationale is that on the SR task clean images or features have a different pattern from the attacked ones in the frequency domain. Observing that existing adversarial attacks usually add high-frequency noises to input images, we introduce a novel random frequency mask module that blocks out high-frequency components possibly containing the harmful perturbations in a stochastic manner. Since the frequency masking may not only destroys the adversarial perturbations but also affects the sharp details in a clean image, we further develop an adversarial sample classifier based on the frequency domain of images to determine if applying the proposed mask module. Based on the above ideas, we devise a novel real-world image SR framework that combines the proposed frequency mask modules and the proposed adversarial classifier with an existing super-resolution backbone network. Experiments show that our proposed method is more insensitive to adversarial attacks and presents more stable SR results than existing models and defenses.
* ACM-MM 2021, Code: https://github.com/lhaof/Robust-SR-against-Adversarial-Attacks
Adversarially-Aware Robust Object Detector
Jul 22, 2022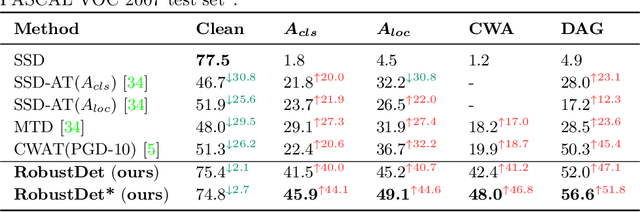
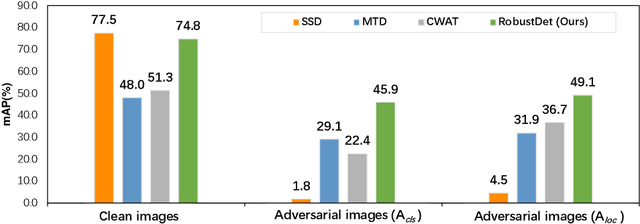
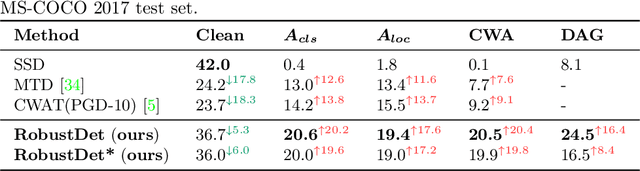
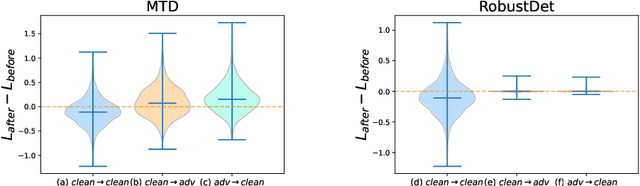
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper
The Lottery Ticket Hypothesis for Self-attention in Convolutional Neural Network
Jul 16, 2022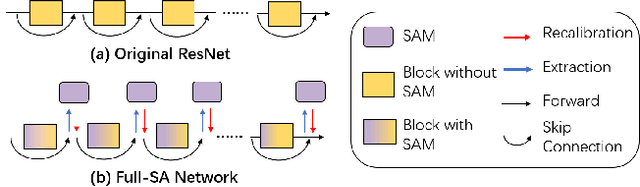
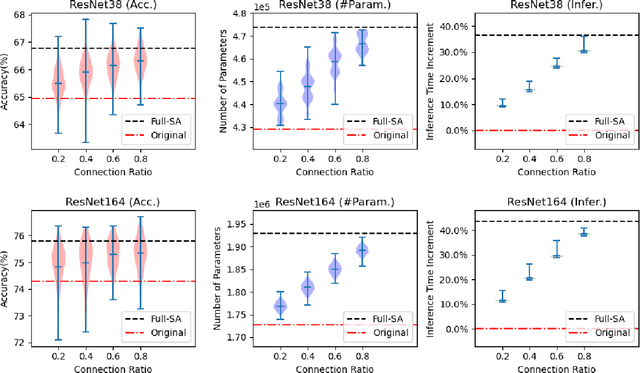
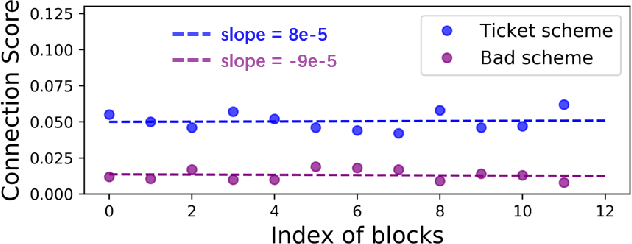
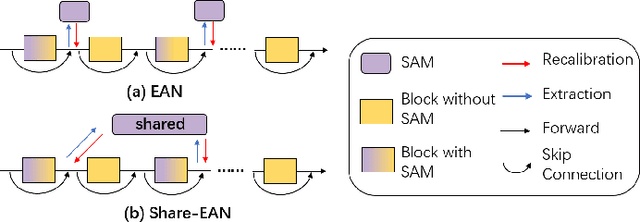
Recently many plug-and-play self-attention modules (SAMs) are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). In general, previous works ignore where to plug in the SAMs since they connect the SAMs individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and the number of parameters with the growth of network depth. However, we empirically find and verify some counterintuitive phenomena that: (a) Connecting the SAMs to all the blocks may not always bring the largest performance boost, and connecting to partial blocks would be even better; (b) Adding the SAMs to a CNN may not always bring a performance boost, and instead it may even harm the performance of the original CNN backbone. Therefore, we articulate and demonstrate the Lottery Ticket Hypothesis for Self-attention Networks: a full self-attention network contains a subnetwork with sparse self-attention connections that can (1) accelerate inference, (2) reduce extra parameter increment, and (3) maintain accuracy. In addition to the empirical evidence, this hypothesis is also supported by our theoretical evidence. Furthermore, we propose a simple yet effective reinforcement-learning-based method to search the ticket, i.e., the connection scheme that satisfies the three above-mentioned conditions. Extensive experiments on widely-used benchmark datasets and popular self-attention networks show the effectiveness of our method. Besides, our experiments illustrate that our searched ticket has the capacity of transferring to some vision tasks, e.g., crowd counting and segmentation.
Discourse-Aware Graph Networks for Textual Logical Reasoning
Jul 04, 2022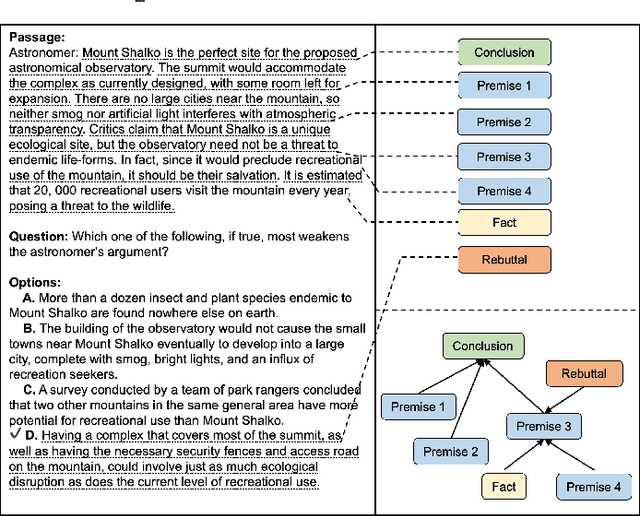
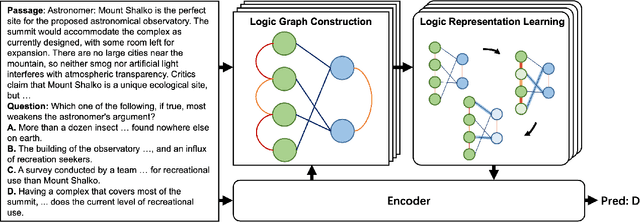
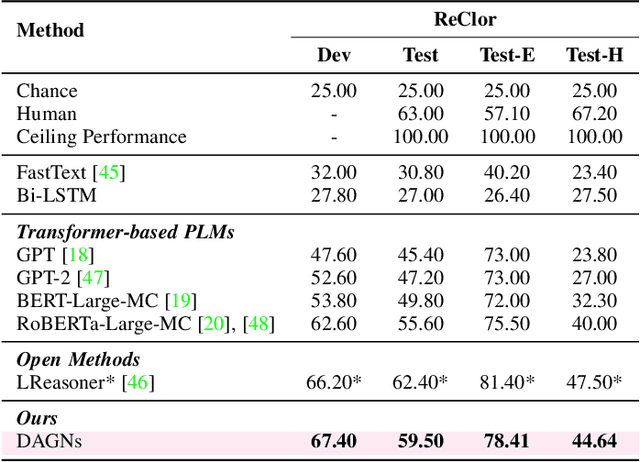
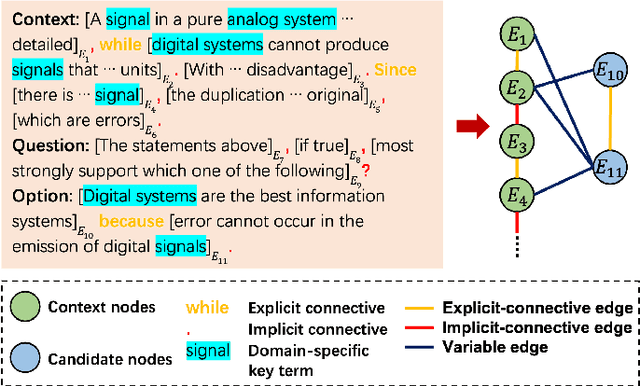
Textual logical reasoning, especially question answering (QA) tasks with logical reasoning, requires awareness of particular logical structures. The passage-level logical relations represent entailment or contradiction between propositional units (e.g., a concluding sentence). However, such structures are unexplored as current QA systems focus on entity-based relations. In this work, we propose logic structural-constraint modeling to solve the logical reasoning QA and introduce discourse-aware graph networks (DAGNs). The networks perform two procedures: (1) logic graph construction that leverages in-line discourse connectives as well as generic logic theories, (2) logic representation learning by graph networks that produces structural logic features. This pipeline is applied to a general encoder, whose fundamental features are joined with the high-level logic features for answer prediction. Experiments on three textual logical reasoning datasets demonstrate the reasonability of the logical structures built in DAGNs and the effectiveness of the learned logic features. Moreover, zero-shot transfer results show the features' generality to unseen logical texts.
Real-World Image Super-Resolution by Exclusionary Dual-Learning
Jun 06, 2022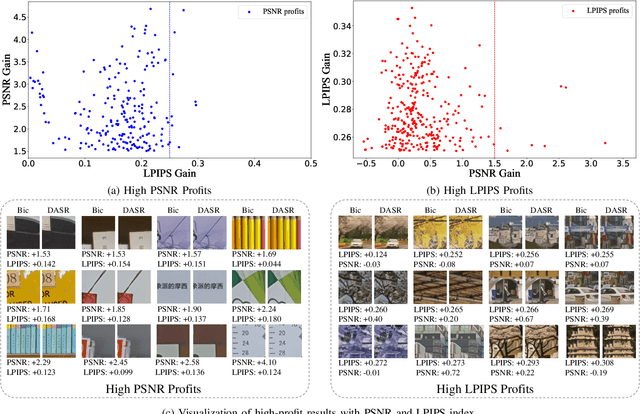

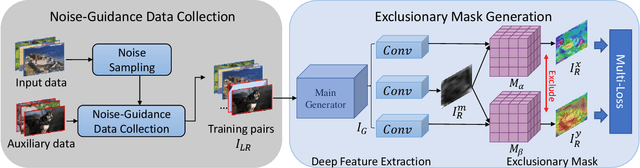
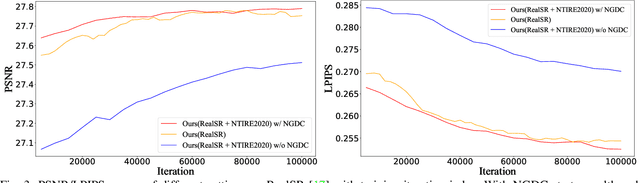
Real-world image super-resolution is a practical image restoration problem that aims to obtain high-quality images from in-the-wild input, has recently received considerable attention with regard to its tremendous application potentials. Although deep learning-based methods have achieved promising restoration quality on real-world image super-resolution datasets, they ignore the relationship between L1- and perceptual- minimization and roughly adopt auxiliary large-scale datasets for pre-training. In this paper, we discuss the image types within a corrupted image and the property of perceptual- and Euclidean- based evaluation protocols. Then we propose a method, Real-World image Super-Resolution by Exclusionary Dual-Learning (RWSR-EDL) to address the feature diversity in perceptual- and L1- based cooperative learning. Moreover, a noise-guidance data collection strategy is developed to address the training time consumption in multiple datasets optimization. When an auxiliary dataset is incorporated, RWSR-EDL achieves promising results and repulses any training time increment by adopting the noise-guidance data collection strategy. Extensive experiments show that RWSR-EDL achieves competitive performance over state-of-the-art methods on four in-the-wild image super-resolution datasets.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
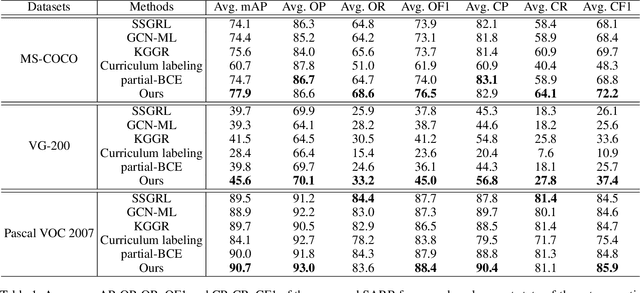
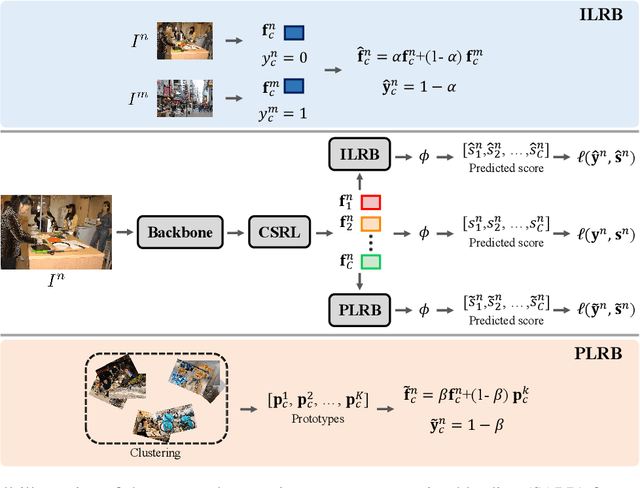
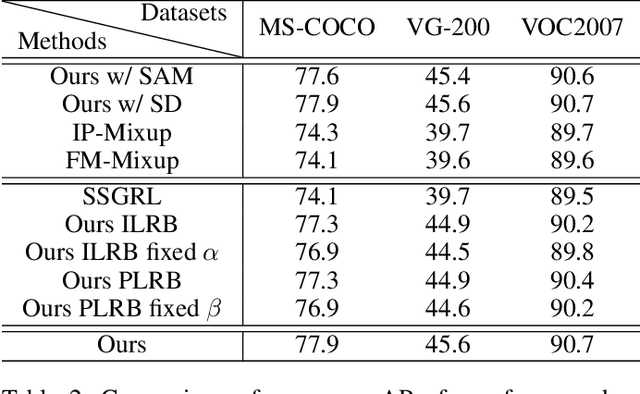
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.
Heterogeneous Semantic Transfer for Multi-label Recognition with Partial Labels
May 23, 2022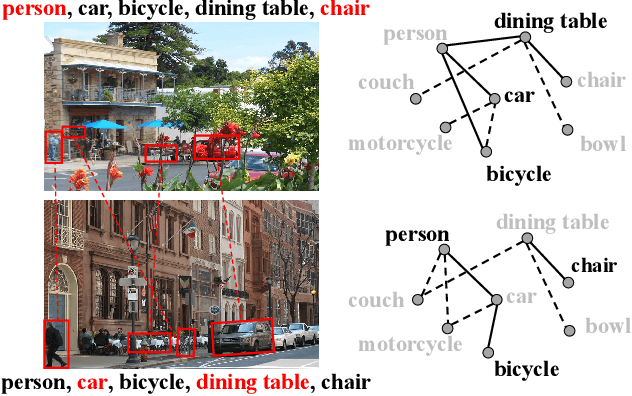
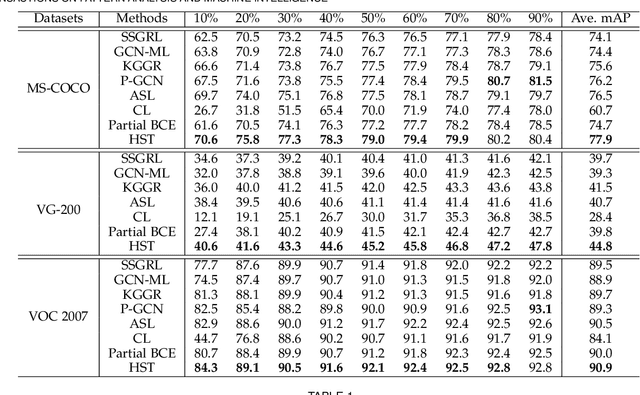

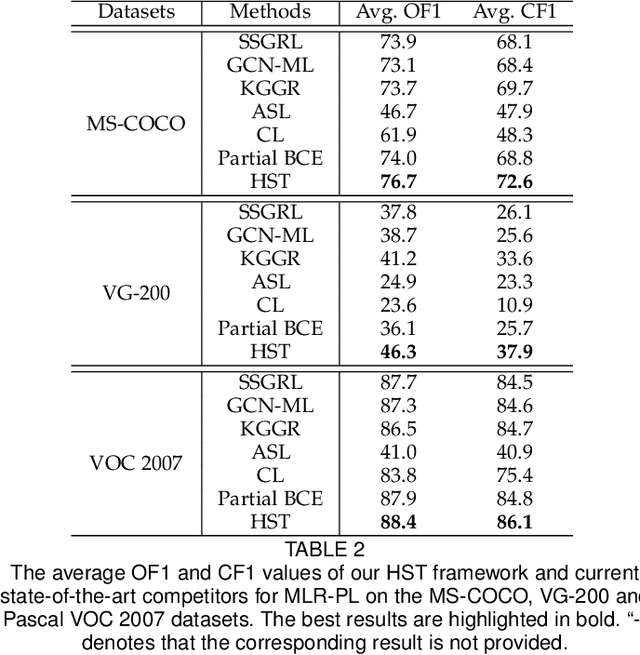
Multi-label image recognition with partial labels (MLR-PL), in which some labels are known while others are unknown for each image, may greatly reduce the cost of annotation and thus facilitate large-scale MLR. We find that strong semantic correlations exist within each image and across different images, and these correlations can help transfer the knowledge possessed by the known labels to retrieve the unknown labels and thus improve the performance of the MLR-PL task (see Figure 1). In this work, we propose a novel heterogeneous semantic transfer (HST) framework that consists of two complementary transfer modules that explore both within-image and cross-image semantic correlations to transfer the knowledge possessed by known labels to generate pseudo labels for the unknown labels. Specifically, an intra-image semantic transfer (IST) module learns an image-specific label co-occurrence matrix for each image and maps the known labels to complement the unknown labels based on these matrices. Additionally, a cross-image transfer (CST) module learns category-specific feature-prototype similarities and then helps complement the unknown labels that have high degrees of similarity with the corresponding prototypes. Finally, both the known and generated pseudo labels are used to train MLR models. Extensive experiments conducted on the Microsoft COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed HST framework achieves superior performance to that of current state-of-the-art algorithms. Specifically, it obtains mean average precision (mAP) improvements of 1.4%, 3.3%, and 0.4% on the three datasets over the results of the best-performing previously developed algorithm.
LogicSolver: Towards Interpretable Math Word Problem Solving with Logical Prompt-enhanced Learning
May 17, 2022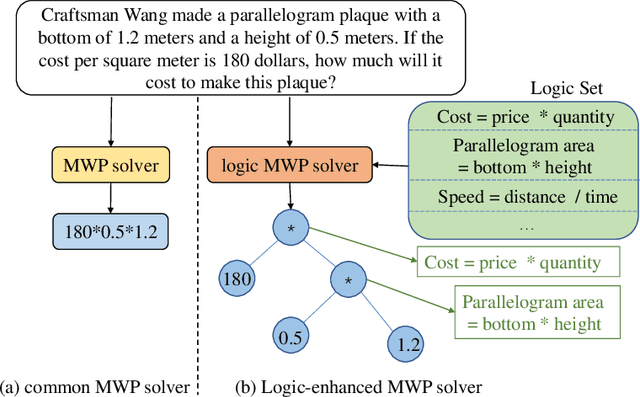
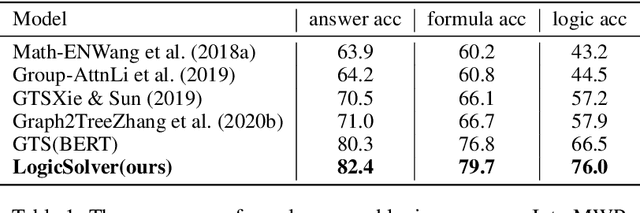

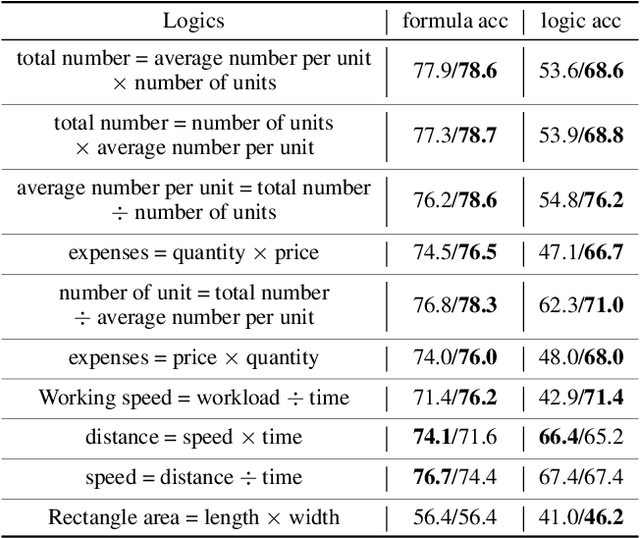
Recently, deep learning models have made great progress in MWP solving on answer accuracy. However, they are uninterpretable since they mainly rely on shallow heuristics to achieve high performance without understanding and reasoning the grounded math logic. To address this issue and make a step towards interpretable MWP solving, we first construct a high-quality MWP dataset named InterMWP which consists of 11,495 MWPs and annotates interpretable logical formulas based on algebraic knowledge as the grounded linguistic logic of each solution equation. Different from existing MWP datasets, our InterMWP benchmark asks for a solver to not only output the solution expressions but also predict the corresponding logical formulas. We further propose a novel approach with logical prompt and interpretation generation, called LogicSolver. For each MWP, our LogicSolver first retrieves some highly-correlated algebraic knowledge and then passes them to the backbone model as prompts to improve the semantic representations of MWPs. With these improved semantic representations, our LogicSolver generates corresponding solution expressions and interpretable knowledge formulas in accord with the generated solution expressions, simultaneously. Experimental results show that our LogicSolver has stronger logical formula-based interpretability than baselines while achieving higher answer accuracy with the help of logical prompts, simultaneously.